This page provides recommended strategies for identifying and remediating data risk in your organization.
Protecting your data starts with understanding what data you are handling, where sensitive data is located, and how this data is secured and used. When you have a comprehensive view of your data and its security posture, you can take the appropriate measures to protect it and continuously monitor for compliance and risk.
This page assumes that you're familiar with the discovery and inspection services and their differences.
Enable sensitive data discovery
To determine where sensitive data exists in your business, configure discovery at the organization, folder, or project level. This service generates data profiles containing metrics and insights about your data, including their sensitivity levels and data risk levels.
As a service, discovery acts as a source of truth about your data assets and can automatically report metrics for audit reports. Additionally, discovery can connect to other Google Cloud services like Security Command Center, Google Security Operations, and Dataplex Universal Catalog to enrich security operations and data management.
The discovery service runs continuously and detects new data as your organization operates and grows. For example, if someone in your organization creates a new project and uploads a large amount of new data, the discovery service can discover, classify, and report on the new data automatically.
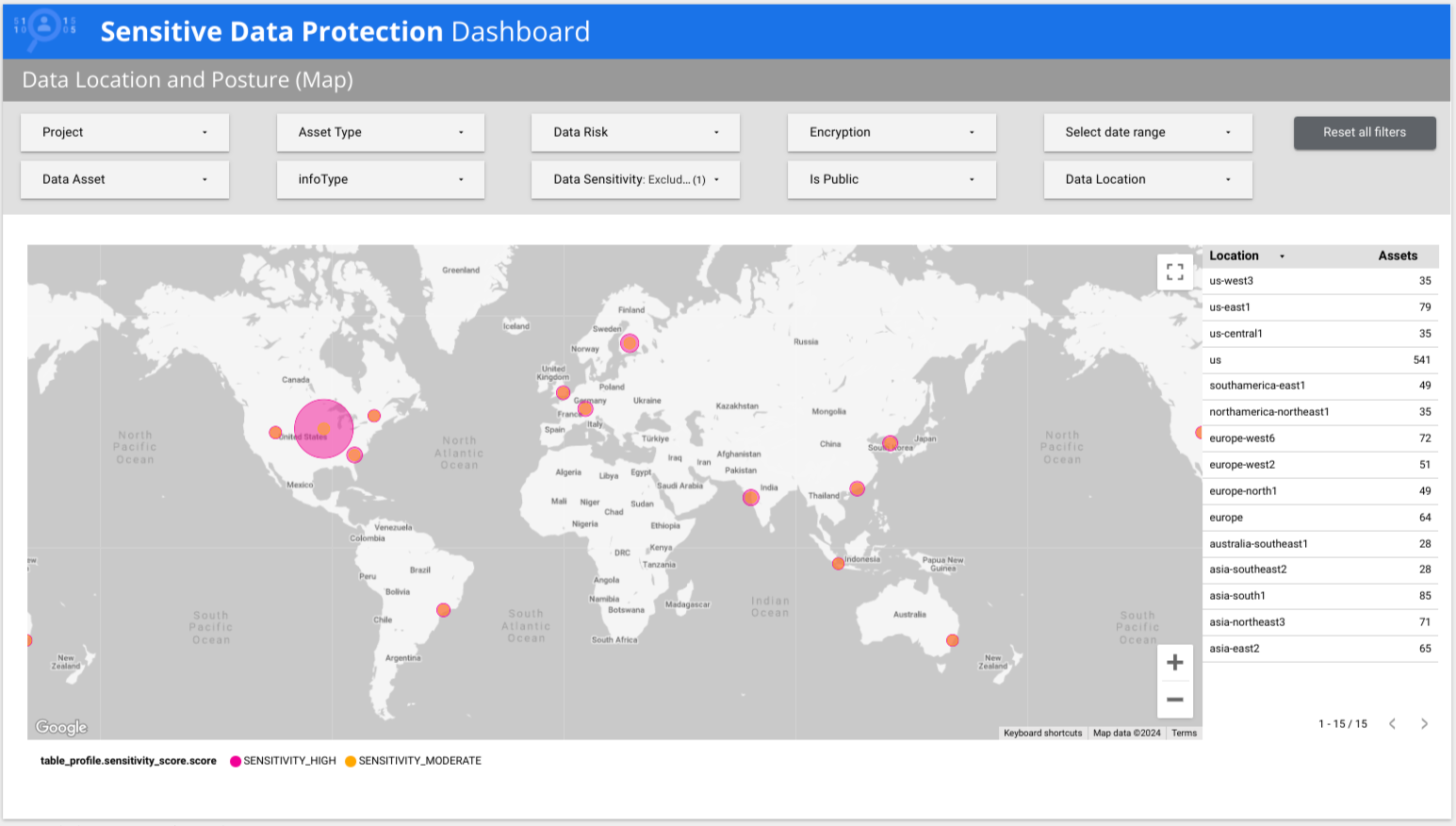
Sensitive Data Protection provides a premade multi-page Looker report that gives you a high-level view of your data, including breakdowns by risk, by infoType, and by location. In the following example, the report shows that low-sensitivity and high-sensitivity data are present in multiple countries around the world.
Take action based on discovery results
After you gain a broad view of your data security posture, you can remediate any issues found. In general, discovery findings fall into one of the following scenarios:
- Scenario 1: Sensitive data was found in a workload where it's expected and it's properly protected.
- Scenario 2: Sensitive data was found in a workload where it was not expected or where it does not have proper controls in place.
- Scenario 3: Sensitive data was found but needs more investigation.
Scenario 1: Sensitive data was found and is properly protected
Although this scenario doesn't require a specific action, you should include the data profiles in your audit reports and security analysis workflows and continue to monitor for changes that can put your data at risk.
We recommend doing the following:
Publish the data profiles to tools for monitoring your security posture and investigating cyber threats. Data profiles can help you determine the severity of a security threat or vulnerability that might put your sensitive data at risk. You can automatically export data profiles to the following:
Publish the data profiles to Dataplex Universal Catalog or an inventory system to track the data profile metrics along with any other appropriate business metadata. For information about automatically exporting data profiles to Dataplex Universal Catalog, see Add Dataplex Universal Catalog aspects based on insights from data profiles.
Scenario 2: Sensitive data was found and isn't properly protected
If discovery finds sensitive data in a resource that isn't properly secured by access controls, then consider the recommendations described in this section.
After you establish the correct controls and data security posture for your data, monitor for any changes that can put your data at risk. See the recommendations in scenario 1.
General recommendations
Consider doing the following:
Make a de-identified copy of your data to mask or tokenize the sensitive columns so that your data analysts and engineers can still work with your data without revealing raw, sensitive identifiers like personally identifiable information (PII).
For Cloud Storage data, you can use a built-in feature in Sensitive Data Protection to make de-identified copies.
If you don't need the data, then consider deleting it.
Recommendations for protecting BigQuery data
- Adjust table-level permissions using IAM.
Set fine-grained column-level access controls by using BigQuery policy tags to restrict access to the sensitive and high-risk columns. This feature lets you protect those columns while allowing access to the rest of the table.
You can also use policy tags to enable automatic data masking, which can give users partially obfuscated data.
Use the row-level security feature of BigQuery to hide or display certain rows of data, depending on whether a user or group is in an allowed list.
De-identify BigQuery data at query time with remote functions (UDF).
Recommendations for protecting Cloud Storage data
Scenario 3: Sensitive data was found but needs more investigation
In some cases, you might get results that require more investigation. For example, a data profile might specify that a column has a high free-text score with evidence of sensitive data. A high free-text score indicates that the data doesn't have a predictable structure and might contain intermittent instances of sensitive data. This might be a column of notes where certain rows contain PII, such as names, contact details, or government-issued identifiers. In this case, we recommend that you set additional access controls on the table and perform other remediations described in scenario 2. In addition, we recommend running a deeper, targeted inspection to identify the extent of the risk.
The inspection service lets you run a thorough scan of a single resource, such as an individual BigQuery table or a Cloud Storage bucket. For data sources that are not directly supported by the inspection service, you can export the data into a Cloud Storage a bucket or BigQuery table and run an inspection job on that resource. For example, if you have data that you need to inspect in a Cloud SQL database, you can export that data to a CSV or AVRO file in Cloud Storage and run an inspection job.
An inspection job locates individual instances of sensitive data, such as a credit card number in the middle of a sentence inside a table cell. This level of detail can help you understand what kind of data is present in unstructured columns or in data objects, including text files, PDFs, images, and other rich document formats. You can then remediate your findings through any of the recommendations described in scenario 2.
In addition to the steps recommended in scenario 2, consider taking steps to
prevent sensitive information from entering your backend data storage.
The content methods
of the Cloud Data Loss Prevention API can accept data from any workload or application
for in-motion data inspection and masking. For example, your application can do
the following:
- Accept a user-provided comment.
- Run
content.deidentifyto de-identify any sensitive data from that string. - Save the de-identified string to your backend storage instead of the original string.
Summary of best practices
The following table summarizes the best practices recommended in this document:
| Challenge | Action |
|---|---|
| You want to know what kind of data your organization is storing. | Run discovery at the organization, folder, or project level. |
| You found sensitive data in a resource that is already protected. | Continuously monitor that resource by running discovery and automatically exporting profiles to Security Command Center, Google SecOps, and Dataplex Universal Catalog. |
| You found sensitive data in a resource that isn't protected. | Hide or display data based on who is viewing it; use IAM, column-level security, or row-level security. You can also use the de-identification tools of Sensitive Data Protection to transform or remove the sensitive elements. |
| You found sensitive data and you need to investigate further to understand the extent of your data risk. | Run an inspection job on the resource. You can also proactively prevent
sensitive data from entering your backend storage by using the synchronous
content methods of the DLP API, which process data
in near real time. |