Konfigurasi TPU
Konfigurasi TPU v5p
Pod TPU v5p terdiri dari chip 8960 yang saling terhubung dengan link berkecepatan tinggi yang dapat dikonfigurasi ulang. Jaringan fleksibel TPU v5p memungkinkan Anda menghubungkan
chip dalam potongan berukuran sama dengan berbagai cara. Saat membuat potongan TPU menggunakan perintah gcloud compute tpus tpu-vm create, tentukan
jenis dan bentuknya menggunakan parameter AcceleratorType
atau AcceleratorConfig.
Tabel berikut menunjukkan bentuk irisan tunggal paling umum yang didukung dengan v5p, ditambah sebagian besar (tetapi tidak semua) bentuk kubus penuh yang lebih besar dari 1 kubus. Bentuk v5p maksimum adalah 16x16x24 (6.144 chip, 96 kubus).
| Bentuk Irisan | Ukuran VM | # Core | # Chip | # Komputer | # Kubus | Mendukung Twisted? |
| 2x2x1 | Host penuh | 8 | 4 | 1 | T/A | T/A |
| 2x2x2 | Host penuh | 16 | 8 | 2 | T/A | T/A |
| 2x4x4 | Host penuh | 64 | 32 | 8 | T/A | T/A |
| 4x4x4 | Host penuh | 128 | 64 | 16 | 1 | T/A |
| 4x4x8 | Host penuh | 256 | 128 | 32 | 2 | Ya |
| 4x8x8 | Host penuh | 512 | 256 | 64 | 4 | Ya |
| 8x8x8 | Host penuh | 1024 | 512 | 128 | 8 | T/A |
| 8x8x16 | Host penuh | 2048 | 1024 | 256 | 16 | Ya |
| 8x16x16 | Host penuh | 4096 | 2048 | 512 | 32 | Ya |
| 16x16x16 | Host penuh | 8192 | 4096 | 1024 | 64 | T/A |
| 16x16x24 | Host penuh | 12288 | 6144 | 1536 | 96 | T/A |
Pelatihan irisan tunggal didukung hingga 6.144 chip. Ini dapat diperluas hingga {i>chip<i} 18432 menggunakan Multislice. Lihat Ringkasan Multislice Cloud TPU untuk mengetahui detail Multislice.
Menggunakan parameter AcceleratorType
Saat mengalokasikan resource TPU, Anda menggunakan argumen --accelerator-type untuk menentukan jumlah TensorCore dalam sebuah slice. --accelerator-type adalah
string berformat
"v$VERSION_NUMBERp-$CORES_COUNT".
Misalnya, v5p-32 menentukan slice TPU v5p dengan 32 TensorCore (16 chip).
Guna menyediakan TPU untuk tugas pelatihan v5p, gunakan salah satu jenis akselerator berikut di permintaan pembuatan CLI atau TPU API Anda:
- V5p-8
- v5p-16
- v5p-32
- v5p-64
- v5p-128 (satu kubus/rak penuh)
- v5p-256 (2 kubus)
- V5p-512
- v5p-1024 ... v5p-12288
Menggunakan parameter AcceleratorConfig
Untuk versi Cloud TPU v5p dan yang lebih baru, AcceleratorConfig
digunakan dengan cara yang hampir sama dengan Cloud TPU v4
Perbedaannya adalah
bukan menentukan jenis TPU sebagai --type=v4, Anda menetapkannya sebagai
versi TPU yang Anda gunakan (misalnya, --type=v5p untuk rilis v5p).
Ketahanan ICI Cloud TPU
Ketahanan ICI membantu meningkatkan fault tolerance link optik dan tombol sirkuit optik (OCS) yang menghubungkan TPU antar-kubus. (Koneksi ICI dalam kubus menggunakan link tembaga yang tidak terpengaruh). Ketahanan ICI memungkinkan koneksi ICI dirutekan di sekitar kesalahan OCS dan ICI optik. Hasilnya, hal ini meningkatkan ketersediaan penjadwalan slice TPU, dengan kompromi dari penurunan sementara pada performa ICI.
Serupa dengan Cloud TPU v4, ketahanan ICI diaktifkan secara default untuk slice v5p yang berupa satu kubus atau lebih besar:
- v5p-128 saat menentukan jenis aklerator
- 4x4x4 saat menentukan konfigurasi akselerator
Properti VM, host, dan slice
| Properti | Nilai dalam TPU |
| # chip v5p | 4 |
| # vCPU | 208 (hanya separuh yang dapat digunakan jika menggunakan binding NUMA untuk menghindari penalti performa lintas-NUMA) |
| RAM (GB) | 448 (hanya separuh yang dapat digunakan jika menggunakan binding NUMA untuk menghindari penalti performa lintas-NUMA) |
| # dari NUMA Node | 2 |
| Throughput NIC (Gbps) | 200 |
Hubungan antara jumlah TensorCore, chip, host/VM, dan kubus dalam Pod:
| Cores | Chip | Host/VM | Kubus | |
|---|---|---|---|---|
| Pembawa acara | 8 | 4 | 1 | |
| Kubus (alias rak) | 128 | 64 | 16 | 1 |
| Slice terbesar yang didukung | 12288 | 6144 | 1536 | 96 |
| Pod v5p lengkap | 17920 | 8960 | 2240 | 140 |
Konfigurasi TPU v5e
Cloud TPU v5e adalah produk pelatihan dan inferensi (penyaluran) gabungan. Untuk membedakan antara pelatihan dan lingkungan inferensi, gunakan flag AcceleratorType atau AcceleratorConfig dengan TPU API atau flag --machine-type saat membuat kumpulan node GKE.
Tugas pelatihan dioptimalkan untuk throughput dan ketersediaan, sekaligus tugas penayangan dioptimalkan untuk latensi. Jadi, tugas pelatihan pada TPU yang disediakan untuk inferensi dapat memiliki ketersediaan yang lebih rendah, demikian pula, tugas penyaluran yang dijalankan di TPU yang disediakan untuk pelatihan dapat memiliki latensi yang lebih tinggi.
Anda menggunakan AcceleratorType untuk menentukan jumlah TensorCore yang ingin digunakan.
Anda menentukan AcceleratorType saat membuat TPU menggunakan gcloud CLI atau Google Cloud Console. Nilai yang Anda
tentukan untuk AcceleratorType adalah string dengan format:
v$VERSION_NUMBER-$CHIP_COUNT.
Anda juga dapat menggunakan AcceleratorConfig untuk menentukan jumlah TensorCore yang ingin digunakan. Namun, karena tidak ada varian topologi 2D kustom untuk TPU v5e, tidak ada perbedaan antara penggunaan AcceleratorConfig dan AcceleratorType.
Untuk mengonfigurasi TPU v5e menggunakan AcceleratorConfig, gunakan --version dan flag --topology. Tetapkan --version ke versi TPU yang ingin Anda gunakan dan
--topology ke susunan fisik chip TPU dalam slice. Nilai
yang Anda tentukan untuk AcceleratorConfig adalah string dengan format AxB,
dengan A dan B adalah chip yang dihitung di setiap arah.
Bentuk irisan 2D berikut didukung untuk v5e:
| Topologi | Jumlah TPU chip | Jumlah Host |
| 1x1 | 1 | 1/8 |
| 2x2 | 4 | 1/2 |
| 2x4 | 8 | 1 |
| 4x4 | 16 | 2 |
| 4x8 | 32 | 4 |
| 8x8 | 64 | 8 |
| 8x16 | 128 | 16 |
| 16x16 | 256 | 32 |
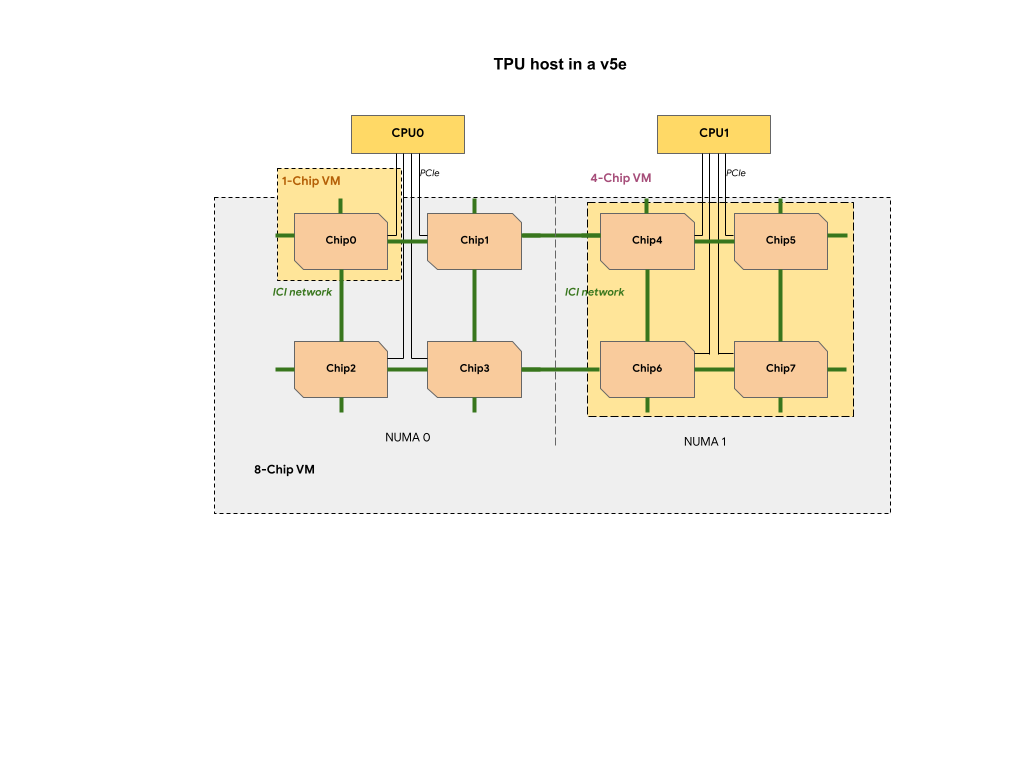
Setiap VM TPU dalam slice TPU v5e berisi 1, 4, atau 8 chip. Dalam 4-chip dan irisan yang lebih kecil, semua chip TPU berbagi node Non Uniform Memory Access (NUMA) yang sama.
Untuk VM TPU 8-chip v5e, komunikasi CPU-TPU akan lebih efisien dalam partisi
NUMA. Misalnya, dalam gambar berikut, komunikasi CPU0-Chip0 akan
lebih cepat daripada komunikasi CPU0-Chip4.
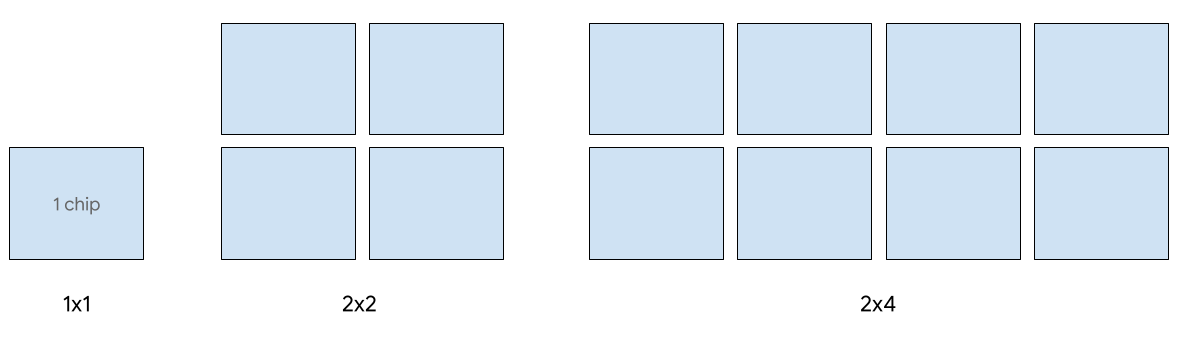
Jenis Cloud TPU v5e untuk inferensi
Penyajian host tunggal didukung hingga 8 chip v5e. Konfigurasi berikut didukung: irisan 1x1, 2x2, dan 2x4. Setiap irisan memiliki 1, 4 dan 8 {i>chip<i}.
Guna menyediakan TPU untuk tugas penayangan, gunakan salah satu jenis akselerator berikut di permintaan pembuatan CLI atau TPU API Anda:
| AkseleratorType (TPU API) | Jenis mesin (GKE API) |
|---|---|
v5litepod-1 |
ct5lp-hightpu-1t |
v5litepod-4 |
ct5lp-hightpu-4t |
v5litepod-8 |
ct5lp-hightpu-8t |
Penayangan di lebih dari 8 chip v5e, yang juga disebut penayangan multi-host, didukung menggunakan Sax. Untuk mengetahui informasi selengkapnya, lihat Penayangan Model Bahasa Besar.
Jenis Cloud TPU v5e untuk pelatihan
Pelatihan didukung hingga 256 chip.
Guna menyediakan TPU untuk tugas pelatihan v5e, gunakan salah satu jenis akselerator berikut di permintaan pembuatan CLI atau API TPU Anda:
| AkseleratorType (TPU API) | Jenis mesin (GKE API) | Topologi |
|---|---|---|
v5litepod-16 |
ct5lp-hightpu-4t |
4x4 |
v5litepod-32 |
ct5lp-hightpu-4t |
4x8 |
v5litepod-64 |
ct5lp-hightpu-4t |
8x8 |
v5litepod-128 |
ct5lp-hightpu-4t |
8x16 |
v5litepod-256 |
ct5lp-hightpu-4t |
16x16 |
Perbandingan jenis VM TPU v5e:
| Jenis VM | n2d-48-24-v5lite-tpu | n2d-192-112-v5lite-tpu | n2d-384-224-v5lite-tpu |
| # chip v5e | 1 | 4 | 8 |
| # vCPU | 24 | 112 | 224 |
| RAM (GB) | 48 | 192 | 384 |
| # dari NUMA Node | 1 | 1 | 2 |
| Berlaku untuk | V5litepod-1 | V5litepod-4 | V5litepod-8 |
| Gangguan | Tinggi | Sedang | Rendah |
Untuk memberi ruang bagi beban kerja yang memerlukan lebih banyak chip, penjadwal dapat melakukan preemption terhadap VM dengan lebih sedikit chip. Jadi VM 8-chip cenderung mendahului VM 1 dan 4-chip.
Konfigurasi TPU v4
Pod TPU v4 terdiri dari 4096 chip yang saling terhubung dengan link berkecepatan tinggi yang dapat dikonfigurasi ulang. Jaringan fleksibel TPU v4 memungkinkan Anda menghubungkan chip dalam
irisan Pod yang berukuran sama melalui beberapa cara. Saat membuat slice Pod TPU, Anda harus menentukan versi TPU dan jumlah resource TPU yang diperlukan. Saat
membuat slice Pod TPU v4, Anda dapat menentukan jenis dan ukurannya dengan salah satu dari dua cara:
AcceleratorType dan AcceleratorConfig.
Menggunakan AcceleratorType
Gunakan AcceleratorType saat Anda tidak menentukan topologi. Untuk mengonfigurasi TPU v4 menggunakan AcceleratorType, gunakan flag --accelerator-type saat membuat slice Pod TPU. Tetapkan --accelerator-type ke string yang berisi versi TPU dan jumlah TensorCore yang ingin digunakan. Misalnya, untuk membuat slice Pod v4 dengan 32 TensorCore, Anda harus menggunakan --accelerator-type=v4-32.
Perintah berikut membuat slice Pod TPU v4 dengan 512 TensorCore menggunakan flag --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --accelerator-type=v4-512 --version=tpu-vm-tf-2.16.1-pod-pjrt
Angka setelah versi TPU (v4) menentukan jumlah TensorCore.
Ada dua TensorCore di TPU v4, sehingga jumlah chip TPU adalah 512/2 = 256.
Menggunakan AcceleratorConfig
Gunakan AcceleratorConfig saat Anda ingin menyesuaikan topologi fisik slice TPU. Hal ini umumnya diperlukan untuk penyesuaian performa dengan slice Pod yang lebih besar dari 256 chip.
Untuk mengonfigurasi TPU v4 menggunakan AcceleratorConfig, gunakan --version dan flag --topology. Tetapkan --version ke versi TPU yang ingin Anda gunakan dan
--topology ke susunan fisik chip TPU di slice Pod.
Anda menentukan topologi TPU menggunakan AxBxC 3-tuple dengan A<=B<=C dan A, B, C
adalah semua <= 4 atau semuanya merupakan kelipatan bilangan bulat 4. Nilai A, B, dan C adalah jumlah
chip di ketiga dimensi tersebut. Misalnya, untuk membuat slice Pod v4
dengan 16 chip, Anda harus menetapkan --version=v4 dan --topology=2x2x4.
Perintah berikut membuat slice Pod TPU v4 dengan 128 chip TPU yang disusun dalam array 4x4x8:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --type=v4 --topology=4x4x8 --version=tpu-vm-tf-2.16.1-pod-pjrt
Topologi dengan 2A=B=C atau 2A=2B=C juga memiliki varian topologi yang dioptimalkan untuk komunikasi menyeluruh, misalnya, 4×4×8, 8×8×16, dan 12×12×24. Ini dikenal sebagai topologi tori tori.
Ilustrasi berikut menunjukkan beberapa topologi TPU v4 yang umum.
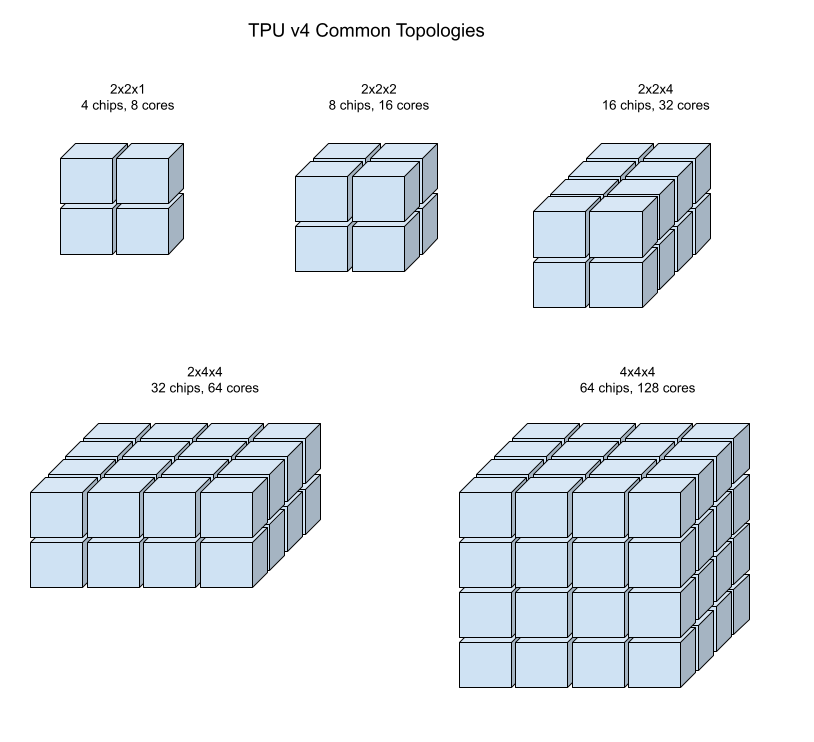
Irisan Pod yang lebih besar dapat dibuat dari satu atau lebih "kubus" chip 4x4x4.
Topologi Tori Berpilin
Beberapa bentuk irisan torus v4 3D memiliki opsi untuk menggunakan topologi torus terpilin. Misalnya, dua kubus v4 dapat disusun sebagai irisan 4x4x8 atau 4x4x8_twisted. Topologi twisted menawarkan bandwidth dua bagian yang jauh lebih tinggi. Peningkatan bandwidth bagian berguna untuk workload yang menggunakan pola komunikasi global. Topologi terpilin dapat meningkatkan performa untuk sebagian besar model, dengan beban kerja penyematan TPU yang paling menguntungkan.
Untuk beban kerja yang menggunakan paralelisme data sebagai satu-satunya strategi paralelisme, topologi terpilin mungkin berperforma sedikit lebih baik. Untuk LLM, performa yang menggunakan topologi terpilin dapat bervariasi bergantung pada jenis paralelismenya (DP, MP, dll.). Praktik terbaik adalah melatih LLM dengan dan tanpa topologi yang dipilin untuk menentukan topologi mana yang memberikan performa terbaik untuk model Anda. Beberapa eksperimen pada model MaxText FSDP telah melihat 1-2 peningkatan MFU menggunakan topologi twisted.
Manfaat utama topologi twisted adalah dapat mengubah topologi torus asimetris (misalnya, 4×4×8) menjadi topologi simetris yang terkait erat. Topologi simetris memiliki banyak manfaat:
- Load balancing yang lebih baik
- Bandwidth dua bagian yang lebih tinggi
- Rute paket yang lebih singkat
Manfaat ini pada akhirnya menghasilkan peningkatan performa bagi banyak pola komunikasi global.
Software TPU mendukung twisted tori pada slice yang ukuran setiap dimensinya sama dengan atau dua kali ukuran dimensi terkecil. Misalnya, 4x4x8, 4×8×8, atau 12x12x24.
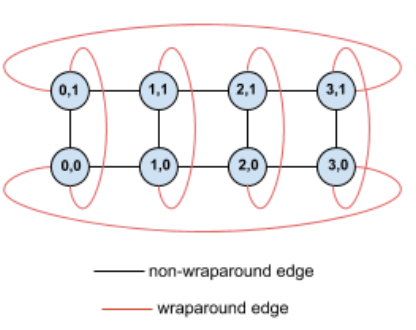
Sebagai contoh, pertimbangkan topologi torus 4×2 ini dengan TPU yang diberi label dengan koordinat (X,Y) dalam slice:
Tepi dalam grafik topologi ini ditampilkan sebagai tepi yang tidak mengarah agar lebih jelas. Dalam praktiknya, setiap edge merupakan koneksi dua arah antara TPU. Kami menyebut tepi antara satu sisi petak ini dan sisi yang berlawanan sebagai tepi menyeluruh, seperti yang ditunjukkan dalam diagram.
Dengan memutar topologi ini, kita akan mendapatkan topologi torus 4×2 yang benar-benar simetris:
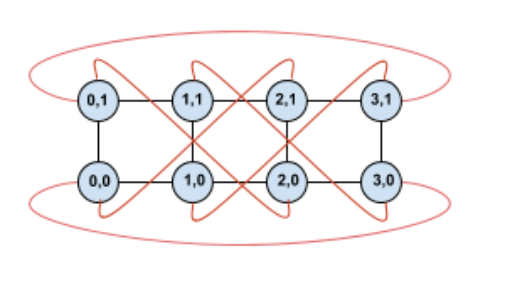
Semua yang berubah antara diagram ini dan sebelumnya adalah tepi wrap-around Y. Alih-alih menghubungkan ke TPU lain dengan koordinat X yang sama, TPU tersebut telah digeser untuk terhubung ke TPU dengan koordinat X+2 mod 4.
Ide yang sama akan menggeneralisasi ke ukuran dimensi yang berbeda dan jumlah dimensi yang berbeda. Jaringan yang dihasilkan bersifat simetris, asalkan setiap dimensi sama dengan atau dua kali ukuran dimensi terkecil.
Tabel berikut menunjukkan topologi terpilin yang didukung dan peningkatan teoretis bandwidth bagian keduanya dibandingkan dengan topologi tidak terpilin.
| Topologi Twisted | Peningkatan secara teoritis dalam dua bagian bandwidth dibandingkan dengan torus yang tidak terpilin |
|---|---|
| 4×4×8_twisted | ~70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
Varian Topologi TPU v4
Beberapa topologi yang berisi jumlah chip yang sama dapat diatur dengan cara yang berbeda. Misalnya, slice Pod TPU dengan 512 chip (1024 TensorCores) dapat dikonfigurasi menggunakan topologi berikut: 4x4x32, 4x8x16, atau 8x8x8. Slice Pod TPU dengan chip 2048 (4096 TensorCores) menawarkan lebih banyak opsi topologi: 4x4x128, 4x8x64, 4x16x32, dan 8x16x16. Slice Pod TPU dengan chip 2048 (4096 TensorCores) menawarkan lebih banyak opsi topologi: 4x4x128, 4x8x64, 4x16x32, dan 8x16x16.
Topologi default yang terkait dengan jumlah chip tertentu adalah yang paling mirip dengan kubus (lihat Topologi v4). Bentuk ini kemungkinan merupakan pilihan terbaik untuk pelatihan ML paralel data. Topologi lainnya dapat berguna untuk workload dengan berbagai jenis paralelisme (misalnya, paralelisme model dan data, atau partisi spasial simulasi). Workload ini akan berfungsi optimal jika topologinya dicocokkan dengan paralelisme yang digunakan. Misalnya, menempatkan paralelisme model 4 arah pada dimensi X dan paralelisme data 256 arah pada dimensi Y dan Z cocok dengan topologi 4x16x16.
Model dengan berbagai dimensi paralelisme memiliki performa terbaik dengan dimensi paralelismenya yang dipetakan ke dimensi topologi TPU. Ini biasanya data+model paralel Model Bahasa Besar (LLM) paralel. Misalnya, untuk slice Pod TPU v4 dengan topologi 8x16x16, dimensi topologi TPU adalah 8, 16, dan 16. Akan lebih efektif jika menggunakan paralelisme model 8 arah atau 16 arah (dipetakan ke salah satu dimensi topologi TPU fisik). Paralelisme model 4 arah akan kurang optimal dengan topologi ini, karena tidak selaras dengan dimensi topologi TPU apa pun, tetapi akan lebih optimal dengan topologi 4x16x32 pada jumlah chip yang sama.
Konfigurasi TPU v4 terdiri dari dua grup, yaitu dengan topologi lebih kecil dari 64 chip (topologi kecil), dan dengan topologi lebih besar dari 64 chip (topologi besar).
Topologi v4 kecil
Cloud TPU mendukung slice Pod TPU v4 berikut yang lebih kecil dari 64 chip, yaitu kubus 4x4x4. Anda dapat membuat topologi v4 kecil ini menggunakan nama berbasis TensorCore (misalnya v4-32), atau topologinya (misalnya, 2x2x4):
| Nama (berdasarkan jumlah TensorCore) | Jumlah chip | Topologi |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologi v4 besar
Slice Pod TPU v4 tersedia dalam kelipatan 64 chip, dengan bentuk yang merupakan
perkalian 4 pada ketiga dimensi. Dimensi juga harus
dalam urutan meningkat. Beberapa contoh ditampilkan dalam tabel berikut. Beberapa
topologi ini adalah topologi "kustom" yang hanya dapat dibuat menggunakan
flag --type dan --topology karena ada lebih dari satu cara untuk mengatur
chip.
Perintah berikut membuat slice Pod TPU v4 dengan 512 chip TPU yang disusun dalam array 8x8x8:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --type=v4 --topology=8x8x8 --version=tpu-vm-tf-2.16.1-pod-pjrt
Anda dapat membuat slice Pod TPU v4 dengan jumlah TensorCore yang sama menggunakan --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --accelerator-type=v4-1024 --version=tpu-vm-tf-2.16.1-pod-pjrt
| Nama (berdasarkan jumlah TensorCore) | Jumlah chip | Topologi |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
T/A - harus menggunakan tanda --type dan --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
T/A - harus menggunakan tanda --type dan --topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |
Konfigurasi TPU v3
Pod TPU v3 terdiri dari 1024 chip yang saling terhubung dengan link berkecepatan tinggi. Untuk
membuat perangkat TPU v3 atau slice Pod, gunakan flag --accelerator-type untuk
perintah gcloud compute tpus tpu-vm. Tentukan jenis akselerator dengan menentukan
versi TPU dan jumlah inti TPU. Untuk satu TPU v3, gunakan
--accelerator-type=v3-8. Untuk slice Pod v3 dengan 128 TensorCore, gunakan
--accelerator-type=v3-128.
Perintah berikut menunjukkan cara membuat slice Pod TPU v3 dengan 128 TensorCore:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --accelerator-type=v3-128 --version=tpu-vm-tf-2.16.1-pjrt
Tabel berikut mencantumkan jenis TPU v3 yang didukung:
| Versi TPU | Dukungan berakhir |
|---|---|
| v3-8 | (Tanggal akhir belum ditetapkan) |
| v3-32 | (Tanggal akhir belum ditetapkan) |
| v3-128 | (Tanggal akhir belum ditetapkan) |
| v3-256 | (Tanggal akhir belum ditetapkan) |
| v3-512 | (Tanggal akhir belum ditetapkan) |
| v3-1024 | (Tanggal akhir belum ditetapkan) |
| v3-2048 | (Tanggal akhir belum ditetapkan) |
Untuk mengetahui informasi selengkapnya tentang cara mengelola TPU, lihat Mengelola TPU. Untuk mengetahui informasi selengkapnya tentang berbagai versi Cloud TPU, lihat Arsitektur sistem.
Konfigurasi TPU v2
Pod TPU v2 terdiri dari 512 chip yang saling terhubung dengan link berkecepatan tinggi yang dapat dikonfigurasi ulang. Untuk membuat slice Pod TPU v2, gunakan flag --accelerator-type
untuk perintah gcloud compute tpus tpu-vm. Tentukan jenis akselerator dengan
menentukan versi TPU dan jumlah inti TPU. Untuk satu TPU v2, gunakan
--accelerator-type=v2-8. Untuk slice Pod v2 dengan 128 TensorCore, gunakan
--accelerator-type=v2-128.
Perintah berikut menunjukkan cara membuat slice Pod TPU v2 dengan 128 TensorCore:
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --accelerator-type=v2-128 --version=tpu-vm-tf-2.16.1-pjrt
Untuk mengetahui informasi selengkapnya tentang cara mengelola TPU, lihat Mengelola TPU. Untuk mengetahui informasi selengkapnya tentang berbagai versi Cloud TPU, lihat Arsitektur sistem.
Tabel berikut mencantumkan jenis TPU v2 yang didukung
| Versi TPU | Dukungan berakhir |
|---|---|
| v2-8 | (Tanggal akhir belum ditetapkan) |
| v2-32 | (Tanggal akhir belum ditetapkan) |
| v2-128 | (Tanggal akhir belum ditetapkan) |
| v2-256 | (Tanggal akhir belum ditetapkan) |
| v2-512 | (Tanggal akhir belum ditetapkan) |
Kompatibilitas jenis TPU
Anda dapat mengubah jenis TPU ke jenis TPU lain yang memiliki jumlah TensorCore atau chip yang sama (misalnya v3-128 dan v4-128), dan menjalankan skrip pelatihan tanpa perubahan kode. Namun, jika beralih ke jenis TPU dengan TensorCore yang lebih besar atau lebih kecil, Anda perlu melakukan penyesuaian dan pengoptimalan yang signifikan. Untuk mengetahui informasi selengkapnya,
lihat Pelatihan terkait Pod TPU.
Versi software VM TPU
Bagian ini menjelaskan versi software TPU yang harus Anda gunakan untuk TPU dengan arsitektur VM TPU. Untuk arsitektur Node TPU, lihat Versi software TPU Node.
Versi software TPU tersedia untuk framework TensorFlow, PyTorch, dan JAX.
TensorFlow
Gunakan versi software TPU yang sesuai dengan versi TensorFlow yang digunakan untuk menulis model Anda.
Mulai TensorFlow 2.15.0, Anda juga harus menentukan runtime stream executor (SE) atau runtime PJRT. Misalnya, jika Anda menggunakan TensorFlow 2.16.1 dengan runtime PJRT, gunakan versi software TPU tpu-vm-tf-2.16.1-pjrt. Versi sebelum TensorFlow 2.15.0 hanya mendukung eksekutor streaming. Untuk mengetahui informasi selengkapnya tentang PJRT, lihat dukungan TensorFlow PJRT.
Versi software VM TensorFlow TPU yang didukung saat ini adalah:
- tpu-vm-tf-2.16.1-pjrt
- tpu-vm-tf-2.16.1-se
- tpu-vm-tf-2.15.0-pjrt
- tpu-vm-tf-2.15.0-se
- tpu-vm-tf-2.14.1
- tpu-vm-tf-2.14.0
- tpu-vm-tf-2.13.1
- tpu-vm-tf-2.13.0
- tpu-vm-tf-2.12.1
- tpu-vm-tf-2.12.0
- tpu-vm-tf-2.11.1
- tpu-vm-tf-2.11.0
- tpu-vm-tf-2.10.1
- tpu-vm-tf-2.10.0
- tpu-vm-tf-2.9.3
- tpu-vm-tf-2.9.1
- tpu-vm-tf-2.8.4
- tpu-vm-tf-2.8.3
- tpu-vm-tf-2.8.0
- tpu-vm-tf-2.7.4
- tpu-vm-tf-2.7.3
Untuk mengetahui informasi selengkapnya tentang versi patch TensorFlow, lihat Versi patch TensorFlow yang didukung.
Dukungan PJRT TensorFlow
Mulai dari TensorFlow 2.15.0, Anda dapat menggunakan antarmuka PJRT untuk TensorFlow di TPU. PJRT menghadirkan defragmentasi memori perangkat otomatis dan menyederhanakan integrasi hardware dengan framework. Untuk informasi lebih lanjut tentang PJRT, lihat PJRT: Menyederhanakan Integrasi Hardware dan Framework ML di Blog Google Open Source.
Tidak semua fitur TPU v2, v3, dan v4 telah dimigrasikan ke runtime PJRT. Tabel berikut menjelaskan fitur yang didukung pada PJRT atau eksekutor uap.
| Akselerator | Fitur | Didukung di PJRT | Didukung di eksekutor streaming |
|---|---|---|---|
| TPU v2-v4 | Komputasi padat (tanpa API embedding TPU) | Ya | Ya |
| TPU v2-v4 | Dense compute API + API embedding TPU | Tidak | Ya |
| TPU v2-v4 | tf.summary/tf.print dengan penempatan perangkat lunak |
Tidak | Ya |
| TPU v5e | Komputasi padat (tanpa API embedding TPU) | Ya | Tidak |
| TPU v5e | API penyematan TPU | T/A - TPU v5e tidak mendukung API penyematan TPU | T/A |
| TPU v5p | Komputasi padat (tanpa API embedding TPU) | Ya | Tidak |
| TPU v5p | API penyematan TPU | Ya | Tidak |
TPU v4 dengan TensorFlow versi 2.10.0 dan yang lebih lama
Jika Anda melatih model di TPU v4 dengan TensorFlow, TensorFlow versi 2.10.0 dan yang lebih lama menggunakan versi khusus v4 yang ditampilkan dalam tabel berikut. Jika versi TensorFlow yang Anda gunakan tidak ditampilkan dalam tabel, ikuti panduan di bagian TensorFlow.
| Versi TensorFlow | Versi software TPU |
|---|---|
| 2.10.0 | tpu-vm-tf-2.10.0-v4, tpu-vm-tf-2.10.0-pod-v4 |
| 2.9.3 | tpu-vm-tf-2.9.3-v4, tpu-vm-tf-2.9.3-pod-v4 |
| 2.9.2 | tpu-vm-tf-2.9.2-v4, tpu-vm-tf-2.9.2-pod-v4 |
| 2.9.1 | tpu-vm-tf-2.9.1-v4, tpu-vm-tf-2.9.1-pod-v4 |
Versi Libtpu
VM TPU dibuat dengan TensorFlow dan library Libtpu terkait yang telah diinstal sebelumnya. Jika Anda membuat image VM sendiri, tentukan versi software TensorFlow TPU berikut dan versi libtpu yang sesuai:
| Versi TensorFlow | versi libtpu.so |
|---|---|
| 2.16.1 | 1.10.1 |
| 2.15.0 | 1.9.0 |
| 2.14.1 | 1.8.1 |
| 2.14.0 | 1.8.0 |
| 2.13.1 | 1.7.1 |
| 2.13.0 | 1.7.0 |
| 2.12.1 | 1.6.1 |
| 2.12.0 | 1.6.0 |
| 2.11.1 | 1.5.1 |
| 2.11.0 | 1.5.0 |
| 2.10.1 | 1.4.1 |
| 2.10.0 | 1.4.0 |
| 2.9.3 | 1.3.2 |
| 2.9.1 | 1.3.0 |
| 2.8.3 | 1.2.3 |
| 2,8.* | 1.2.0 |
| 2.7.3 | 1.1.2 |
PyTorch
Gunakan versi software TPU yang sesuai dengan versi PyTorch yang digunakan untuk menulis model Anda. Misalnya, jika Anda menggunakan PyTorch 1.13 dan TPU v2 atau
v3, gunakan versi software TPU tpu-vm-pt-1.13. Jika Anda menggunakan TPU v4, gunakan
versi software TPU tpu-vm-v4-pt-1.13. Versi software TPU yang sama digunakan untuk Pod TPU (misalnya,v2-32, v3-128, v4-32). Versi software TPU yang didukung saat ini adalah:
TPU v2/v3:
- tpu-vm-pt-2.0 (pytorch-2.0)
- tpu-vm-pt-1.13 (pytorch-1.13)
- tpu-vm-pt-1.12 (pytorch-1.12)
- tpu-vm-pt-1.11 (pytorch-1.11)
- tpu-vm-pt-1.10 (pytorch-1.10)
- v2-alpha (pytorch-1.8.1)
TPU v4:
- tpu-vm-v4-pt-2.0 (pytorch-2.0)
- tpu-vm-v4-pt-1.13 (pytorch-1.13)
TPU v5 (v5e dan v5p):
- v2-alpha-tpuv5 (pytorch-2.0)
Saat Anda membuat VM TPU, PyTorch versi terbaru akan diprainstal di VM TPU. Versi libtpu.so yang benar akan otomatis diinstal saat Anda menginstal PyTorch.
Untuk mengubah versi software PyTorch saat ini, lihat Mengubah versi PyTorch.
JAX
Anda harus menginstal JAX secara manual di VM TPU. Tidak ada versi software TPU (runtime) khusus JAX untuk TPU v2 dan v3. Untuk versi TPU lebih baru, gunakan versi software berikut:
- TPU v4: tpu-vm-v4-base
- TPU v5e: v2-alpha-tpuv5
- TPU v5p: v2-alpha-tpuv5
Versi libtpu.so yang benar akan otomatis diinstal saat Anda menginstal JAX.
Versi software TPU Node
Bagian ini menjelaskan versi software TPU yang harus Anda gunakan untuk TPU dengan arsitektur TPU Node. Untuk arsitektur VM TPU, lihat Versi software VM TPU.
Versi software TPU tersedia untuk framework TensorFlow, PyTorch, dan JAX.
TensorFlow
Gunakan versi software TPU yang sesuai dengan versi TensorFlow yang digunakan untuk menulis model Anda. Misalnya, jika Anda menggunakan TensorFlow 2.12.0, gunakan versi software TPU 2.12.0. Versi software TPU khusus TensorFlow adalah:
- 2.12.1
- 2.12.0
- 2.11.1
- 2.11.0
- 2.10.1
- 2.10.0
- 2.9.3
- 2.9.1
- 2.8.4
- 2.8.2
- 2.7.3
Untuk mengetahui informasi selengkapnya tentang versi patch TensorFlow, lihat Versi patch TensorFlow yang didukung.
Saat Anda membuat TPU Node, versi terbaru TensorFlow sudah diinstal sebelumnya di TPU Node.
PyTorch
Gunakan versi software TPU yang cocok dengan versi PyTorch yang digunakan untuk menulis
model Anda. Misalnya, jika Anda menggunakan PyTorch 1.9, gunakan
versi software pytorch-1.9.
Versi software TPU khusus PyTorch adalah:
- pytorch-2,0
- pytorch-1,13
- pytorch-1,12
- pytorch-1,11
- pytorch-1,10
- pytorch-1,9
- pytorch-1,8
- pytorch-1,7
pytorch-1,6
pytorch-nightly
Saat Anda membuat TPU Node, PyTorch versi terbaru sudah diinstal sebelumnya di TPU Node.
JAX
Anda harus menginstal JAX secara manual di VM TPU, sehingga tidak ada versi software TPU khusus JAX yang telah diinstal sebelumnya. Anda dapat menggunakan versi software apa pun yang dicantumkan untuk TensorFlow.
Langkah selanjutnya
- Pelajari arsitektur TPU lebih lanjut di halaman Arsitektur Sistem.
- Lihat Kapan harus menggunakan TPU untuk mempelajari jenis model yang cocok dengan Cloud TPU.