TPU v4
Este documento descreve a arquitetura e as configurações disponíveis no Cloud TPU v4.
Arquitetura do sistema
Cada chip da TPU v4 contém dois TensorCores. Cada TensorCore tem quatro unidades de multiplicação de matrizes (MXUs), uma unidade vetorial e uma escalar. A tabela a seguir mostra as principais especificações de um Pod de TPU da v4.
| Principais especificações | Valores do pod da v4 |
|---|---|
| Pico de computação por chip | 275 teraflops (bf16 ou int8) |
| Capacidade e largura de banda de HBM2 | 32 GiB, 1200 GBps |
| Potência mínima/média/máxima medida | 90/170/192 W |
| Tamanho do Pod de TPU | 4096 chips |
| Topologia de interconexão | Malha 3D |
| Cálculo máximo por pod | 1,1 exaflops (bf16 ou int8) |
| Largura de banda de redução total por pod | 1,1 PB/s |
| Largura de banda de bissecção por pod | 24 TB/s |
O diagrama a seguir ilustra um chip da TPU v4.
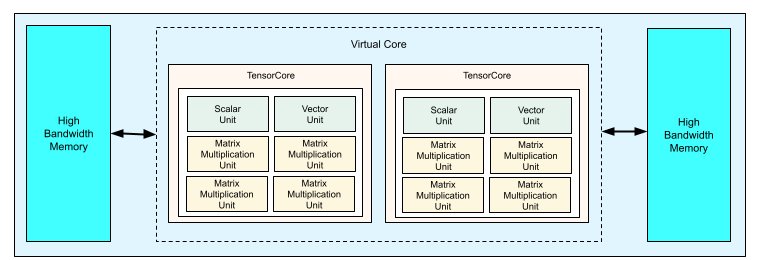
Para saber os detalhes da arquitetura e as características de desempenho da TPU v4, consulte TPU v4: um supercomputador opticamente reconfigurável para machine learning com disponibilidade de hardware para embeddings.
Malha 3D e toro 3D
As TPUs v4 têm uma conexão direta com os chips vizinhos mais próximos em três dimensões, o que resulta em uma malha 3D de conexões de rede. As conexões podem ser configuradas como um toro 3D em frações em que a topologia, AxBxC, é 2A=B=C ou 2A=2B=C, em que cada dimensão é um múltiplo de 4. Por exemplo, 4x4x8, 4x8x8 ou 12x12x24. Em geral, o desempenho de uma configuração de toro 3D é melhor do que uma configuração de malha 3D. Para mais informações, consulte Topologias de toros torcidos.
Benefícios de desempenho da TPU v4 em relação à v3
Esta seção mostra uma forma eficiente de usar a memória para executar um script de treinamento de amostra na TPU v4, além das melhorias de desempenho da TPU v4 em comparação com a TPU v3.
Sistema de memória
O acesso à memória não uniforme (NUMA) é uma arquitetura de memória de computador para máquinas com várias CPUs. Cada CPU tem acesso direto a um bloco de memória de alta velocidade. Uma CPU e a memória associada são chamadas de nó NUMA. Os nós NUMA são conectados a outros diretamente adjacentes. Uma CPU de um nó NUMA pode acessar a memória de outro, mas esse acesso é mais lento do que o acesso à memória no próprio nó.
O software executado em uma máquina com várias CPUs pode colocar os dados necessários para uma CPU no nó NUMA dela, o que aumenta a capacidade de processamento de memória. Para mais informações sobre NUMA, consulte Acesso à memória não uniforme na Wikipédia.
Para aproveitar os benefícios de localidade de NUMA, vincule o script de treinamento ao nó NUMA 0.
Para ativar a vinculação de nós NUMA, faça o seguinte:
Instale a ferramenta de linha de comando numactl. Com ela, é possível executar processos com uma política específica de programação de NUMA ou de alocação de memória.
$ sudo apt-get update $ sudo apt-get install numactl
Vincule o código do script ao nó NUMA 0. Substitua your-training-script pelo caminho do script de treinamento.
$ numactl --cpunodebind=0 python3 your-training-script
Ative a vinculação de nós NUMA nestes casos:
- Se a carga de trabalho depender muito de cargas de trabalho de CPU, como para classificação de imagens e recomendação, seja qual for o framework.
- Ao usar uma versão do ambiente de execução de TPU sem um sufixo -pod,
como
tpu-vm-tf-2.10.0-v4.
Outras diferenças no sistema de memória:
- Os chips da TPU v4 têm um espaço de memória de HBM unificado de 32 GiB em todo o chip, o que permite uma coordenação melhor entre os dois TensorCores no chip.
- Melhoria no desempenho de HBM usando os padrões e as velocidades de memória mais recentes.
- Melhoria no perfil de desempenho de DMA com disponibilidade integrada para saltos de alto desempenho em granularidades de 512 bytes.
TensorCores
- O dobro do número de MXUs e uma velocidade de clock mais alta, que oferece 275 TFLOPS máximos.
- O dobro de largura de banda de transposição e permutação.
- Modelo de acesso à memória de carregamento e armazenamento para memória comum (Cmem).
- Largura de banda de carregamento de peso de MXU mais rápida e compatibilidade com o modo de 8 bits para permitir tamanhos de lote menores e melhor latência de inferência.
Interconexão entre chips
Seis links de interconexão por chip para permitir topologias de rede com diâmetros menores.
Outros
- Interface PCIe Gen3 x16 para host (conexão direta).
- Modelo de segurança aprimorado.
- Maior eficiência energética.
Configurações
Um Pod de TPU v4 é composto por 4.096 chips interconectados com links de alta velocidade
reconfiguráveis. Com a rede flexível da TPU v4, é possível conectar os chips em
frações de mesmo tamanho de várias maneiras. Ao criar uma fração de TPU, especifique a
versão da TPU e o número de recursos de TPU necessários. Ao criar
uma fração de TPU v4, é possível especificar o tipo e o tamanho dela de duas maneiras:
AcceleratorType e AccleratorConfig.
Como usar AcceleratorType
Use AcceleratorType quando não estiver especificando uma topologia. Para configurar TPUs v4
usando AcceleratorType, utilize a flag --accelerator-type ao criar
a fração de TPU. Defina --accelerator-type como uma string que contenha a
versão da TPU e o número de TensorCores que você quer usar. Por exemplo, para criar uma
fração da v4 com 32 TensorCores, use --accelerator-type=v4-32.
Use o comando gcloud compute tpus tpu-vm create
para criar uma
fração de TPU v4 com 512 TensorCores
e utilize a flag --accelerator-type:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
O número após a versão da TPU (v4) especifica a quantidade de TensorCores.
Há dois TensorCores em uma TPU v4. Portanto, o número de chips de TPU
seria 512/2 = 256.
Para saber como gerenciar TPUs, consulte Gerenciar TPUs. Para mais informações sobre a arquitetura do sistema do Cloud TPU, consulte Arquitetura do sistema.
Como usar AcceleratorConfig
Use AcceleratorConfig para personalizar a
topologia física da fração de TPU. Em geral, isso é necessário para o ajuste de
desempenho com frações com mais de 256 chips.
Para configurar TPUs v4 usando AcceleratorConfig,
utilize as flags --type e --topology. Defina --type como a versão da TPU que você quer usar e
--topology como a disposição física dos chips de TPU na fração.
Especifique uma topologia de TPU usando uma tupla de três elementos, AxBxC, em que
A<=B<=C e A, B, C são todos <= 4 ou números inteiros múltiplos de 4. Os valores de A, B e C são as
contagens de chips em cada uma das três dimensões. Por exemplo, para criar uma fração da v4
com 16 chips, defina --type=v4 e --topology=2x2x4.
Use o comando gcloud compute tpus tpu-vm create
para criar uma
fração de TPU da v4 com 128 chips de TPU organizados em uma matriz 4x4x8:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
As topologias em que 2A=B=C ou 2A=2B=C também têm variantes de topologia otimizadas para a comunicação de todos com todos, como 4×4×8, 8×8×16 e 12×12×24. Elas são conhecidas como topologias de toros torcidos.
As ilustrações a seguir mostram algumas topologias comuns de TPU v4.
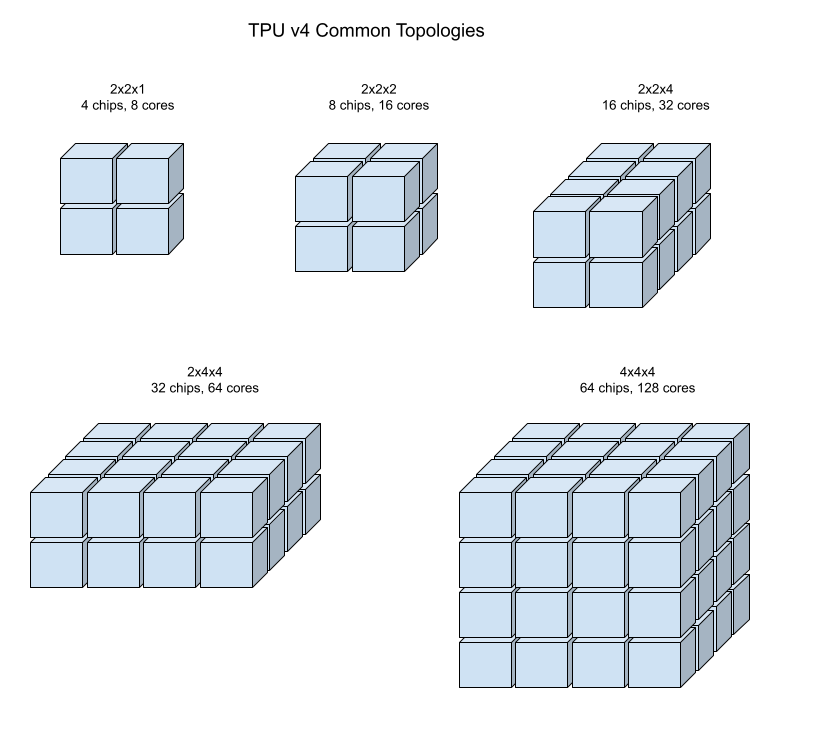
Frações maiores podem ser criadas com um ou mais cubos de chips de 4x4x4.
Para saber como gerenciar TPUs, consulte Gerenciar TPUs. Para mais informações sobre a arquitetura do sistema do Cloud TPU, consulte Arquitetura do sistema.
Topologias de toros torcidos
Alguns formatos de fração de toro 3D da v4 permitem o uso de uma topologia de toros torcidos. Por exemplo, dois cubos da v4 podem ser organizados como uma fração 4x4x8 ou 4x4x8_twisted. As topologias de toros torcidos oferecem uma largura de banda de bisseção significativamente maior. Por exemplo, uma fração com a topologia 4x4x8_twisted oferece um aumento teórico de 70% na largura de banda de bissecção em comparação com uma fração 4x4x8 sem toros torcidos. O aumento da largura de banda de bisseção é útil para cargas de trabalho que usam padrões de comunicação global. As topologias de toros torcidos podem melhorar o desempenho da maioria dos modelos, e as cargas de trabalho de embedding de TPU grandes são as maiores beneficiadas.
Para cargas de trabalho que usam o paralelismo de dados como a única estratégia de paralelismo, as topologias de toros torcidos podem oferecer um desempenho um pouco melhor. Para os LLMs, o desempenho ao usar uma topologia de toros torcidos pode variar de acordo com o tipo de paralelismo (DP, MP etc.). A prática recomendada é treinar o LLM com uma topologia de toros torcidos e com outra topologia para determinar qual delas oferece o melhor desempenho. Alguns experimentos no modelo MaxText de FSDP tiveram melhorias de 1 a 2 pontos na MFU usando uma topologia de toros torcidos.
O principal benefício das topologias de toros torcidos é que elas transformam uma topologia de toro assimétrica, como 4×4×8, em uma topologia simétrica intimamente relacionada. A topologia simétrica tem muitos benefícios:
- Melhor balanceamento de carga
- Maior largura de banda bisseccional
- Rotas de pacote menores
Esses benefícios resultam em um desempenho melhor para muitos padrões de comunicação global.
O software de TPU aceita toros torcidos em frações em que o tamanho de cada dimensão é igual ou o dobro da menor dimensão. Por exemplo, 4x4x8, 4×8×8 ou 12x12x24.
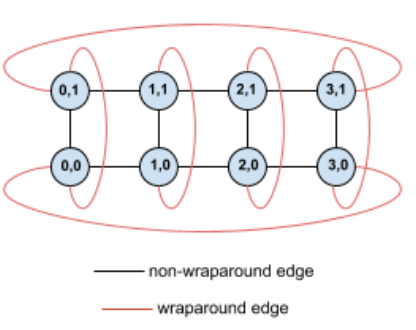
Por exemplo, considere esta topologia de toro 4×2 com TPUs rotuladas com as respectivas coordenadas (X,Y) na fração:
Para maior clareza, as arestas nesse gráfico de topologia são mostradas como não direcionadas. Na prática, cada aresta é uma conexão bidirecional entre TPUs. As arestas entre um lado e o lado oposto dessa grade são chamadas de arestas circundantes, conforme indicado no diagrama.
Ao mudar essa topologia para a de toros torcidos, o resultado é uma topologia de 4×2 completamente simétrica:
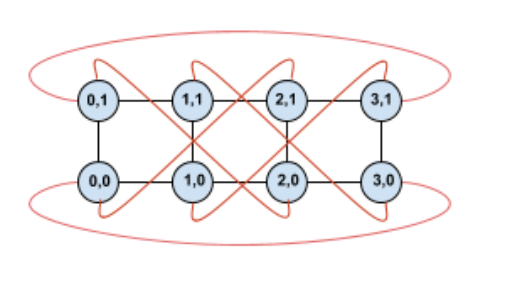
A única coisa que mudou entre este diagrama e o anterior são as arestas circundantes de Y. Em vez de se conectar a outra TPU com a mesma coordenada X, elas foram movidas para se conectar à TPU com a coordenada X+2 mod 4.
A mesma ideia vale para diferentes tamanhos e números de dimensões. A rede resultante é simétrica, desde que cada dimensão seja igual ou o dobro da menor dimensão.
Consulte Como usar AcceleratorConfig para saber como especificar uma configuração de toros torcidos ao criar um Cloud TPU.
A tabela a seguir mostra as topologias de toros torcidos disponíveis e um aumento teórico na largura de banda de bissecção com elas em comparação com as outras topologias.
| Topologia de toros torcidos | Aumento teórico na largura de banda de bisseção em comparação com outras topologias |
|---|---|
| 4×4×8_twisted | Cerca de 70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | Cerca de 40% |
| 8×16×16_twisted |
Variantes de topologia da TPU v4
Algumas topologias com o mesmo número de chips podem ser organizadas de maneiras diferentes. Por exemplo, uma fração de TPU com 512 chips (1.024 TensorCores) pode ser configurada usando as seguintes topologias: 4x4x32, 4x8x16 ou 8x8x8. Uma fração de TPU com 2.048 chips (4.096 TensorCores) oferece ainda mais opções de topologia: 4x4x128, 4x8x64, 4x16x32 e 8x16x16.
A topologia padrão associada a uma determinada contagem de chips é a mais parecida com um cubo. Esse formato provavelmente é a melhor opção para treinamentos de ML com paralelismo de dados. Outras topologias podem ser úteis para cargas de trabalho com vários tipos de paralelismo, como paralelismo de modelos e de dados ou particionamento espacial de simulações. Essas cargas de trabalho têm melhor desempenho quando a topologia corresponde ao paralelismo usado. Por exemplo, colocar o paralelismo de modelo de quatro vias na dimensão X e o paralelismo de dados de 256 vias nas dimensões Y e Z corresponde a uma topologia 4x16x16.
Os modelos com várias dimensões de paralelismo têm melhor desempenho quando as dimensões do paralelismo são associadas às dimensões da topologia da TPU. Normalmente, esses são os modelos de linguagem grandes (LLMs) com paralelismo de dados e modelos. Por exemplo, para uma fração da TPU v4 com a topologia 8x16x16, as dimensões da topologia da TPU são 8, 16 e 16. É mais eficiente usar o paralelismo de modelos de oito ou 16 vias, associado a uma das dimensões da topologia física da TPU. Um paralelismo de modelos de quatro vias seria menos ideal com essa topologia, já que ele não está alinhado a nenhuma das dimensões da topologia da TPU. No entanto, ele seria ideal com uma topologia 4x16x32 com o mesmo número de chips.
As configurações da TPU v4 consistem em dois grupos: aquelas com topologias menores que 64 chips (topologias pequenas) e aquelas com topologias maiores que 64 chips (topologias grandes).
Topologias pequenas da v4
O Cloud TPU aceita as frações da TPU v4 a seguir menores que 64 chips, ou seja, um cubo de 4x4x4. É possível criar essas pequenas topologias da v4 usando o nome baseado em TensorCores, como v4-32, ou a topologia, como 2x2x4:
| Nome (com base na contagem de TensorCores) | Número de chips | Topologia |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologias grandes da v4
As frações da TPU v4 estão disponíveis em incrementos de 64 chips, com formatos
múltiplos de 4 em todas as três dimensões. As dimensões precisam estar
em ordem crescente. Confira alguns exemplos na tabela a seguir. Algumas dessas
topologias são personalizadas e só podem ser criadas usando as
flags --type e --topology porque há mais de uma
forma de organizar os chips.
| Nome (com base na contagem de TensorCores) | Número de chips | Topologia |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
topologia personalizada: é preciso usar as flags --type e --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
topologia personalizada: é preciso usar as flags --type e --topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |