このチュートリアルには次の内容が組み込まれています。
- さまざまなサイズ(7B、13B、70B)の大型言語モデル(LLM)の Llama 2 ファミリーをデプロイする Cloud TPU VM の作成
- モデルのチェックポイントを準備し、SAX にデプロイする
- HTTP エンドポイントを介してモデルを操作する
Serving for AGI Experiments(SAX)は、推論に Paxml、JAX、PyTorch モデルを提供する試験運用版のシステムです。SAX のコードとドキュメントは Saxml Git リポジトリにあります。TPU v5e をサポートする現在の安定バージョンは v1.1.0 です。
SAX セルについて
SAX セル(またはクラスタ)は、モデルを提供するコアユニットです。積極的な聞き取りは、主に 2 つの部分から成ります。
- 管理サーバー: このサーバーはモデルサーバーを追跡し、モデルサーバーにモデルを割り当てます。クライアントが操作する適切なモデルサーバーを見つけるのに役立ちます。
- モデルサーバー: モデルを実行するサーバー。受信リクエストの処理とレスポンスの生成を担当します。
次の図は、SAX セルの図を示しています。
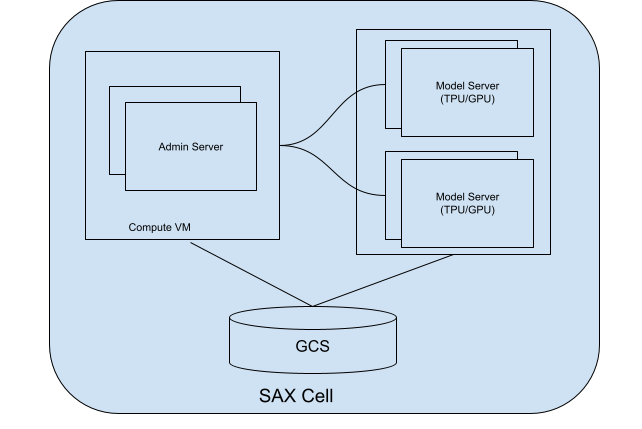
図 1. 管理サーバーとモデルサーバーを含む SAX セル。
SAX セルは、Python、C++、Go で記述されたクライアントを使用して操作できます。また、HTTP サーバー経由で直接操作することもできます。次の図は、外部クライアントが SAX セルとやり取りする方法を示しています。

図 2.SAX セルとやり取りする外部クライアントのランタイム アーキテクチャ。
目標
- サービス提供用の TPU リソースを設定する
- SAX クラスタを作成する
- Llama 2 モデルを公開する
- モデルを操作する
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
- Cloud TPU
- Compute Engine
- Cloud Storage
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
Cloud TPU 環境の設定の手順に沿って、Google Cloud プロジェクトを設定し、Cloud TPU API を有効にして、サービス アカウントを作成します。
TPU を作成する
次の手順では、モデルを提供する TPU VM を作成する方法を示します。
環境変数を作成します。
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
環境変数の説明
PROJECT_ID- Google Cloud プロジェクトの ID
ACCELERATOR_TYPE- アクセラレータ タイプでは、作成する Cloud TPU のバージョンとサイズを指定します。Llama 2 モデルのサイズによって、TPU サイズの要件が異なります。
- 7B:
v5litepod-4以上 - 13B:
v5litepod-8以上 - 70B:
v5litepod-16以上
- 7B:
ZONE- Cloud TPU を作成するゾーン。
SERVICE_ACCOUNT- Cloud TPU に接続するサービス アカウント。
TPU_NAME- Cloud TPU の名前。
QUEUED_RESOURCE_ID- キューに入れられたリソース リクエストの識別子。
アクティブな Google Cloud CLI 構成でプロジェクト ID とゾーンを設定します。
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONETPU VM を作成します。
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}TPU がアクティブであることを確認します。
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
チェックポイント変換ノードの設定
SAX クラスタで Llama モデルを実行するには、元の Llama チェックポイントを SAX 対応形式に変換する必要があります。
変換には、モデルサイズに応じて、かなりのメモリリソースが必要です。
| モデル | マシンタイプ |
|---|---|
| 70 億人 | 50~ 60 GB のメモリ |
| 13B | 120 GB のメモリ |
| 70B | 500~600 GB のメモリ(N2 または M1 マシンタイプ) |
7B モデルと 13B モデルの場合は、TPU VM で変換を実行できます。70B モデルの場合は、約 1 TB のディスク容量を持つ Compute Engine インスタンスを作成する必要があります。
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
変換サーバーとして TPU または Compute Engine インスタンスを使用する場合でも、Llama 2 チェックポイントを変換するようにサーバーを設定します。
7B モデルと 13B モデルの場合は、サーバー名の環境変数に TPU の名前を設定します。
export CONV_SERVER_NAME=$TPU_NAME70B モデルの場合、サーバー名の環境変数を Compute Engine インスタンスの名前に設定します。
export CONV_SERVER_NAME=INSTANCE_NAME
SSH を使用してコンバージョン ノードに接続します。
変換ノードが TPU の場合は、TPU に接続します。
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEコンバージョン ノードが Compute Engine インスタンスの場合は、Compute Engine VM に接続します。
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE必要なパッケージを変換ノードにインストールします。
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Llama チェックポイント変換スクリプトをダウンロードします。
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Llama 2 の重みをダウンロードする
モデルを変換する前に、Llama 2 の重みをダウンロードする必要があります。このチュートリアルでは、Hugging Face Transformers 形式に変換された重み(meta-llama/Llama-2-7b-hf など)ではなく、元の Llama 2 の重み(meta-llama/Llama-2-7b など)を使用する必要があります。
Llama 2 の重みがすでにある場合は、重みの変換に進みます。
Hugging Face ハブから重みをダウンロードするには、ユーザー アクセス トークンを設定し、Llama 2 モデルへのアクセスをリクエストする必要があります。アクセスをリクエストするには、使用するモデルの Hugging Face ページの手順(meta-llama/Llama-2-7b など)に沿って操作します。
重みのディレクトリを作成します。
sudo mkdir WEIGHTS_DIRECTORY
Hugging Face Hub から Llama2 の重みを取得します。
Hugging Face hub CLI をインストールします。
pip install -U "huggingface_hub[cli]"ウェイト ディレクトリに移動します。
cd WEIGHTS_DIRECTORY
Llama 2 ファイルをダウンロードします。
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
LLAMA2_REPO は、ダウンロードする Hugging Face リポジトリの名前(
Llama-2-7b、Llama-2-13b、Llama-2-70b)に置き換えます。
重みを変換する
変換スクリプトを編集し、変換スクリプトを実行してモデルの重みを変換します。
変換された重みを保持するディレクトリを作成します。
sudo mkdir CONVERTED_WEIGHTS
読み取り、書き込み、実行の権限があるディレクトリに Saxml GitHub リポジトリのクローンを作成します。
git clone https://github.com/google/saxml.git -b r1.1.0saxmlディレクトリに移動します。cd saxmlsaxml/tools/convert_llama_ckpt.pyファイルを開きます。saxml/tools/convert_llama_ckpt.pyファイルの 169 行目を次のように変更します。'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()宛先:
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()saxml/tools/init_cloud_vm.shスクリプトを実行します。saxml/tools/init_cloud_vm.sh70B のみ: テストモードをオフにします。
saxml/server/pax/lm/params/lm_cloud.pyファイルを開きます。saxml/server/pax/lm/params/lm_cloud.pyファイルの 344 行目を次のように変更します。return True宛先:
return False
重みを変換します。
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
以下を置き換えます。
- WEIGHTS_DIRECTORY: 元の重みのディレクトリ。
- CONVERTED_WEIGHTS: 変換された重みのターゲット パス。
- MODEL_SIZE:
7b、13b、または70b。
チェックポイント ディレクトリを準備する
チェックポイントを変換すると、チェックポイント ディレクトリの構造は次のようになります。
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
commit_success.txt という名前の空のファイルを作成し、そのコピーを checkpoint_00000000、metadata、state の各ディレクトリに配置します。これにより、このチェックポイントが完全に変換され、読み込みの準備ができたことを SAX に通知します。
チェックポイント ディレクトリに移動します。
cd CONVERTED_WEIGHTS/checkpoint_00000000
commit_success.txtという名前の空のファイルを作成します。touch commit_success.txtメタデータ ディレクトリに移動し、
commit_success.txtという名前の空のファイルを作成します。cd metadata && touch commit_success.txt状態ディレクトリに移動し、
commit_success.txtという名前の空のファイルを作成します。cd .. && cd state && touch commit_success.txt
チェックポイント ディレクトリの構造は次のようになります。
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Cloud Storage バケットの作成
変換されたチェックポイントは、モデルの公開時に使用できるように、Cloud Storage バケットに保存する必要があります。
Cloud Storage バケットの名前の環境変数を設定します。
export GSBUCKET=BUCKET_NAME
バケットを作成します。
gcloud storage buckets create gs://${GSBUCKET}変換されたチェックポイント ファイルをバケットにコピーします。
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
SAX_LLAMA2_DIR は、適切な値で置き換えます。
- 7B:
saxml_llama27b - 13B:
saxml_llama213b - 70B:
saxml_llama270b
- 7B:
SAX クラスタを作成する
SAX クラスタを作成するには、次の操作を行います。
通常のデプロイでは、Compute Engine インスタンスで管理者サーバーを実行し、TPU または GPU でモデルサーバーを実行します。このチュートリアルでは、管理サーバーとモデルサーバーを同じ TPU v5e インスタンスにデプロイします。
管理者サーバーを作成する
管理者サーバーの Docker コンテナを作成します。
変換サーバーに Docker をインストールします。
sudo apt-get update sudo apt-get install docker.io管理サーバーの Docker コンテナを起動します。
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
-d オプションを指定せずに docker run コマンドを実行すると、ログを表示して、管理サーバーが無事に起動したことを確認できます。
モデルサーバーの作成
次のセクションでは、モデルサーバーを作成する方法について説明します。
7b モデル
モデルサーバーの Docker コンテナを起動します。
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
13b モデル
LLaMA13BFP16TPUv5e の構成が lm_cloud.py にありません。次の手順では、lm_cloud.py を更新して新しい Docker イメージをコミットする方法を示します。
モデルサーバーを起動します。
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'SSH を使用して Docker コンテナに接続します。
sudo docker exec -it sax-model-server bashDocker イメージに Vim をインストールします。
$ apt update $ apt install vimsaxml/server/pax/lm/params/lm_cloud.pyファイルを開きます。LLaMA13Bを検索します。次のコードが表示されます。@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return True@quantizationで始まる行をコメントアウトするか削除します。この変更を加えると、ファイルは次のようになります。@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueTPU 構成をサポートするため、次のコードを追加します。
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseDocker コンテナの SSH セッションを終了します。
exit変更を新しい Docker イメージに commit します。
sudo docker commit sax-model-server sax-model-server:v1.1.0-mod新しい Docker イメージが作成されたことを確認します。
sudo docker imagesDocker イメージをプロジェクトの Artifact Registry に公開できますが、このチュートリアルではローカル イメージを使用します。
モデルサーバーを停止します。このチュートリアルの残りの部分では、更新されたモデルサーバーを使用します。
sudo docker stop sax-model-server更新された Docker イメージを使用してモデルサーバーを起動します。更新されたイメージ名
sax-model-server:v1.1.0-modを指定してください。sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
70B モデル
SSH を使用して TPU に接続し、モデルサーバーを起動します。
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
ログを確認する
モデルサーバーのログをチェックして、モデルサーバーが正しく起動したことを確認します。
docker logs -f sax-model-server
モデルサーバーが開始されない場合は、トラブルシューティングのセクションをご覧ください。
70B モデルの場合は、TPU VM ごとに次の手順を繰り返します。
SSH を使用して TPU に接続します。
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBER
WORKER_NUMBER は、接続する TPU VM を示す、0 から始まるインデックスです。
ログを確認します。
sudo docker logs -f sax-model-server3 つの TPU VM が他のインスタンスに接続していることが表示されます。
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001TPU VM の 1 つに、モデルサーバーの起動を示すログがあるはずです。
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
モデルを公開する
SAX には、SAX モデルサーバーの操作を簡素化する saxutil というコマンドライン ツールが付属しています。このチュートリアルでは、saxutil を使用してモデルを公開します。saxutil コマンドの完全なリストについては、Saxml README ファイルをご覧ください。
Saxml GitHub リポジトリのクローンを作成したディレクトリに移動します。
cd saxml70B モデルの場合は、コンバージョン サーバーに接続します。
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Bazel をインストールする
sudo apt-get install bazelCloud Storage バケットで
saxutilを実行するためのエイリアスを設定します。alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'saxutilを使用してモデルを公開します。これには、TPU v5litepod-8 では約 10 分を要します。saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1
次の変数を置き換えます。
モデルの規模 値 70 億人 MODEL: llama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13B MODEL: llama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70B MODEL: llama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
デプロイのテスト
デプロイが成功したかどうかを確認するには、saxutil ls コマンドを使用します。
saxutil ls /sax/test/MODEL
デプロイが成功すると、レプリカの数はゼロより大きくなり、次のように表示されます。
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
モデルサーバーの Docker ログは次のようになります。
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
トラブルシューティング
デプロイが失敗した場合は、モデルサーバーのログを確認します。
sudo docker logs -f sax-model-server
デプロイが成功すると、次の出力が表示されます。
Successfully loaded model for key: /sax/test/llama27b
ログにモデルがデプロイされたことが表示されない場合は、モデル構成とモデル チェックポイントへのパスを確認してください。
レスポンスの生成
saxutil ツールを使用して、プロンプトに対するレスポンスを生成できます。
質問に対する回答を生成する:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
出力例を以下に示します。
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
クライアントからモデルを操作する
SAX リポジトリには、SAX セルを操作するために使用できるクライアントが含まれています。クライアントは C++、Python、Go で使用できます。次の例は、Python クライアントをビルドする方法を示しています。
Python クライアントをビルドします。
bazel build saxml/client/python:sax.cc --compile_one_dependencyクライアントを
PYTHONPATHに追加します。この例では、ホーム ディレクトリの下にsaxmlがあることを前提としています。export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Python シェルから SAX を操作します。
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
HTTP エンドポイントからモデルを操作する
HTTP エンドポイントからモデルを操作するには、HTTP クライアントを作成します。
Compute Engine VM を作成する
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
SSH を使用して Compute Engine VM に接続します。
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEGKE GitHub リポジトリに AI のクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitHTTP サーバーのディレクトリに移動します。
cd ai-on-gke/tools/saxml-on-gke/httpserverDocker ファイルをビルドします。
docker build -f Dockerfile -t sax-http .HTTP サーバーを実行する
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
次のコマンドを使用して、ローカルマシンまたはポート 8888 にアクセスできる別のサーバーからエンドポイントをテストします。
サーバーの IP アドレスとポートの環境変数をエクスポートします。
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
モデルとクエリを含む JSON ペイロードを設定します。
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )
リクエストを送信します。
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
このチュートリアルが終了したら、次の手順でリソースをクリーンアップします。
Cloud TPU を削除します。
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONE
Compute Engine インスタンスを作成した場合は、そのインスタンスを削除します。
gcloud compute instances delete INSTANCE_NAME
Cloud Storage バケットとその内容を削除します。
gcloud storage rm --recursive gs://BUCKET_NAME
次のステップ