Creating an alerting policy for an SLO
This page describes how to create an alerting policy in Cloud Monitoring for a service level objective (SLO) that you create in Cloud Service Mesh.
For an introduction to SLOs, see the Service level objectives overview.
Cloud Monitoring can trigger an alert when a Service is on track to violate an SLO. You can create an alerting policy based on the rate of consumption of your error budget. All alerts on error budgets have the same basic condition: a specified percentage of the error budget for the compliance period is consumed in a lookback period, which is a time period, such as the previous 60 minutes. When you create the alerting policy, Cloud Service Mesh automatically sets most of the conditions for the alert based on the settings in the SLO. You specify the lookback period and the consumption percentage.
Determining what values you should set for the lookback period and consumption percentage might take some trial and error. You could use the default lookback period of 60 minutes as a starting point. To determine the consumption percentage, monitor the service behavior to see what percentage of the total error budget (over the compliance period) was consumed in the previous 60 minutes. You want to set the consumption percentage so that you don't burn more error budget in the lookback period than you can afford, but you don't want to set off an alert unnecessarily.
For example, suppose you created an SLO with the following name:
95% < 300ms Latency in Calendar Week
With this SLO, only 5% of the total number of requests in a week can have a
latency > 300ms. Hitting or exceeding 5% consumes your total error budget. If
you set the lookback period to one hour, each lookback period is 1/168 of your
compliance period (there are 168 hours in a week). To calculate the hourly
consumption percentage that doesn't exceed the total error budget for the week:
5% ÷ 168 ≈ 0.03%
Because latency for your Service can fluctuate depending on load or other conditions, setting 0.03% as the consumption percentage might trigger unnecessary alerts. You could start with a value twice that, or 0.06%, then monitor your Service and adjust the value as needed.
Before you begin
Create an SLO for one of your Services.
Creating an alerting policy on an SLO
Go to the Health tab for a service:
In the Google Cloud console, go to Cloud Service Mesh.
Select the Google Cloud project from the drop-down list on the menu bar.
Click the service that you want to create an alerting policy for.
In the left navigation bar, click Health.
Click the SLO that you want to create an alerting policy for.
In the Current Status of SLO section on the right, click the Create Alerting Policy link.
The Add condition dialog displays. Cloud Service Mesh automatically populates the SLO Burn Rate condition based on the settings in the SLO. You configure the SLO Burn Rate condition so that you get an alert when the SLO's error budget is declining too rapidly. You want to make sure that you get an alert before the SLO is out of error budget.
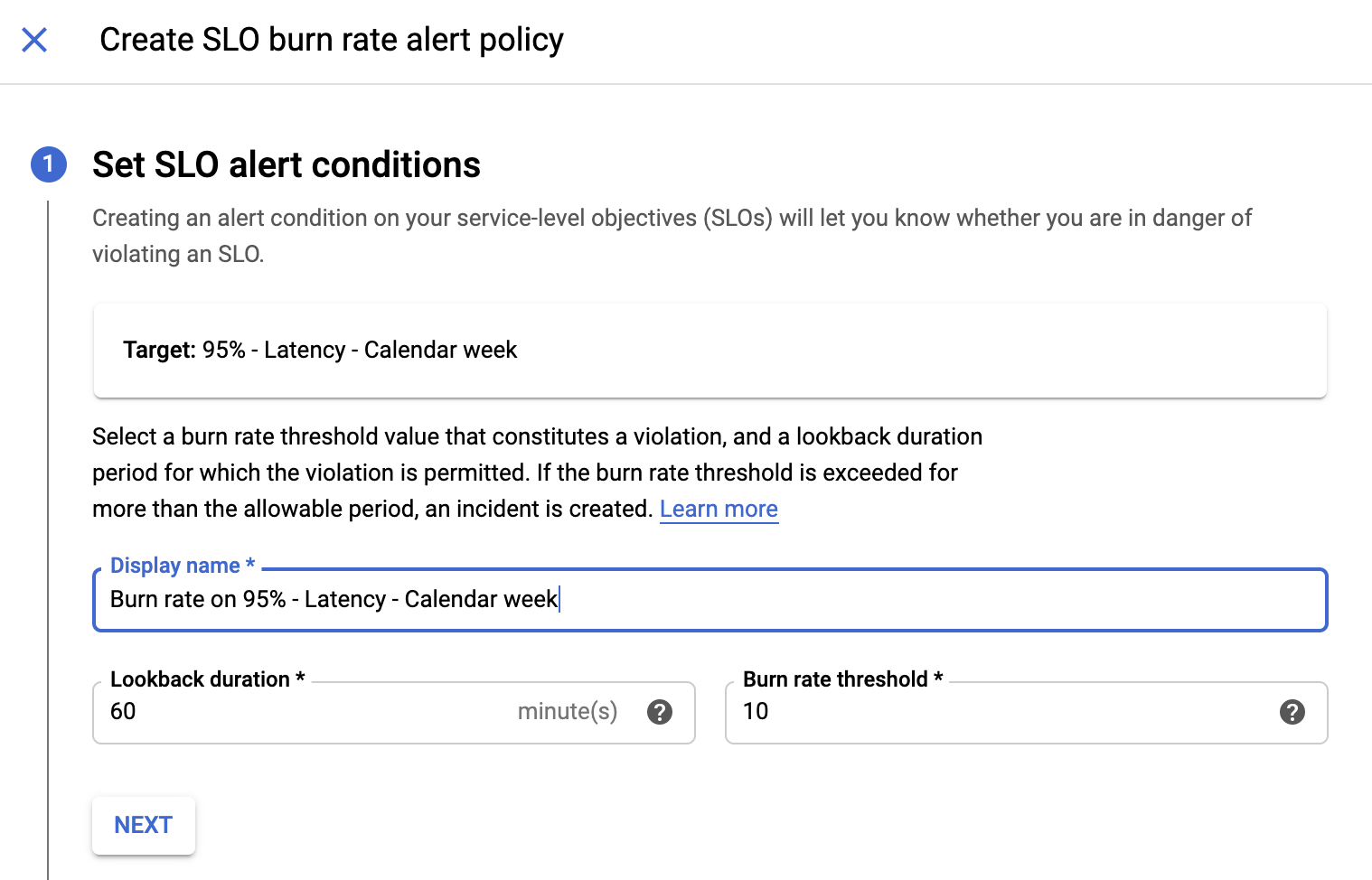
Configure the condition:
- To name the condition, click the Suggested title link to use the name based on your SLO, or enter a name for the condition.
- In the Target section, enter the lookback period in the Lookback Duration field, or use the default value.
- In the Configuration section, enter the consumption percentage in the Threshold field.
- Click Save. The Create new alerting policy window displays.
Configure the alerting policy:
- Enter a policy name.
- The condition is automatically populated, but you can optionally add another condition.
- If the alerting policy has only one condition, then leave the Policy triggers field at the default value of Any condition is met.
- Optionally, configure the Notifications and Documentation sections. See Managing alerting policies for more information.
- Click Save. The Policy details page is displayed.
- To go back to the Cloud Service Mesh dashboard, click the Navigation menu dehaze and go to Anthos > Services.
What's next
Learn more about alerting from Site Reliability Engineering at Google: