TPU v3
En este documento se describe la arquitectura y las configuraciones admitidas de Cloud TPU v3.
Arquitectura del sistema
Cada chip de TPU v3 contiene dos TensorCores. Cada Tensor Core tiene dos unidades de multiplicación de matrices (MXUs), una unidad vectorial y una unidad escalar. En la siguiente tabla se muestran las especificaciones clave y sus valores para un pod de TPU v3.
| Especificaciones principales | Valores de los pods de la versión 3 |
|---|---|
| Rendimiento máximo por chip | 123 teraflops (bf16) |
| Capacidad y ancho de banda de HBM2 | 32 GiB, 900 GB/s |
| Potencia mínima, media y máxima medidas | 123/220/262 W |
| Tamaño del pod de TPUs | 1024 chips |
| Topología de interconexión | Toroide bidimensional |
| Computación máxima por pod | 126 petaflops (bf16) |
| Ancho de banda de All-reduce por pod | 340 TB/s |
| Ancho de banda de bisección por pod | 6,4 TB/s |
En el siguiente diagrama se muestra un chip de TPU v3.
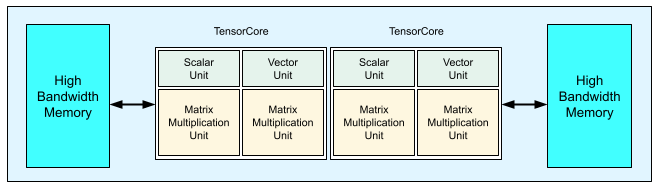
Los detalles de la arquitectura y las características de rendimiento de la TPU v3 están disponibles en A Domain Specific Supercomputer for Training Deep Neural Networks (Un superordenador específico de un dominio para entrenar redes neuronales profundas).
Ventajas de rendimiento de la versión 3 de TPU con respecto a la versión 2
El aumento de FLOPS por Tensor Core y de capacidad de memoria en las configuraciones de TPU v3 puede mejorar el rendimiento de tus modelos de las siguientes formas:
Las configuraciones de TPU v3 ofrecen importantes ventajas de rendimiento por Tensor Core para los modelos con limitaciones de computación. Es posible que los modelos con limitaciones de memoria en configuraciones de TPU v2 no logren la misma mejora del rendimiento si también tienen limitaciones de memoria en configuraciones de TPU v3.
En los casos en los que los datos no caben en la memoria de las configuraciones de TPU v2, TPU v3 puede ofrecer un mejor rendimiento y reducir el recálculo de los valores intermedios (rematerialización).
Las configuraciones de TPU v3 pueden ejecutar modelos nuevos con tamaños de lote que no cabían en las configuraciones de TPU v2. Por ejemplo, la TPU v3 podría permitir modelos de ResNet más profundos e imágenes más grandes con RetinaNet.
Los modelos que casi dependen de la entrada ("infeed") en la TPU v2 porque los pasos de entrenamiento esperan la entrada también pueden depender de la entrada con la TPU v3 de Cloud. La guía de rendimiento de la canalización puede ayudarte a resolver problemas de feeds.
Configuraciones
Un pod de TPU v3 se compone de 1024 chips interconectados con enlaces de alta velocidad. Para crear un dispositivo o una porción de TPU v3, usa la marca --accelerator-type
en el comando de creación de TPU (gcloud compute tpus tpu-vm). Especifica el tipo de acelerador indicando la versión de TPU y el número de núcleos de TPU. Por ejemplo, para una sola TPU v3, usa --accelerator-type=v3-8. Para un segmento de la versión 3 con 128 Tensor Cores, usa
--accelerator-type=v3-128.
En la siguiente tabla se indican los tipos de TPU v3 admitidos:
| Versión de TPU | Fin de la asistencia |
|---|---|
| v. 3-8 | (Fecha de finalización aún no definida) |
| v. 3-32 | (Fecha de finalización aún no definida) |
| v3-128 | (Fecha de finalización aún no definida) |
| v3-256 | (Fecha de finalización aún no definida) |
| v3-512 | (Fecha de finalización aún no definida) |
| v3-1024 | (Fecha de finalización aún no definida) |
| v3-2048 | (Fecha de finalización aún no definida) |
El siguiente comando muestra cómo crear un segmento de TPU v3 con 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
Para obtener más información sobre cómo gestionar las TPUs, consulta Gestionar TPUs. Para obtener más información sobre la arquitectura del sistema de las TPU de Cloud, consulta Arquitectura del sistema.