Cloud TPU ノードでモデルをプロファイリングする
モデルをプロファイリングすることで、Cloud TPU でのトレーニング パフォーマンスを最適化できます。モデルのプロファイルを作成するには、TensorBoard と Cloud TPU TensorBoard プラグインを使用します。インストール手順については、TensorBoard のインストール手順をご覧ください。
サポートされているフレームワークのいずれかと TensorBoard を使用する方法については、次のドキュメントをご覧ください。
前提条件
TensorBoard は TensorFlow の一部としてインストールされます。TensorFlow は、デフォルトで Cloud TPU ノードにインストールされます。TensorFlow を手動でインストールすることもできます。 どちらの場合も、追加の依存関係が必要になる場合があります。次のコマンドを実行してインストールします。
(vm)$ pip3 install --user -r /usr/share/models/official/requirements.txt
Cloud TPU TensorBoard プラグインのインストール
TPU ノードに SSH で接続します。
$ gcloud compute ssh your-vm --zone=your-zone
次のコマンドを実行します。
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install --user --upgrade -U "tensorboard>=2.3" pip3 install --user --upgrade -U "tensorflow>=2.3"
プロファイルのキャプチャ
プロファイルは、TensorBoard UI またはプログラムを使用してキャプチャできます。
TensorBoard を使用してプロファイルをキャプチャする
TensorBoard を起動すると、ウェブサーバーが起動します。ブラウザで TensorBoard の URL を指定すると、ウェブページが表示されます。ウェブページでは、手動でプロファイルをキャプチャして、そのプロファイル データを表示できます。
TensorFlow Profiler サーバーを起動する
tf.profiler.experimental.server.start(6000)
これにより、TPU VM で TensorFlow Profiler サーバーが起動します。
トレーニング スクリプトを開始する
トレーニング スクリプトを実行し、モデルがアクティブにトレーニングされていることを示す出力が表示されるまで待ちます。この表示はコードやモデルによって異なります。Epoch 1/100 のような出力を探します。または、Google Cloud コンソール の Cloud TPU ページに移動して TPU を選択し、CPU 使用率のグラフを表示することもできます。これは TPU の使用率ではありませんが、TPU によってモデルをトレーニングされていることを示す良いサインです。
TensorBoard サーバーを起動する
新しいターミナル ウィンドウを開き、ポート転送を使用して TPU VM に SSH で接続します。これで、ローカル ブラウザが TPU VM 上で実行されている TensorBoard サーバーと通信できるようになります。
gcloud compute tpus execution-groups ssh your-vm --zone=us-central1-a --ssh-flag="-4 -L 9001:localhost:9001"
開いたターミナル ウィンドウで TensorBoard を実行し、TensorBoard で --logdir フラグを使用してプロファイリング データを書き込むディレクトリを指定します。例:
TPU_LOAD_LIBRARY=0 tensorboard --logdir your-model-dir --port 9001
TensorBoard でウェブサーバーが起動され、その URL が表示されます。
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001/ (Press CTRL+C to quit)
ウェブブラウザを開き、TensorBoard の出力に表示されている URL に移動します。TensorBoard ページの右上にある再読み込みボタンをクリックして、TensorBoard のプロファイル データが完全に読み込まれていることを確認します。デフォルトで、Scalars タブを選択された状態で [TensorBoard] ページが表示されます。
TPU ノードでプロファイルをキャプチャする
- 画面上部のプルダウン メニューから [PROFILE] を選択します。
- [CAPTURE PROFILE] ボタンを選択します。
- [TPU 名] ラジオボタンをオンにします。
- TPU 名を入力します。
- CAPTUREボタンを選択します。
プログラムでプロファイルをキャプチャする
プログラムでプロファイルをキャプチャする方法は、使用している ML フレームワークによって異なります。
TensorFlow を使用している場合は、tf.profiler.experimental.start() と tf.profiler.experimental.stop() を使用してプロファイラを起動、停止します。詳細については、TensorFlow のパフォーマンス ガイドをご覧ください。
JAX を使用している場合は、jax.profiler.start_trace() と jax.profiler.stop_trace() を使用してプロファイラを起動、停止します。詳細については、JAX プログラムのプロファイリングをご覧ください。
プロファイルの一般的な問題をキャプチャする
トレースをキャプチャしようとすると、次のようなメッセージが表示されることがあります。
No trace event is collected after xx attempt(s). Perhaps, you want to try again
(with more attempts?).Tip: increase number of attempts with --num_tracing_attempts.
Failed to capture profile: empty trace result
これは、TPU で計算がアクティブに実行されていない、トレーニング ステップに時間がかかりすぎている、などの理由で発生します。このメッセージが表示された場合は、次の手順をお試しください。
- いくつかのエポックが実行された後にプロファイルのキャプチャを試します。
- TensorBoard の [Capture Profile] ダイアログでプロファイリング期間を増やします。トレーニング ステップに時間がかかりすぎている可能性があります。
- VM と TPU の両方が同じ TF バージョンであることを確認します。
TensorBoard でプロファイル データを表示する
[Profile] タブは、一部のモデルデータがキャプチャされると表示されます。TensorBoard ページの右上にある再読み込みボタンをクリックする必要がある場合もします。データが利用可能になり、[Profile] タブをクリックすると、パフォーマンス分析に役立つ次のようなツールが表示されます。
- 概要ページ
- トレース ビューア(Chrome ブラウザのみ)
- ストリーミング トレース ビューア(Chrome ブラウザのみ)
トレース ビューア
トレース ビューアは、[Profile] で利用可能な Cloud TPU パフォーマンス分析ツールです。このツールは、Chrome トレース イベント プロファイリング ビューアを使用するため、Chrome ブラウザでのみ機能します。
トレース ビューアには次のタイムラインが表示されます。
- TensorFlow モデルによって実行された演算の実行期間。
- 演算を実行したシステムの部分(TPU またはホストマシン)。通常、ホストマシンがトレーニング データを前処理して TPU に転送する infeed 演算を実行し、TPU は実際のモデル トレーニングを行います。
トレース ビューアを使用して、モデル内のパフォーマンスの問題を特定し、この問題を解決する対策を講じることができます。たとえば、大まかには、インフィードとモデル トレーニングのどちらに大部分の時間を費やしているかどうかを識別できます。さらに詳しく見ると、実行に最も時間がかかっている TensorFlow 演算も識別できます。
トレース ビューアは、Cloud TPU ごとに 1M イベントに制限されています。他のイベントを評価する場合は、代わりにストリーミング トレース ビューアを使用してください。
トレース ビューアのインターフェース
トレース ビューアを開くには、TensorBoard に移動して画面上部の [Profile] タブをクリックし、[Tools] プルダウンから [trace_viewer] を選択します。ビューアが開き、最新の実行結果が表示されます。
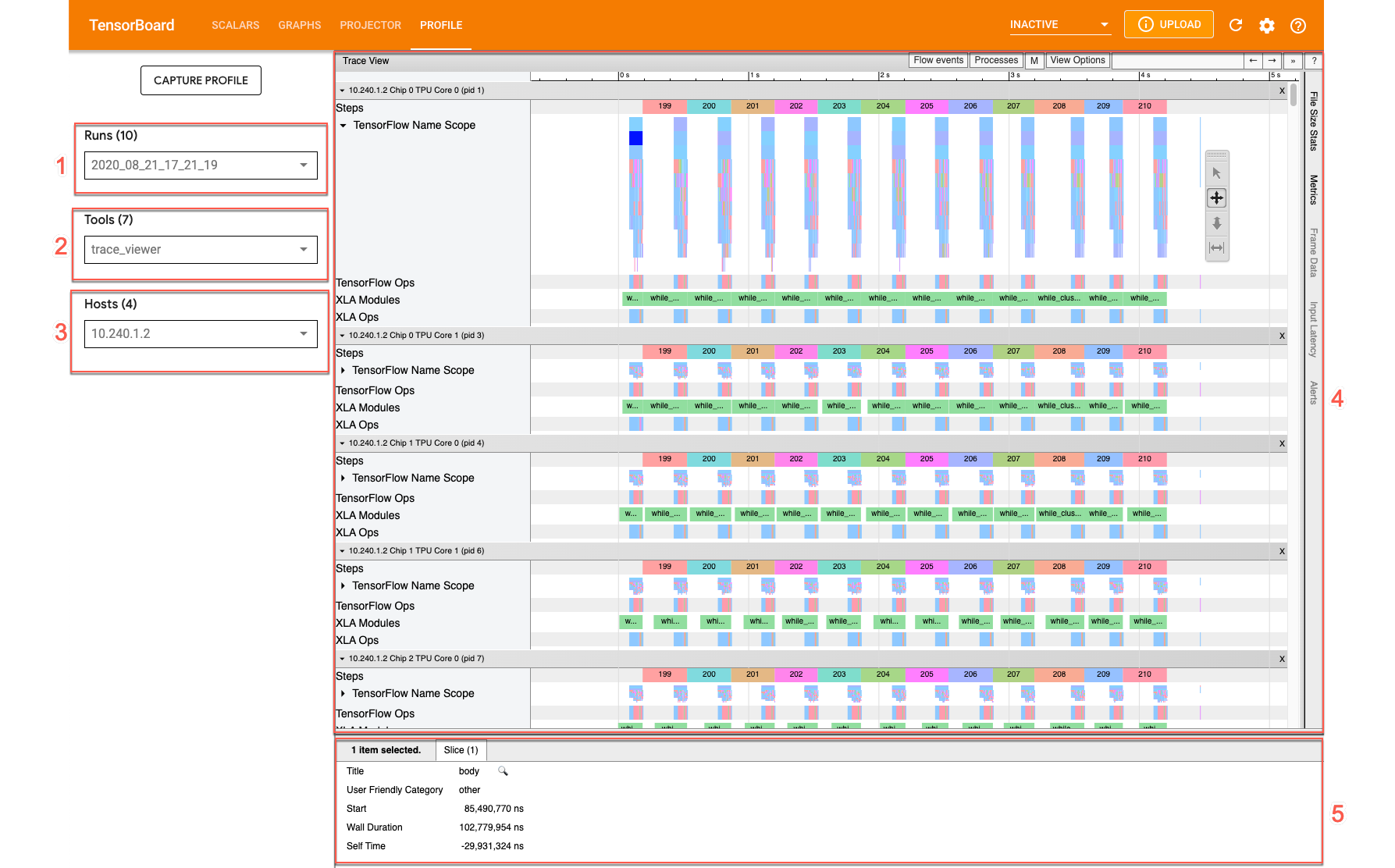
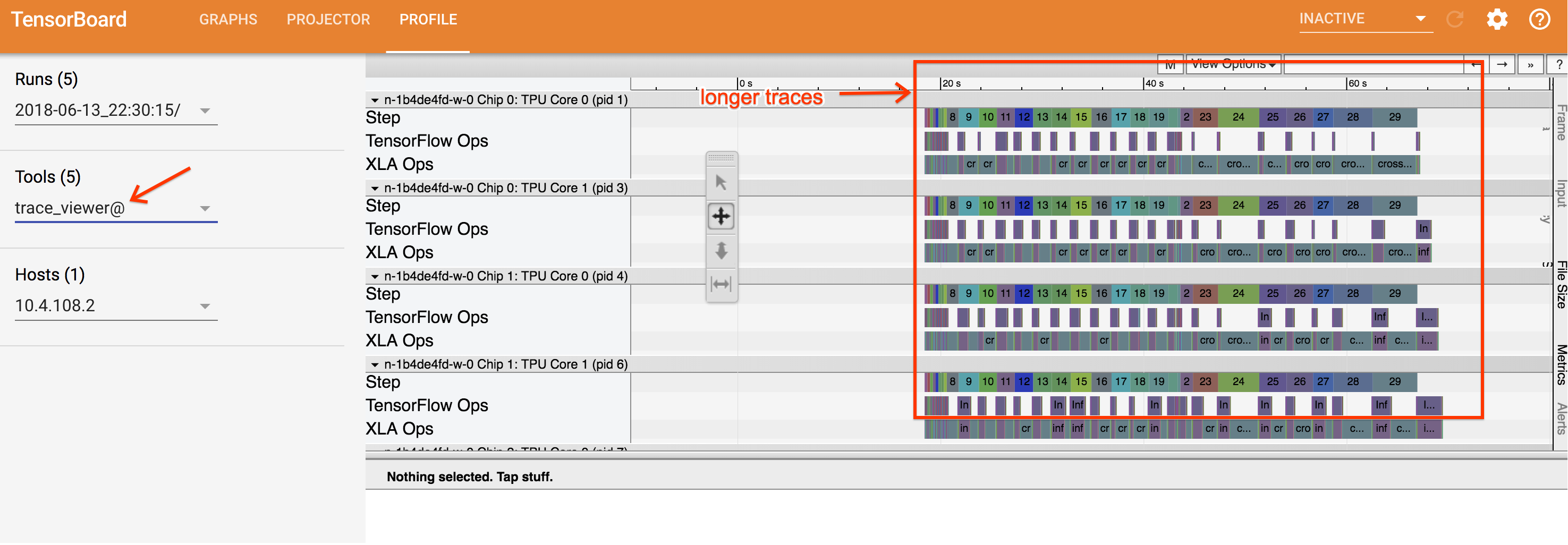
この画面には、次の主要な要素(上で番号が付けられています)が表示されます。
- [Runs] プルダウン。トレース情報をキャプチャしたすべての実行が表示されます。デフォルトのビューは最新の実行ですが、プルダウンを開いて別の実行を選択することもできます。
- [Tools] プルダウン。さまざまなプロファイリング ツールを選択します。
- [Host] プルダウン。Cloud TPU セットを含むホストを選択します。
- [Timeline] ペイン。Cloud TPU とホストマシンで実行された演算が時系列で表示されます。
- [Details] ペイン。[Timeline] ペインで選択した演算の詳細情報が表示されます。
では、[Timeline] ペインについて詳しく見てみましょう。
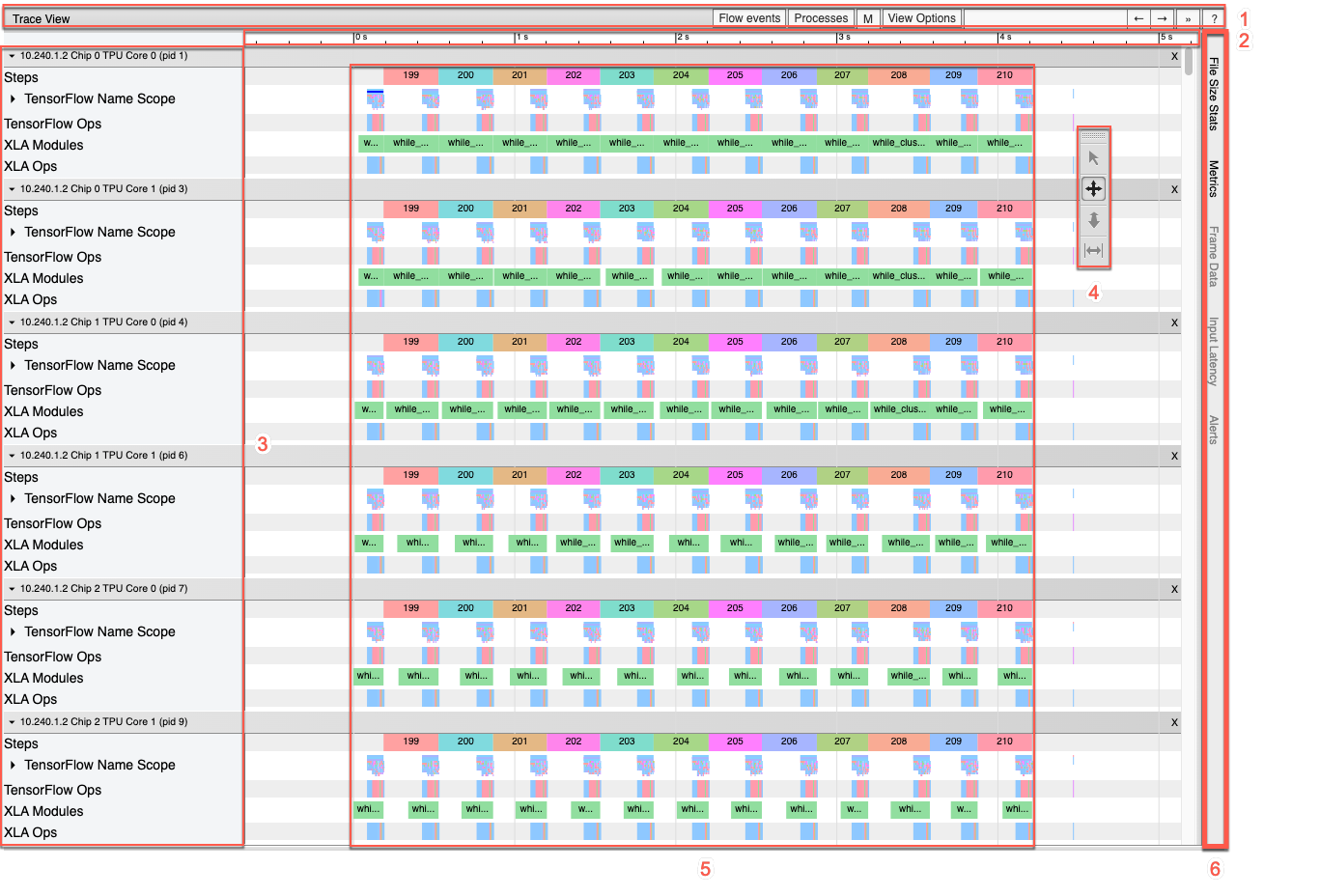
[Timeline] ペインには、次の要素が含まれます。
- 上部バー。さまざまな補助コントロールが表示されます。
- 時間軸。トレースの開始位置を基準にした時間が表示されます。
- セクションとトラックラベル。各セクションには複数のトラックが含まれています。左側にある三角形をクリックすると、セクションの展開や折りたたみを行うことができます。システムで処理中の要素ごとに 1 つのセクションがあります。
- ツールセレクタ。トレース ビューアを操作するさまざまなツールが用意されています。
- イベント。これらのイベントは、演算が実行されていた時間やトレーニング ステップなどのメタイベントの期間を示します。
- 垂直タブバー。Cloud TPU での使用は適しません。このバーは、Chrome が提供する汎用のトレース ビューアツールの一部で、さまざまなパフォーマンス分析タスクに使用されます。
セクションとトラック
トレース ビューアには、次のセクションがあります。
- TPU ノードごとに 1 つのセクション。ラベルとして TPU チップの数とチップ内の TPU ノードの数が使用されます(例: 「Chip 2: TPU Core 1」)。TPU ノードのセクションには、次のトラックが含まれます。
- Step。TPU で実行されていたトレーニング ステップの期間が表示されます。
- TensorFlow Ops。TPU 上で実行される TensorFlow 演算が表示されます。
- XLA Ops。TPU 上で実行された XLA 演算が表示されます。1 つの演算が 1 つ以上の XLA 演算に変換されます。XLA コンパイラにより、XLA 演算が TPU 上で実行されるコードに変換されます。
- ホストマシンの CPU 上で実行されるスレッドのセクション。「Host Threads」というラベルが付いています。このセクションには、CPU スレッドごとに 1 つのトラックが含まれます。注: セクション ラベルと一緒に表示される情報は無視してもかまいません。
タイムラインのツールセレクタ
TensorBoard のタイムライン ツールセレクタを使用して、タイムライン ビューを操作できます。タイムライン ツールをクリックするか、次のキーボード ショートカットを使用してツールをアクティブにできます。タイムライン ツールセレクタを移動するには、上部の点線部分をクリックしてセレクタを目的の場所にドラッグします。
タイムライン ツールの使い方は次のとおりです。
|
選択ツール イベントをクリックして選択します。複数のイベントを選択するにはドラッグします。選択したイベントに関する詳細情報(名前、開始時間、期間)が、詳細ペインに表示されます。 |
|
パンツール ドラッグしてタイムライン ビューを水平方向または垂直方向にパンします。 |
|
ズームツール 水平方向(時間軸)に沿って上にドラッグするとズームインし、下にドラッグするとズームアウトします。マウスカーソルの水平位置により、ズームが行われる中心が決まります。 注: ズームツールには、マウスカーソルがタイムライン ビューの外部にあるときにマウスボタンを放すと、ズームがアクティブのままになるという既知のバグがあります。これが発生した場合は、タイムライン ビューを軽くクリックすると、ズームが解除されます。 |
|
タイミング ツール 水平方向にドラッグして、時間間隔をマークできます。間隔の長さは時間軸に表示されます。間隔を調整するには、間隔の両端をドラッグします。間隔をクリアするには、タイムライン ビュー内の任意の場所をクリックします。 他のいずれかのツールを選択しても、間隔はマークされたままになることにご注意ください。 |




グラフ
TensorBoard では、さまざまなグラフを使用してモデルとそのパフォーマンスを視覚的に表示できます。グラフと一緒にトレース ビューアまたはストリーミング トレース ビューアを使用すると、モデルを微調整して Cloud TPU でのパフォーマンスを改善できます。
モデルグラフ
モデリング フレームワークで、モデルからグラフが生成される場合があります。グラフのデータは、--logdir パラメータで指定したストレージ バケットの MODEL_DIR ディレクトリに保存されます。このグラフは、capture_tpu_profile を実行しなくても表示できます。
モデルのグラフを表示するには、TensorBoard の [Graphs] タブを選択します。
構造グラフ内のノードは 1 つの演算を表しています。
TPU 互換性グラフ
[Graphs] タブには、モデルの実行時に問題を引き起こす可能性がある演算をチェックして表示する互換性チェック モジュールがあります。
モデルの TPU 互換性グラフを表示するには、TensorBoard の [Graphs] タブを選択してから [TPU Compatibility] オプションを選択します。互換性のある有効な演算は緑色で表示され、互換性のない無効な演算は赤色で表示されます。
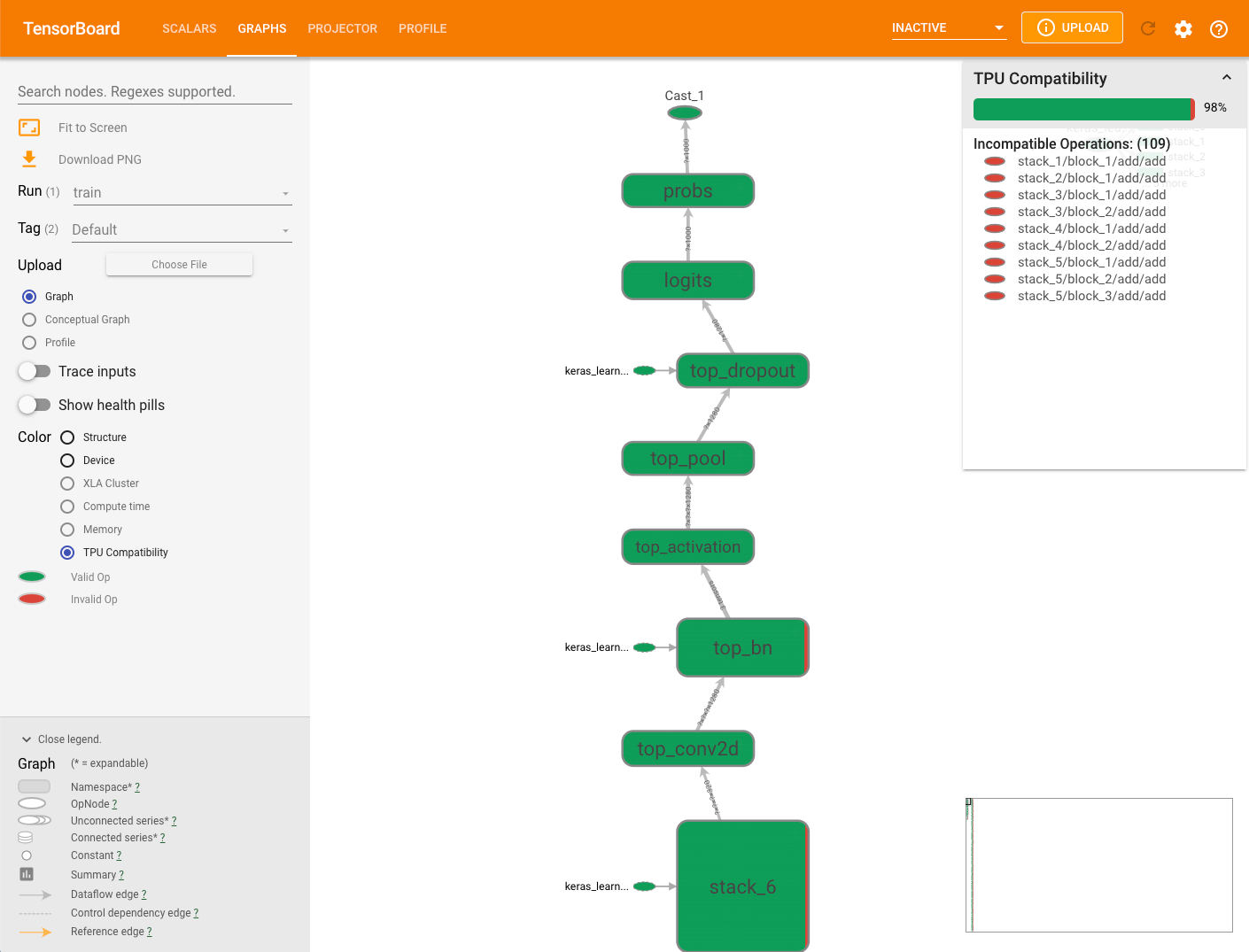
Cloud TPU と互換性のある演算が色別で表示されるだけでなく、各ノードの演算の互換性のレベルも表示できます。互換性の結果の意味をご覧ください。
グラフの右側に表示されている互換性のサマリーパネルには、Cloud TPU と互換性のある演算の割合、それらの属性、選択されたノードで互換性のない演算の一覧が表示されます。
グラフで演算をクリックすると、その属性がサマリーパネルに表示されます。
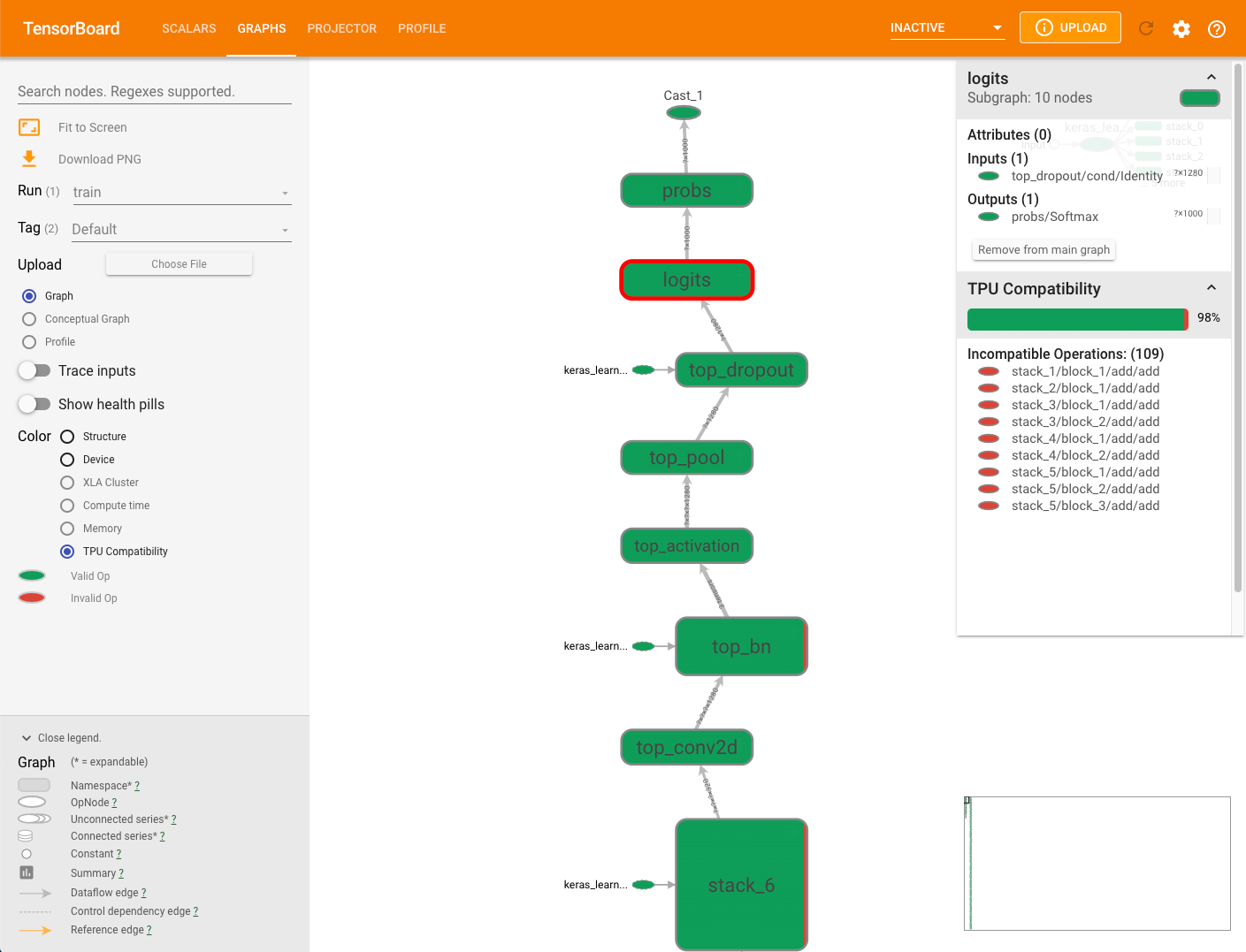
互換性チェッカーは、手動デバイス割り当てを使用して TPU 以外のデバイスに明示的に割り当てられた演算を評価しません。また、実際にモデルをコンパイルして実行するわけでもありません。互換性の予測値として結果を解釈してください。
互換性の結果の意味
プロフィール
[Profile] タブは、一部のモデルデータがキャプチャされると表示されます。TensorBoard ページの右上にある再読み込みボタンをクリックする必要がある場合もします。データが利用可能になり、[Profile] タブをクリックすると、パフォーマンス分析に役立つ次のようなツールが表示されます。
- 概要ページ
- 入力パイプライン分析ツール
- XLA 演算プロファイル
- トレース ビューア(Chrome ブラウザのみ)
- メモリビューア
- Pod ビューア
- ストリーミング トレース ビューア(Chrome ブラウザのみ)
プロファイルの概要ページ
[overview_page] タブにある概要ページ(overview_page)には、キャプチャ中のモデルがどのように実行されたかが表示されます。このページには、すべての TPU を集計した概要と入力パイプライン全体の分析結果が表示されます。[Host] プルダウンから特定の TPU を選択することもできます。
このページでは、次のパネルにデータが表示されます。
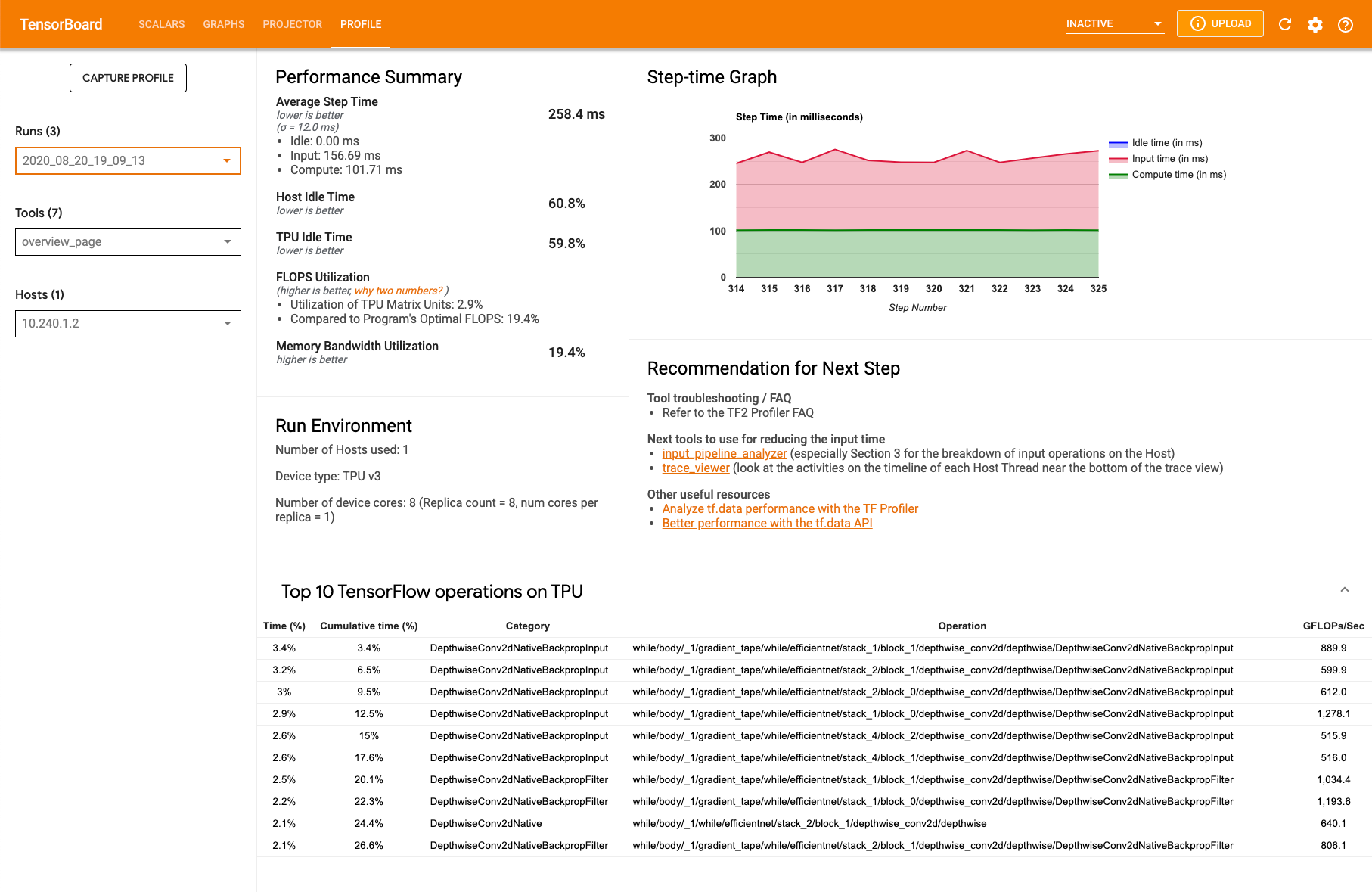
パフォーマンス サマリー
- 平均ステップ時間 - サンプリングされたすべてのステップの平均ステップ時間
- ホストのアイドル時間 - ホストがアイドル状態だった時間の割合
- TPU のアイドル時間 - TPU がアイドル状態だった時間の割合
- FLOPS 使用率 - TPU マトリックス ユニットの使用率
- メモリ帯域幅使用率 - 使用されたメモリ帯域幅の割合
ステップ時間のグラフ。サンプリングされたすべてのステップのデバイス ステップ時間(ミリ秒)がグラフに表示されます。青色の領域は、TPU がホストからの入力データを待機しているステップ時間を表します。赤色の領域は、Cloud TPU が実際に稼働していた時間数に対応します。
TPU での上位 10 個の TensorFlow 演算。多くの時間が費やされた TensorFlow 演算が表示されます。
各行は、演算に費やされた自己時間(すべての演算にかかった時間に占める割合)、累積時間、カテゴリ、名前、FLOPS 率を示します。
実行環境
- 使用されたホストの数
- 使用された TPU のタイプ
- TPU コアの数
- トレーニング バッチサイズ
次の推奨ステップ。モデルで入力処理の負荷が高くなった場合や、Cloud TPU で問題が発生した場合に報告されます。提案ツールを使用すると、パフォーマンスのボトルネックを見つけることができます。
入力パイプライン分析ツール
入力パイプライン分析ツールを使用すると、パフォーマンスの結果をより詳しく分析できます。このツールは、capture_tpu_profile ツールが収集した input_pipeline.json ファイルからパフォーマンスの結果を表示します。
このツールは、プログラムで負荷の高い入力処理をすぐに通知します。デバイス側とホスト側で分析を行い、ボトルネックとなっているパイプラインのステージをデバッグできます。
パイプラインのパフォーマンスの最適化について詳しくは、入力パイプラインのパフォーマンスに関するガイダンスをご覧ください。
入力パイプライン
TensorFlow プログラムがファイルからデータを読み込むと、TensorFlow グラフにパイプライン方式でデータが表示されます。読み取りプロセスは連続した複数のデータ処理ステージに分割され、1 つのステージの出力が次のステージの入力となります。この読み込み方式を入力パイプラインといいます。
ファイルからレコードを読み取るための一般的なパイプラインには、次のステージがあります。
- ファイルの読み取り
- ファイルの前処理(オプション)
- ホストマシンからデバイスへのファイル転送
入力パイプラインが非効率な場合、アプリケーションの速度が大幅に低下する可能性があります。入力パイプラインに多くの時間が費やされている場合、このアプリケーションは入力バウンドとみなされます。入力パイプライン分析ツールを使用すると、非効率な入力パイプラインを特定できます。
入力パイプライン ダッシュボード
入力パイプライン分析ツールを開くには、[Profile] を選択し、[Tools] プルダウンから [input_pipeline_analyzer] を選択します。
ダッシュボードは 3 つのセクションから構成されます。
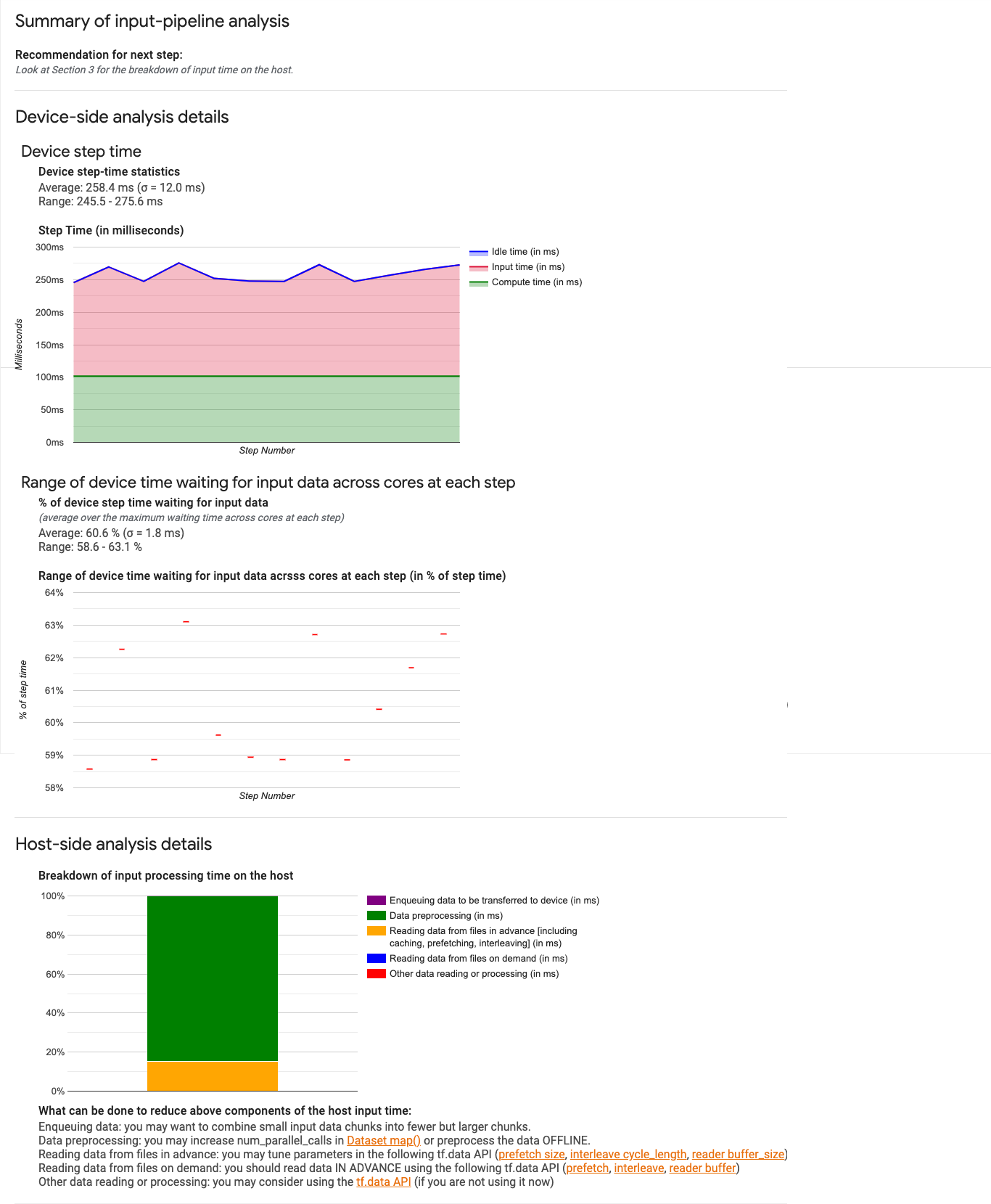
- サマリー。入力パイプライン全体のサマリーが表示されます。たとえば、アプリケーションが入力バウンドかどうか表示されます。入力バウンドの場合はその量も表示されます。
- デバイス側の分析。デバイス側の分析結果が表示されます。デバイスのステップ時間、各ステップのコアで入力データの待機に費やしたデバイス時間などが表示されます。
- ホスト側の分析。ホスト側の分析結果が表示されます。ホスト上での入力処理時間の内訳などが表示されます。
入力パイプラインのサマリー
最初のセクションでは、ホストからの入力の待機に費やされたデバイス時間の割合が表示されます。これにより、プログラムが入力バウンドかどうか確認できます。インストゥルメント化された標準の入力パイプラインを使用している場合は、多くの入力処理時間が費やされている部分を確認できます。次に例を示します。

デバイス側の分析
2 番目のセクションでは、デバイス側の詳しい分析結果が表示されます。デバイスとホストの間で費やされた時間、ホストからの入力データの待機に費やされたデバイス時間などが表示されます。
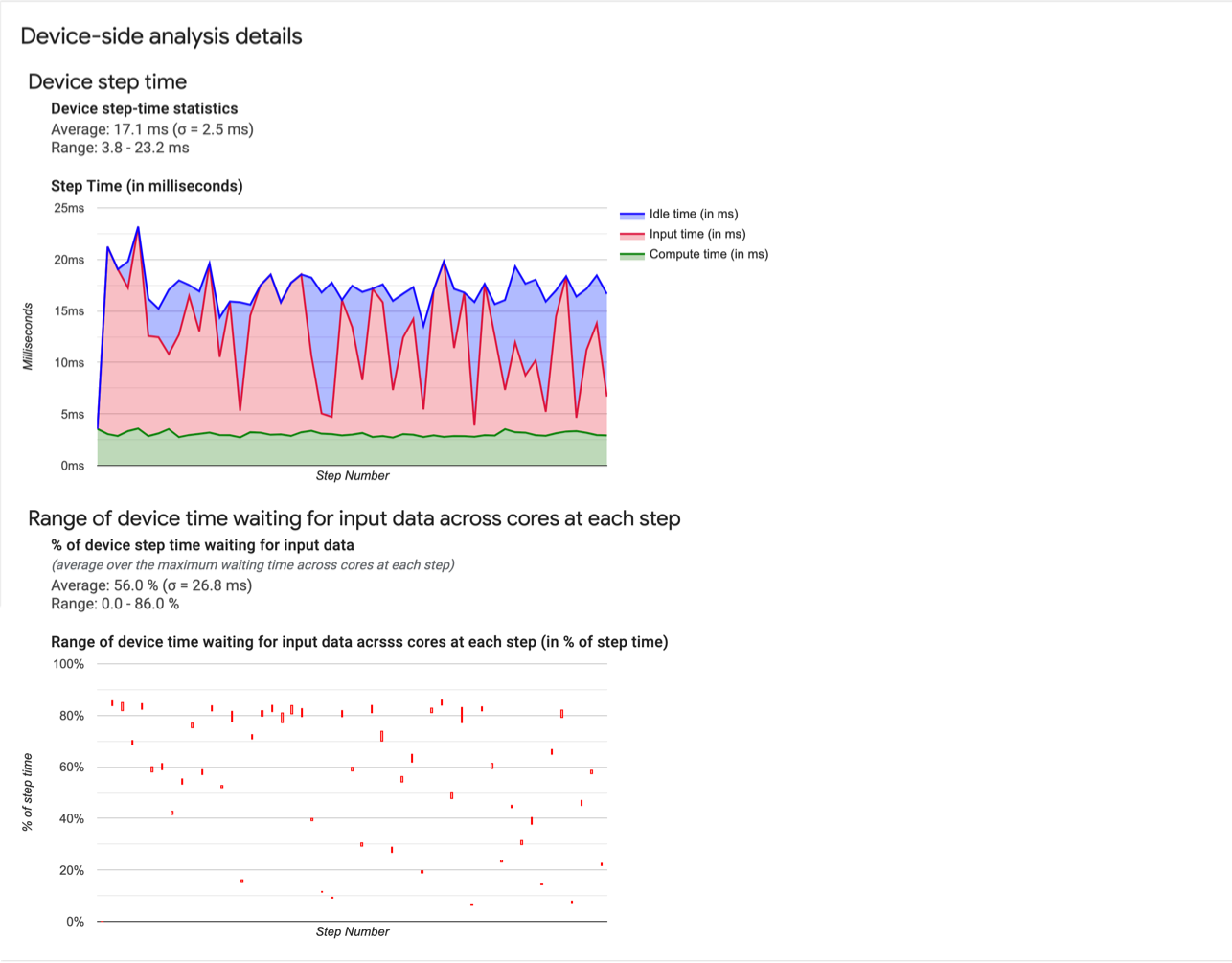
- デバイスのステップ時間の統計情報。デバイス ステップ時間の平均、標準偏差、範囲(最小、最大)が報告されます。
- ステップ時間。サンプリングされたすべてのステップのデバイス ステップ時間(ミリ秒)がグラフに表示されます。青色の領域は、Cloud TPU がホストからの入力データを待機していたステップ時間の部分を表します。赤色の領域は、Cloud TPU が実際に稼働していた時間数に対応します。
- 入力データを待機している時間の割合。入力データを待機していた時間の平均、標準偏差、範囲(最小、最大)が、デバイスの合計ステップ時間で正規化されて表示されます。
- 入力データの待機に費やされた各コアのデバイス時間の範囲(ステップ番号別)。入力データ処理の待機に費やされたデバイス時間の割合を示す折れ線グラフを表示します(デバイスの合計ステップ時間との割合で表されます)。消費される時間の割合はコアごとに異なるため、各コアに対する割合の範囲もステップごとにプロットされます。ステップにかかる時間は最も遅いコアによって決まるため、範囲はできる限り小さくする必要があります。
ホスト側の分析
セクション 3 にはホスト側の分析の詳細が表示されます。これにより、ホスト上での入力処理時間(データセット API 演算に費やされた時間)をいくつかのカテゴリに分類した内訳が報告されます。
- デバイスに転送するデータのエンキュー。デバイスへの転送前にデータがインフィード キューに追加される際に費やされた時間。
- データの前処理。画像の圧縮など、前処理操作に費やされた時間。
- ファイルからの事前のデータ読み取り。キャッシング、プリフェッチ、インターリーブなど、ファイルの読み取りに費やされた時間。
- ファイルからのオンデマンドのデータ読み取り。キャッシュ、プリフェッチ、インターリーブなしで、ファイルからデータを読み取る際に費やされた時間。
- その他のデータの読み取りまたは処理。
tf.dataを使用しない、その他の入力関連のオペレーションに費やされた時間。

個々の入力演算の統計とそのカテゴリの内訳を実行時間別に表示するには、[Show Input Op statistics] セクションを展開します。
ソースデータ テーブルは次のようになります。
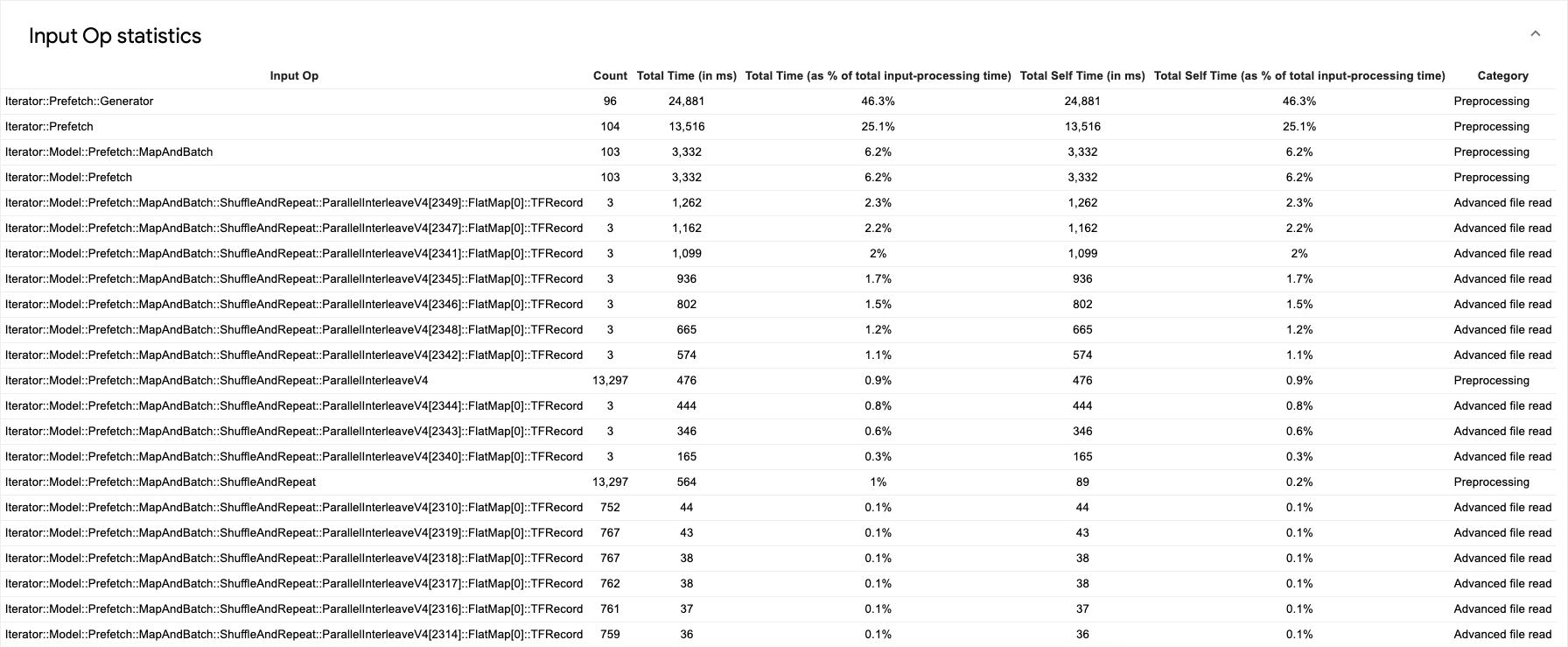
各テーブル エントリには、次の情報が含まれます。
- 入力演算。入力演算の TensorFlow 演算名が表示されます。
- 件数。プロファイリング期間中に実行された演算のインスタンスの合計数が表示されます。
- 合計時間(ミリ秒)。各演算インスタンスに費やされた時間の累積合計が表示されます。
- 合計時間(%)。演算に費やされた合計時間が、入力処理に費やされた合計時間との割合で表示されます。
- 合計自己時間(ミリ秒)。各インスタンスに費やされた自己時間の累積合計が表示されます。この自己時間は、関数本体内で費やされた時間を測定したもので、関数本体から呼び出される関数で費やされた時間は含まれません。たとえば、
Iterator::PaddedBatch::Filter::ForeverRepeat::MapはIterator::PaddedBatch::Filterによって呼び出されるため、その合計自己時間は、後者の合計自己時間から除外されます。 - 合計自己時間(%)。合計自己時間が、入力処理に費やされた合計時間との割合で表示されます。
- カテゴリ。入力演算の処理カテゴリを示します。
演算プロファイル
演算プロファイルは、プロファイリング期間中に実行された XLA 演算のパフォーマンス統計を表示する Cloud TPU ツールです。演算プロファイルには次の情報が表示されます。
- アプリケーションによる Cloud TPU の使用状況。演算に費やされた時間の割合がカテゴリ別に表示されます。また、TPU FLOPS の使用率も表示されます。
- 最も時間のかかる演算。これらの演算は、最適化の潜在的なターゲットとなります。
- 個々の演算の詳細。演算で使用される形状、パディング、式などが表示されます。
演算プロファイルを使用すると、最適化のターゲットを見つけることができます。たとえば、モデルで TPU のピーク FLOPS が 5% にすぎない場合、このツールを使用して、実行に最も時間を費やした XLA 演算とその演算による TPU FLOPS の使用量を特定できます。
演算プロファイルの使用
プロファイル収集中、capture_tpu_profile は XLA 演算のパフォーマンス統計を含む op_profile.json ファイルも作成します。
TensorBoard の op_profile からデータを表示するには、画面上部の [Profile] タブをクリックし、[Tools] プルダウンから op_profile を選択します。次のような画面が表示されます。
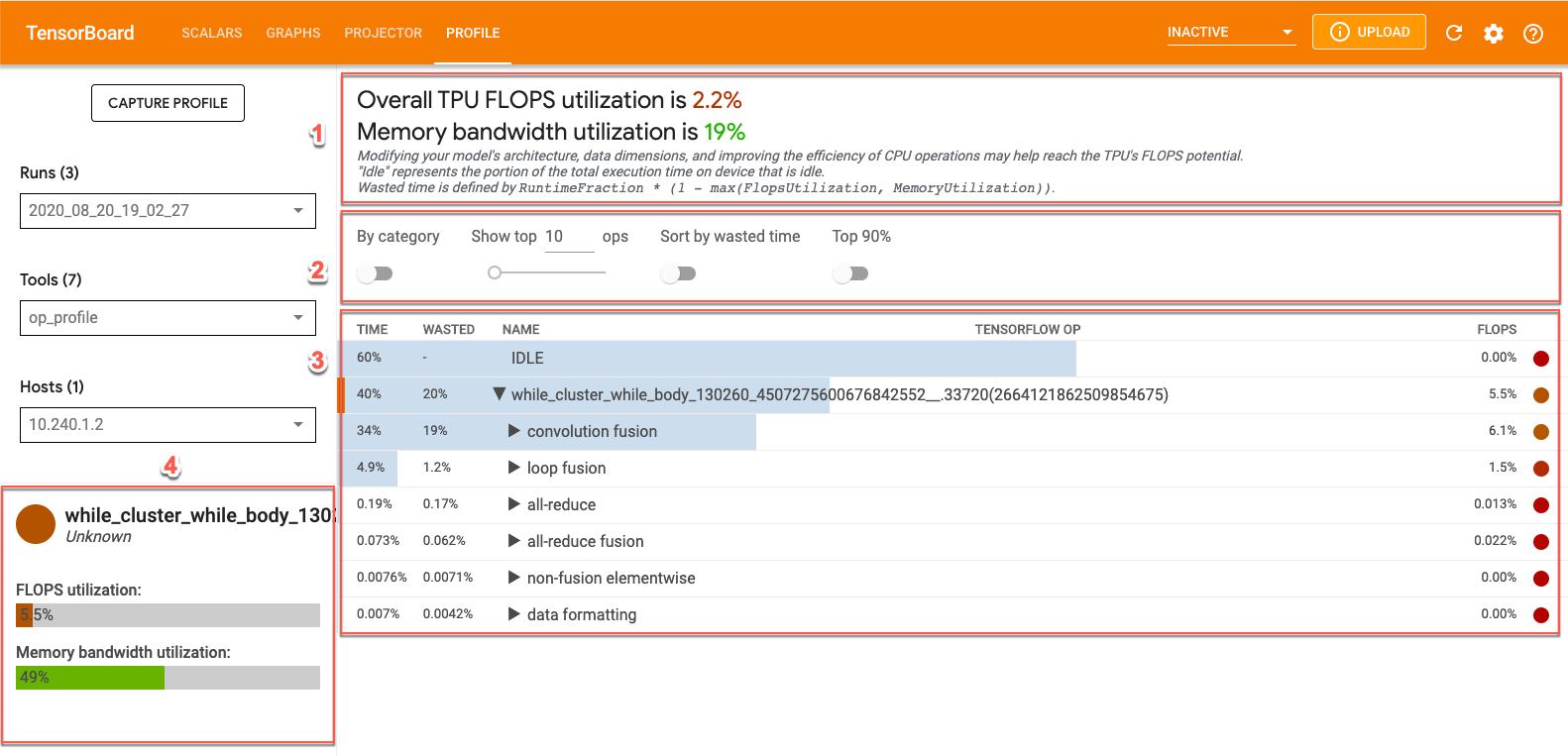
- 概要セクション。Cloud TPU の使用率を表示し、最適化のための推奨事項が表示されます。
- コントロール パネル。表に表示される演算の数、表示される演算、並べ替え方法を設定するためのコントロールが含まれます。
- 演算テーブル。XLA 演算に関連付けられている TensorFlow 演算の上位カテゴリを一覧表示する表。これらの演算は、Cloud TPU 使用率の順に並んでいます。
- 演算詳細カード。テーブル内の演算にカーソルを合わせると、演算に関する詳細情報が表示されます。FLOPS 使用率、演算が使用されている式、演算レイアウト(fit)などが表示されます。
XLA 演算テーブル
演算テーブルには、Cloud TPU 使用率の高い順に XLA 演算が表示されます。最初の段階では、カテゴリの実行時間の割合、演算カテゴリ名、関連する TensorFlow 演算名、FLOPS 使用率が表示されます。カテゴリで最も時間のかかる XLA 演算の上位 10 個の表示と非表示を切り替えるには、テーブル内のカテゴリ名の横にある三角形をクリックします。
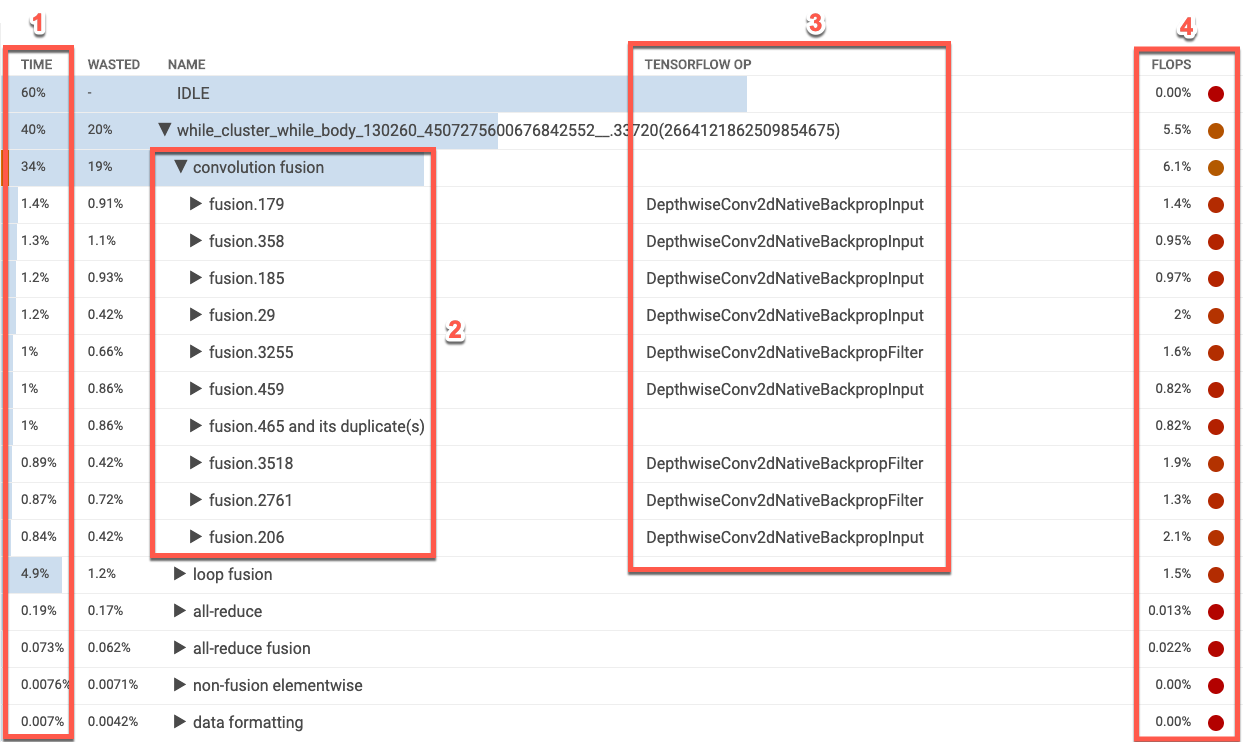
- 時間。そのカテゴリに含まれるすべての演算の実行時間の合計を割合で表します。クリックするとエントリが展開され、個々の演算によって費やされた時間の内訳が表示されます。
- 上位 10 個の演算。カテゴリ名の横にあるトグルを使用すると、カテゴリ内で時間のかかる上位 10 個の演算を表示または非表示にできます。演算リストに fusion 演算が表示されている場合、このエントリを展開すると、fusion 以外の要素ごとの演算が表示されます。
- TensorFlow 演算。XLA 演算に関連付けられる TensorFlow 演算名が表示されます。
- FLOPS。FLOPS 使用率が表示されます。FLOPS の測定値が Cloud TPU ピーク FLOPS の割合として表示されます。FLOPS 使用率が高いほど、演算が速くなります。テーブルセルは色分けされています。FLOPS 使用率が高い場合には緑色(良好)、FLOPS 使用率が低い場合には赤色(不良)です。
演算詳細カード
テーブル エントリを選択すると、左側にカードが表示され、XLA 演算または演算カテゴリの詳細が表示されます。通常、次のようなカードが表示されます。
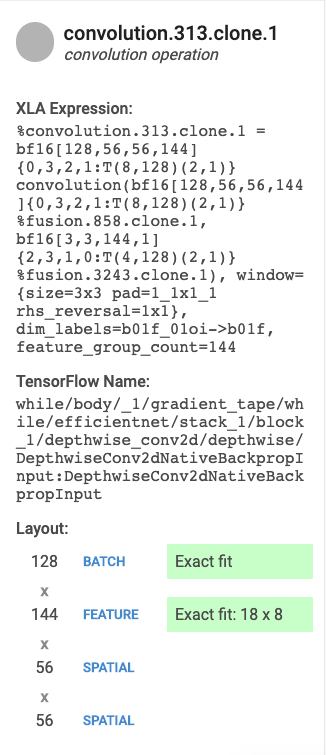
- 名前とカテゴリ。XLA 演算名とカテゴリが表示されます。
- FLOPS 使用率。FLOPS の使用率が FLOPS の合計数との割合で表示されます。
- 式。演算を含む XLA 式が表示されます。
- メモリ使用率。プログラムによるピーク時のメモリ使用率が表示されます。
- レイアウト(畳み込み演算のみ)。テンソルの形状とレイアウトが表示されます。テンソルの形状がマトリックス ユニットに正確に一致しているかどうか、形状がどのようにパディングされているかも表示されます。
結果の解釈
畳み込み演算の場合、次のいずれかまたは両方の理由で、TPU FLOPS の使用率が低くなることがあります。
- パディング(マトリックス ユニットが部分的に使用されている)
- 畳み込み演算がメモリバインドになっている
このセクションでは、FLOPS が低い別のモデルの数値について解釈します。この例では、output fusion と convolution が実行時間の大半を占め、FLOPS が非常に低いベクトル演算またはスカラー演算が長く続いています。
このようなプロファイルを最適化する方法としては、ベクトル演算またはスカラー演算を畳み込み演算に変換する方法があります。
次の例で、%convolution.399 は前の例の %convolution.340 よりも FLOPS とメモリ使用率が低くなっています。
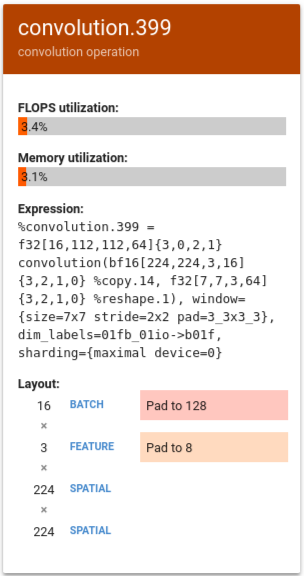
レイアウトを確認すると、バッチサイズ 16 が 128 にパディングされ、特徴サイズ 3 が 8 にパディングされていることがわかります。これは、マトリックス ユニットの 5% しか効率的に使用されていないことを示します。(この使用率の計算では、(((batch_time * num_of_features) / padding_size ) / num_of_cores) となります)。この例の FLOPS を前の例の %convolution.340 と比較すると、マトリックスに完全に適合していることがわかります。
Pod ビューア
Pod ビューアツールを使用すると、Pod 内の各コアのパフォーマンスを視覚的に表示し、Pod 内のコア間の通信チャネルのステータスを確認できます。Pod ビューアでは、潜在的なボトルネックや最適化が必要な領域が強調表示されます。このツールは、完全なポッドとすべての v2 / v3 Pod スライスに対応しています。
Pod ビューアツールを表示するには:
- Tensorboard ウィンドウの右上にあるメニューボタンから [Profile] を選択します。
- ウィンドウの左側にある [Tools] メニューをクリックして、[pod_viewer] を選択します。
Pod ビューアのユーザー インターフェースには次のものが表示されます。
- ステップ スライダー。調べたいステップを選択できます。
- トポロジグラフ。TPU システム全体で TPU コアをインタラクティブに視覚化できます。
- 通信リンクのグラフ。トポロジグラフの送受信チャネルが視覚的に表示されます。
- 送受信チャネルのレイテンシを示す棒グラフ。このグラフの棒にカーソルを合わせると、通信リンクのグラフが表示されます。左側のバーにチャンネル詳細カードが表示され、転送されたデータのサイズ、レイテンシ、帯域幅などのチャンネル情報が表示されます。
- ステップ内訳グラフ。すべてのコアステップの内訳が視覚的に表示されます。これは、システムのボトルネックや、システムの処理速度を低下させているコアの特定に使用します。
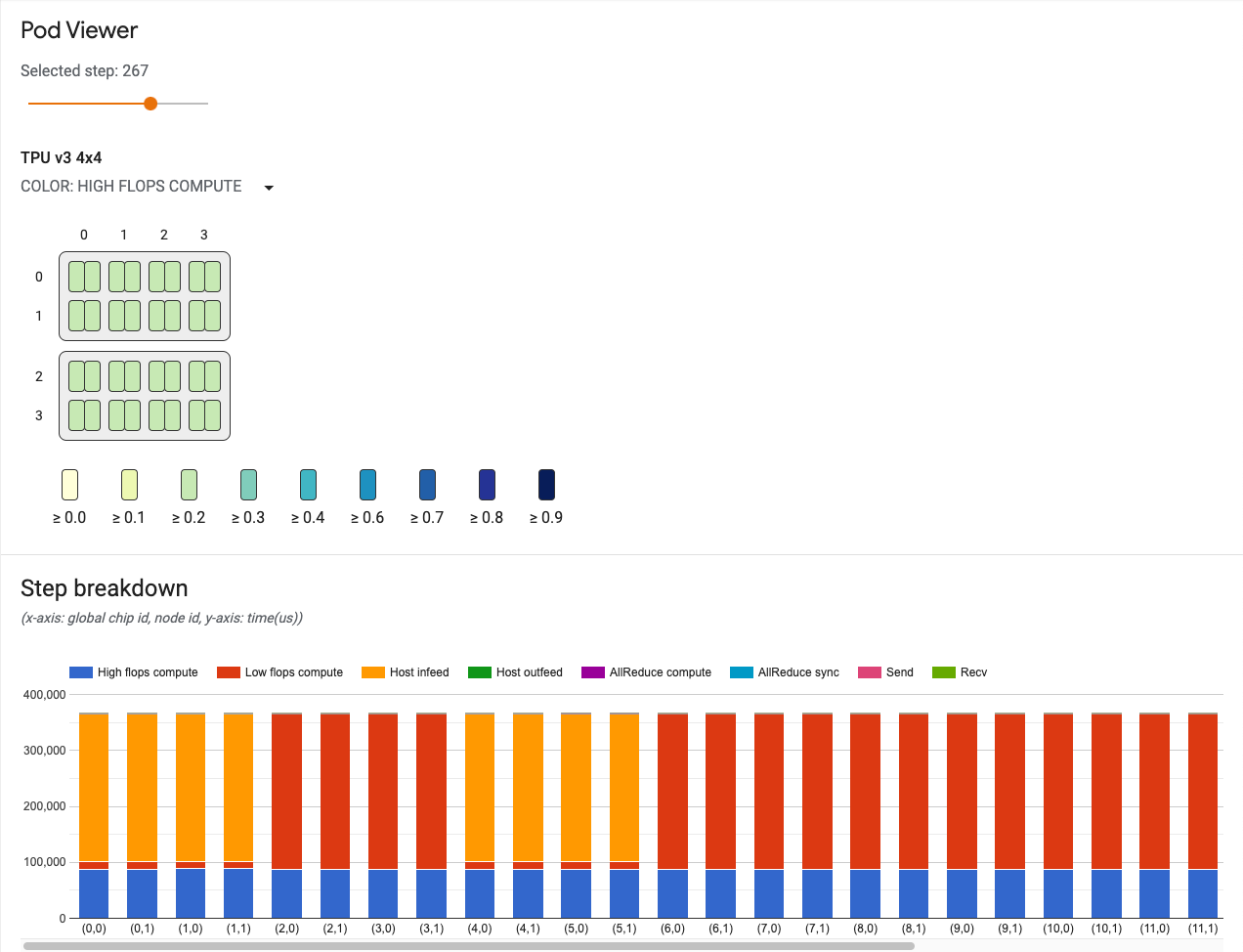
ステップ スライダー
スライダーでステップを選択します。ツールの残りの部分には、そのステップの内訳や通信リンクなどの統計が表示されます。
トポロジグラフ
トポロジグラフには、ホスト、チップ、コアが階層的に表示されます。TPU コアは、最小の長方形で表示されます。2 つのコアが TPU チップを表し、4 つのチップが 1 つのホストを表します。
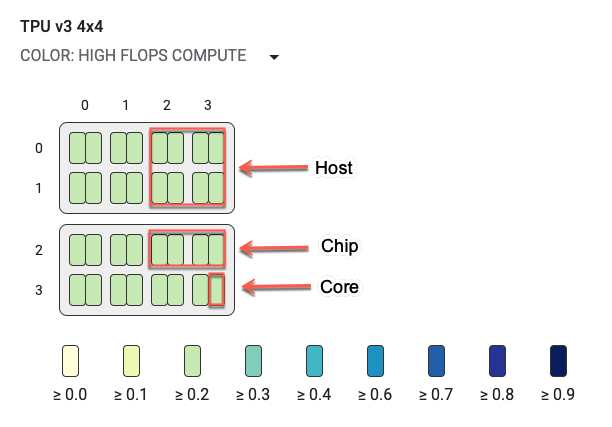
トポロジグラフはヒートマップでもあり、選択したステップで特定の内訳(高 FLOPS、インフィード、送信など)に費やされた時間の割合で色分けされています。トポロジグラフのすぐ下のバー(次の図を参照)には、コアとチップの使用状況が色別で表示されます。コアの色は使用率を表し、黄色から青色の範囲で表示されます。FLOPS が高いコンピューティングの場合、数値が大きく(色が濃く)なればなるほど、コンピューティングに費やされる時間が長くなります。それ以外の内訳では、数値が小さく(色が薄く)なればなるほど、待機時間が短くなります。他のコアより暗い色の部分は、潜在的な問題が存在しているか、ホットスポットになっています。
システム名の隣にあるプルダウン メニューのセレクタ(上の図で赤丸の部分)をクリックすると、特定の内訳を選択できます。
小さな四角形(単一コア)にカーソルを合わせると、システム内でのコアの位置、グローバル チップ ID、ホスト名などを含むヒントが表示されます。このヒントには、選択した内訳カテゴリ(高 FLOPS など)の期間およびステップでのその使用率も表示されます。
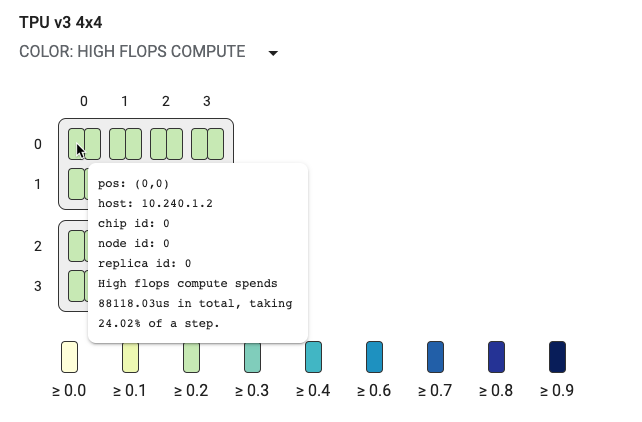
通信チャネル
このツールは、モデルがコア間の通信に使用する送受信リンクの可視化に役立ちます。モデルに send 演算と recv 演算が含まれている場合、チャネル ID セレクタを使用してチャネル ID を選択できます。送信元(src)コアと宛先(dst)コアからのリンクが通信チャネルを表します。送信チャネルと受信チャネルのレイテンシを示すグラフのバーにカーソルを合わせると、チャネルの情報がトポロジグラフに表示されます。

左側のバーにカードが表示され、通信チャネルの詳細が表示されます。通常、次のようなカードが表示されます。
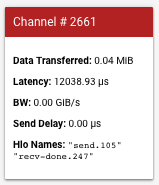
- データ通信量。送受信チャネルで転送されたデータの量が MiB 単位で表示されます。
- レイテンシ。送信イベントの開始から受信完了イベントの終了までの時間がマイクロ秒単位で表示されます。
- BW。期間内に送信元コアから宛先コアに転送されたデータ量が GiB 単位で表示されます。
- 送信遅延。受信完了から送信開始までの時間がマイクロ秒単位で表示されます。send 演算の開始後に recv-done 演算が開始した場合、遅延はゼロになります。
- HLO 名。このチャネルに関連付けられた XLA HLO 演算の名前が表示されます。この HLO 名は、他の TensorBoard ツール(op_profile、memory_viewer など)に表示される統計に関連付けられています。
ステップ内訳グラフ
このグラフには、トレーニングまたは評価ステップの詳細が表示されます。
X 軸はグローバル チップ ID を表し、Y 軸が時間(ミリ秒)を表します。このグラフでは、特定のトレーニング ステップで使用された時間を確認できます。また、ボトルネックの存在や、チップ全体の負荷バランスの問題も確認できます。
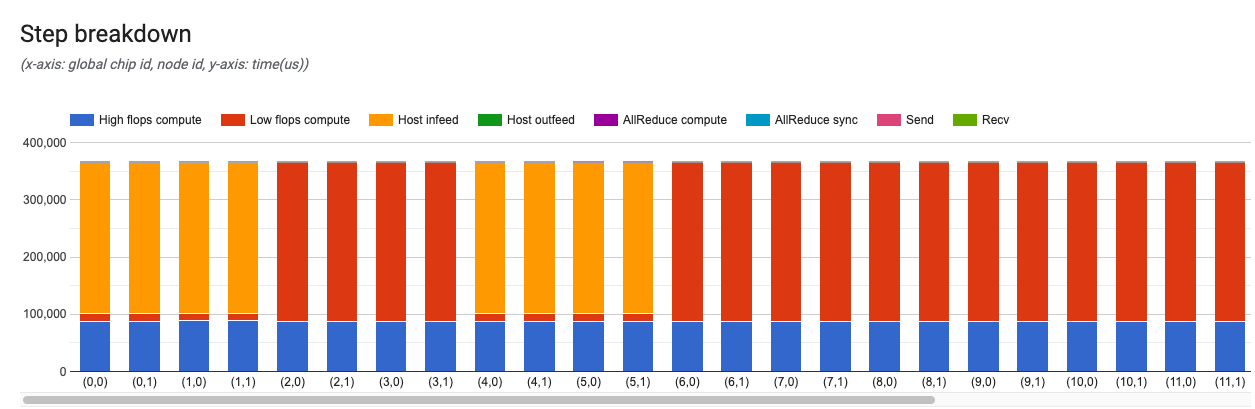
左側のバーにカードが表示され、ステップ内訳の詳細を確認できます。通常、次のようなカードが表示されます。
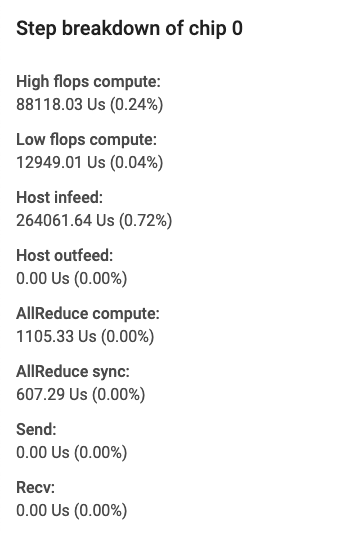
カードのフィールドには、次の情報が表示されます。
- 高 FLOPS 計算。convolution 演算または output fusion 演算に費やされた時間。
- 低 FLOPS 計算。合計時間から他のすべての内訳を減算して計算されます。
- インフィード。TPU がホストの待機に費やした時間。
- アウトフィード。ホストが TPU からの出力を待機した時間。
- AllReduce 同期。他のコアとの同期を待機している CrossReplicaSum 演算に費やされた時間。CrossReplicaSum 演算はレプリカ全体の合計をコンピューティングします。
- AllReduce コンピューティング。CrossReplicaSum 演算に費やされた実際のコンピューティング時間です。
- チップ間の send 演算。send 演算に費やされた時間。
- チップ間の recv-done 演算。recv 演算に費やされた時間。
トレース ビューア
トレース ビューアは、[Profile] で利用可能な Cloud TPU パフォーマンス分析ツールです。このツールは、Chrome トレース イベント プロファイリング ビューアを使用するため、Chrome ブラウザでのみ機能します。
トレース ビューアには次のタイムラインが表示されます。
- TensorFlow モデルによって実行された演算の実行期間。
- 演算を実行したシステムの部分(TPU またはホストマシン)。通常、ホストマシンがトレーニング データを前処理して TPU に転送する infeed 演算を実行し、TPU は実際のモデル トレーニングを行います。
トレース ビューアを使用して、モデル内のパフォーマンスの問題を特定し、この問題を解決する対策を講じることができます。たとえば、大まかには、インフィードとモデル トレーニングのどちらに大部分の時間を費やしているかどうかを識別できます。さらに詳しく見ると、実行に最も時間がかかっている TensorFlow 演算も識別できます。
トレース ビューアは、Cloud TPU ごとに 1M イベントに制限されています。他のイベントを評価する場合は、代わりにストリーミング トレース ビューアを使用してください。
トレース ビューアのインターフェース
トレース ビューアを開くには、TensorBoard に移動して画面上部の [Profile] タブをクリックし、[Tools] プルダウンから [trace_viewer] を選択します。ビューアが開き、最新の実行結果が表示されます。
この画面には、次の主要な要素(上で番号が付けられています)が表示されます。
- [Runs] プルダウン。トレース情報をキャプチャしたすべての実行が表示されます。デフォルトのビューは最新の実行ですが、プルダウンを開いて別の実行を選択することもできます。
- [Tools] プルダウン。さまざまなプロファイリング ツールを選択します。
- [Host] プルダウン。Cloud TPU セットを含むホストを選択します。
- [Timeline] ペイン。Cloud TPU とホストマシンで実行された演算が時系列で表示されます。
- [Details] ペイン。[Timeline] ペインで選択した演算の詳細情報が表示されます。
では、[Timeline] ペインについて詳しく見てみましょう。
[Timeline] ペインには、次の要素が含まれます。
- 上部バー。さまざまな補助コントロールが表示されます。
- 時間軸。トレースの開始位置を基準にした時間が表示されます。
- セクションとトラックラベル。各セクションには複数のトラックが含まれています。左側にある三角形をクリックすると、セクションの展開や折りたたみを行うことができます。システムで処理中の要素ごとに 1 つのセクションがあります。
- ツールセレクタ。トレース ビューアを操作するさまざまなツールが用意されています。
- イベント。これらのイベントは、演算が実行されていた時間やトレーニング ステップなどのメタイベントの期間を示します。
- 垂直タブバー。Cloud TPU での使用は適しません。このバーは、Chrome が提供する汎用のトレース ビューアツールの一部で、さまざまなパフォーマンス分析タスクに使用されます。
セクションとトラック
トレース ビューアには、次のセクションがあります。
- TPU ノードごとに 1 つのセクション。ラベルとして TPU チップの数とチップ内の TPU ノードの数が使用されます(例: 「Chip 2: TPU Core 1」)。TPU ノードのセクションには、次のトラックが含まれます。
- Step。TPU で実行されていたトレーニング ステップの期間が表示されます。
- TensorFlow Ops。TPU 上で実行される TensorFlow 演算が表示されます。
- XLA Ops。TPU 上で実行された XLA 演算が表示されます。1 つの演算が 1 つ以上の XLA 演算に変換されます。XLA コンパイラにより、XLA 演算が TPU 上で実行されるコードに変換されます。
- ホストマシンの CPU 上で実行されるスレッドのセクション。「Host Threads」というラベルが付いています。このセクションには、CPU スレッドごとに 1 つのトラックが含まれます。注: セクション ラベルと一緒に表示される情報は無視してもかまいません。
タイムラインのツールセレクタ
TensorBoard のタイムライン ツールセレクタを使用して、タイムライン ビューを操作できます。タイムライン ツールをクリックするか、次のキーボード ショートカットを使用してツールをアクティブにできます。タイムライン ツールセレクタを移動するには、上部の点線部分をクリックしてセレクタを目的の場所にドラッグします。
タイムライン ツールの使い方は次のとおりです。
|
選択ツール イベントをクリックして選択します。複数のイベントを選択するにはドラッグします。選択したイベントに関する詳細情報(名前、開始時間、期間)が、詳細ペインに表示されます。 |
|
パンツール ドラッグしてタイムライン ビューを水平方向または垂直方向にパンします。 |
|
ズームツール 水平方向(時間軸)に沿って上にドラッグするとズームインし、下にドラッグするとズームアウトします。マウスカーソルの水平位置により、ズームが行われる中心が決まります。 注: ズームツールには、マウスカーソルがタイムライン ビューの外部にあるときにマウスボタンを放すと、ズームがアクティブのままになるという既知のバグがあります。これが発生した場合は、タイムライン ビューを軽くクリックすると、ズームが解除されます。 |
|
タイミング ツール 水平方向にドラッグして、時間間隔をマークできます。間隔の長さは時間軸に表示されます。間隔を調整するには、間隔の両端をドラッグします。間隔をクリアするには、タイムライン ビュー内の任意の場所をクリックします。 他のいずれかのツールを選択しても、間隔はマークされたままになることにご注意ください。 |
イベント
タイムライン内のイベントは異なる色で表示されます。色自体には特別な意味はありません。
タイムラインの上部バー
[Timeline] ペインの上部バーには、いくつかの補助コントロールがあります。

- メタデータ表示。TPU では使用しません。
- 表示オプション。TPU では使用しません。
- 検索ボックス。テキストを入力して、名前にそのテキストが含まれるすべてのイベントを検索します。検索ボックスの右側にある矢印ボタンをクリックして、一致するイベントを順方向および逆方向に移動することで順番に各イベントを選択します。
- コンソール ボタン。TPU では使用しません。
- ヘルプボタン。クリックしてヘルプのサマリーを表示します。
キーボード ショートカット
トレース ビューアでは、次のキーボード ショートカットを使用できます。上部バーの [Help] ボタン(?)をクリックすると、キーボード ショートカットがさらに表示されます。
w Zoom in
s Zoom out
a Pan left
d Pan right
f Zoom to selected event(s)
m Mark time interval for selected event(s)
1 Activate selection tool
2 Activate pan tool
3 Activate zoom tool
4 Activate timing tool
f キーのショートカットは非常に便利です。ステップを選択して f キーを押すと、そのステップにすばやくズームインできます。
特徴的なイベント
TPU のパフォーマンスを分析する際に非常に役立つイベントタイプがあります。

InfeedDequeueTuple。この TensorFlow 演算は TPU 上で実行され、ホストから送信される入力データを受信します。インフィードに時間がかかっている場合、ホストマシン上のデータを前処理する TensorFlow 演算が、TPU でデータを消費できる速度に追いついていない可能性があります。InfeedEnqueueTuple というホストトレースで、該当するイベントを確認できます。より詳細な入力パイプラインの分析結果を表示するには、Input Pipeline Analyzer ツールを使用してください。
CrossReplicaSum。この TensorFlow 演算は TPU 上で実行され、レプリカ全体の合計をコンピューティングします。各レプリカは異なる TPU ノードに対応しているため、演算では、すべての TPU ノードでステップが完了するまで待機する必要があります。この演算に時間がかかる場合は、合計の演算自体が遅いのではなく、TPU ノードがデータ インフィードの遅い別の TPU ノードを待機している可能性があります。

- Dataset Ops。データが Dataset API で読み込まれると、トレース ビューアによって、データセット演算が可視化されます。この例の
Iterator::Filter::Batch::ForeverRepeat::Memoryがコンパイルされ、dataset.map()演算に対応します。トレース ビューアで読み込みオペレーションを調査し、デバッグ作業と同時に入力パイプラインのボトルネックを軽減できます。
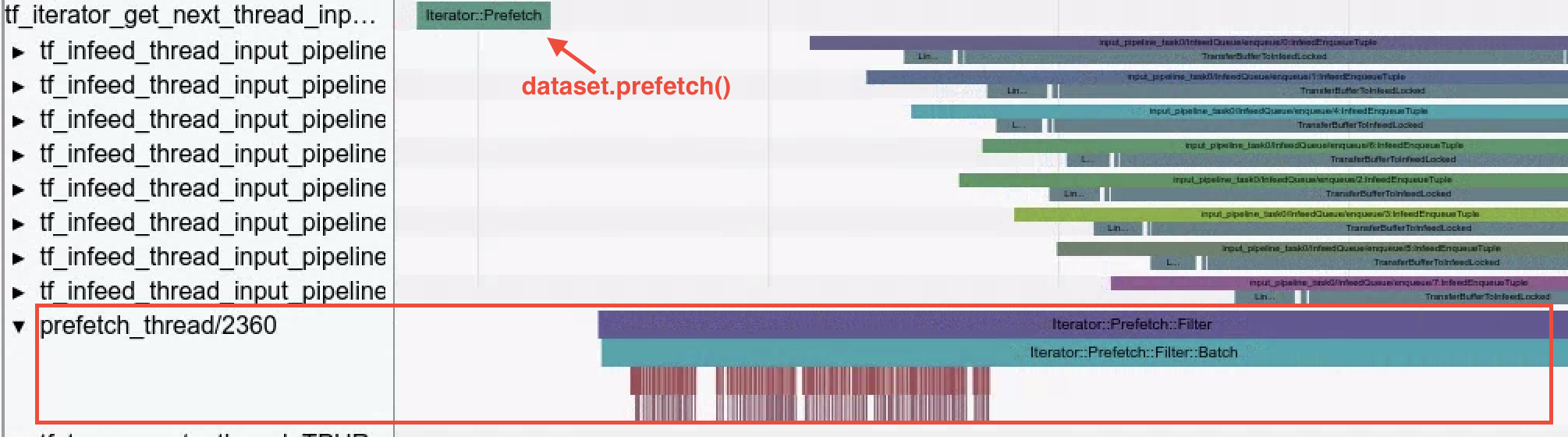
- Prefetch Threads。
dataset.prefetch()を使用して入力データをバッファリングすると、入力パイプラインでボトルネックとなるファイル アクセスの散発的な減速を防ぐことができます。
うまくいかない場合
トレース ビューアを使用する場合は、次の点に注意してください。
- 表示されるイベント数の上限。イベント ビューアには、最大で 100 万件のイベントが表示されます。これ以上のイベントをキャプチャした場合、最初の 100 万件のイベントが表示され、それ以降のイベントは破棄されます。より多くの TPU イベントをキャプチャするには、
--include_dataset_ops=Falseフラグを使用して、capture_tpu_profileでデータセット演算を除外するように明示的に指定する必要があります。 - 非常に長いイベント。キャプチャの開始前に発生したイベントと、キャプチャの終了後に発生したイベントはトレース ビューアに表示されません。結果として、非常に長いイベントが表示されない場合があります。
トレース キャプチャを開始するタイミング。トレース キャプチャは、Cloud TPU の稼働を確認した後に開始してください。それよりも前に開始すると、トレース ビューアに表示されるイベントがないか、少数になることがあります。
--duration_msフラグを使用すると、プロファイリング時間を延長できます。--num_tracing_attemptsフラグを使用すると、自動再試行を設定できます。例:(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000 --num_tracing_attempts=10
メモリビューア
メモリビューアには、プログラムのピーク時のメモリ使用量と、プログラムの存続時間全体でのメモリ使用の傾向が視覚的に表示されます。
メモリビューアの UI は次のようになります。
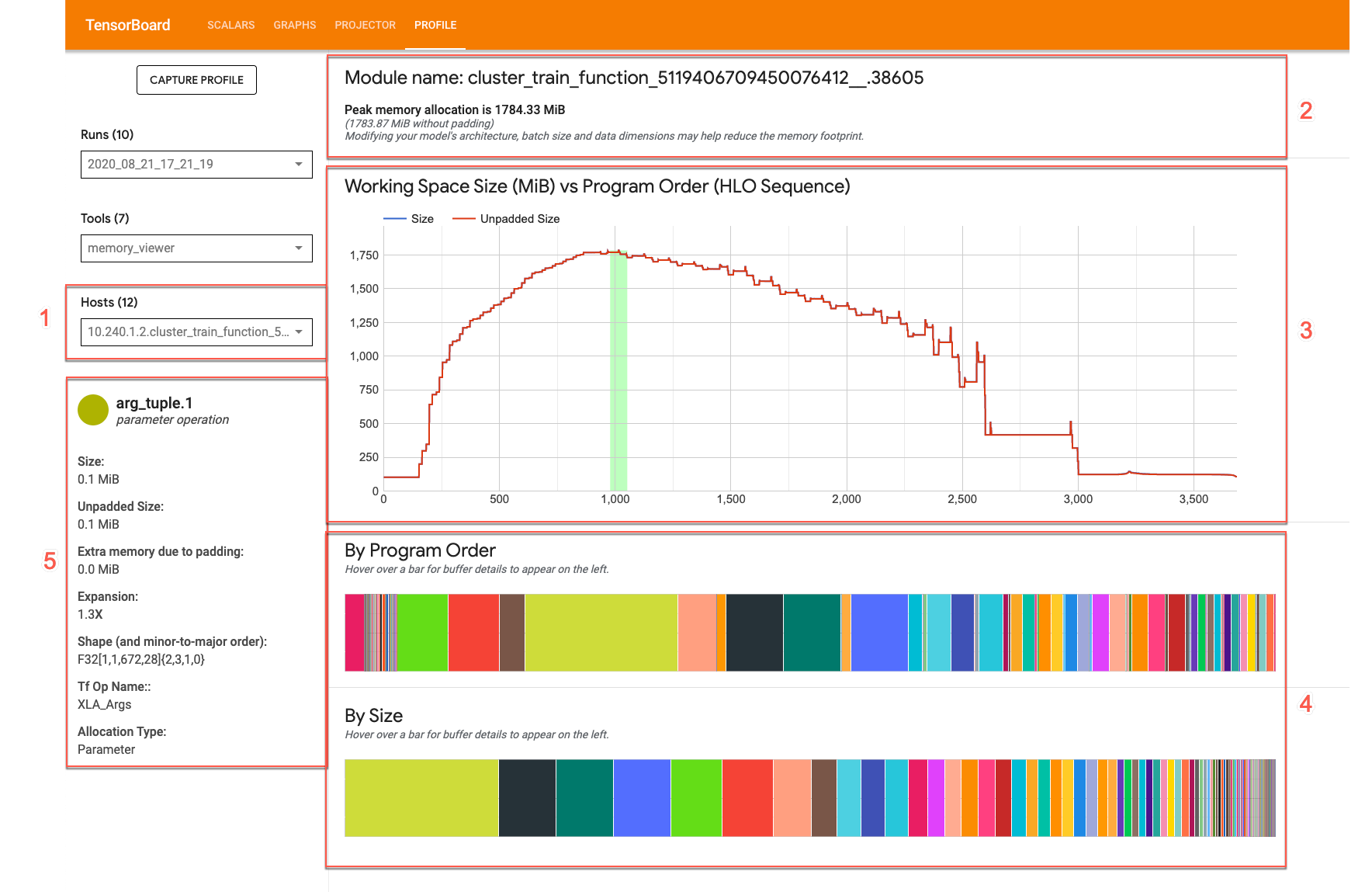
- [Host] プルダウン。表示する TPU ホストと XLA High Level Optimizer(HLO)モジュールを選択します。
- メモリの概要。ピーク時のメモリ割り当てとパディングなしのサイズが表示されます。
- 作業スペースグラフ。ピーク時のメモリ使用量とプログラムの存続期間全体でのメモリ使用の傾向が表示されます。バッファグラフに表示されているバッファにカーソルを合わせると、バッファの存続期間とバッファの詳細カードの注釈が表示されます。
- バッファグラフ。ピーク時のメモリ使用量の時点(作業スペースのプロットの縦線)でのバッファ割り当てを表示する 2 つのグラフが表示されます。いずれかのバッファグラフに表示されているバッファにカーソルを合わせると、作業スペースグラフにバッファの存続期間バーが表示され、左側に詳細カードが表示されます。
- バッファ割り当て詳細カード。バッファの割り当て詳細が表示されます。
メモリ概要パネル
メモリの概要パネルには、合計バッファ割り当てサイズが最大に達したときのモジュール名とピークメモリ割り当てが表示されます。比較のため、パディングされていないピーク割り当てサイズも表示されます。

作業スペースグラフ
このグラフには、ピーク時のメモリ使用量とメモリ使用の傾向が表示されます。プロットの上から下に描かれた線は、プログラムのピーク時のメモリ使用率を表します。このポイントにより、プログラムが使用可能なグローバル メモリ空間に収まるかどうか判断できます。
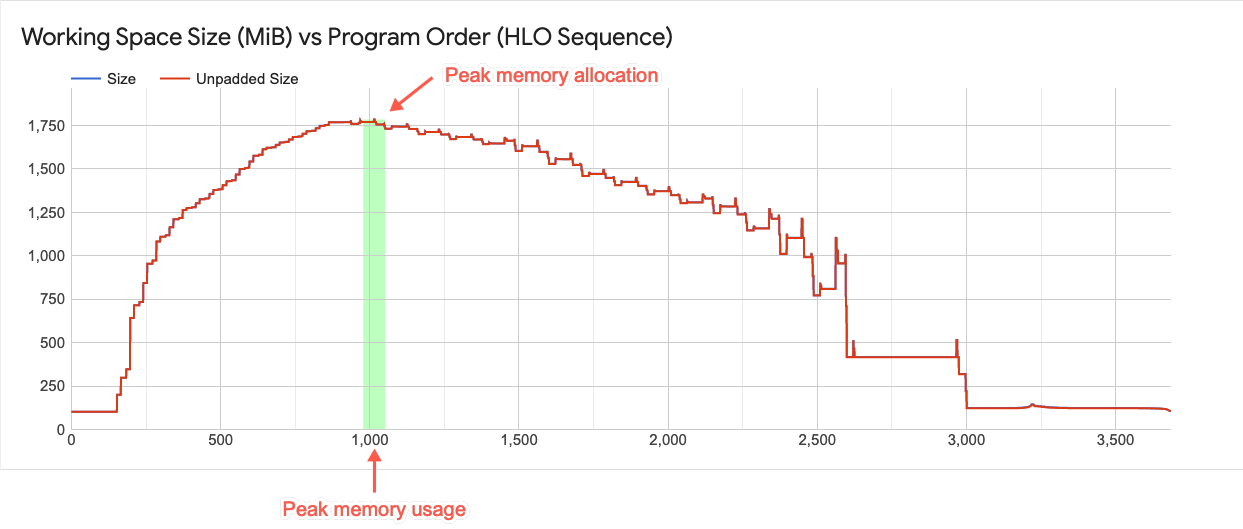
プロット上の各ポイントは、コンパイラによってスケジュールされた、XLA の HLO プログラムにおける「プログラム ポイント」を表します。この線を見ると、ピーク時の使用量に起因する急激な変化がわかります。
バッファグラフ要素の操作
作業スペースグラフの下のバッファグラフに表示されているバッファにカーソルを合わせると、作業スペースグラフにバッファの存続期間が水平線で表示されます。水平線は、強調表示されたバッファと同じ色で表示されます。
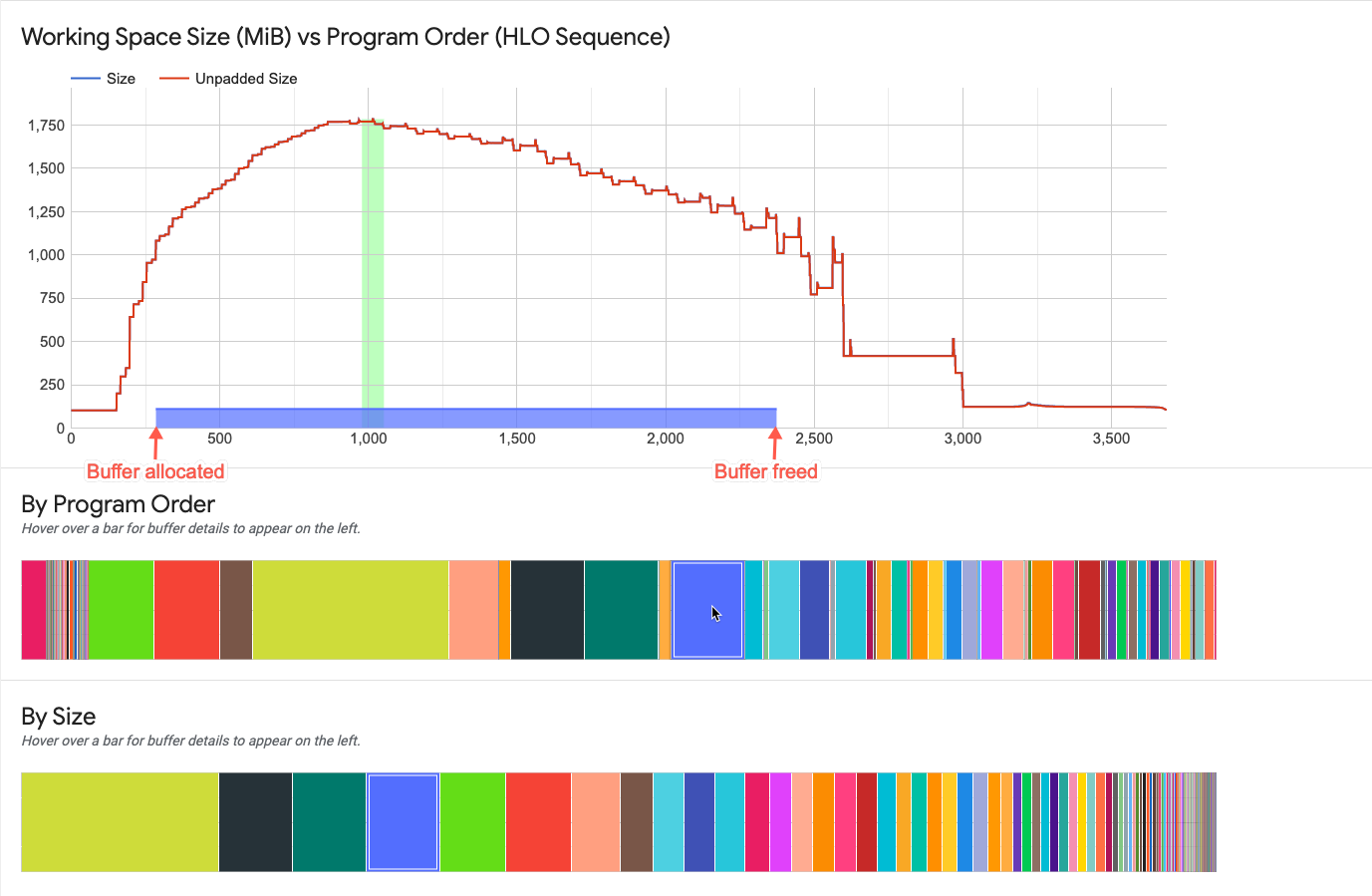
水平線の太さは、ピーク時のメモリ割り当てに対する相対的なバッファサイズを表します。線の長さはバッファの存続期間を表します。プログラムでバッファ領域が割り当てられてから領域が解放されるまでの期間を表します。
バッファグラフ
2 つのグラフで、ピーク時のメモリ使用量(グラフ上でのプロットの縦線)の詳細が表示されます。
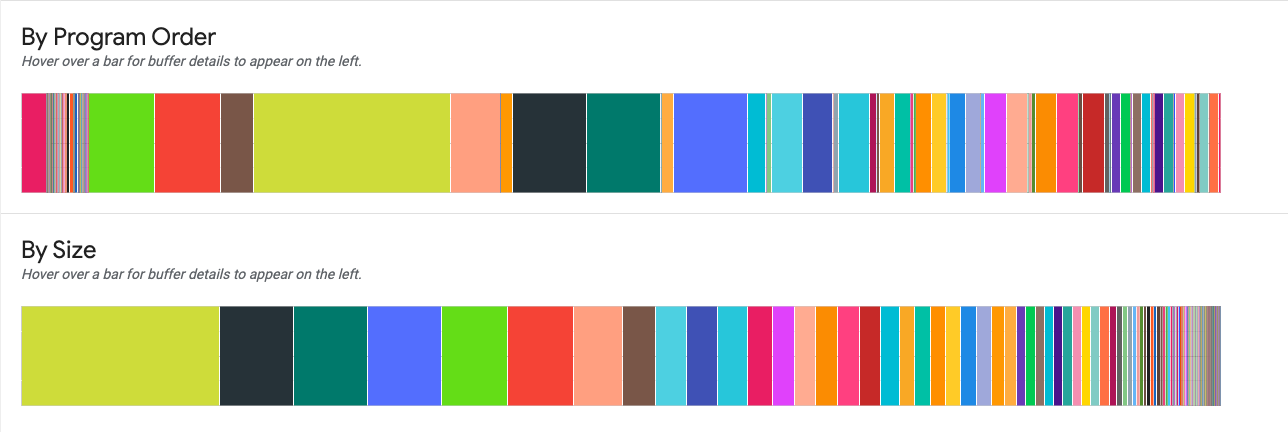
By Program Order。プログラムの実行中にアクティブだったバッファが左から順に表示されます。アクティブな時間が最も長かったバッファが左側に表示されます。
By Size。プログラム実行中にアクティブだったバッファがサイズの降順で表示されます。ピーク時のメモリ使用量に最も大きな影響を与えたバッファが左側に表示されます。
バッファ割り当て詳細カード
バッファグラフに表示されているバッファにカーソルを合わせると、バッファ割り当て詳細カードが表示されます(作業スペースグラフにはバッファの存続期間を表す水平線が表示されます)。通常、次のような詳細カードが表示されます。
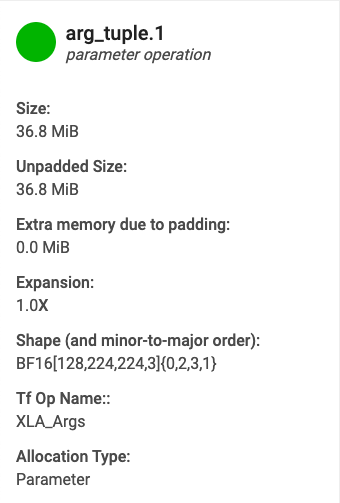
- 名前。XLA 演算の名前。
- カテゴリ。演算カテゴリ。
- サイズ。バッファ割り当てサイズ(パディングを含む)。
- パディングなしのサイズ。パディングなしのバッファ割り当てサイズ。
- 拡張。パディングありとパディングなしの場合のバッファサイズの違い。
- 追加メモリ。パディングのために余分に使用されるメモリ量。
- 形状。N 次元配列のランク、サイズ、データ型。
- TensorFlow 演算名。バッファ割り当てに関連した TensorFlow 演算の名前。
- 割り当てタイプ。バッファ割り当てのカテゴリです。タイプには、Parameter、Output、Thread-local、Temporary(fusion 内のバッファ割り当てなど)があります。
メモリ不足エラー
モデルの実行中にメモリ不足エラーが発生した場合は、次のコマンドを使用してメモリ プロファイルを取得し、メモリビューアで確認します。プロファイリング時間がプログラムのコンパイル時間と重なるように、適切な duration_ms を設定してください。次のコマンドの出力は、エラーの原因を特定するのに役立ちます。
(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000
ストリーミング トレース ビューア
ストリーミング トレース ビューア(trace_viewer)は、TensorFlow 2.17.0 以降で利用可能な Cloud TPU パフォーマンス分析ツールで、動的なトレース レンダリングを行います。このツールは、Chrome トレース イベント プロファイリング ビューアを使用するため、Chrome ブラウザでのみ機能します。
capture_tpu_profile を使用してプロファイルをキャプチャすると、.tracetable ファイルが Google Cloud Storage バケットに保存されます。このファイルには大量のトレース イベントが記録されます。このイベントは、トレース ビューアとストリーミング トレース ビューアの両方で確認できます。
ストリーミング トレース ビューアの使用
ストリーミング トレース ビューア trace_viewer を使用するには、既存の TensorBoard セッションをシャットダウンし、検査する TPU の IP アドレスを使用して TensorBoard を再起動する必要があります。ストリーミング トレース ビューアでは、Cloud TPU の IP アドレスに対して Google リモートプロシージャコール(GRPC)を行うために TensorBoard が必要です。GRPC チャネルは暗号化されません。
Cloud TPU ホストの IP アドレスは、Cloud TPU ページで確認できます。Cloud TPU を探し、[内部 IP] 列で IP アドレスを確認します。
VM で、次のように TensorBoard を実行します。ここで、tpu-ip は、TPU の IP アドレスに置き換えます。
(vm)$ tensorboard --logdir=${MODEL_DIR} \
--master_tpu_unsecure_channel=tpu-ip
TensorBoard に [Tools] プルダウン リストが表示されます。
タイムラインでズームインまたはズームアウトを行うと、トレース イベントの負荷をブラウザで動的に確認できます。
Cloud TPU ジョブのモニタリング
このセクションでは、capture_tpu_profile を使用して単一プロファイルをキャプチャする方法について説明します。また、コマンドライン インターフェースで Cloud TPU ジョブをリアルタイムでモニタリングする方法についても説明します。--monitoring_level オプションを 0(デフォルト)、1、または 2 に設定すると、それぞれ単一プロファイルの生成、基本モニタリング、詳細モニタリングが行われます。
新しい Cloud Shell を開いて VM に SSH で接続します(コマンドの m-name は VM 名に置き換えます)。
(vm)$ gcloud compute ssh vm-name \
--ssh-flag=-L6006:localhost:6006
新しい Cloud Shell で、--monitoring_level フラグに 1 または 2 を設定して capture_tpu_profile を実行します。次に例を示します。
(vm)$ capture_tpu_profile --tpu=$TPU_NAME \
--monitoring_level=1
monitoring_level=1 を設定すると、次のような出力が生成されます。
TPU type: TPU v2
Utilization of TPU Matrix Units is (higher is better): 10.7%
monitoring_level=2 に設定すると、より詳細な情報が表示されます。
TPU type: TPU v2
Number of TPU Cores: 8
TPU idle time (lower is better): 0.091%
Utilization of TPU Matrix Units is (higher is better): 10.7%
Step time: 1.95 kms (avg), 1.90kms (minute), 2.00 kms (max)
Infeed percentage: 87.5% (avg). 87.2% (min), 87.8 (max)
モニタリング フラグ
--tpu(必須)。モニタリングする Cloud TPU の名前を指定します。--monitoring_level。capture_tpu_profileの動作を単一プロファイルの作成から基本モニタリングまたは詳細な連続モニタリングに変更します。次の 3 つのレベルがあります。レベル 0(デフォルト): 単一プロファイルを生成して終了します。レベル 1: TPU のバージョンと TPU の使用率を表示します。レベル 2: TPU の使用率、TPU のアイドル時間、使用された TPU コア数が表示されます。min、avg、max のステップ時間と、インフィードの割合も表示されます。--duration_ms(任意、デフォルトは 1,000 ms)。各サイクルで TPU ホストをプロファイリングする時間を指定します。一般に、少なくとも 1 トレーニング ステップ分のデータを取得するのに十分な長さにする必要があります。ほとんどのモデルにおいて、1 秒で 1 つのトレーニング ステップがキャプチャされますが、モデルのステップ時間が非常に長い場合は、値を 2xstep_time(ミリ秒)にできます。--num_queriesにはcapture_tpu_profileの実行サイクルを指定します。TPU ジョブを継続的にモニタリングするには、高い値に設定してください。モデルのステップ時間をすばやく確認するには、値を小さい数値に設定します。