Introducción
La previsión y la detección de anomalías en miles de millones de series temporales requieren un procesamiento intensivo. La mayoría de los sistemas existentes ejecutan la previsión y la detección de anomalías como trabajos por lotes (por ejemplo, canalizaciones de riesgos, previsión de tráfico, planificación de la demanda, etcétera). Esto limita severamente el tipo de análisis que puedes realizar en línea, como decidir si enviar una alerta en función de un aumento o una disminución repentinos en un conjunto de dimensiones de eventos.
Los objetivos principales de la API de Timeseries Insights son los siguientes:
- Ajusta la escala a miles de millones de series temporales que se construyen de forma dinámica a partir de eventos sin procesar y sus propiedades, según los parámetros de consulta.
- Proporciona resultados de previsión y detección de anomalías en tiempo real Es decir, en unos segundos, detecta las tendencias y la estacionalidad en todas las series temporales y decide si alguna de las divisiones aumenta o disminuye de forma inesperada.
Funcionalidad de la API
- Administra conjuntos de datos
- Indexa y carga un conjunto de datos que contenga varias fuentes de datos almacenadas en Cloud Storage. Permite agregar eventos nuevos de forma continua.
- Descarga un conjunto de datos que ya no necesites.
- Solicita el estado de procesamiento de un conjunto de datos.
- Consultar conjuntos de datos
- Recupera la serie temporal que coincide con los valores de propiedad determinados. La serie temporal se prevé hasta un horizonte temporal especificado. También se evalúa la serie temporal en busca de anomalías.
- Detecta automáticamente combinaciones de valores de propiedades para detectar anomalías.
- Actualiza conjuntos de datos
- Transferir eventos nuevos que ocurrieron recientemente y, luego, incorporarlos al índice casi en tiempo real (con una demora de segundos a minutos)
Recuperación ante desastres
La API de Timeseries Insights no funciona como una copia de seguridad de Cloud Storage ni muestra actualizaciones de transmisión sin procesar. Los clientes son responsables de almacenar y crear copias de seguridad de los datos por separado.
Después de una interrupción regional, el servicio realiza una recuperación del mejor esfuerzo. Es posible que no se recuperen los metadatos (información sobre el conjunto de datos y el estado operativo) y los datos del usuario transmitidos que se actualizaron dentro de las 24 horas posteriores al inicio de la interrupción.
Durante la recuperación, es posible que las consultas y las actualizaciones de transmisión a los conjuntos de datos no estén disponibles.
Datos de entrada
Es común que se recopilen datos numéricos y categóricos a lo largo del tiempo. Por ejemplo, en la siguiente figura, se muestra el uso de la CPU, el uso de la memoria y el estado de una sola tarea en ejecución en un centro de datos por minuto durante un período. El uso de la CPU y el uso de la memoria son valores numéricos, y el estado es un valor categórico.
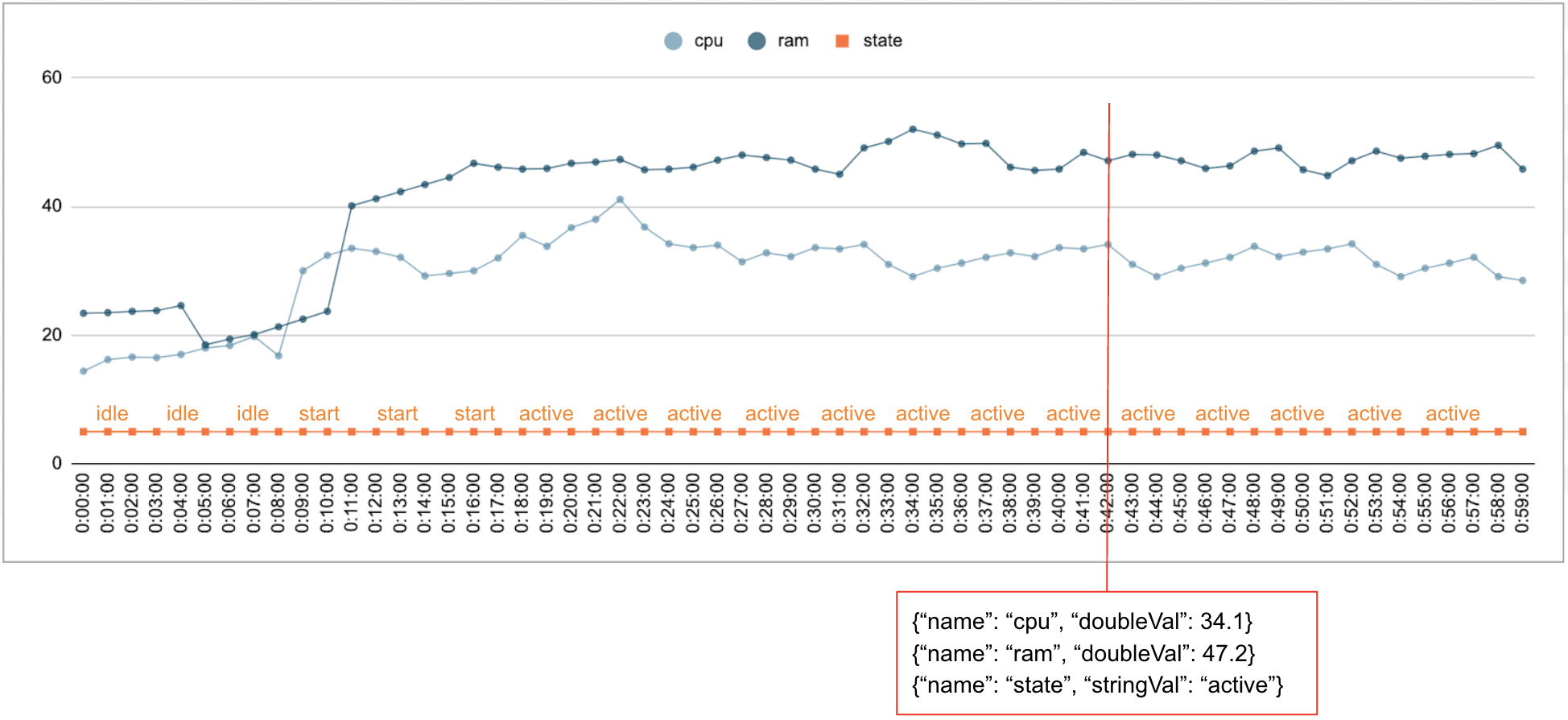
Evento
La API de Timeseries Insights usa eventos como la entrada de datos básica. Cada evento tiene una marca de tiempo y una colección de dimensiones, es decir, pares clave-valor en los que la clave es el nombre de la dimensión. Esta representación simple nos permite manejar datos a escala de billones. Por ejemplo, se incluyen el centro de datos, el usuario, los nombres de los trabajos y los números de tareas para representar por completo un solo evento. En la figura anterior, se muestra una serie de eventos registrados para un solo trabajo que ilustra un subconjunto de dimensiones.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
Un DataSet es una colección de eventos. Las consultas se realizan dentro del mismo conjunto de datos. Cada proyecto puede tener varios conjuntos de datos.
Un conjunto de datos se compila a partir de datos por lotes y de transmisión. La compilación de datos por lotes lee desde varios URIs de Cloud Storage como fuentes de datos. Una vez que se completa la compilación por lotes, el conjunto de datos se puede actualizar con datos de transmisión. Con la compilación por lotes para los datos históricos, el sistema puede evitar problemas de inicio en frío.
Un conjunto de datos debe compilarse o indexarse antes de que se pueda consultar o actualizar. El indexado comienza cuando se crea el conjunto de datos y, por lo general, tarda de minutos a horas en completarse, según la cantidad de datos. Más específicamente, las fuentes de datos se analizan una vez durante la indexación inicial. Si el contenido de los URIs de Cloud Storage cambia después de que se completa la indexación inicial, no se vuelven a analizar. Usa actualizaciones de transmisión para obtener datos adicionales. Las actualizaciones de transmisión se indexan de forma continua en tiempo casi real.
Series temporales y detección de anomalías
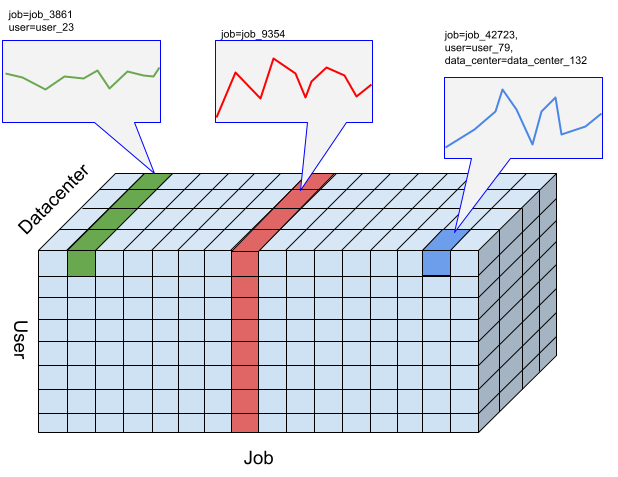
En el caso de la API de Timeseries Insights, una porción es una colección de eventos con una combinación determinada de valores de dimensión. Nos interesa una medición de los eventos que se incluyen en estos segmentos a lo largo del tiempo.
Para un intervalo determinado, los eventos se agregan en valores numéricos por la resolución de intervalos de tiempo especificada por el usuario, que son las series temporales para detectar anomalías. En la figura anterior, se ilustran las diferentes opciones de cortes que resultan de diferentes combinaciones de las dimensiones “usuario”, “trabajo” y “centro de datos”.
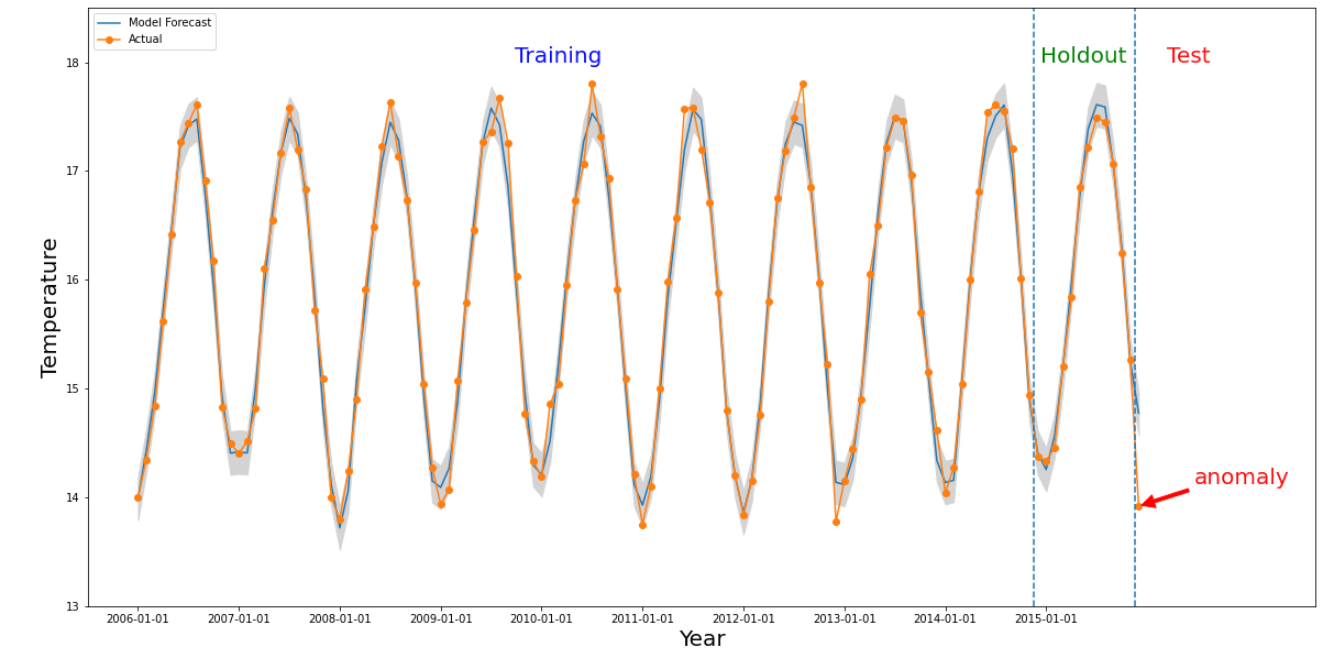
Se produce una anomalía para un período determinado si el valor numérico del intervalo de tiempo de interés es muy diferente de los valores anteriores. En la imagen anterior, se ilustra una serie temporal basada en las temperaturas medidas en todo el mundo durante 10 años. Supongamos que nos interesa saber si el último mes de 2015 es una anomalía. Una consulta al sistema especifica que el período de interés, detectionTime, sea “2015/12/01” y que granularity sea “1 mes”. Las series temporales recuperadas antes de detectionTime se particionan en un período de entrenamiento anterior seguido de un período de aislamiento. El sistema usa datos del período de entrenamiento para entrenar un modelo y usa el período de retención para verificar que el modelo pueda predecir de forma confiable los próximos valores. En este ejemplo, el período de retención es de 1 año. En la imagen, se muestran los datos reales y los valores previstos del
modelo con límites superior e inferior. La temperatura de diciembre de 2015 se marca como anomalía porque el valor real está fuera de los límites previstos.
¿Qué sigue?
- Conceptos de la API de Timeseries Insights
- Un instructivo más detallado
- Obtén más información sobre la API de REST.