TPU v4
En este documento, se describe la arquitectura y las configuraciones compatibles de Cloud TPU v4.
Arquitectura del sistema
Cada chip TPU v4 contiene dos TensorCores. Cada TensorCore tiene cuatro unidades de multiplicación de matrices (MXUs), una unidad vectorial y una escalar. En la siguiente tabla, se muestran las especificaciones clave de un pod de TPU v4.
| Especificaciones clave | Valores de pod de la versión 4 |
|---|---|
| Procesamiento máximo por chip | 275 teraflops (bf16 o int8) |
| Capacidad y ancho de banda de HBM2 | 32 GiB, 1200 GBps |
| Potencia mínima, media y máxima medida | 90/170/192 W |
| Tamaño del pod de TPU | 4,096 chips |
| Topología de interconexión | Malla 3D |
| Procesamiento máximo por Pod | 1.1 exaflops (bf16 o int8) |
| Ancho de banda de reducción total por Pod | 1.1 PB/s |
| Ancho de banda de bisección por pod | 24 TB/s |
En el siguiente diagrama, se ilustra un chip TPU v4.
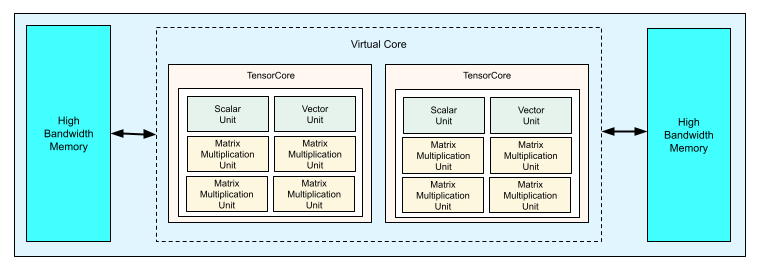
Para obtener más información sobre los detalles de la arquitectura y las características de rendimiento de la TPU v4, consulta TPU v4: Un supercomputador ópticamente reconfigurable para el aprendizaje automático con compatibilidad de hardware para las incorporaciones.
Malla 3D y toro 3D
Las TPU v4 tienen una conexión directa con los chips vecinos más cercanos en 3 dimensiones, lo que genera una malla 3D de conexiones de red. Las conexiones se pueden configurar como un toro 3D en rebanadas en las que la topología, AxBxC, es 2A=B=C o 2A=2B=C, donde cada dimensión es un múltiplo de 4. Por ejemplo, 4 × 4 × 8, 4 × 8 × 8 o 12 × 12 × 24. En general, el rendimiento de una configuración de toro 3D será mejor que el de una configuración de malla 3D. Para obtener más información, consulta Topologías de toros torcidos.
Beneficios de rendimiento de TPU v4 sobre v3
En esta sección, se muestra una forma eficiente en términos de memoria para ejecutar una secuencia de comandos de entrenamiento de muestra en TPU v4, así como las mejoras de rendimiento de TPU v4 en comparación con TPU v3.
Sistema de memoria
El acceso no uniforme a la memoria (NUMA) es una arquitectura de memoria de computadora para máquinas que tienen varias CPUs. Cada CPU tiene acceso directo a un bloque de memoria de alta velocidad. Una CPU y su memoria se denominan nodo NUMA. Los nodos NUMA están conectados a otros nodos NUMA que están directamente adyacentes entre sí. Una CPU de un nodo de NUMA puede acceder a la memoria de otro nodo de NUMA, pero este acceso es más lento que acceder a la memoria dentro de un nodo de NUMA.
El software que se ejecuta en una máquina con varias CPU puede colocar los datos que necesita una CPU dentro de su nodo NUMA, lo que aumenta la capacidad de procesamiento de la memoria. Para obtener más información sobre NUMA, consulta Acceso a memoria no uniforme en Wikipedia.
Para aprovechar los beneficios de la localidad de NUMA, vincula tu secuencia de comandos de entrenamiento al nodo NUMA 0.
Para habilitar la vinculación de nodos NUMA, haz lo siguiente:
Instala la herramienta de línea de comandos numactl. Esta herramienta te permite ejecutar procesos con una programación NUMA o una política de ubicación de memoria específicas.
$ sudo apt-get update $ sudo apt-get install numactl
Vincula el código de la secuencia de comandos al nodo NUMA 0. Reemplaza your-training-script por la ruta de acceso a tu secuencia de comandos de entrenamiento.
$ numactl --cpunodebind=0 python3 your-training-script
Habilita la vinculación de nodos NUMA en los siguientes casos:
- Si tu carga de trabajo depende en gran medida de las cargas de trabajo de la CPU (por ejemplo, la clasificación de imágenes o las cargas de trabajo de recomendación), independientemente del framework.
- Si usas una versión del entorno de ejecución de TPU sin un sufijo -pod (por ejemplo,
tpu-vm-tf-2.10.0-v4).
Otras diferencias entre los sistemas de memoria:
- Los chips de TPU v4 tienen un espacio de memoria HBM unificado de 32 GiB en todo el chip, lo que permite una mejor coordinación entre los dos núcleos de tensor en chip.
- Rendimiento mejorado de HBM con los estándares y las velocidades de memoria más recientes
- Se mejoró el perfil de rendimiento de DMA con compatibilidad integrada para el acceso por salto de alto rendimiento con granularidades de 512 B.
TensorCores
- El doble de la cantidad de MXUs y una velocidad de reloj más alta que ofrece 275 TFLOPS máximos
- Ancho de banda de transposición y permutación 2x.
- Modelo de acceso a la memoria de carga y almacenamiento para la memoria común (Cmem).
- Ancho de banda de carga de peso de MXU más rápido y compatibilidad con el modo de 8 bits para permitir tamaños de lotes más pequeños y una latencia de inferencia mejorada.
Interconexión entre chips
Seis vínculos de interconexión por chip para habilitar topologías de red que tengan diámetros de red más pequeños.
Otro
- Interfaz PCIE gen3 x16 al host (conexión directa)
- Modelo de seguridad mejorado.
- Mayor eficiencia energética.
Configuraciones
Un pod de TPU v4 se compone de 4,096 chips interconectados con vínculos de alta velocidad reconfigurables. La red flexible de la TPU v4 te permite conectar los chips de una porción del mismo tamaño de varias maneras. Cuando creas una porción de TPU, debes especificar la versión de TPU y la cantidad de recursos de TPU que necesitas. Cuando creas una porción de TPU v4, puedes especificar su tipo y tamaño de una de las siguientes dos maneras: AcceleratorType y AccleratorConfig.
Usa AcceleratorType
Usa AcceleratorType cuando no especifiques una topología. Para configurar TPU v4
con AcceleratorType, usa la marca --accelerator-type cuando crees tu
porción de TPU. Establece --accelerator-type en una cadena que contenga la versión de la TPU y la cantidad de TensorCores que deseas usar. Por ejemplo, para crear una porción v4 con 32 TensorCores, usarías --accelerator-type=v4-32.
Usa el comando gcloud compute tpus tpu-vm create para crear una porción de TPU v4 con 512 TensorCores con la marca --accelerator-type:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
El número que aparece después de la versión de la TPU (v4) especifica la cantidad de TensorCores.
Hay dos TensorCores en una TPU v4, por lo que la cantidad de chips TPU sería 512/2 = 256.
Para obtener más información sobre cómo administrar TPU, consulta Administra TPU. Para obtener más información sobre la arquitectura del sistema de Cloud TPU, consulta Arquitectura del sistema.
Usa AcceleratorConfig
Usa AcceleratorConfig cuando quieras personalizar la topología física de tu porción de TPU. Por lo general, esto es necesario para el ajuste de rendimiento con fragmentos de más de 256 chips.
Para configurar TPU v4 con AcceleratorConfig, usa las marcas --type y --topology. Establece --type en la versión de TPU que deseas usar y --topology en la disposición física de los chips TPU en la porción.
Especificas una topología de TPU con un 3-tuplo, AxBxC, donde A<=B<=C y A, B y C son todos <= 4 o son todos múltiplos enteros de 4. Los valores A, B y C son los recuentos de chips en cada una de las tres dimensiones. Por ejemplo, para crear una porción v4 con 16 chips, debes configurar --type=v4 y --topology=2x2x4.
Usa el comando gcloud compute tpus tpu-vm create para crear una porción de TPU v4 con 128 chips de TPU organizados en un array de 4 × 4 × 8:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
Las topologías en las que 2A=B=C o 2A=2B=C también tienen variantes de topología optimizadas para la comunicación de todos con todos, por ejemplo, 4×4×8, 8×8×16 y 12×12×24. Estas se conocen como topologías de toros torcidos.
En las siguientes ilustraciones, se muestran algunas topologías comunes de TPU v4.
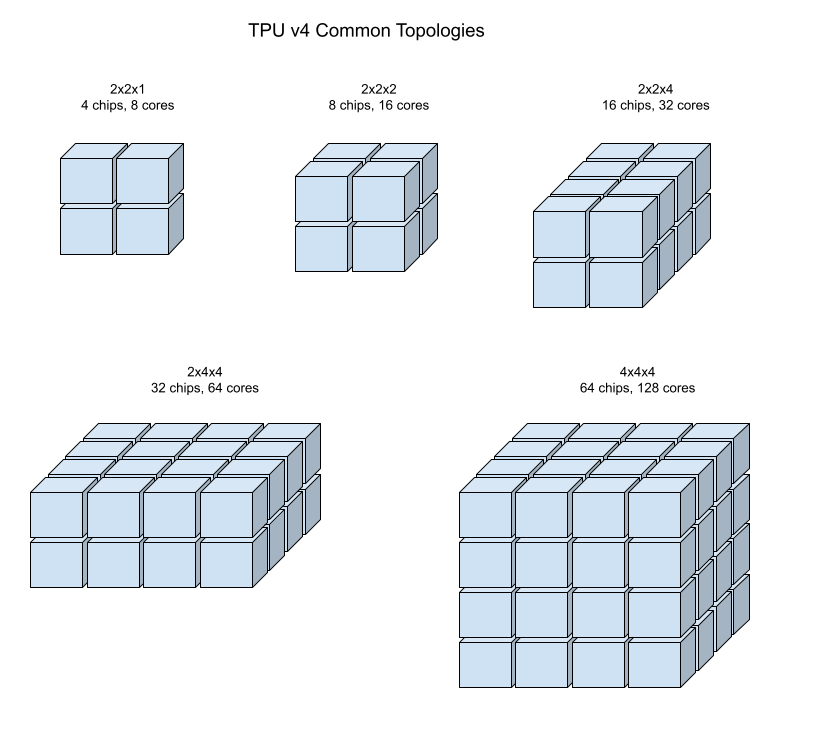
Las porciones más grandes se pueden crear a partir de uno o más “cubos” de chips de 4 × 4 × 4.
Para obtener más información sobre cómo administrar TPU, consulta Administra TPU. Para obtener más información sobre la arquitectura del sistema de Cloud TPU, consulta Arquitectura del sistema.
Topologías de toros torcidos
Algunas formas de rebanada de toro 3D de la v4 tienen la opción de usar lo que se conoce como una topología de toro torcido. Por ejemplo, dos cubos v4 se pueden organizar como una porción 4 × 4 × 8 o 4 × 4 × 8_trenzada. Las topologías trenzadas ofrecen una mayor ancho de banda de bisección. Por ejemplo, una porción con la topología 4x4x8_twisted proporciona un aumento teórico del 70% en el ancho de banda de la bisección en comparación con una porción 4x4x8 no trenzada. El aumento del ancho de banda de bisección es útil para las cargas de trabajo que usan patrones de comunicación globales. Las topologías trenzadas pueden mejorar el rendimiento de la mayoría de los modelos, y las cargas de trabajo de incorporación de TPU grandes se benefician más.
En el caso de las cargas de trabajo que usan el paralelismo de datos como la única estrategia de paralelismo, las topologías torcidas podrían tener un mejor rendimiento. En el caso de los LLM, el rendimiento con una topología trenzada puede variar según el tipo de paralelismo (DP, MP, etc.). La práctica recomendada es entrenar tu LLM con y sin una topología trenzada para determinar cuál proporciona el mejor rendimiento para tu modelo. Algunos experimentos en el modelo MaxText de FSDP mostraron mejoras de 1 a 2 MFU con una topología trenzada.
El beneficio principal de las topologías trenzadas es que transforman una topología de toro asimétrica (por ejemplo, 4 × 4 × 8) en una topología simétrica estrechamente relacionada. La topología simétrica tiene muchos beneficios:
- Balanceo de cargas mejorado
- Ancho de banda de bisección más alto
- Rutas de paquetes más cortas
Estos beneficios se traducen en un mejor rendimiento para muchos patrones de comunicación globales.
El software de TPU admite toros torcidos en rebanadas en las que el tamaño de cada dimensión es igual o el doble del tamaño de la dimensión más pequeña. Por ejemplo, 4 × 4 × 8, 4 × 8 × 8 o 12 × 12 × 24.
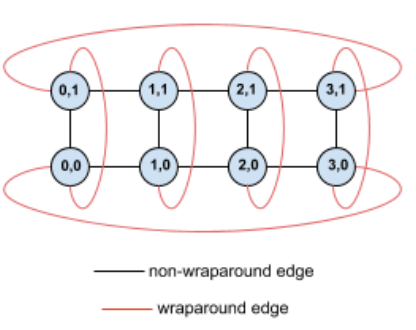
A modo de ejemplo, considera esta topología de toro de 4 × 2 con TPU etiquetadas con sus coordenadas (X,Y) en la porción:
Para mayor claridad, los bordes de este gráfico de topología se muestran como bordes no dirigidos. En la práctica, cada borde es una conexión bidireccional entre las TPU. Nos referimos a los bordes entre un lado de esta cuadrícula y el lado opuesto como bordes de unión, como se indica en el diagrama.
Si torcemos esta topología, obtenemos una topología de toro torcido 4 × 2 completamente simétrica:
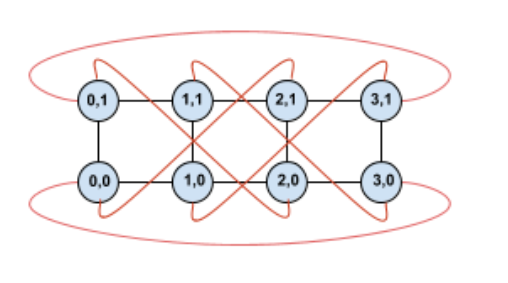
Lo único que cambió entre este diagrama y el anterior son los bordes de unión de Y. En lugar de conectarse a otra TPU con la misma coordenada X, se desplazaron para conectarse a la TPU con la coordenada X+2 mod 4.
La misma idea se generaliza a diferentes tamaños de dimensiones y diferentes cantidades de estas. La red resultante es simétrica, siempre que cada dimensión sea igual o el doble del tamaño de la dimensión más pequeña.
Consulta Cómo usar AcceleratorConfig para obtener detalles sobre cómo especificar una configuración de toro torcido cuando creas una Cloud TPU.
En la siguiente tabla, se muestran las topologías trenzadas compatibles y un aumento teórico en el ancho de banda de bisección con ellas en comparación con las topologías no trenzadas.
| Topología de giro | Aumento teórico en el ancho de banda de la bisección en comparación con un toro no torcido |
|---|---|
| 4×4×8_trenzado | ~70% |
| 8x8x16_twisted | |
| 12×12×24_trenzado | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
Variantes de topología de TPU v4
Algunas topologías que contienen la misma cantidad de chips se pueden organizar de diferentes maneras. Por ejemplo, un fragmento de TPU con 512 chips (1, 024 TensorCores) se puede configurar con las siguientes topologías: 4 × 4 × 32, 4 × 8 × 16 o 8 × 8 × 8. Un fragmento de TPU con 2,048 chips (4,096 TensorCores) ofrece aún más opciones de topología: 4 × 4 × 128, 4 × 8 × 64, 4 × 16 × 32 y 8 × 16 × 16.
La topología predeterminada asociada con un recuento de chips determinado es la que es más similar a un cubo. Es probable que esta forma sea la mejor opción para el entrenamiento de AA en paralelo con los datos. Otras topologías pueden ser útiles para cargas de trabajo con varios tipos de paralelismo (por ejemplo, paralelismo de modelos y datos, o partición espacial de una simulación). Estas cargas de trabajo tienen un mejor rendimiento si la topología coincide con el paralelismo utilizado. Por ejemplo, colocar el paralelismo de modelos de 4 vías en la dimensión X y el paralelismo de datos de 256 vías en las dimensiones Y y Z coincide con una topología de 4 × 16 × 16.
Los modelos con varias dimensiones de paralelismo tienen un mejor rendimiento cuando sus dimensiones de paralelismo están asignadas a las dimensiones de topología de TPU. Por lo general, estos son datos y modelos de lenguaje grandes (LLM) paralelos. Por ejemplo, para una porción de TPU v4 con topología 8x16x16, las dimensiones de la topología de TPU son 8, 16 y 16. Es más eficiente usar el paralelismo de modelos de 8 o 16 vías (asignado a una de las dimensiones de la topología física de TPU). Un paralelismo de 4 vías sería subóptimo con esta topología, ya que no está alineado con ninguna de las dimensiones de la topología de TPU, pero sería óptimo con una topología de 4 × 16 × 32 en la misma cantidad de chips.
Las configuraciones de TPU v4 consisten en dos grupos: las que tienen topologías de menos de 64 chips (topologías pequeñas) y las que tienen topologías de más de 64 chips (topologías grandes).
Topologías v4 pequeñas
Cloud TPU admite las siguientes porciones de TPU v4 más pequeñas que 64 chips, un cubo de 4 × 4 × 4. Puedes crear estas topologías v4 pequeñas con su nombre basado en TensorCore (por ejemplo, v4-32) o su topología (por ejemplo, 2 × 2 × 4):
| Nombre (según la cantidad de TensorCore) | Cantidad de chips | Topología |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologías v4 grandes
Las porciones de TPU v4 están disponibles en incrementos de 64 chips, con formas que son múltiplos de 4 en las tres dimensiones. Las dimensiones deben estar en
orden creciente. En la siguiente tabla, se muestran varios ejemplos. Algunas de estas topologías son "personalizadas" y solo se pueden crear con las marcas --type y --topology, ya que hay más de una forma de organizar los chips.
| Nombre (según la cantidad de TensorCore) | Cantidad de chips | Topología |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4 x 4 x 8 |
| v4-512 | 256 | 4 x 8 x 8 |
topología personalizada: Se deben usar las marcas --type y --topology. |
256 | 4 × 4 × 16 |
| v4-1024 | 512 | 8 x 8 x 8 |
| v4-1536 | 768 | 8 x 8 x 12 |
| v4-2048 | 1024 | 8 x 8 x 16 |
topología personalizada: Se deben usar las marcas --type y --topology. |
1024 | 4 × 16 × 16 |
| v4-4096 | 2,048 | 8 × 16 × 16 |
| … | … | … |