Topik ini menunjukkan cara mengukur k-anonimitas set data menggunakan Sensitive Data Protection dan memvisualisasikannya di Looker Studio. Dengan begitu, Anda juga dapat lebih memahami risiko dan membantu mengevaluasi pertimbangan dalam kegunaan yang mungkin Anda lakukan jika Anda menyamarkan atau menganonimkan data.
Meskipun fokus topik ini adalah memvisualisasikan metrik analisis risiko identifikasi ulang k-anonimitas, Anda juga dapat memvisualisasikan metrik l-diversity menggunakan metode yang sama.
Topik ini mengasumsikan bahwa Anda sudah memahami konsep k-anonimitas dan kegunaannya untuk menilai pengidentifikasian ulang data dalam set data. Sebaiknya Anda juga memahami cara menghitung k-anonimitas menggunakan Sensitive Data Protection, dan cara menggunakan Looker Studio.
Pengantar
Teknik de-identifikasi dapat membantu melindungi privasi subjek Anda saat Anda memproses atau menggunakan data. Namun, bagaimana cara mengetahui apakah set data telah dianonimkan secara memadai? Lalu, bagaimana Anda akan mengetahui apakah de-identifikasi Anda telah menyebabkan terlalu banyak kehilangan data untuk kasus penggunaan Anda? Artinya, bagaimana Anda dapat membandingkan risiko identifikasi ulang dengan kegunaan data untuk membantu membuat keputusan berdasarkan data?
Menghitung nilai anonimitas k dari set data membantu menjawab pertanyaan ini dengan menilai kemampuan identifikasi ulang data set data. Perlindungan Data Sensitif berisi fungsi bawaan untuk menghitung nilai anonimitas k pada set data berdasarkan kuasi-pengenal yang Anda tentukan. Hal ini membantu Anda mengevaluasi dengan cepat apakah penghapusan identitas pada kolom atau kombinasi kolom tertentu akan menghasilkan set data yang lebih atau kurang mungkin diidentifikasi ulang.
Contoh set data
Berikut adalah beberapa baris pertama dari contoh set data besar.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Untuk tujuan tutorial ini, user_id tidak akan dibahas, karena fokusnya
adalah pada kuasi-pengenal. Dalam skenario dunia nyata, Anda harus memastikan bahwa user_id disamarkan atau ditokenisasi dengan tepat. Kolom
score adalah eksklusif untuk set data ini, dan kemungkinan penyerang tidak akan dapat mempelajarinya dengan cara lain, jadi Anda tidak akan menyertakannya dalam analisis. Fokus Anda adalah pada kolom age dan title yang tersisa, yang
dapat digunakan penyerang untuk mempelajari individu melalui sumber data
lain. Pertanyaan yang ingin Anda jawab untuk set data adalah:
- Apa pengaruh dua kuasi-pengenal—
agedantitle—terhadap risiko identifikasi ulang keseluruhan data yang tidak teridentifikasi? - Bagaimana penerapan transformasi de-identifikasi akan memengaruhi risiko ini?
Anda ingin memastikan bahwa kombinasi age dan title tidak akan dipetakan ke
sejumlah kecil pengguna. Misalnya, hanya ada satu pengguna dalam set data yang memiliki jabatan Programmer I dan berusia 69 tahun. Penyerang mungkin dapat
mencocokkan informasi tersebut dengan demografi atau informasi lain yang tersedia, mengetahui siapa orang tersebut, dan mempelajari nilai skornya.
Untuk mengetahui informasi selengkapnya tentang fenomena ini, lihat bagian "ID entity dan komputasi
k-anonimitas" dalam topik konseptual Analisis
risiko.
Langkah 1: Hitung k-anonimitas pada set data
Pertama, gunakan Sensitive Data Protection untuk menghitung anonimitas k pada set data dengan
mengirim JSON berikut ke resource
DlpJob. Dalam
JSON ini, Anda menetapkan ID entity ke kolom
user_id, dan mengidentifikasi dua kuasi-ID sebagai kolom age dan
title. Anda juga menginstruksikan Perlindungan Data Sensitif untuk menyimpan hasil ke tabel BigQuery baru.
Input JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}Setelah tugas anonimitas k selesai, Sensitive Data Protection akan mengirimkan hasil tugas ke tabel BigQuery yang bernama dlp-demo-2.dlp_testing.test_results.
Langkah 2: Hubungkan hasil ke Looker Studio
Selanjutnya, Anda akan menghubungkan tabel BigQuery yang Anda buat di Langkah 1 ke laporan baru di Looker Studio.
Buka Looker Studio.
Klik Buat > Laporan.
Di panel Tambahkan data ke laporan di bagian Hubungkan ke data, klik BigQuery. Anda mungkin perlu mengizinkan Looker Studio untuk mengakses tabel BigQuery Anda.
Di pemilih kolom, pilih Project saya. Kemudian pilih project, set data, dan tabel. Setelah selesai, klik Tambahkan. Jika Anda melihat pemberitahuan bahwa Anda akan menambahkan data ke laporan ini, klik Tambahkan ke laporan.
Hasil pemindaian k-anonimitas kini telah ditambahkan ke laporan Looker Studio baru. Pada langkah berikutnya, Anda akan membuat diagram.
Langkah 3: Buat diagram
Lakukan hal berikut untuk menyisipkan dan mengonfigurasi diagram:
- Di Looker Studio, jika tabel nilai muncul, pilih tabel tersebut dan tekan Delete untuk menghapusnya.
- Di menu Sisipkan, klik Diagram kombinasi.
- Klik dan gambar persegi panjang di kanvas tempat Anda ingin diagram ditampilkan.
Selanjutnya, konfigurasikan data diagram di tab Data sehingga diagram menampilkan efek dari memvariasikan ukuran dan rentang nilai bucket:
- Hapus kolom di bawah judul berikut dengan mengarahkan kursor ke setiap kolom
dan mengklik X , seperti yang ditunjukkan di sini:
- Dimensi Rentang Tanggal
- Dimensi
- Metrik
- Urutkan
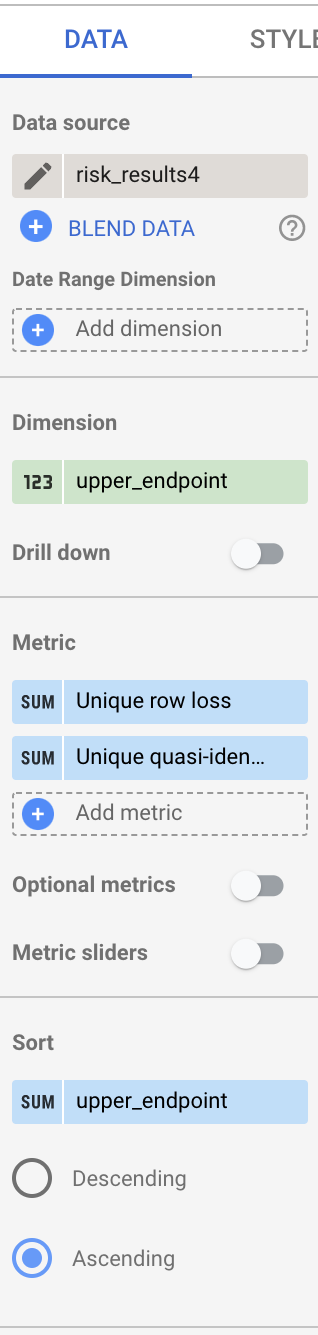
- Setelah semua kolom dihapus, tarik kolom upper_endpoint dari kolom Kolom yang tersedia ke heading Dimensi.
- Tarik kolom upper_endpoint ke heading Urutkan, lalu pilih Naik.
- Tarik kolom bucket_size dan bucket_value_count ke heading Metrik.
- Arahkan kursor ke ikon di sebelah kiri metrik bucket_size dan ikon Edit akan muncul.
Klik ikon Edit, lalu lakukan tindakan berikut:
- Di kolom Nama, ketik
Unique row loss. - Di bagian Type, pilih Percent.
- Di bagian Penghitungan perbandingan, pilih Persen total.
- Di bagian Penghitungan berjalan, pilih Jumlah berjalan.
- Di kolom Nama, ketik
- Ulangi langkah sebelumnya untuk metrik bucket_value_count, tetapi di kolom
Name, ketik
Unique quasi-identifier combination loss.
Setelah selesai, kolom akan muncul seperti yang ditunjukkan di sini:
Terakhir, konfigurasi diagram untuk menampilkan diagram garis untuk kedua metrik:
- Klik tab Gaya di panel di sebelah kanan jendela.
- Untuk Seri #1 dan Seri #2, pilih Garis.
- Untuk melihat diagram akhir secara terpisah, klik tombol Lihat di sudut kanan atas jendela.
Berikut adalah contoh diagram setelah menyelesaikan langkah-langkah sebelumnya.
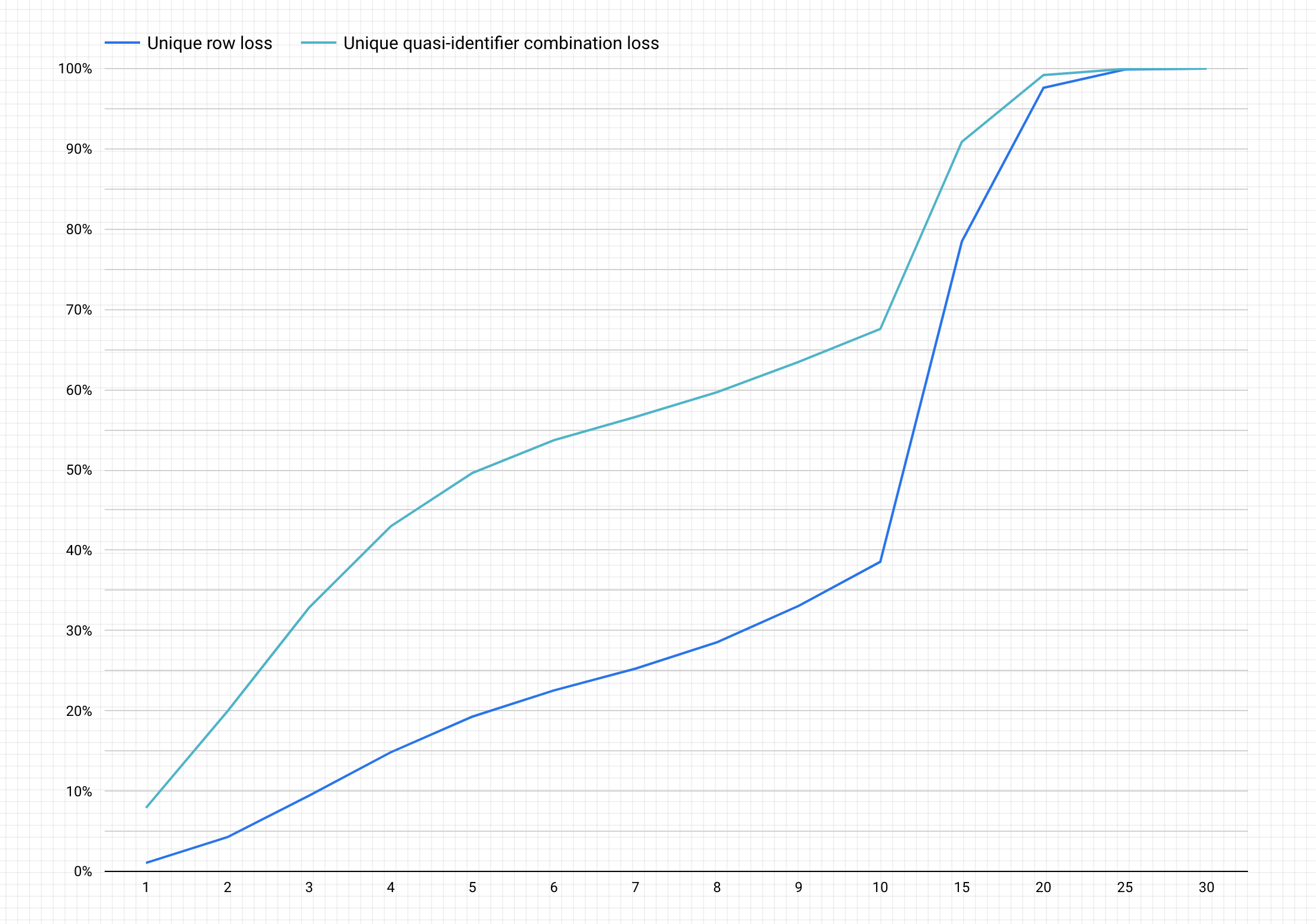
Menafsirkan diagram
Diagram yang dihasilkan memplot, pada sumbu y, potensi persentase kehilangan data untuk baris unik dan kombinasi quasi-ID unik untuk mencapai, pada sumbu x, nilai k-anonimitas k.
Nilai k-anonymity yang lebih tinggi menunjukkan risiko identifikasi ulang yang lebih rendah. Namun, untuk mencapai nilai k-anonimitas k yang lebih tinggi, Anda harus menghapus persentase baris total yang lebih tinggi dan kombinasi quasi-ID unik yang lebih tinggi, yang dapat mengurangi kegunaan data.
Untungnya, menghapus data bukan satu-satunya opsi untuk mengurangi risiko identifikasi ulang. Teknik penghapusan identitas lainnya dapat mencapai keseimbangan yang lebih baik antara kehilangan dan kegunaan. Misalnya, untuk mengatasi jenis kehilangan data yang terkait dengan nilai k-anonimitas yang lebih tinggi dan set data ini, Anda dapat mencoba mengelompokkan usia atau jabatan untuk mengurangi keunikan kombinasi usia/jabatan. Misalnya, Anda dapat mencoba mengelompokkan usia dalam rentang 20-25, 25-30, 30-35, dan seterusnya. Untuk mengetahui informasi selengkapnya tentang cara melakukannya, lihat Generalisasi dan pengelompokan serta Melakukan de-identifikasi data sensitif dalam konten teks.