Conservar el progreso del entrenamiento con Autocheckpoint
Tradicionalmente, cuando una VM de TPU requiere mantenimiento, el procedimiento se inicia inmediatamente, sin dejar tiempo para que los usuarios realicen acciones que conserven el progreso, como guardar un punto de control. Esto se muestra en la figura 1(a).
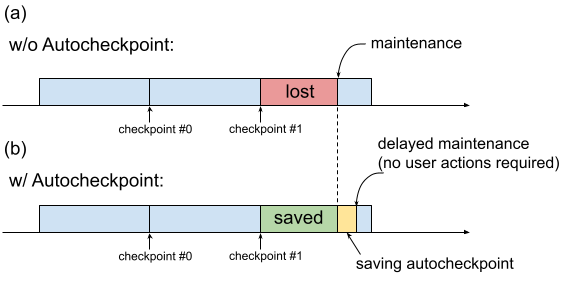
Fig. 1. Ilustración de la función Autocheckpoint: (a) Sin Autocheckpoint, el progreso del entrenamiento desde el último punto de control se pierde cuando hay un evento de mantenimiento programado. b) Con Autocheckpoint, el progreso del entrenamiento desde el último punto de control se puede conservar cuando haya un evento de mantenimiento programado.
Puedes usar Autocheckpoint (figura 1b) para conservar el progreso del entrenamiento configurando tu código para que guarde un punto de control no programado cuando se produzca un evento de mantenimiento. Cuando se produce un evento de mantenimiento, se guarda automáticamente el progreso desde el último punto de control. Esta función se puede usar tanto con una sola porción como con varias.
La función de punto de control automático funciona con frameworks que pueden capturar señales SIGTERM y, posteriormente, guardar un punto de control. Entre los frameworks admitidos se incluyen los siguientes:
Usar Autocheckpoint
La función de guardado automático está inhabilitada de forma predeterminada. Cuando creas una TPU o solicitas un recurso en cola, puedes habilitar Autocheckpoint añadiendo la marca --autocheckpoint-enabled al aprovisionar la TPU.
Con la función habilitada, la TPU de Cloud realiza los siguientes pasos una vez que recibe la notificación de un evento de mantenimiento:
- Captura la señal SIGTERM enviada al proceso mediante el dispositivo TPU.
- Espera a que finalice el proceso o a que transcurran 5 minutos, lo que ocurra primero.
- Realizar el mantenimiento de las porciones afectadas
La infraestructura que usa Autocheckpoint es independiente del framework de aprendizaje automático. Cualquier framework de aprendizaje automático puede admitir Autocheckpoint si puede capturar la señal SIGTERM e iniciar un proceso de creación de puntos de control.
En el código de la aplicación, debes habilitar las funciones de Autocheckpoint que proporciona el framework de aprendizaje automático. En Pax, por ejemplo, esto significa habilitar marcas de línea de comandos al iniciar el entrenamiento. Para obtener más información, consulta la guía de inicio rápido de Autocheckpoint con Pax. En segundo plano, los frameworks guardan un punto de control no programado cuando se recibe una señal SIGTERM y la VM de TPU afectada se somete a mantenimiento cuando la TPU ya no está en uso.
Guía de inicio rápido: Autocheckpoint con MaxText
MaxText es un LLM de alto rendimiento, escalable de forma arbitraria, de código abierto y bien probado escrito en Python/JAX puro para TPUs de Cloud. MaxText contiene toda la configuración necesaria para usar la función Autocheckpoint.
El archivo MaxText READMEdescribe dos formas de ejecutar MaxText a gran escala:
- Usar
multihost_runner.py, recomendado para experimentos - Usar
multihost_job.py(recomendado para producción)
Cuando uses multihost_runner.py, habilita Autocheckpoint definiendo la marca autocheckpoint-enabled al aprovisionar el recurso en cola.
Cuando uses multihost_job.py, habilita Autocheckpoint especificando la marca de línea de comandos ENABLE_AUTOCHECKPOINT=true al iniciar el trabajo.
Guía de inicio rápido: Autocomprobación con Pax en una sola porción
En esta sección se muestra un ejemplo de cómo configurar y usar Autocheckpoint con Pax en una sola porción. Con la configuración adecuada:
- Se guardará un punto de control cuando se produzca un evento de mantenimiento.
- Cloud TPU realizará el mantenimiento en las máquinas virtuales de TPU afectadas después de guardar el punto de control.
- Cuando la TPU de Cloud complete el mantenimiento, podrás usar la máquina virtual de TPU como de costumbre.
Usa la marca
autocheckpoint-enabledal crear la VM de TPU o al solicitar un recurso en cola.Por ejemplo:
Define las variables de entorno:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Descripciones de las variables de entorno
Variable Descripción PROJECT_IDEl ID de tu proyecto Google Cloud . Usa un proyecto que ya tengas o crea uno. TPU_NAMEEl nombre de la TPU. ZONELa zona en la que se creará la VM de TPU. Para obtener más información sobre las zonas admitidas, consulta Regiones y zonas de TPU. ACCELERATOR_TYPEEl tipo de acelerador especifica la versión y el tamaño de la TPU de Cloud que quieres crear. Para obtener más información sobre los tipos de aceleradores compatibles con cada versión de TPU, consulta Versiones de TPU. RUNTIME_VERSIONLa versión de software de la TPU de Cloud. Define el ID del proyecto y la zona en la configuración activa:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Crea una TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Conéctate a la TPU mediante SSH:
gcloud compute tpus tpu-vm ssh $TPU_NAMEInstalar Pax en una sola porción
La función de creación automática de puntos de control está disponible en las versiones 1.1.0 y posteriores de Pax. En la VM de TPU, instala
jax[tpu]y la versión más reciente depaxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Configura el
LmCloudSpmd2Bmodelo. Antes de ejecutar la secuencia de comandos de entrenamiento, cambiaICI_MESH_SHAPEpor[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Inicia el entrenamiento con la configuración adecuada.
En el siguiente ejemplo se muestra cómo configurar el modelo
LmCloudSpmd2Bpara guardar los puntos de control activados por Autocheckpoint en un segmento de Cloud Storage. Sustituye your-storage-bucket por el nombre de un segmento que ya tengas o crea uno.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Ten en cuenta las dos marcas que se transfieren al comando:
jax_fully_async_checkpoint: Si esta marca está activada, se usaráorbax.checkpoint.AsyncCheckpointer. La claseAsyncCheckpointerguarda automáticamente un punto de control cuando la secuencia de comandos de entrenamiento recibe una señal SIGTERM.exit_after_ondemand_checkpoint: Si esta marca está activada, el proceso de TPU se cierra después de que se guarde correctamente el Autocheckpoint, lo que hace que el mantenimiento se realice inmediatamente. Si no usas esta marca, el entrenamiento continuará después de guardar el punto de control y la TPU de Cloud esperará a que se agote el tiempo de espera (5 minutos) antes de realizar el mantenimiento necesario.
Autocomprobación con Orbax
La función de punto de control automático no se limita a MaxText ni a Pax. Cualquier framework que pueda capturar la señal SIGTERM e iniciar un proceso de creación de puntos de control funciona con la infraestructura proporcionada por Autocheckpoint. Orbax, un espacio de nombres que proporciona bibliotecas de utilidades comunes para los usuarios de JAX, ofrece estas funciones.
Como se explica en la documentación de Orbax, estas funciones están habilitadas de forma predeterminada para los usuarios de orbax.checkpoint.CheckpointManager. El método save, al que se llama después de cada paso, comprueba automáticamente si se va a producir un evento de mantenimiento y, si es así, guarda un punto de control aunque el número de paso no sea múltiplo de save_interval_steps.
En la documentación de GitHub también se explica cómo hacer que el entrenamiento finalice después de guardar un Autocheckpoint, con una modificación en el código de usuario.