TPU v6e
本文档介绍了 Cloud TPU v6e (Trillium) 的架构和支持的配置。
Trillium 是 Cloud TPU 的最新一代 AI 加速器。在所有技术界面(例如 API 和日志)以及本文档中,Trillium 都将称为 v6e。
v6e 的每个 Pod 有 256 个芯片,与 v5e 有很多相似之处。此系统经过优化,成为适用于 Transformer、文本转图片和卷积神经网络 (CNN) 训练、微调和部署的高价值产品。
系统架构
每个 v6e 芯片包含一个 TensorCore。每个 TensorCore 都有两个矩阵乘法单元 (MXU)、一个向量单元和一个标量单元。下表展示了 TPU v6e 相较于 TPU v5e 的主要规范及其值。
| 规范 | v5e | v6e |
|---|---|---|
| 性能/总拥有成本 (TCO)(预期) | 0.65 倍 | 1 |
| 每个芯片的峰值计算能力 (bf16) | 197 TFLOPs | 918 TFLOPs |
| 每个芯片的峰值计算能力 (Int8) | 393 TOPs | 1836 TOPs |
| 每个芯片的 HBM 容量 | 16 GB | 32 GB |
| 每个芯片的 HBM 带宽 | 800 GBps | 1600 GBps |
| 芯片间互连 (ICI) 带宽 | 1600 Gbps | 3200 Gbps |
| 每个芯片的 ICI 端口数 | 4 | 4 |
| 每个主机的 DRAM | 512 GiB | 1536 GiB |
| 每个主机上的芯片数 | 8 | 8 |
| TPU Pod 大小 | 256 个芯片 | 256 个芯片 |
| 互连拓扑 | 2D 环面 | 2D 环面 |
| 每个 Pod 的 BF16 峰值计算能力 | 50.63 PFLOPs | 234.9 PFLOPs |
| 每个 Pod 的全归约带宽 | 51.2 TB/s | 102.4 TB/s |
| 每个 Pod 的对分带宽 | 1.6 TB/s | 3.2 TB/s |
| 按主机NIC配置 | 2 x 100 Gbps NIC | 4 x 200 Gbps NIC |
| 每个 Pod 的数据中心网络带宽 | 6.4 Tbps | 25.6 Tbps |
| 特殊功能 | - | SparseCore |
受支持的配置
下表显示了 v6e 支持的 2D 切片形状:
| 拓扑 | TPU 芯片 | 主机 | 虚拟机 | 加速器类型 (TPU API) | 机器类型 (GKE API) | 范围 |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
子主机 |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
子主机 |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
单个主机 |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
单个主机 |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
多主机 |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
多主机 |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
多主机 |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
多主机 |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
多主机 |
附加到单个虚拟机的 8 芯片切片 (v6e-8) 经过推理优化,允许在单个服务工作负载中使用所有 8 个芯片。您可以使用 Pathways on Cloud 执行多主机推理。如需了解详情,请参阅使用 Pathways 执行多主机推理。
如需了解每种拓扑的虚拟机数量,请参阅虚拟机类型。
虚拟机类型
每个 TPU v6e 虚拟机都可以包含 1 个、4 个或 8 个芯片。4 芯片及更小的切片具有相同的非统一内存访问 (NUMA) 节点。如需详细了解 NUMA 节点,请参阅维基百科上的非统一内存访问。
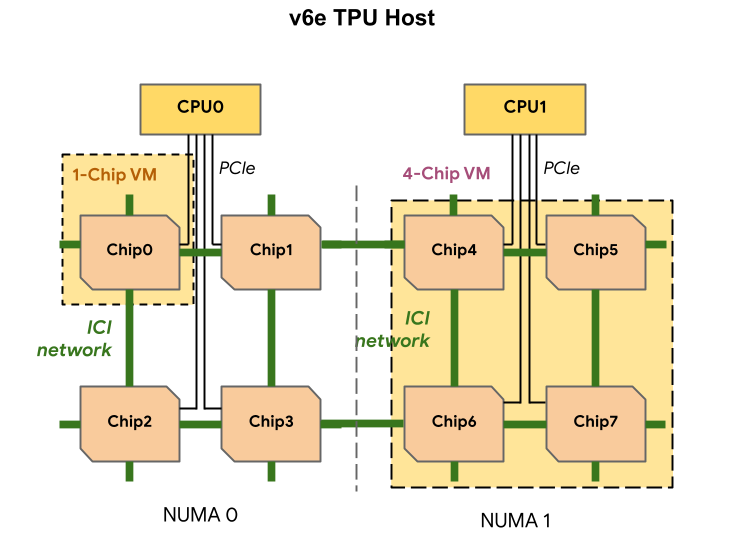
v6e 切片是使用半主机虚拟机创建的,每个虚拟机有 4 个 TPU 芯片。此规则有两种例外情况:
v6e-1:仅包含单个芯片的虚拟机,主要用于测试v6e-8:一种全主机虚拟机,已针对推理使用情形进行优化,所有 8 个芯片都连接到单个虚拟机。
下表比较了 TPU v6e 虚拟机类型:
| 虚拟机类型 | 每个虚拟机的 vCPU 数量 | 每个虚拟机的 RAM (GB) | 每个虚拟机的 NUMA 节点数 |
|---|---|---|---|
| 单芯片虚拟机 | 44 | 176 | 1 |
| 4 芯片虚拟机 | 180 | 720 | 1 |
| 8 芯片虚拟机 | 180 | 1440 | 2 |
指定 v6e 配置
使用 TPU API 分配 TPU v6e 切片时,您可以使用 AcceleratorType 参数指定其大小和形状。
如果您使用的是 GKE,请使用 --machine-type 标志指定支持您要使用的 TPU 的机器类型。如需了解详情,请参阅 GKE 文档中的规划 GKE 中的 TPU。
使用 AcceleratorType
分配 TPU 资源时,您可以使用 AcceleratorType 指定切片中的 TensorCore 数量。您为 AcceleratorType 指定的值是一个字符串,格式为:v$VERSION-$TENSORCORE_COUNT。例如,v6e-8 指定一个具有 8 个 TensorCore 的 v6e TPU 切片。
以下示例展示了如何使用 AcceleratorType 创建具有 32 个 TensorCore 的 TPU v6e 切片:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e