TPU v3
本文档介绍了 Cloud TPU v3 的架构和支持的配置。
系统架构
每个 v3 TPU 芯片包含两个 TensorCore。每个 TensorCore 都有两个矩阵乘法单元 (MXU)、一个向量单元和一个标量单元。下表展示了 v3 TPU Pod 的主要规范及其值。
| 主要规范 | v3 Pod 值 |
|---|---|
| 每个芯片峰值计算能力 | 123 teraflop (bf16) |
| HBM2 容量和带宽 | 32 GiB、900 GBps |
| 测得的最小/平均/最大功率 | 123/220/262 W |
| TPU Pod 大小 | 1024 个芯片 |
| 互连拓扑 | 2D 环面 |
| 每个 Pod 的峰值计算能力 | 126 petaflop (bf16) |
| 每个 Pod 的 All-reduce 带宽 | 340 TB/s |
| 每个 Pod 的对分带宽 | 6.4 TB/s |
下图展示了 TPU v3 芯片。
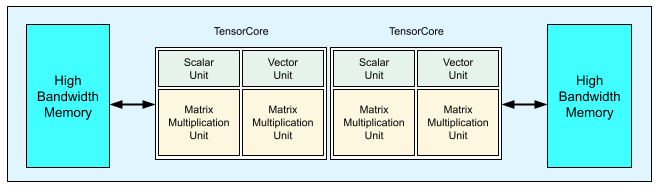
如需了解 TPU v3 的架构详情和性能特征,请参阅用于训练深度神经网络的领域专用超级计算机。
TPU v3 相对于 v2 的性能优势
TPU v3 配置中增加的每个 TensorCore 的 FLOPS 和内存容量可以通过以下方式提高模型的性能:
对于计算受限的模型,TPU v3 配置可为每个 TensorCore 提供明显的性能优势。如果采用 TPU v2 配置且内存受限的模型在采用 TPU v3 配置时同样也受内存限制,则可能无法实现同等的性能提升。
如果采用 TPU v2 配置时,内存无法容纳数据,则 TPU v3 可以提供改进的性能并减少中间值的重计算(再物化)。
TPU v3 配置可以运行批次大小不适合 TPU v2 配置的新模型。例如,TPU v3 可能允许更深的 ResNet 模型和使用 RetinaNet 的较大图片。
因训练步骤等待输入而在 TPU v2 上几乎成为受限于输入(“馈入”)的模型,在 Cloud TPU v3 中也可能会受限于输入。流水线性能指南可以帮助解决馈入问题。
配置
TPU v3 Pod 由 1024 个芯片组成,这些芯片通过高速链路相互连接。如需创建 TPU v3 设备或切片,请在 TPU 创建命令 (gcloud compute tpus tpu-vm) 中使用 --accelerator-type 标志。您可以通过指定 TPU 版本和 TPU 核心数来指定加速器类型。例如,对于单个 v3 TPU,请使用 --accelerator-type=v3-8。对于具有 128 个 TensorCore 的 v3 切片,请使用 --accelerator-type=v3-128。
下表列出了支持的 v3 TPU 类型:
| TPU 版本 | 支持结束 |
|---|---|
| v3-8 | (结束日期尚未确定) |
| v3-32 | (结束日期尚未确定) |
| v3-128 | (结束日期尚未确定) |
| v3-256 | (结束日期尚未确定) |
| v3-512 | (结束日期尚未确定) |
| v3-1024 | (结束日期尚未确定) |
| v3-2048 | (结束日期尚未确定) |
以下命令展示了如何创建具有 128 个 TensorCore 的 v3 TPU 切片:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
如需详细了解如何管理 TPU,请参阅管理 TPU。如需详细了解 Cloud TPU 的系统架构,请参阅系统架构。