TPU v4
이 문서에서는 Cloud TPU v4의 아키텍처와 지원되는 구성을 설명합니다.
시스템 아키텍처
각 TPU v4 칩에는 2개의 TensorCore가 포함됩니다. 각 TensorCore에는 4개의 행렬 곱셈 단위(MXU), 벡터 단위, 스칼라 단위가 있습니다. 다음 표는 v4 TPU Pod의 주요 사양을 보여줍니다.
| 주요 사양 | v4 포드 값 |
|---|---|
| 칩당 최고 컴퓨팅 | 275테라플롭(bf16 또는 int8) |
| HBM2 용량 및 대역폭 | 32GiB, 1,200GBps |
| 측정된 최소/평균/최대 전력 | 90/170/192W |
| TPU Pod 크기 | 칩 4,096개 |
| 상호 연결 토폴로지 | 3D 메시 |
| 포드당 최고 컴퓨팅 | 1.1엑사플롭(bf16 또는 int8) |
| 포드당 올리듀스 대역폭 | 1.1PB/초 |
| 포드당 바이섹션 대역폭 | 24TB/초 |
다음 다이어그램은 TPU v4 칩을 보여줍니다.
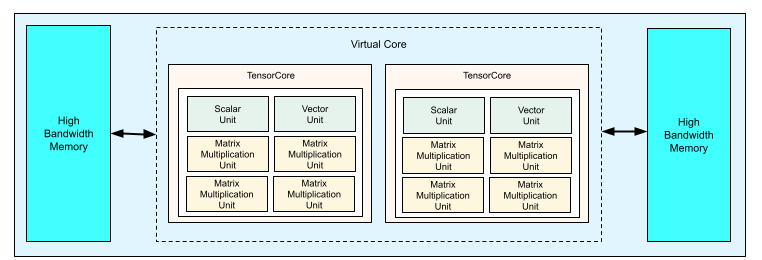
TPU v4의 아키텍처 세부정보와 성능 특성에 대한 자세한 내용은 TPU v4: 임베딩을 위한 하드웨어 지원이 포함된 머신러닝용 광학 재구성 가능 슈퍼컴퓨터를 참조하세요.
3D 메시 및 3D 토러스
v4 TPU는 가장 가까이 인접한 칩에 3차원으로 직접 연결하여 네트워킹 연결의 3D 메시를 형성합니다. 토폴로지 AxBxC가 2A=B=C 또는 2A=2B=C이고, 각 차원이 4의 배수인 슬라이스에서 연결을 3D 토러스로 구성할 수 있습니다. 예: 4x4x8, 4x8x8 또는 12x12x24 일반적으로 3D 토러스 구성의 성능이 3D 메시 구성보다 우수합니다. 자세한 내용은 왜곡 토러스 토폴로지를 참조하세요.
TPU v4와 v3의 성능 이점 비교
이 섹션에서는 TPU v4에서 샘플 학습 스크립트를 실행하는 메모리 효율적인 방법과, TPU v3과 비교했을 때 TPU v4의 성능 향상 내용을 함께 보여줍니다.
메모리 시스템
비균일 메모리 액세스(NUMA)는 CPU가 여러 개 있는 머신을 위한 컴퓨터 메모리 아키텍처입니다. 각 CPU는 고속 메모리 블록에 직접 액세스합니다. CPU와 해당 메모리를 NUMA 노드라고 부릅니다. NUMA 노드는 서로 인접한 다른 NUMA 노드에 연결됩니다. NUMA 노드의 CPU가 다른 NUMA 노드의 메모리에 액세스할 수 있지만 이러한 액세스는 NUMA 노드 내의 메모리에 액세스할 때보다 느립니다.
다중 CPU 머신에서 실행되는 소프트웨어는 해당 NUMA 노드 내에서 CPU에 필요한 데이터를 배치하여 메모리 처리량을 늘릴 수 있습니다. NUMA에 대한 자세한 내용은 Wikipedia에서 비균일 메모리 액세스를 참조하세요.
학습 스크립트를 NUMA 노드 0에 바인딩하여 NUMA 지역 이점을 활용할 수 있습니다.
NUMA 노드 바인딩 사용을 설정하려면 다음 안내를 따릅니다.
numactl 명령줄 도구를 설치합니다. numactl을 사용하면 특정 NUMA 스케줄링 또는 메모리 배치 정책을 사용해서 프로세스를 실행할 수 있습니다.
$ sudo apt-get update $ sudo apt-get install numactl
스크립트 코드를 NUMA 노드 0에 바인딩합니다. your-training-script를 학습 스크립트의 경로로 바꿉니다.
$ numactl --cpunodebind=0 python3 your-training-script
다음과 같은 경우 NUMA 노드 바인딩을 사용 설정합니다.
- 프레임워크에 관계없이 워크로드가 CPU 워크로드(예: 이미지 분류, 권장사항 워크로드)에 크게 의존하는 경우
- 포드 서픽스가 없는 TPU 런타임 버전을 사용하는 경우(예:
tpu-vm-tf-2.10.0-v4)
기타 메모리 시스템 차이:
- v4 TPU 칩은 전체 칩에서 통합된 32GiB HBM 메모리 공간을 가지므로 두 개의 온칩 TensorCore 간에 더 효과적으로 조정할 수 있습니다.
- 최신 메모리 표준 및 속도를 사용하여 HBM 성능을 개선했습니다.
- 512B 단위로 고성능 스트라이딩을 기본적으로 지원하는 DMA 성능 프로필이 향상되었습니다.
TensorCores
- MXU 수의 두 배이고 클록 속도는 최대 TFLOPS 275개를 제공합니다.
- 2x 전치 및 치환 대역폭
- Common Memory(Cmem)의 부하 저장 메모리 액세스 모델
- 더 빠른 MXU 가중치 로드 대역폭 및 8비트 모드 지원으로 배치 크기를 줄이고 추론 지연 시간을 개선할 수 있습니다.
칩 간 상호 연결
네트워크 지름이 작은 네트워크 토폴로지를 사용 설정하기 위한 칩당 6개의 상호 연결 링크입니다.
기타
- 호스팅할 x16 PCIE gen3 인터페이스(직접 연결)입니다.
- 보안 모델이 향상되었습니다.
- 에너지 효율이 개선되었습니다.
구성
TPU v4 Pod는 재구성이 가능한 고속 링크로 상호 연결된 4,096개의 칩으로 구성되어 있습니다. TPU v4의 유연한 네트워킹을 사용하면 다양한 방식으로 칩을 동일한 크기의 슬라이스로 연결할 수 있습니다. TPU 슬라이스를 만들 때 TPU 버전과 필요한 TPU 리소스 수를 지정합니다. TPU v4 슬라이스를 만들 때 AcceleratorType 및 AccleratorConfig 두 가지 방법 중 하나로 유형과 크기를 지정할 수 있습니다.
AcceleratorType 사용
토폴로지를 지정하지 않는 경우 AcceleratorType을 사용합니다. AcceleratorType을 사용하여 v4 TPU를 구성하려면 TPU 슬라이스를 만들 때 --accelerator-type 플래그를 사용합니다. --accelerator-type을 TPU 버전과 사용하려는 TensorCore 수를 포함하는 문자열로 설정합니다. 예를 들어 TensorCore 32개가 있는 v4 슬라이스를 만들려면 --accelerator-type=v4-32를 사용합니다.
--accelerator-type 플래그를 사용하여 512개의 TensorCore 512개로 구성된 v4 TPU 슬라이스를 만들려면 gcloud compute tpus tpu-vm create 명령어를 사용합니다.
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
TPU 버전 다음의 번호(v4)는 TensorCore 수를 지정합니다.
v4 TPU에는 2개의 TensorCore가 있으므로 TPU 칩 수는 512/2 = 256이 됩니다.
TPU 관리에 대한 자세한 내용은 TPU 관리를 참조하세요. Cloud TPU의 시스템 아키텍처에 대한 자세한 내용은 시스템 아키텍처를 참조하세요.
AcceleratorConfig 사용
TPU 슬라이스의 물리적 토폴로지를 맞춤설정하려면 AcceleratorConfig를 사용합니다. 이는 일반적으로 256개 칩을 초과하는 슬라이스를 사용하여 성능을 조정하는 데 필요합니다.
AcceleratorConfig를 사용하여 v4 TPU를 구성하려면 --type 및 --topology 플래그를 사용합니다. --type을 사용할 TPU 버전으로 설정하고 --topology를 Pod 슬라이스에 있는 TPU 칩의 물리적 배열로 설정합니다.
3튜플인 AxBxC를 사용하여 TPU 토폴로지를 지정합니다. 여기서 A<=B<=C이고 A, B, C는 모두 <=4이거나 4의 모든 정수 배수입니다. A, B, C 값은 3개 차원 각각의 칩 수입니다. 예를 들어 칩이 16개 있는 v4 슬라이스를 만들려면 --type=v4 및 --topology=2x2x4를 설정합니다.
4x4x8 배열로 구성된 128개의 TPU 칩을 사용하는 v4 TPU 슬라이스를 만들려면 gcloud compute tpus tpu-vm create 명령어를 사용합니다.
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
2A=B=C 또는 2A=2B=C인 토폴로지에는 전체 통신에 최적화된 토폴로지 변이(예: 4×4×8, 8×8×16, 12×12×24)도 있습니다. 이러한 토폴로지를 왜곡 토러스라고 합니다.
다음 이미지는 몇 가지 일반적인 TPU v4 토폴로지를 보여줍니다.
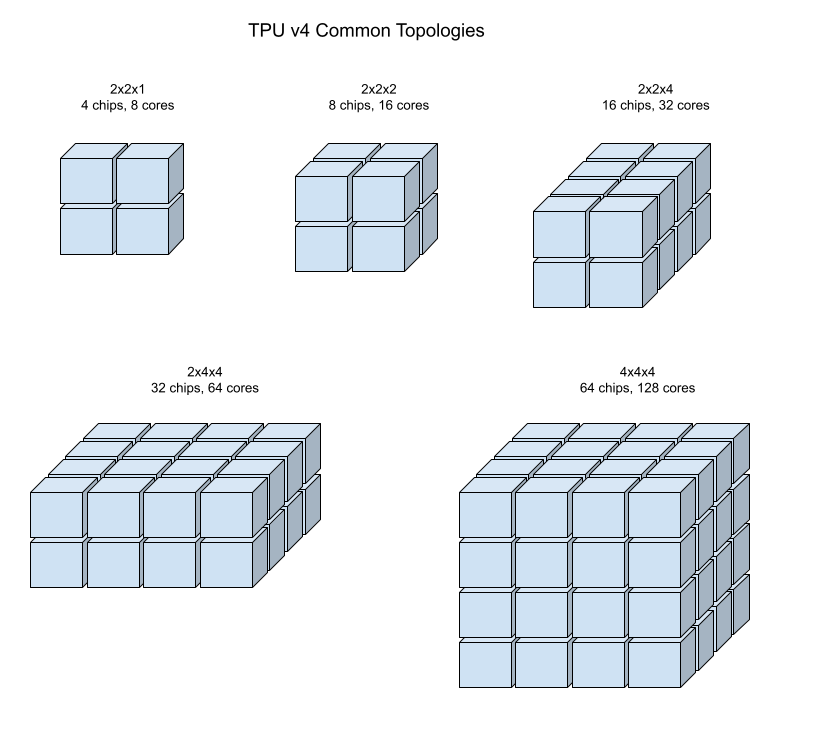
큰 슬라이스는 하나 이상의 4x4x4 '큐브'의 칩에서 빌드할 수 있습니다.
TPU 관리에 대한 자세한 내용은 TPU 관리를 참조하세요. Cloud TPU의 시스템 아키텍처에 대한 자세한 내용은 시스템 아키텍처를 참조하세요.
왜곡 토러스 토폴로지
일부 v4 3D 토러스 슬라이스 형태에서는 왜곡 토러스 토폴로지라고 하는 구성을 사용할 수 있는 옵션이 있습니다. 예를 들어 v4 큐브 두 개를 4x4x8 슬라이스 또는 4x4x8_twisted로 정렬할 수 있습니다. 왜곡 토폴로지는 훨씬 높은 바이섹션 대역폭을 제공합니다. 예를 들어 4x4x8_twisted 토폴로지를 사용하는 슬라이스는 비트위스티드 방식의 4x4x8 슬라이스보다 이론적으로 바이섹션 대역폭이 70% 더 높습니다. 증가된 바이섹션 대역폭은 전역 통신 패턴을 사용하는 워크로드에 유용합니다. 왜곡 토폴로지는 대부분의 모델에서 성능을 개선하며 대규모 TPU 임베딩 워크로드가 가장 큰 이점을 누립니다.
유일한 동시 로드 전략으로 데이터 동시 로드를 사용하는 워크로드의 경우 왜곡 토폴로지의 성능이 약간 더 높을 수 있습니다. LLM의 경우 왜곡 토폴로지를 사용하는 성능은 동시 로드 유형(DP, MP 등)에 따라 다를 수 있습니다. 가장 좋은 방법은 LLM을 왜곡 토폴로지에 관계없이 학습시켜 모델에 가장 적합한 성능을 제공하는 것입니다. FSDP MaxText 모델의 일부 실험에서는 왜곡 토폴로지를 사용하여 1~2MFU를 개선했습니다.
왜곡 토폴로지의 주요 이점은 비대칭 토러스 토폴로지(예: 4×4×8)를 밀접하게 관련된 대칭 토폴로지로 변환한다는 점입니다. 대칭 토폴로지에는 다음과 같은 많은 이점이 있습니다.
- 부하 분산 개선
- 더 높은 바이섹션 대역폭
- 더 짧은 패킷 경로
이러한 이점은 결국 다양한 전역 통신 패턴에서 성능 향상에 기여합니다.
TPU 소프트웨어는 각 차원의 크기가 가장 작은 차원 크기와 같거나 두 배인 슬라이스(예: 4x4x8, 4×8×8 또는 12x12x24)에서 왜곡 토러스를 지원합니다.
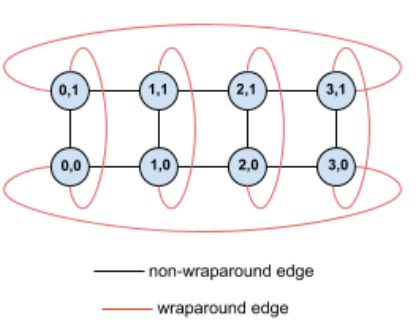
예를 들어 TPU에 슬라이스의 (X,Y) 좌표로 라벨이 지정된 다음과 같은 4×2 토러스 토폴로지를 살펴보세요.
이 토폴로지 그래프의 변은 명확성을 위해 방향이 없는 변으로 표시됩니다. 실제로는 각 변은 TPU 간의 양방향 연결입니다. 다이어그램에 표시된 것처럼 이 그리드의 한 쪽과 반대쪽을 잇는 변을 순환 변이라고 합니다.
이 토폴로지를 비틀면 완전히 대칭적인 4×2 왜곡 토폴로지가 형성됩니다.
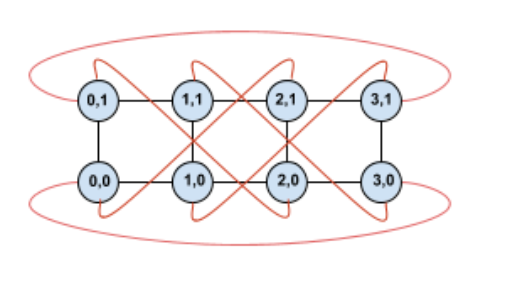
이 다이어그램과 이전 다이어그램의 차이점은 Y 순환 변입니다. X 좌표가 동일한 다른 TPU에 연결하는 대신 좌표가 X+2 mod 4인 TPU에 연결하도록 변경되었습니다.
이 아이디어는 다른 차원 크기 및 다른 차원 수에도 일반화됩니다. 각 차원이 가장 작은 차원 크기와 같거나 두 배이면 대칭적인 네트워크가 형성됩니다.
Cloud TPU를 만들 때 왜곡 토러스 구성을 지정하는 방법에 대한 자세한 내용은 AcceleratorConfig 사용을 참조하세요.
다음 표에서는 지원되는 왜곡 토폴로지 및 비왜곡 토폴로지와 비교한 이론적인 바이섹션 대역폭 증가를 보여줍니다.
| 왜곡 토폴로지 | 비왜곡 토러스와 비교한 이론적인 바이섹션 대역폭 증가 |
|---|---|
| 4×4×8_twisted | ~70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
TPU v4 토폴로지 변이
동일한 수의 칩을 포함하는 일부 토폴로지는 다양한 방식으로 정렬할 수 있습니다. 예를 들어 512개 칩이 포함된 TPU 슬라이스(TensorCore 1,024개)는 4x4x32, 4x8x16, 8x8x8 토폴로지를 사용하여 구성할 수 있습니다. 2,048개의 칩이 포함된 TPU 슬라이스(TensorCore 4,096개)는 4x4x128, 4x8x64, 4x16x32, 8x16x16 등 더 많은 토폴로지 옵션을 제공합니다.
지정된 칩 수와 연결된 기본 토폴로지는 큐브와 가장 유사한 토폴로지입니다. 이 형태는 데이터 병렬 ML 학습에 가장 적합할 수 있습니다. 다른 토폴로지는 여러 종류의 동시 로드가 있는 워크로드(예: 모델 및 데이터 동시 로드 또는 시뮬레이션의 공간 분할)에 유용할 수 있습니다. 이러한 워크로드는 토폴로지가 사용된 동시 로드와 일치할 때 최고의 성능을 발휘합니다. 예를 들어 X 차원에 4방향 모델 동시 로드를 배치하고 Y 및 Z차원에 256방향 데이터 동시 로드를 배치하면 4x16x16 토폴로지와 일치합니다.
여러 차원의 동시 로드가 있는 모델은 TPU 토폴로지 차원에 매핑된 동시 로드 차원에서 가장 잘 작동합니다. 일반적으로 데이터 및 모델 병렬 대규모 언어 모델(LLM)이 여기에 해당합니다. 예를 들어 토폴로지 8x16x16이 있는 TPU v4 슬라이스의 경우 토폴로지 차원은 8, 16, 16입니다. 8방향 또는 16방향 모델 동시 로드(물리적 토폴로지 차원 중 하나에 매핑)를 사용하면 성능이 더 개선됩니다. 4방향 모델 동시 로드는 TPU 토폴로지 차원에 맞게 정렬되지 않으므로 이 토폴로지의 차선입니다. 칩 수가 동일한 4x16x32 토폴로지를 사용하는 것이 최적의 방법입니다.
TPU v4 구성은 64개 칩보다 작은 토폴로지(소형 토폴로지)와 64개 칩보다 큰 토폴로지(대형 토폴로지)가 있는 그룹 두 개로 구성됩니다.
작은 v4 토폴로지
Cloud TPU는 64개 칩이 있는 4x4x4 큐브보다 작은 다음 TPU v4 슬라이스를 지원합니다. 다음과 같은 TensorCore 기반 이름(예: v4-32) 또는 토폴로지(예: 2x2x4)를 사용하여 이러한 작은 v4 토폴로지를 만들 수 있습니다.
| 이름(TensorCore 수 기반) | 칩 수 | 토폴로지 |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
대형 v4 토폴로지
TPU v4 슬라이스는 64개의 칩 단위로 제공되며, 세 차원 모두에서 4의 배수인 형태를 띱니다. 차원은 오름차순이어야 합니다. 다음 표에 몇 가지 예시가 나와 있습니다. 이러한 토폴로지 중 일부는 --type 및 --topology 플래그를 통해서만 만들 수 있는 '커스텀' 토폴로지입니다. 칩을 정렬하는 방법이 두 개 이상 있기 때문입니다.
| 이름(TensorCore 수 기반) | 칩 수 | 토폴로지 |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
커스텀 토폴로지: --type 및 --topology 플래그를 사용해야 함 |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
커스텀 토폴로지: --type 및 --topology 플래그를 사용해야 함 |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |