En esta página, se describen y comparan dos servicios de Protección de datos sensibles que te ayudan a comprender tus datos y habilitar flujos de trabajo de administración de datos: el servicio de descubrimiento y el servicio de inspección.
Descubrimiento de datos sensibles
El servicio de descubrimiento supervisa los datos en toda tu organización. Este servicio se ejecuta de forma continua y descubre, clasifica y genera perfiles de datos automáticamente. El descubrimiento puede ayudarte a comprender la ubicación y la naturaleza de los datos que almacenas, incluidos los recursos de datos que quizás no conozcas. Los datos desconocidos (a veces llamados datos sombra) no suelen someterse al mismo nivel de administración de datos y gestión de riesgos que los datos conocidos.
Configuras el descubrimiento en varios alcances. Puedes establecer diferentes programaciones de generación de perfiles para distintos subconjuntos de tus datos. También puedes excluir subconjuntos de datos que no necesites para la creación de perfiles.
Resultados del análisis de descubrimiento: perfiles de datos
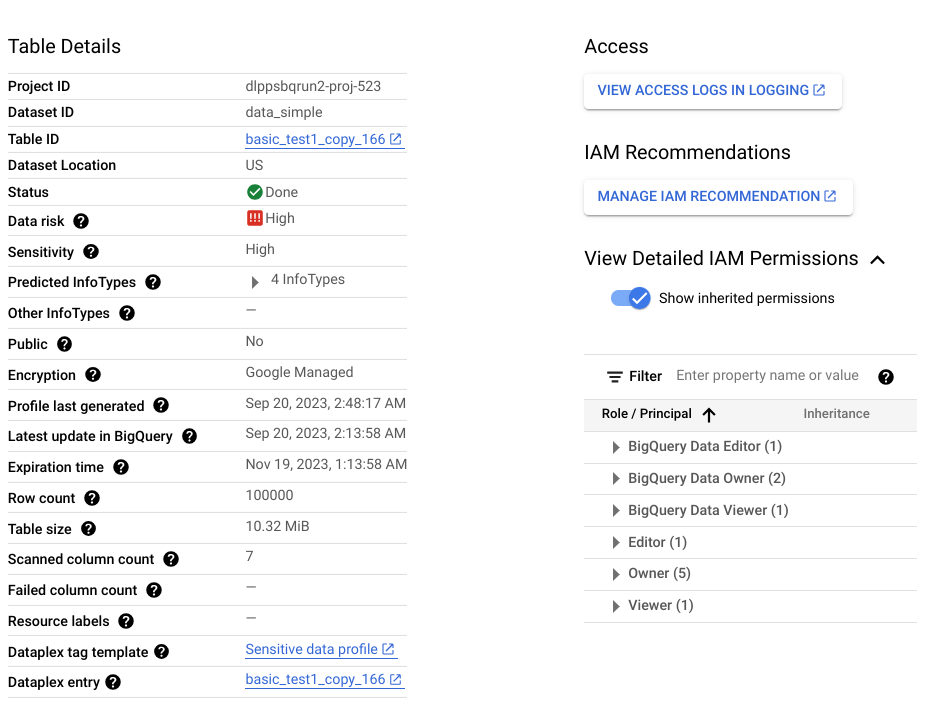
El resultado de un análisis de detección es un conjunto de perfiles de datos para cada recurso de datos dentro del alcance. Por ejemplo, un análisis de descubrimiento de datos de BigQuery o Cloud SQL genera perfiles de datos a nivel de proyecto, tabla y columna.
Un perfil de datos contiene métricas y estadísticas sobre el recurso del que se generó el perfil. Incluye las clasificaciones de datos (o infoTypes), los niveles de sensibilidad, los niveles de riesgo de los datos, el tamaño de los datos, la forma de los datos y otros elementos que describen la naturaleza de los datos y su posición de seguridad de los datos (qué tan seguros son los datos). Puedes usar perfiles de datos para tomar decisiones fundamentadas sobre cómo proteger tus datos, por ejemplo, estableciendo políticas de acceso en la tabla.
Considera una columna de BigQuery llamada ccn, en la que cada fila contiene un número de tarjeta de crédito único y no hay valores nulos. El perfil de datos a nivel de la columna generado tendrá los siguientes detalles:
| Nombre visible | Valor |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Además, este perfil a nivel de la columna forma parte de un perfil a nivel de la tabla, que proporciona estadísticas como la ubicación de los datos, el estado de encriptación y si la tabla se comparte públicamente. En la consola de Google Cloud , también puedes ver las entradas de Cloud Logging para la tabla y las entidades principales de IAM con roles para la tabla.
Para obtener una lista completa de las métricas y las estadísticas disponibles en los perfiles de datos, consulta la Referencia de métricas.
Cuándo usar el descubrimiento
Cuando planifiques tu enfoque de administración de riesgos de datos, te recomendamos que comiences con el descubrimiento. El servicio de detección te ayuda a obtener una vista general de tus datos y a habilitar las alertas, los informes y la corrección de problemas.
Además, el servicio de detección puede ayudarte a identificar los recursos en los que podrían residir datos no estructurados. Es posible que estos recursos requieran una inspección exhaustiva. Los datos no estructurados se especifican con una puntuación alta de texto libre en una escala del 0 al 1.
Inspección de datos sensibles
El servicio de inspección realiza un análisis exhaustivo de un solo recurso para ubicar cada instancia individual de datos sensibles. Una inspección produce un hallazgo para cada instancia detectada.
Los trabajos de inspección proporcionan un amplio conjunto de opciones de configuración para ayudarte a identificar los datos que deseas inspeccionar. Por ejemplo, puedes activar el muestreo para limitar los datos que se inspeccionarán a una cierta cantidad de filas (para los datos de BigQuery) o a ciertos tipos de archivos (para los datos de Cloud Storage). También puedes segmentar la búsqueda para un período específico en el que se crearon o modificaron los datos.
A diferencia del descubrimiento, que supervisa tus datos de forma continua, la inspección es una operación a pedido. Sin embargo, puedes programar trabajos de inspección recurrentes llamados activadores de trabajo.
Resultado del análisis de inspección: hallazgos
Cada hallazgo incluye detalles como la ubicación de la instancia detectada, su posible Infotipo y la certeza (también llamada probabilidad) de que el hallazgo coincida con el Infotipo. Según tu configuración, también puedes obtener la cadena real a la que se refiere el hallazgo. En la Protección de datos sensibles, esta cadena se denomina cita.
Para obtener una lista completa de los detalles incluidos en un hallazgo de inspección, consulta Finding.
Cuándo usar la inspección
Una inspección es útil cuando necesitas investigar datos no estructurados (como comentarios o opiniones creados por usuarios) y, luego, identificar cada instancia de información de identificación personal (PII). Si un análisis de detección identifica recursos que contienen datos no estructurados, te recomendamos que ejecutes un análisis de inspección en esos recursos para obtener detalles sobre cada hallazgo individual.
Cuándo no usar la inspección
La inspección de un recurso no es útil si se cumplen las siguientes condiciones. Un análisis de descubrimiento puede ayudarte a decidir si se necesita un análisis de inspección.
- Solo tienes datos estructurados en el recurso. Es decir, no hay columnas de datos de formato libre, como comentarios u opiniones de los usuarios.
- Ya conoces los infoTypes almacenados en ese recurso.
Por ejemplo, supongamos que los perfiles de datos de un análisis de descubrimiento indican que una determinada tabla de BigQuery no tiene columnas con datos no estructurados, pero sí tiene una columna de números de tarjetas de crédito únicos. En este caso, no es útil inspeccionar la tabla en busca de números de tarjetas de crédito. Una inspección producirá un hallazgo para cada elemento de la columna. Si tienes 1 millón de filas y cada una contiene 1 número de tarjeta de crédito, un trabajo de inspección producirá 1 millón de resultados para el Infotipo CREDIT_CARD_NUMBER. En este ejemplo, no se necesita la inspección porque el análisis de detección ya indica que la columna contiene números de tarjetas de crédito únicos.
Residencia, procesamiento y almacenamiento de datos
Tanto el descubrimiento como la inspección admiten los requisitos de residencia de los datos:
- El servicio de descubrimiento procesa tus datos donde residen y almacena los perfiles de datos generados en la misma región o multirregión que los datos perfilados. Para obtener más información, consulta Consideraciones sobre la residencia de los datos.
- Cuando se inspeccionan datos dentro de un sistema de almacenamiento de Google Cloud , el servicio de inspección procesa tus datos en la misma región en la que residen y almacena el trabajo de inspección en esa región. Cuando inspeccionas datos a través de un trabajo híbrido o un método
content, el servicio de inspección te permite especificar dónde debe procesar tus datos. Para obtener más información, consulta Cómo se almacenan los datos.
Resumen de comparación: Servicios de descubrimiento e inspección
| Discovery | Inspección | |
|---|---|---|
| Beneficios |
|
|
| Costo |
10 TB cuestan aproximadamente USD 300 por mes en modo de consumo. |
10 TB cuestan alrededor de USD 10,000 por análisis. |
| Fuentes de datos compatibles | BigLake BigQuery Variables de entorno de las funciones de Cloud Run Variables de entorno de la revisión del servicio de Cloud Run Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore Híbrido (cualquier fuente)1 |
| Permisos admitidos |
|
Una sola tabla de BigQuery, un bucket de Cloud Storage o un tipo de Datastore |
| Plantillas de inspección integradas | Sí | Sí |
| Infotipos integrados y personalizados | Sí | Sí |
| Resultado del análisis | Descripción general de alto nivel (perfiles de datos) de todos los datos admitidos. | Son los resultados concretos de datos sensibles en el recurso inspeccionado. |
| Guarda los resultados en BigQuery | Sí | Sí |
| Enviar a Dataplex Universal Catalog como etiquetas (obsoleto) | Yes | Yes |
| Enviar a Dataplex Universal Catalog como aspectos | Yes | No |
| Publicar los resultados en Security Command Center | Yes | Yes |
| Publicar resultados en Google Security Operations | Sí para el descubrimiento a nivel de la organización y de la carpeta | No |
| Publicar en Pub/Sub | Yes | Sí |
| Compatibilidad con la residencia de datos | Yes | Yes |
1 La inspección híbrida tiene un modelo de precios diferente. Para obtener más información, consulta Inspección de datos de cualquier fuente .
¿Qué sigue?
- Explora las estrategias recomendadas para mitigar el riesgo de los datos (siguiente documento de esta serie).