TPU v3
Ce document décrit l'architecture et les configurations compatibles de Cloud TPU v3.
Architecture du système
Chaque puce TPU v3 contient deux TensorCores. Chaque TensorCore possède deux unités de multiplication de matrices (MXU), une unité vectorielle et une unité scalaire. Le tableau suivant présente les principales spécifications et leurs valeurs pour un pod TPU v3.
| Principales caractéristiques | Valeurs des pods v3 |
|---|---|
| Calcul maximal par puce | 123 téraflops (bf16) |
| Capacité et bande passante de la mémoire HBM2 | 32 Gio, 900 Gbit/s |
| Puissance minimale/moyenne/maximale mesurée | 123/220/262 W |
| Taille du pod TPU | 1 024 chips |
| Topologie d'interconnexion | Tore 2D |
| Calcul maximal par pod | 126 pétaflops (bf16) |
| Bande passante de réduction globale par pod | 340 To/s |
| Bande passante bissectionnelle par pod | 6,4 To/s |
Le schéma suivant illustre un chip TPU v3.
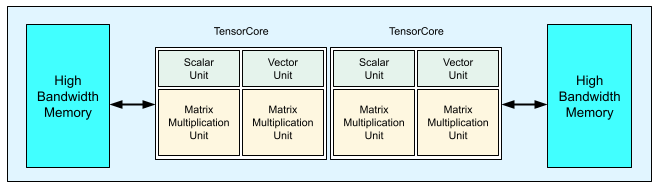
Les détails d'architecture et les caractéristiques de performance des TPU v3 sont présentés dans l'article A Domain Specific Supercomputer for Training Deep Neural Networks (Super-ordinateur spécifique au domaine pour l'entraînement de réseaux de neurones profonds).
Avantages en termes de performances des TPU v3 par rapport aux TPU v2
L'augmentation de FLOPS par TensorCore et de la capacité de mémoire dans les configurations TPU v3 peut améliorer les performances de vos modèles des manières suivantes:
Les configurations TPU v3 offrent des avantages significatifs en termes de performances par TensorCore pour les modèles subordonnés aux calculs. Les modèles subordonnés à la mémoire sur les configurations TPU v2 peuvent ne pas bénéficier de cette même amélioration de performances s'ils sont également subordonnés à la mémoire sur les configurations TPU v3.
En cas de capacité de mémoire insuffisante sur les configurations TPU v2, les TPU v3 peuvent améliorer les performances et réduire le recalcul des valeurs intermédiaires (rematérialisation).
Les configurations TPU v3 peuvent exécuter de nouveaux modèles avec des tailles de lots supérieures à celles acceptées par les configurations TPU v2. Par exemple, les TPU v3 acceptent des modèles ResNet plus profonds et des images plus grandes avec RetinaNet.
Les modèles qui, avec un TPU v2, sont presque subordonnés au flux d'entrée ("infeed") parce que certaines étapes d'entraînement attendent une entrée, peuvent également être subordonnés aux entrées avec Cloud TPU v3. Le guide pour un pipeline performant peut vous aider à résoudre les problèmes de flux d'entrée.
Configurations
Un pod TPU v3 est composé de 1 024 puces interconnectées par des liaisons à haut débit. Pour créer un appareil ou une tranche TPU v3, utilisez l'indicateur --accelerator-type dans la commande de création de TPU (gcloud compute tpus tpu-vm). Vous spécifiez le type d'accélérateur en spécifiant la version de TPU et le nombre de cœurs TPU. Par exemple, pour un seul TPU v3, utilisez --accelerator-type=v3-8. Pour une tranche v3 avec 128 TensorCores, utilisez --accelerator-type=v3-128.
Le tableau suivant répertorie les types de TPU v3 compatibles:
| Version du TPU | Fin de la compatibilité |
|---|---|
| v3-8 | (Date de fin pas encore fixée) |
| v3-32 | (Date de fin pas encore fixée) |
| v3-128 | (Date de fin pas encore fixée) |
| v3-256 | (Date de fin pas encore fixée) |
| v3-512 | (Date de fin pas encore fixée) |
| v3-1024 | (Date de fin pas encore fixée) |
| v3-2048 | (Date de fin pas encore fixée) |
La commande suivante montre comment créer une tranche TPU v3 avec 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
Pour en savoir plus sur la gestion des TPU, consultez Gérer les TPU. Pour en savoir plus sur l'architecture système de Cloud TPU, consultez la page Architecture du système.