Neste guia de início rápido, saiba como medir e melhorar a acurácia do Google Cloud Speech-to-Text para seus dados de áudio. Explore também os diversos modelos e opções disponíveis na API para melhorar a acurácia da transcrição. Saiba como usar a interface do Speech-to-Text no console do Google Cloud e um arquivo de informações empíricas para medir a acurácia e receber insights sobre o sistema de conversão de voz em texto.
Os sistemas de machine learning (ML) estão inerentemente sujeitos a imprecisões, e os sistemas de reconhecimento automático de fala (ASR, na sigla em inglês), também conhecidos como sistemas de conversão de voz em texto não são exceção. A medição precisa está fortemente acoplada a casos de uso específicos e aos sistemas que estão sendo avaliados, já que as diferenças na qualidade da gravação de áudio e nas condições acústicas podem afetar significativamente a acurácia. Como resultado, uma pontuação de acurácia única para todos os clientes e casos de uso é impraticável. Para garantir o desempenho confiável dos sistemas ASR em desempenho crítico dos sistemas voltados à produção. Também é essencial entender o desempenho do Speech-to-Text no contexto mais amplo do sistema.
Para este guia de início rápido, use o método padrão do setor para comparação, a taxa de erros de palavras (WER, na sigla em inglês), muitas vezes abreviada como WER. Para mais informações sobre como a WER é calculada e interpretada, consulte Medir e melhorar a acurácia da fala. Vamos começar.
Introdução ao console do Speech-to-Text
Verifique se você se inscreveu em uma conta do Google Cloud e criou um projeto. 1. Acesse Speech no console do Google Cloud e navegue até a UI do Speech-to-Text. 2. Usando um arquivo de áudio que represente seu caso de uso e como você pretende usar o sistema ASR, siga as instruções do guia de início rápido para fazer sua primeira transcrição usando o Speech-to-Text.
Como calcular a acurácia da transcrição
- Depois de transcrever o arquivo de áudio, use a seção
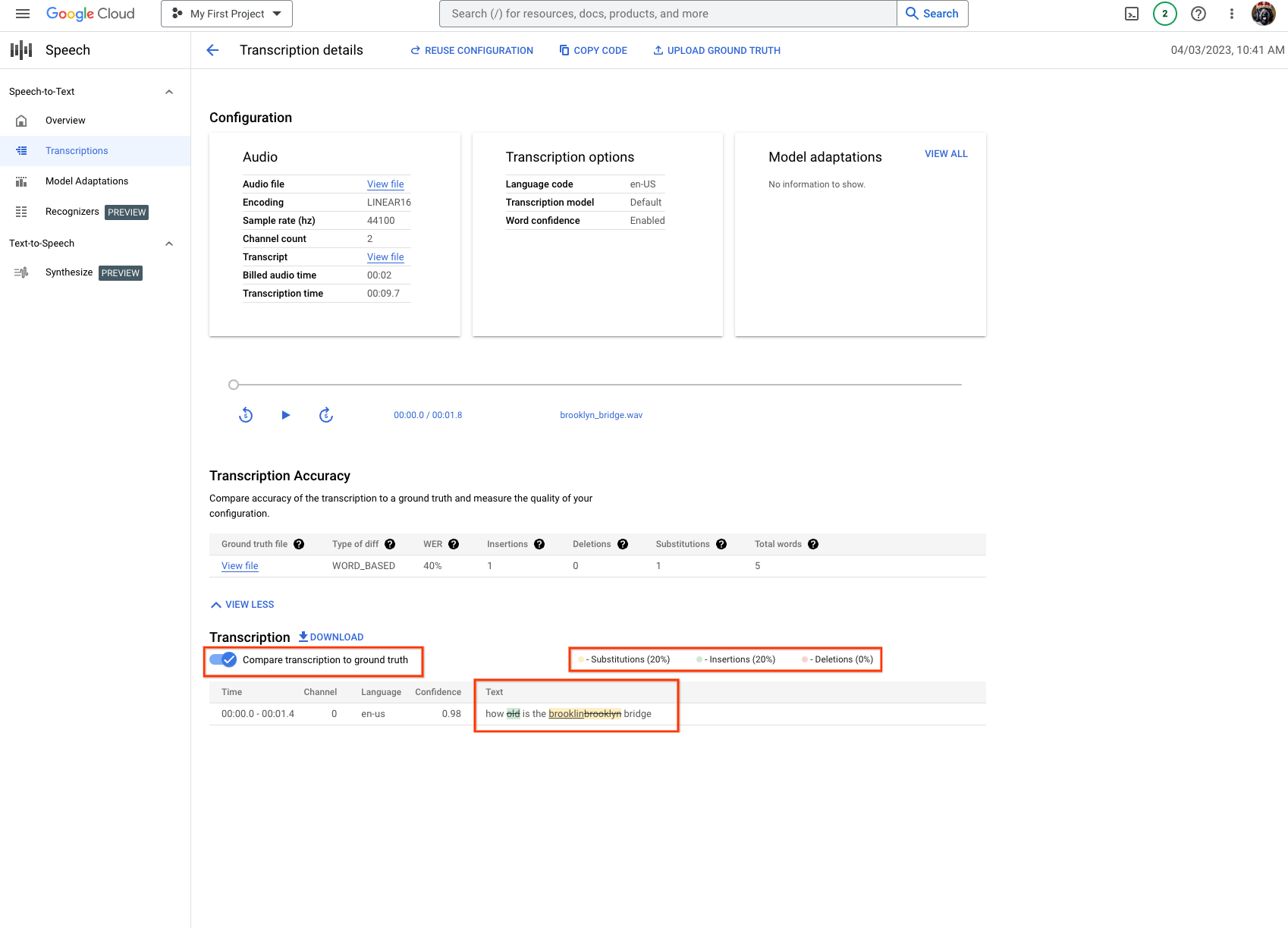
Transcription Accuracy. Esta seção permanece vazia até que a acurácia seja calculada para sua transcrição. - Usando o botão Fazer Upload de Informações Empíricas na parte superior da seção, você pode começar a calcular a acurácia.
Como especificar informações empíricas
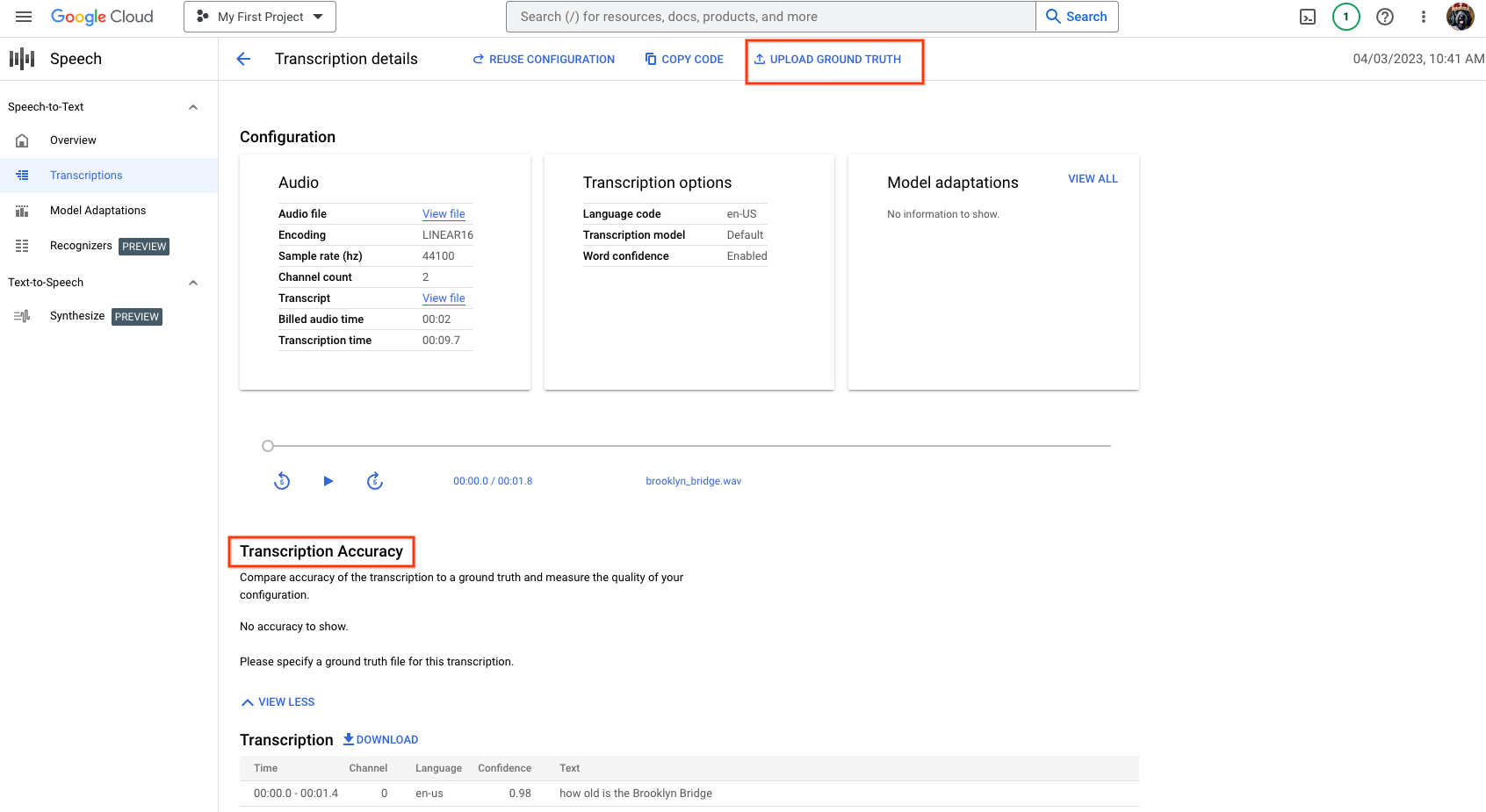
- Para calcular a acurácia da transcrição, forneça um arquivo de informações empíricas. Este é um arquivo
.txtou.csv, normalmente um arquivo de transcrição gerado pelo usuário que contém as transcrições corretas ou esperadas para comparação. - Use
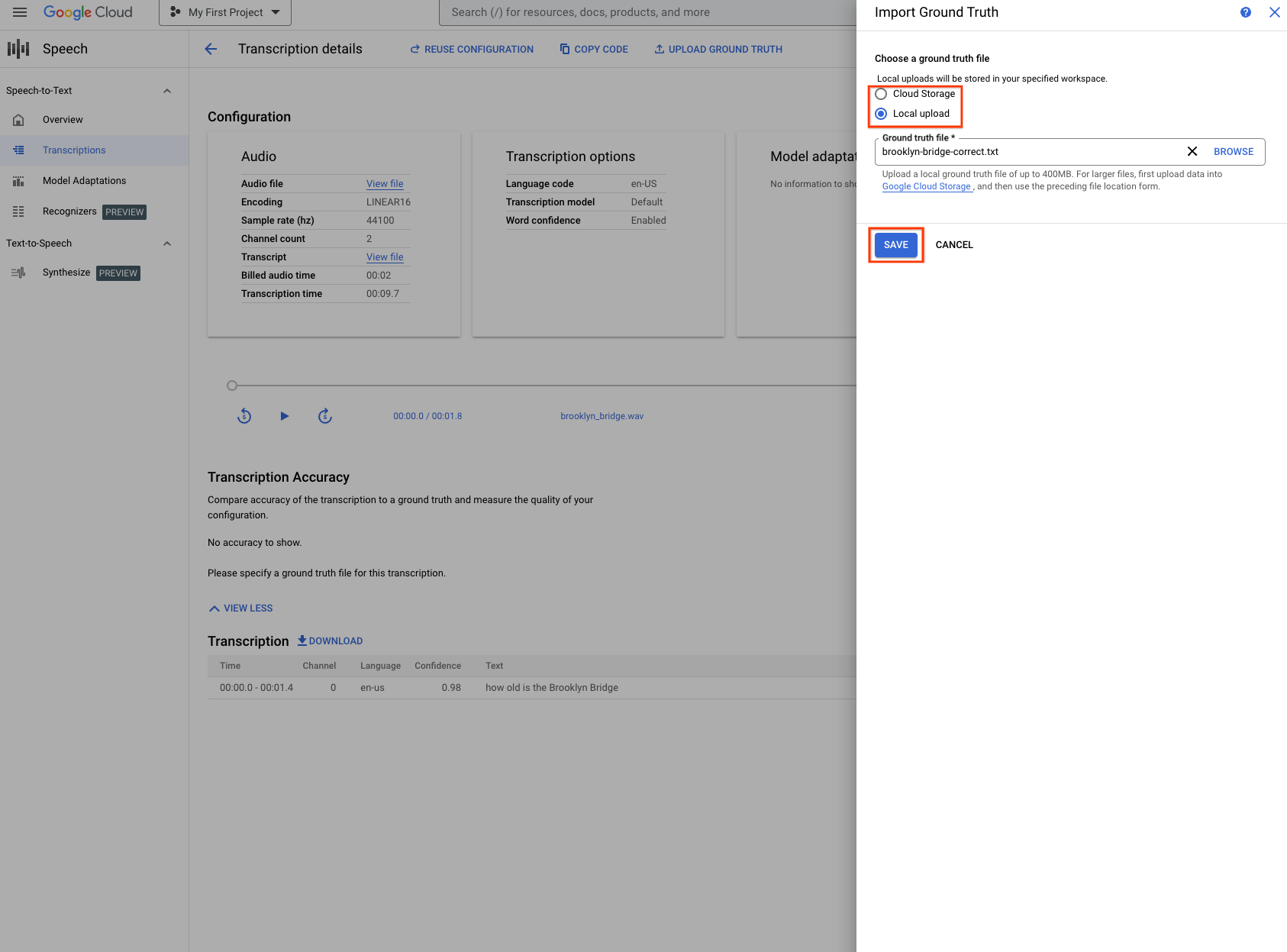
gs://cloud-samples-data/speech/brooklyn_bridge.wavcomo exemplo. O arquivo de informações empíricas contém:How old is the Brooklyn Bridge. Se você não tiver um arquivo de informações empíricas disponível, baixe a transcrição em um formato de texto. Edite o arquivo de transcrição conforme necessário. Faça o upload do arquivo de transcrição como o arquivo de informações empíricas. - Usando a opção Fazer Upload ou um arquivo do Cloud Storage, especifique o arquivo de informações empíricas e clique em Salvar.
Como confirmar as informações empíricas
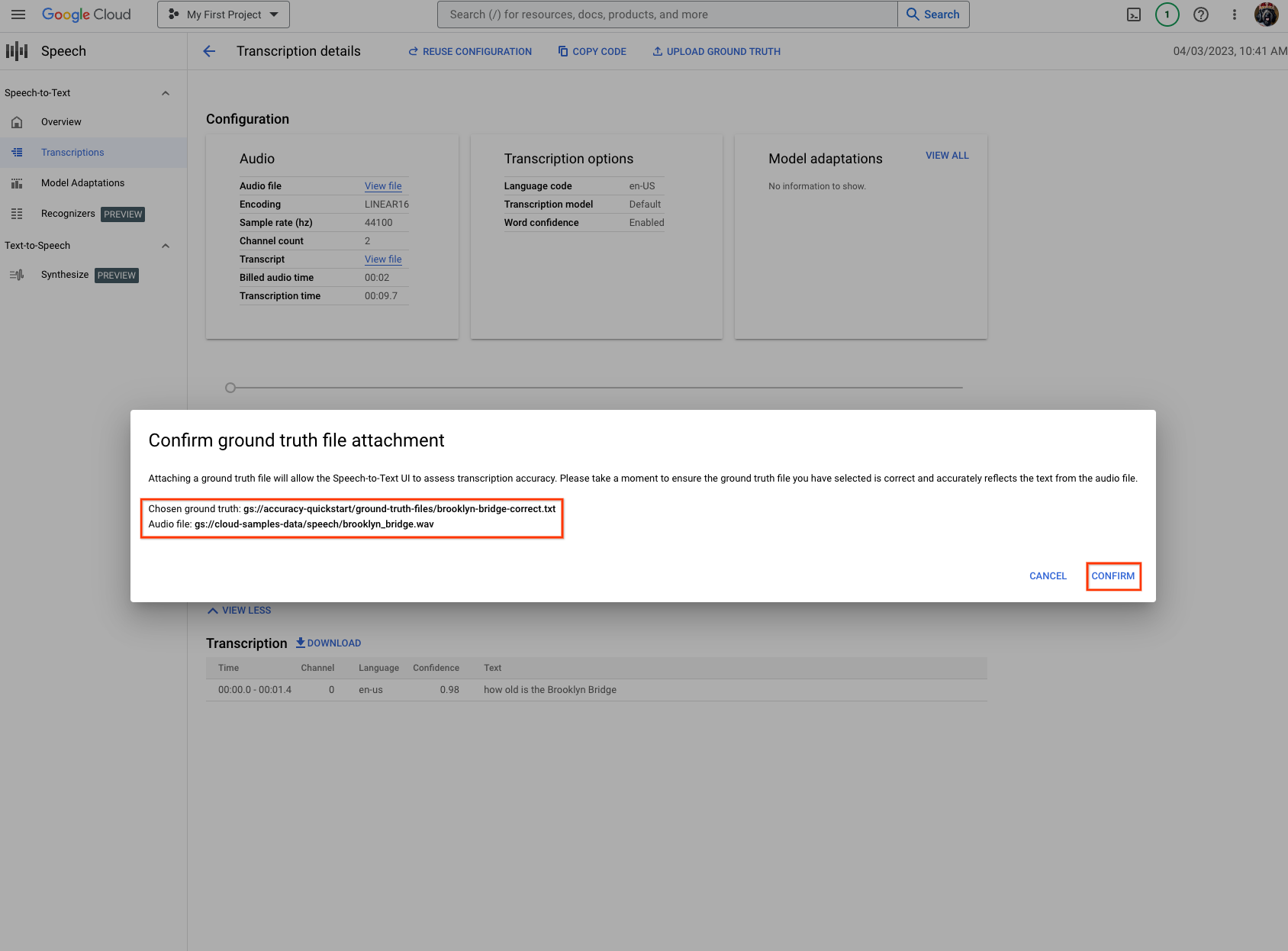
- Depois que você clicar em Salvar, será exibida uma solicitação para confirmar se o arquivo de informações empíricas especificado está correto. Verifique se o arquivo de informações empíricas representa corretamente as transcrições, já que isso afeta diretamente as métricas de acurácia.
- Clique em Confirmar para continuar.
Analisar os resultados da avaliação
- Dependendo do tamanho dos dados de entrada, o processo de avaliação pode levar algum tempo, e os resultados são exibidos após a conclusão.
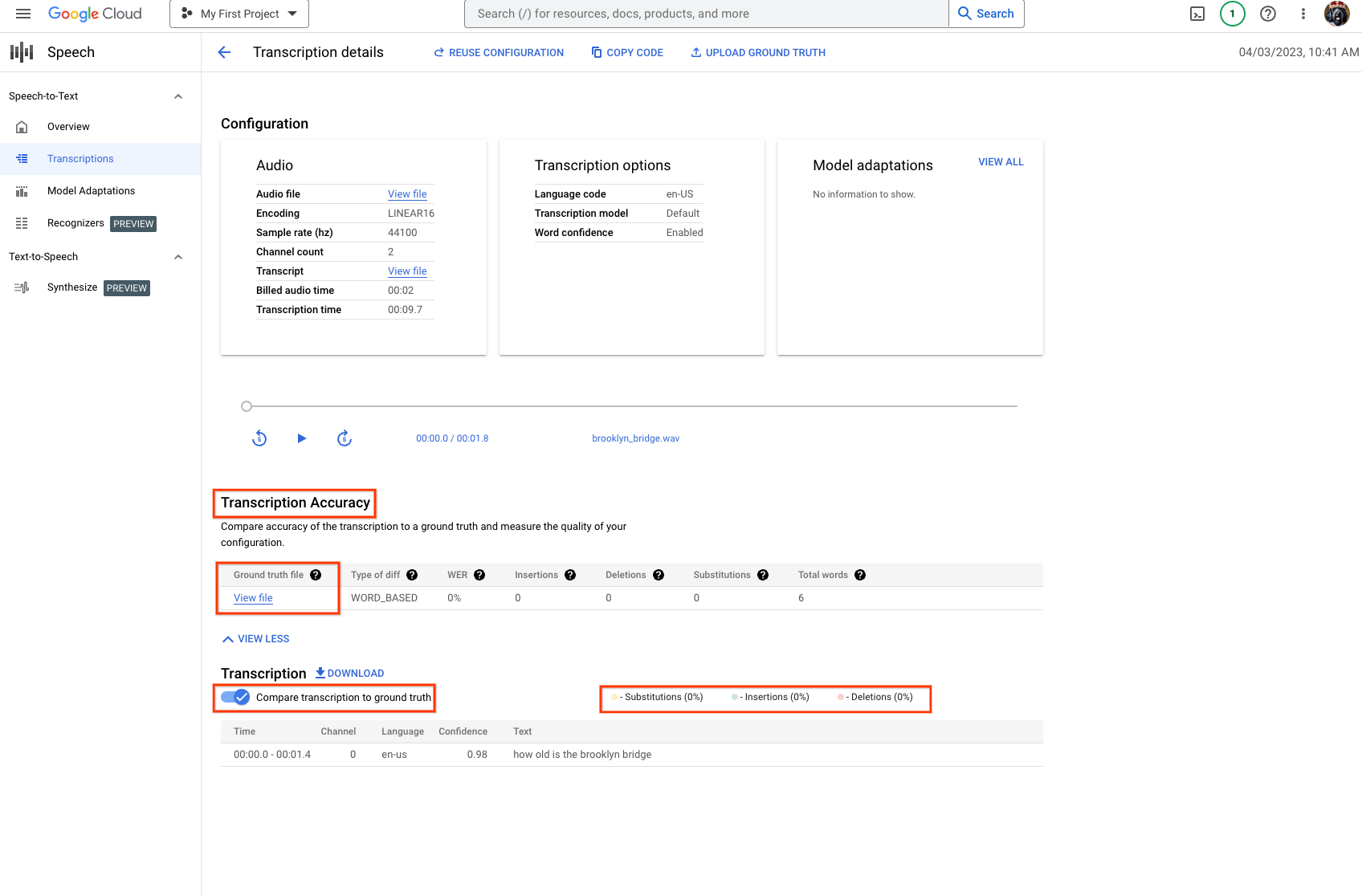
- Depois que a avaliação for concluída, as seguintes seções serão exibidas:
- A tabela Acurácia da Transcrição, as métricas de acurácia e um link para o arquivo de informações empíricas usado no processo.
- O
Transcriptioncom uma opção para comparar com o arquivo de informações empíricas, além de um detalhamento de métricas e destaques de acurácia.
- Analise e interprete os resultados de acurácia para entender o desempenho do reconhecedor do Speech-to-Text usado para identificar áreas de melhoria, já que os resultados variam de acordo com as entradas e a transcrição usadas. Nos exemplos a seguir, você pode ver casos indicativos dos resultados de acurácia, que fornecem insights valiosos para a otimização do sistema Google Cloud Speech-to-Text.
- Um exemplo de WER igual a 0%:
- Um exemplo de WER igual a 40%:
- Um exemplo de WER igual a 0%:
Opcional: como atualizar as informações empíricas
Para testar uma informação empírica diferente da transcrição atual, anexe novamente um arquivo diferente e repita as etapas três e quatro com um arquivo atualizado de informações empíricas.
Faça um teste
Se você ainda não conhece o Google Cloud, crie uma conta para avaliar o desempenho do Speech-to-Text em cenários reais. Clientes novos também recebem US$ 300 em créditos sem custos para executar, testar e implantar cargas de trabalho.
Faça um teste do Speech-to-Text sem custos financeiros