TPU v4
Este documento descreve a arquitetura e as configurações suportadas da Cloud TPU v4.
Arquitetura do sistema
Cada chip de TPU v4 contém dois TensorCores. Cada TensorCore tem quatro unidades de multiplicação de matrizes (MXUs), uma unidade vetorial e uma unidade escalar. A tabela seguinte mostra as especificações principais de um TPU Pod v4.
| Principais especificações | Valores do agrupamento v4 |
|---|---|
| Capacidade de computação máxima por chip | 275 teraflops (bf16 ou int8) |
| Capacidade e largura de banda da HBM2 | 32 GiB, 1200 GBps |
| Potência mínima/média/máxima medida | 90/170/192 W |
| Tamanho do pod TPU | 4096 chips |
| Topologia de interligação | Malha 3D |
| Pico de computação por agrupamento | 1,1 exaflops (bf16 ou int8) |
| Largura de banda de redução total por Pod | 1,1 PB/s |
| Largura de banda de bissecção por agrupamento | 24 TB/s |
O diagrama seguinte ilustra um chip de TPU v4.
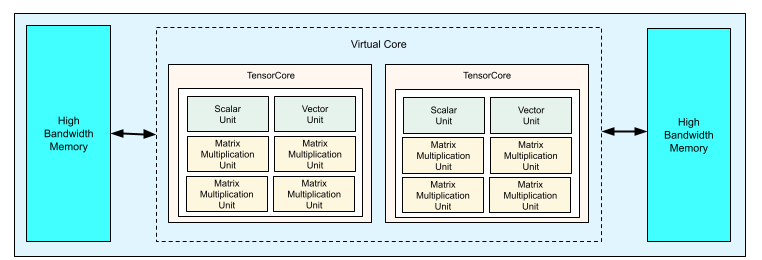
Para mais informações sobre detalhes de arquitetura e características de desempenho para a TPU v4, consulte o artigo TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
Malha 3D e toro 3D
As TPUs v4 têm uma ligação direta aos chips vizinhos mais próximos em 3 dimensões, o que resulta numa malha 3D de ligações de rede. As ligações podem ser configuradas como um toro 3D em fatias em que a topologia, AxBxC, é 2A=B=C ou 2A=2B=C, em que cada dimensão é um múltiplo de 4. Por exemplo, 4x4x8, 4x8x8 ou 12x12x24. Em geral, o desempenho de uma configuração de toro 3D é melhor do que o de uma configuração de malha 3D. Para mais informações, consulte o artigo Topologias de toros retorcidos.
Vantagens de desempenho da TPU v4 em relação à v3
Esta secção mostra uma forma eficiente em termos de memória de executar um script de preparação de amostras na TPU v4, bem como as melhorias de desempenho da TPU v4 em comparação com a TPU v3.
Sistema de memória
O acesso à memória não uniforme (NUMA) é uma arquitetura de memória de computador para máquinas com vários CPUs. Cada CPU tem acesso direto a um bloco de memória de alta velocidade. Uma CPU e a respetiva memória denominam-se um nó NUMA. Os nós NUMA estão ligados a outros nós NUMA que estão diretamente adjacentes entre si. Uma CPU de um nó NUMA pode aceder à memória noutro nó NUMA, mas este acesso é mais lento do que o acesso à memória num nó NUMA.
O software executado numa máquina com várias CPUs pode colocar os dados necessários para uma CPU no respetivo nó NUMA, o que aumenta a taxa de transferência de memória. Para mais informações sobre NUMA, consulte o artigo Acesso não uniforme à memória na Wikipédia.
Pode tirar partido das vantagens da localidade NUMA associando o seu script de preparação ao nó NUMA 0.
Para ativar a vinculação de nós NUMA:
Instale a ferramenta de linha de comandos numactl. O numactl permite-lhe executar processos com uma política de posicionamento de memória ou agendamento NUMA específica.
$ sudo apt-get update $ sudo apt-get install numactl
Associe o código do script ao nó NUMA 0. Substitua your-training-script pelo caminho para o seu script de preparação.
$ numactl --cpunodebind=0 python3 your-training-script
Ative a vinculação de nós NUMA se:
- Se a sua carga de trabalho tiver uma forte dependência das cargas de trabalho da CPU (por exemplo, classificação de imagens, cargas de trabalho de recomendações), independentemente da framework.
- Se estiver a usar uma versão do tempo de execução da TPU sem o sufixo -pod (por exemplo,
tpu-vm-tf-2.10.0-v4).
Outras diferenças do sistema de memória:
- Os chips TPU v4 têm um espaço de memória HBM unificado de 32 GiB em todo o chip, o que permite uma melhor coordenação entre os dois TensorCores no chip.
- Desempenho de HBM melhorado com as mais recentes normas e velocidades de memória.
- Perfil de desempenho de DMA melhorado com suporte integrado para passos de alto desempenho a granularidades de 512 B.
TensorCores
- O dobro do número de MXUs e uma taxa de relógio mais elevada, que oferecem um máximo de 275 TFLOPS.
- Largura de banda de transposição e permutação 2x.
- Modelo de acesso à memória de carregamento/armazenamento para memória comum (Cmem).
- Largura de banda de carregamento de peso MXU mais rápida e suporte do modo de 8 bits para permitir tamanhos de lotes mais baixos e latência de inferência melhorada.
Interligação entre chips
Seis ligações de interconexão por chip para permitir topologias de rede com diâmetros de rede mais pequenos.
Outro
- Interface PCIE gen3 x16 para anfitrião (ligação direta).
- Modelo de segurança melhorado.
- Eficiência energética melhorada.
Configurações
Um Pod de TPUs v4 é composto por 4096 chips interligados com ligações de alta velocidade reconfiguráveis. A rede flexível da TPU v4 permite-lhe ligar os chips numa fatia do mesmo tamanho de várias formas. Quando cria uma fatia de TPU, especifica a versão da TPU e o número de recursos de TPU de que precisa. Quando cria uma fatia de TPU v4, pode especificar o respetivo tipo e tamanho de uma das seguintes formas: AcceleratorType e AccleratorConfig.
A usar AcceleratorType
Use AcceleratorType quando não estiver a especificar uma topologia. Para configurar TPUs v4
com o AcceleratorType, use a flag --accelerator-type quando criar a fatia de TPU. Defina --accelerator-type como uma string que contém a versão da TPU e o número de TensorCores que quer usar. Por exemplo, para criar uma fatia v4 com 32 TensorCores, usaria --accelerator-type=v4-32.
Use o gcloud compute tpus tpu-vm createcomando
para criar uma fatia de TPU v4 com 512 TensorCores usando a flag --accelerator-type:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
O número após a versão da TPU (v4) especifica o número de TensorCores.
Existem dois TensorCores numa TPU v4, pelo que o número de chips de TPU seria 512/2 = 256.
Para mais informações sobre a gestão de TPUs, consulte o artigo Faça a gestão de TPUs. Para mais informações sobre a arquitetura do sistema da Cloud TPU, consulte o artigo Arquitetura do sistema.
A usar AcceleratorConfig
Use AcceleratorConfig quando quiser personalizar a topologia física
da sua fatia de TPU. Isto é geralmente necessário para o ajuste de desempenho com fatias superiores a 256 chips.
Para configurar as TPUs v4 com o AcceleratorConfig, use as flags --type e --topology. Defina --type para a versão da TPU que quer usar e --topology para a disposição física dos chips da TPU na fatia.
Especifica uma topologia de TPU através de uma tupla de 3 elementos, AxBxC, em que A<=B<=C e A, B, C são
todos <= 4 ou são todos múltiplos inteiros de 4. Os valores A, B e C são as contagens de chips em cada uma das três dimensões. Por exemplo, para criar uma fatia v4 com 16 chips, definiria --type=v4 e --topology=2x2x4.
Use o gcloud compute tpus tpu-vm createcomando
para criar uma fatia de TPU v4 com 128 chips de TPU organizados numa matriz de 4x4x8:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
As topologias em que 2A=B=C ou 2A=2B=C também têm variantes de topologia otimizadas para comunicação total, por exemplo, 4×4×8, 8×8×16 e 12×12×24. Estas são conhecidas como topologias de tori retorcidos.
As ilustrações seguintes mostram algumas topologias comuns de TPUs v4.
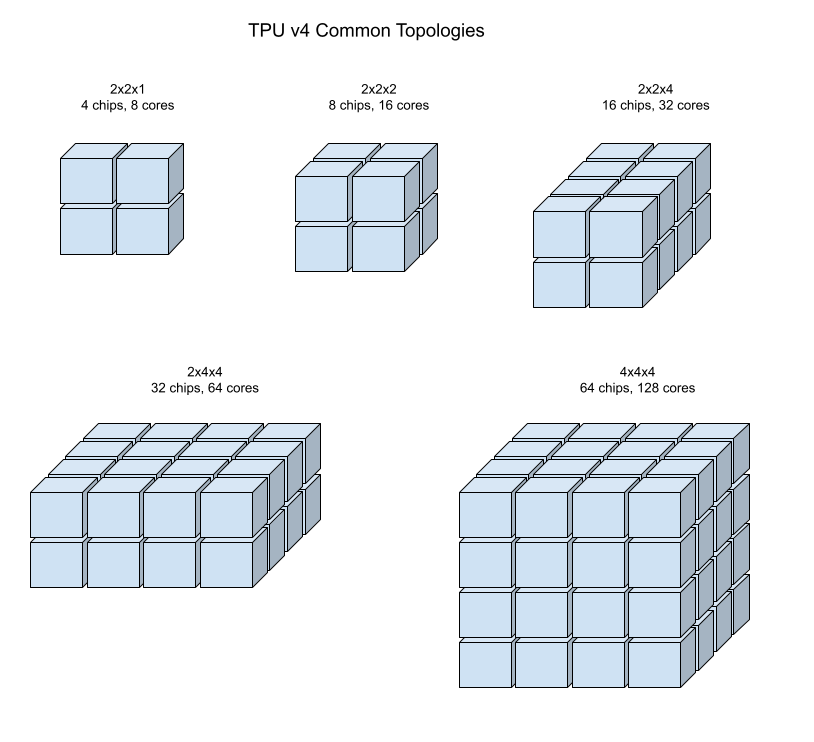
As fatias maiores podem ser criadas a partir de um ou mais "cubos" de chips de 4x4x4.
Para mais informações sobre a gestão de TPUs, consulte o artigo Faça a gestão de TPUs. Para mais informações sobre a arquitetura do sistema da Cloud TPU, consulte o artigo Arquitetura do sistema.
Topologias de toros torcidos
Algumas formas de fatia de toro 3D v4 têm a opção de usar o que é conhecido como uma topologia de toro torcido. Por exemplo, dois cubos v4 podem ser organizados como uma fatia 4x4x8 ou 4x4x8_twisted. As topologias retorcidas oferecem uma largura de banda de bissecção significativamente mais elevada. Por exemplo, uma fatia com a topologia 4x4x8_twisted oferece um aumento teórico de 70% na largura de banda de bissecção em relação a uma fatia 4x4x8 não retorcida. O aumento da largura de banda de bissecção é útil para cargas de trabalho que usam padrões de comunicação globais. As topologias invertidas podem melhorar o desempenho da maioria dos modelos, sendo que os grandes volumes de trabalho de incorporação de TPUs são os que mais beneficiam.
Para cargas de trabalho que usam o paralelismo de dados como a única estratégia de paralelismo, as topologias invertidas podem ter um desempenho ligeiramente melhor. Para os MDIs, o desempenho com uma topologia complexa pode variar consoante o tipo de paralelismo (DP, MP, etc.). A prática recomendada é preparar o seu MDI/CE com e sem uma topologia distorcida para determinar qual oferece o melhor desempenho para o seu modelo. Algumas experiências no modelo MaxText FSDP registaram melhorias de 1 a 2 MFU com uma topologia invertida.
A principal vantagem das topologias retorcidas é que transformam uma topologia de toro assimétrica (por exemplo, 4×4×8) numa topologia simétrica estreitamente relacionada. A topologia simétrica tem muitas vantagens:
- Balanceamento de carga melhorado
- Largura de banda de bissecção mais elevada
- Trajetos de pacotes mais curtos
Estes benefícios traduzem-se, em última análise, num melhor desempenho para muitos padrões de comunicação globais.
O software da TPU suporta toros retorcidos em fatias em que a dimensão de cada dimensão é igual ou o dobro da dimensão mais pequena. Por exemplo, 4x4x8, 4×8×8 ou 12x12x24.
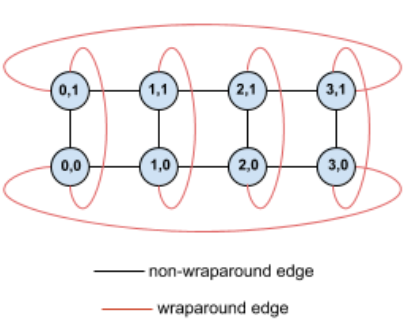
Por exemplo, considere esta topologia de toro 4×2 com TPUs etiquetadas com as respetivas coordenadas (X,Y) na fatia:
Para maior clareza, as arestas neste gráfico de topologia são apresentadas como arestas não direcionadas. Na prática, cada aresta é uma ligação bidirecional entre as TPUs. Referimo-nos às arestas entre um lado desta grelha e o lado oposto como arestas de envolvimento, conforme indicado no diagrama.
Ao alterar esta topologia, obtemos uma topologia de toro torcido 4×2 completamente simétrica:
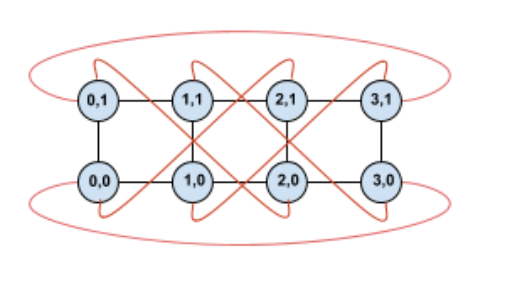
A única diferença entre este diagrama e o anterior são os limites envolventes. Em vez de se ligarem a outra TPU com a mesma coordenada X, foram deslocadas para se ligarem à TPU com a coordenada X+2 mod 4.
A mesma ideia generaliza-se a diferentes tamanhos de dimensões e diferentes números de dimensões. A rede resultante é simétrica, desde que cada dimensão seja igual ou duas vezes o tamanho da dimensão mais pequena.
Consulte usar AcceleratorConfig para ver detalhes sobre como especificar uma configuração de tori retorcido ao criar um TPU na nuvem.
A tabela seguinte mostra as topologias invertidas suportadas e um aumento teórico na largura de banda de bissecção com elas em comparação com as topologias não invertidas.
| Topologia retorcida | Aumento teórico na largura de banda de bisseção em comparação com um toro não retorcido |
|---|---|
| 4×4×8_twisted | Cerca de 70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | Cerca de 40% |
| 8×16×16_twisted |
Variantes de topologia da TPU v4
Algumas topologias que contêm o mesmo número de chips podem ser organizadas de diferentes formas. Por exemplo, uma fatia de TPU com 512 chips (1024 TensorCores) pode ser configurada através das seguintes topologias: 4x4x32, 4x8x16 ou 8x8x8. Uma fatia de TPU com 2048 chips (4096 TensorCores) oferece ainda mais opções de topologia: 4x4x128, 4x8x64, 4x16x32 e 8x16x16.
A topologia predefinida associada a uma determinada quantidade de chips é a mais semelhante a um cubo. Este formato é provavelmente a melhor escolha para o treino de ML paralelo de dados. Outras topologias podem ser úteis para cargas de trabalho com vários tipos de paralelismo (por exemplo, paralelismo de modelos e dados, ou partição espacial de uma simulação). Estas cargas de trabalho têm o melhor desempenho se a topologia corresponder ao paralelismo usado. Por exemplo, colocar o paralelismo do modelo de 4 vias na dimensão X e o paralelismo de dados de 256 vias nas dimensões Y e Z corresponde a uma topologia de 4 x 16 x 16.
Os modelos com várias dimensões de paralelismo têm o melhor desempenho quando as respetivas dimensões de paralelismo são mapeadas para as dimensões de topologia da TPU. Normalmente, estes são grandes modelos de linguagem (GMLs) paralelos de dados e modelos. Por exemplo, para uma fatia de TPU v4 com topologia 8x16x16, as dimensões da topologia de TPU são 8, 16 e 16. É mais eficiente usar o paralelismo de modelos de 8 ou 16 vias (mapeado a uma das dimensões da topologia física da TPU). Um paralelismo de modelos de 4 vias seria subótimo com esta topologia, uma vez que não está alinhado com nenhuma das dimensões da topologia da TPU, mas seria ótimo com uma topologia de 4 x 16 x 32 no mesmo número de chips.
As configurações de TPU v4 consistem em dois grupos: as que têm topologias inferiores a 64 chips (topologias pequenas) e as que têm topologias superiores a 64 chips (topologias grandes).
Topologias pequenas v4
A Cloud TPU suporta as seguintes fatias de TPU v4 com menos de 64 chips, um cubo de 4x4x4. Pode criar estas pequenas topologias v4 através do respetivo nome baseado em TensorCore (por exemplo, v4-32) ou da respetiva topologia (por exemplo, 2x2x4):
| Nome (com base na quantidade de TensorCores) | Número de chips | Topologia |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologias v4 grandes
As fatias de TPU v4 estão disponíveis em incrementos de 64 chips, com formas que são
múltiplos de 4 em todas as três dimensões. As dimensões têm de estar por ordem crescente. A tabela seguinte mostra vários exemplos. Algumas destas topologias são topologias "personalizadas" que só podem ser criadas através das flags --type e --topology, porque existem várias formas de organizar os chips.
| Nome (com base na quantidade de TensorCores) | Número de chips | Topologia |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
topologia personalizada: tem de usar os indicadores --type e --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
topologia personalizada: tem de usar as flags --type e --topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |