このページでは、データの理解とデータ ガバナンス ワークフローの実現に役立つ 2 つの機密データの保護サービス(検出サービスと検査サービス)について説明し、比較します。
機密データの検出
検出サービスは、組織全体のデータをモニタリングします。このサービスは継続的に実行され、データの検出、分類、プロファイリングが自動的に行われます。検出は、保存しているデータの場所と性質(認識していないデータリソースなど)を把握するのに役立ちます。未知のデータ(シャドウデータとも呼ばれる)には、通常、既知のデータと同じレベルのデータ ガバナンスやリスク管理は適用されません。
さまざまなスコープで検出を構成します。データのサブセットごとに異なるプロファイリング スケジュールを設定できます。プロファイリングする必要のないデータのサブセットを除外することもできます。
検出スキャンの出力: データ プロファイル
検出スキャンの出力は、スコープ内の各データリソースに対するデータ プロファイルのセットです。たとえば、BigQuery または Cloud SQL データの検出スキャンにより、プロジェクト レベル、テーブルレベル、列レベルでデータ プロファイルが生成されます。
データ プロファイルには、プロファイリングされたリソースに関する指標と分析情報が含まれています。データ プロファイルには、データ分類(または infoTypes)、機密性レベル、データリスク レベル、データサイズ、データ形状、およびデータの性質とそのデータ セキュリティ対策(データの安全性)を記述するその他の要素が含まれます。データ プロファイルを使用すると、データの保護方法(テーブルへのアクセス ポリシーの設定など)に関して情報に基づいた意思決定が可能となります。
各行に一意のクレジットカード番号が含まれ、NULL 値がない ccn という BigQuery 列を考えてみましょう。生成された列レベルのデータ プロファイルの詳細は、次のようになります。
| 表示名 | 値 |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
また、この列レベルのプロファイルはテーブルレベルのプロファイルの一部であり、データの場所、暗号化ステータス、テーブルが一般公開されているかどうかなどの分析情報を提供します。 Google Cloud コンソールには、テーブルの Cloud Logging エントリと、テーブルに対するロールがある IAM プリンシパルを表示することもできます。
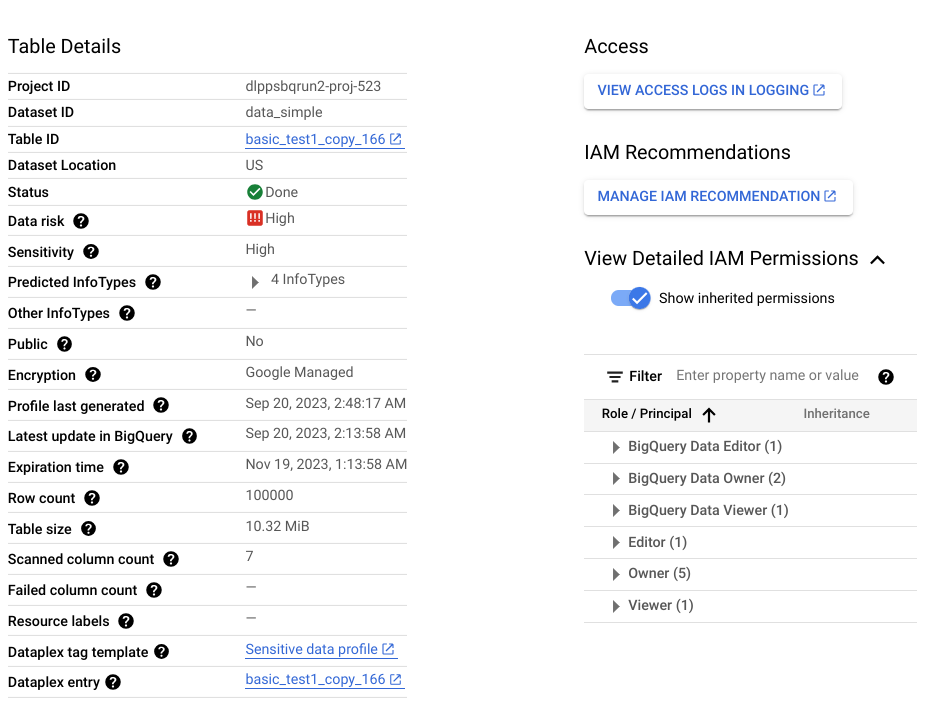
データ プロファイルで使用可能な指標と分析情報の完全なリストについては、指標のリファレンスをご覧ください。
検出を使用する場合
データリスク管理のアプローチを計画する場合は、まず検出から始めることをおすすめします。検出サービスを使用すると、データの全体像を把握し、問題のアラート、レポート、修復を可能にするのに役立ちます。
さらに、この検出サービスは、非構造化データが存在する可能性のあるリソースを特定するうえで役立ちます。そうしたリソースには徹底的な検査が必要となる可能性があります。非構造化データは、0~1 のスケールの高いフリーテキスト スコアで指定されます。
機密データの検査
検査サービスは、1 つのリソースを徹底的にスキャンして、機密データの個々のインスタンスを特定します。検査では、検出されたインスタンスごとに検出結果が生成されます。
検査ジョブには、検査する必要があるデータをピンポイントで特定できる豊富な構成オプションが用意されています。たとえば、サンプリングをオンにして、検査するデータを特定の行数(BigQuery データの場合)または特定のファイル形式(Cloud Storage データの場合)に制限できます。データが作成または変更された特定のタイムスパンをターゲットにすることもできます。
データを継続的にモニタリングする検出とは異なり、検査はオンデマンド オペレーションです。ただし、ジョブトリガーと呼ばれる定期的な検査ジョブをスケジュールできます。
検査スキャンの出力: 検出結果
各検出結果には、検出されたインスタンスの場所、検出結果の潜在的な infoType、検出結果が infoType に一致する確実性(尤度とも呼ばれる)などの詳細情報が含まれます。設定によっては、検出結果に関連する実際の文字列を取得することもできます。この文字列は、機密データの保護では引用符と呼ばれます。
検査結果に含まれる詳細情報の一覧については、Finding をご覧ください。
検査を使用する場合
検査は、非構造化データ(ユーザーが作成したコメントやレビューなど)を調査して、個人情報(PII)の各インスタンスを識別する必要がある場合に便利です。検出スキャンで非構造化データが含まれるリソースが特定された場合は、それらのリソースに対して検査スキャンを実行して、個々の検出結果の詳細情報を取得することをおすすめします。
検査を使用しない場合
次の両方の条件に該当する場合、リソースの検査は役に立ちません。検出スキャンは、検査スキャンが必要かどうかを判断するのに役立ちます。
- リソースに構造化データしかない。つまり、ユーザーのコメントやレビューなどの自由形式のデータの列がない。
- そのリソースに格納されている infoType をすでに把握している。
たとえば、検出スキャンのデータ プロファイルで、ある BigQuery テーブルに非構造化データを含む列はないが、一意のクレジット カード番号の列があることが示されているとします。この場合、デーブルのクレジット カード番号を検査することは役に立ちません。検査では、列の各項目に対して検出結果が生成されます。100 万行があって各行に 1 つのクレジット カード番号が含まれている場合、検査ジョブは CREDIT_CARD_NUMBER infoType に対して 100 万行の検出結果を生成します。この例では、検出スキャンですでに列に一意のクレジット カード番号が含まれていることが示されているため、検査は必要ありません。
データの所在地、処理、保存
検出と検査の両方でデータ所在地要件がサポートされています。
- 検出サービスは、データが存在する場所でデータを処理し、生成されたデータ プロファイルを、プロファイリングされたデータと同じリージョンまたはマルチリージョンに保存します。詳細については、データ所在地に関する検討事項をご覧ください。
- Google Cloud ストレージ システム内のデータを検査する場合、検査サービスはデータが存在するリージョンと同じリージョンでデータを処理し、そのリージョンに検査ジョブを保存します。ハイブリッド ジョブまたは
contentメソッドを使用してデータを検査する場合、検査サービスではデータの処理場所を指定できます。詳細については、データの保存方法をご覧ください。
比較の概要: 検出サービスと検査サービス
| 発見 | 検査 | |
|---|---|---|
| 利点 |
|
|
| 費用 |
10 TB の費用は約 US$300/月(消費モードの場合)。 |
10 TB の費用は約 US$10,000/スキャン。 |
| サポートされるデータソース | BigLake BigQuery Cloud Run 関数の環境変数 Cloud Run サービス リビジョンの環境変数 Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore ハイブリッド(任意のソース)1 |
| サポートされているスコープ |
|
単一の BigQuery テーブル、Cloud Storage バケット、または Datastore の種類。 |
| 組み込みの検査テンプレート | ○ | ○ |
| 組み込みとカスタムの infoType | ○ | ○ |
| スキャン出力 | サポートされているすべてのデータの概要(データ プロファイル)。 | 検査されたリソース内の機密データの具体的な検出結果。 |
| 結果の BigQuery への保存 | ○ | ○ |
| タグとして Dataplex Universal Catalog に送信する(非推奨) | はい | はい |
| アスペクトとして Dataplex Universal Catalog に送信する | はい | いいえ |
| 結果を Security Command Center に公開する | はい | はい |
| Google Security Operations に結果を公開する | 組織レベルとフォルダレベルの検出の場合は「はい」 | × |
| Pub/Sub に公開 | はい | ○ |
| データ所在地のサポート | はい | はい |
1 ハイブリッド検査には異なる料金モデルがあります。詳細については、任意のソースからのデータの検査をご覧ください。
次のステップ
- データリスクを軽減するために推奨される戦略(このシリーズの次のドキュメント)を確認する。