TPU v3
This document describes the architecture and supported configurations of Cloud TPU v3.
System architecture
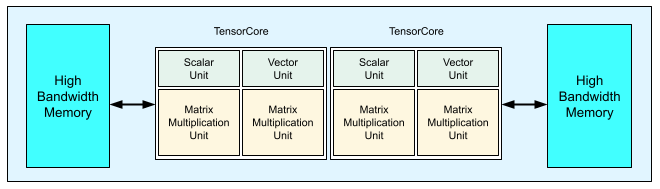
Each v3 TPU chip contains two TensorCores. Each TensorCore has two matrix-multiply units (MXUs), a vector unit, and a scalar unit. The following table shows the key specifications and their values for a v3 TPU Pod.
| Key specifications | v3 Pod values |
|---|---|
| Peak compute per chip | 123 teraflops (bf16) |
| HBM2 capacity and bandwidth | 32 GiB, 900 GBps |
| Measured min/mean/max power | 123/220/262 W |
| TPU Pod size | 1024 chips |
| Interconnect topology | 2D torus |
| Peak compute per Pod | 126 petaflops (bf16) |
| All-reduce bandwidth per Pod | 340 TB/s |
| Bisection bandwidth per Pod | 6.4 TB/s |
The following diagram illustrates a TPU v3 chip.
Architectural details and performance characteristics of TPU v3 are available in A Domain Specific Supercomputer for Training Deep Neural Networks.
Performance benefits of TPU v3 over v2
The increased FLOPS per TensorCore and memory capacity in TPU v3 configurations can improve the performance of your models in the following ways:
TPU v3 configurations provide significant performance benefits per TensorCore for compute-bound models. Memory-bound models on TPU v2 configurations might not achieve this same performance improvement if they are also memory-bound on TPU v3 configurations.
In cases where data does not fit into memory on TPU v2 configurations, TPU v3 can provide improved performance and reduced recomputation of intermediate values (rematerialization).
TPU v3 configurations can run new models with batch sizes that did not fit on TPU v2 configurations. For example, TPU v3 might allow deeper ResNet models and larger images with RetinaNet.
Models that are nearly input-bound ("infeed") on TPU v2 because training steps are waiting for input might also be input-bound with Cloud TPU v3. The pipeline performance guide can help you resolve infeed issues.
Configurations
A TPU v3 Pod is composed of 1024 chips interconnected with high-speed links. To
create a TPU v3 device or slice, use the --accelerator-type
flag in the TPU creation command (gcloud compute tpus tpu-vm). You specify the accelerator type by specifying the
TPU version and the number of TPU cores. For example, for a single v3 TPU, use
--accelerator-type=v3-8. For a v3 slice with 128 TensorCores, use
--accelerator-type=v3-128.
The following table lists the supported v3 TPU types:
| TPU version | Support ends |
|---|---|
| v3-8 | (End date not yet set) |
| v3-32 | (End date not yet set) |
| v3-128 | (End date not yet set) |
| v3-256 | (End date not yet set) |
| v3-512 | (End date not yet set) |
| v3-1024 | (End date not yet set) |
| v3-2048 | (End date not yet set) |
The following command shows how to create a v3 TPU slice with 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
For more information about managing TPUs, see Manage TPUs. For more information about the system architecture of Cloud TPU, see System architecture.