This page describes and compares two Sensitive Data Protection services that help you understand your data and enable data governance workflows: the discovery service and the inspection service.
Sensitive data discovery
The discovery service monitors data across your organization. This service runs continuously and automatically discovers, classifies, and profiles data. Discovery can help you understand the location and nature of the data you're storing, including data resources that you might not be aware of. Unknown data (sometimes called shadow data) typically doesn't undergo the same level of data governance and risk management as known data.
You configure discovery at various scopes. You can set different profiling schedules for different subsets of your data. You can also exclude subsets of data that you don't need to profile.
Discovery scan output: data profiles
The output of a discovery scan is a set of data profiles for each data resource in scope. For example, a discovery scan of BigQuery or Cloud SQL data generates data profiles at the project, table, and column levels.
A data profile contains metrics and insights about the profiled resource. It includes the data classifications (or infoTypes), sensitivity levels, data risk levels, data size, data shape, and other elements that describe the nature of the data and its data security posture (how secure the data is). You can use data profiles to make informed decisions about how to protect your data—for example, by setting access policies on the table.
Consider a BigQuery column called ccn, where each row contains a
unique credit card number and there are no null values. The generated
column-level data profile will have the following details:
| Display name | Value |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Additionally, this column-level profile is part of a table-level profile, which provides insights like the data location, encryption status, and whether the table is shared publicly. In the Google Cloud console, you can also view the Cloud Logging entries for the table, and the IAM principals with roles for the table.
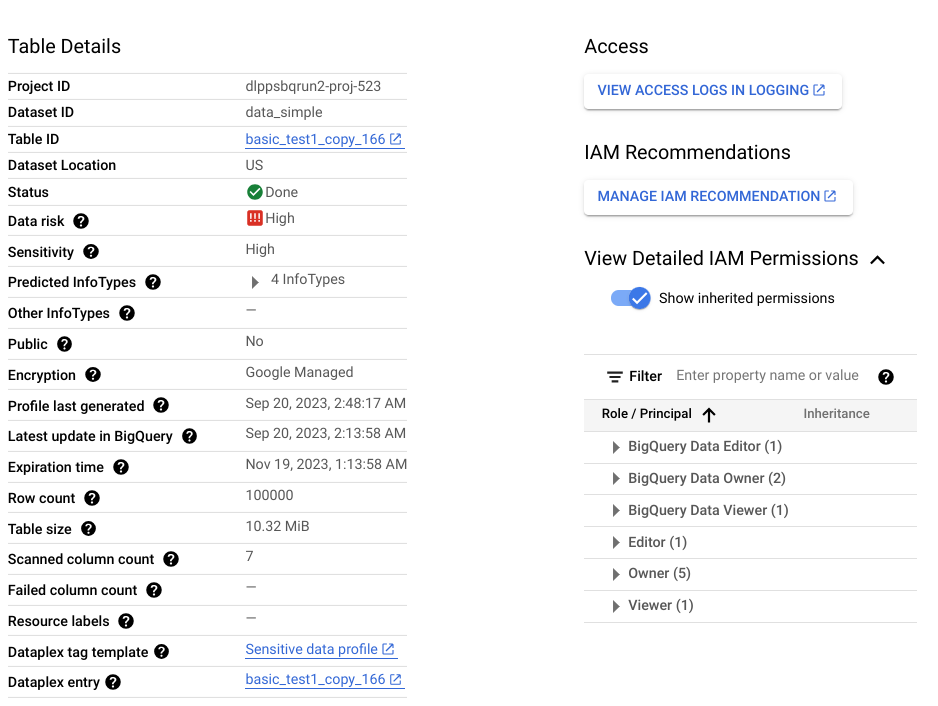
For a full list of metrics and insights available in data profiles, see Metrics reference.
When to use discovery
When you plan your data risk management approach, we recommend that you start with discovery. The discovery service helps you get a broad view of your data and enable alerting, reporting, and remediation of issues.
In addition, the discovery service can help you identify the resources where unstructured data might reside. Such resources might warrant an exhaustive inspection. Unstructured data is specified by a high free text score in a scale from 0 to 1.
Sensitive data inspection
The inspection service performs an exhaustive scan of a single resource to locate each individual instance of sensitive data. An inspection produces a finding for each detected instance.
Inspection jobs provide a rich set of configuration options to help you pinpoint the data you want to inspect. For example, you can turn on sampling to limit the data to be inspected to a certain number of rows (for BigQuery data) or certain file types (for Cloud Storage data). You can also target a specific timespan in which the data was created or modified.
Unlike discovery, which continuously monitors your data, an inspection is an on-demand operation. However, you can schedule recurring inspection jobs called job triggers.
Inspection scan output: findings
Each finding includes details like the location of the detected instance, its potential infoType, and the certainty (also called likelihood) that the finding matches the infoType. Depending on your settings, you can also get the actual string that the finding pertains to; this string is called a quote in Sensitive Data Protection.
For a full list of details included in an inspection finding, see
Finding.
When to use inspection
An inspection is useful when you need to investigate unstructured data (like user-created comments or reviews) and identify each instance of personally identifiable information (PII). If a discovery scan identifies any resources containing unstructured data, we recommend running an inspection scan on those resources to get details on each individual finding.
When not to use inspection
Inspecting a resource isn't useful if both of the following conditions apply. A discovery scan can help you decide if an inspection scan is needed.
- You have only structured data in the resource. That is, there are no columns of freeform data, like user comments or reviews.
- You already know the infoTypes stored in that resource.
For example, suppose that data profiles from a discovery scan indicate that a
certain BigQuery table doesn't have columns with unstructured
data but has a column of unique credit card numbers. In this case, inspecting
for credit card numbers in the table isn't useful. An inspection will produce a
finding for each item in the column. If you have 1 million rows and each row
contains 1 credit card number, an inspection job will produce 1 million findings
for the CREDIT_CARD_NUMBER infoType. In this example, the inspection isn't
needed because the discovery scan already indicates that the
column contains unique credit card numbers.
Data residency, processing, and storage
Both discovery and inspection support data residency requirements:
- The discovery service processes your data where it resides and stores the generated data profiles in the same region or multi-region as the profiled data. For more information, see Data residency considerations.
- When inspecting data within a Google Cloud storage system, the
inspection service processes your data in the same region where the
data resides and stores the inspection job in that region. When inspecting
data through a hybrid job or through a
contentmethod, the inspection service lets you specify where it should process your data. For more information, see How data is stored.
Comparison summary: discovery and inspection services
| Discovery | Inspection | |
|---|---|---|
| Benefits |
|
|
| Cost |
10 TB costs approximately US$300 per month in consumption mode. |
10 TB costs approximately US$10,000 per scan. |
| Supported data sources | BigLake BigQuery Cloud Run functions environment variables Cloud Run service revision environment variables Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore Hybrid (any source)1 |
| Supported scopes |
|
A single BigQuery table, Cloud Storage bucket, or Datastore kind. |
| Built-in inspection templates | Yes | Yes |
| Built-in and custom infoTypes | Yes | Yes |
| Scan output | High-level overview (data profiles) of all supported data. | Concrete findings of sensitive data in the inspected resource. |
| Save results to BigQuery | Yes | Yes |
| Send to Dataplex Universal Catalog as tags (Deprecated) | Yes | Yes |
| Send to Dataplex Universal Catalog as aspects | Yes | No |
| Publish results to Security Command Center | Yes | Yes |
| Publish findings to Google Security Operations | Yes for organization-level and folder-level discovery | No |
| Publish to Pub/Sub | Yes | Yes |
| Data residency support | Yes | Yes |
1 Hybrid inspection has a different pricing model. For more information, see Inspection of data from any source .
What's next
- Explore recommended strategies for mitigating data risk (next document in this series)