Auf dieser Seite wird der Dienst zur Erkennung sensibler Daten beschrieben. Mit diesem Dienst können Sie leichter ermitteln, wo sich sensible Daten und Daten mit hohem Risiko in Ihrer Organisation befinden.
Übersicht
Mit dem Erkennungsservice können Sie Daten in Ihrer Organisation schützen, indem Sie ermitteln, wo sich vertrauliche Daten und Daten mit hohem Risiko befinden. Wenn Sie eine Scankonfiguration für die Erkennung erstellen, werden Ihre Ressourcen vom Sensitive Data Protection-Dienst gescannt, um die Daten zu ermitteln, die für die Profilierung infrage kommen. Anschließend werden Profile Ihrer Daten erstellt. Solange die Konfiguration für die Erkennung aktiv ist, erstellt Sensitive Data Protection automatisch Profile für Daten, die Sie hinzufügen und ändern. Sie können Datenprofile für die gesamte Organisation, einzelne Ordner und einzelne Projekte generieren.
Jedes Datenprofil besteht aus einer Reihe von Statistiken und Metadaten, die der Discovery-Dienst beim Scannen einer unterstützten Ressource erfasst. Zu den Statistiken gehören die vorhergesagten infoTypes und die berechneten Datenrisiko- und Empfindlichkeitsstufen Ihrer Daten. Verwenden Sie diese Informationen, um fundierte Entscheidungen darüber zu treffen, wie Sie Ihre Daten schützen, freigeben und verwenden.
Datenprofile werden mit unterschiedlichen Detaillierungsgraden generiert. Wenn Sie beispielsweise BigQuery-Daten profilieren, werden Profile auf Projekt-, Tabellen- und Spaltenebene generiert.
Die folgende Abbildung zeigt eine Liste der Datenprofile auf Spaltenebene. Klicken Sie auf das Bild, um es zu vergrößern.

Eine Liste der in jedem Datenprofil enthaltenen Statistiken und Metadaten finden Sie in der Referenz zu Messwerten.
Weitere Informationen zur Google Cloud Ressourcenhierarchie finden Sie unter Ressourcenhierarchie.
Generierung von Datenprofilen
Zum Generieren von Datenprofilen erstellen Sie eine Erfassungskonfiguration (auch als Datenprofilkonfiguration bezeichnet). In dieser Scankonfiguration legen Sie den Umfang des Discovery-Vorgangs und die Art der Daten fest, die Sie profilieren möchten. In der Scankonfiguration können Sie Filter festlegen, um Teilmengen von Daten anzugeben, die Sie profilieren oder überspringen möchten. Sie können auch den Zeitplan für die Profilierung festlegen.
Beim Erstellen einer Scankonfiguration legen Sie auch die zu verwendende Inspektionsvorlage fest. In der Inspektionsvorlage geben Sie die Typen sensibler Daten (auch infoTypes genannt) an, nach denen der Schutz sensibler Daten suchen muss.
Wenn der Schutz sensibler Daten Datenprofile erstellt, werden Ihre Daten basierend auf Ihrer Scankonfiguration und Inspektionsvorlage analysiert.
Der Schutz sensibler Daten erstellt neue Datenprofile wie unter Häufigkeit der Datenprofilerstellung beschrieben. Sie können die Profilerstellungshäufigkeit in Ihrer Scankonfiguration anpassen, indem Sie einen Zeitplan erstellen. Wie Sie den Discovery-Dienst dazu zwingen, Ihre Daten neu zu profilieren, erfahren Sie unter Neuprofilierung erzwingen.
Arten der Erkennung
In diesem Abschnitt werden die Arten von Discovery-Vorgängen beschrieben, die Sie ausführen können, und die unterstützten Datenressourcen.
Discovery für BigQuery und BigLake
Wenn Sie BigQuery-Daten profilieren, werden Datenprofile auf Projekt-, Tabellen- und Spaltenebene generiert. Nachdem Sie eine BigQuery-Tabelle profiliert haben, können Sie die Ergebnisse mit einer Detailprüfung weiter untersuchen.
Tabellen mit Profilen für den Schutz sensibler Daten, die von der BigQuery Storage Read API unterstützt werden, darunter:
- Standard-BigQuery-Tabellen
- Tabellen-Snapshots
- In Cloud Storage gespeicherte BigLake-Tabellen
Folgendes wird nicht unterstützt:
- BigQuery Omni-Tabellen
- Tabellen, bei denen die Größe der serialisierten Daten einzelner Zeilen die maximale Größe der serialisierten Daten überschreitet, die von der BigQuery Storage Read API unterstützt wird: 128 MB.
- Externe Nicht-BigLake-Tabellen, z. B. Google Tabellen
Weitere Informationen zum Erstellen von BigQuery-Datenprofilen finden Sie unter den folgenden Links:
- BigQuery-Daten in einem einzigen Projekt profilieren
- BigQuery-Daten in einer Organisation oder einem Ordner profilieren
Weitere Informationen zu BigQuery finden Sie in der BigQuery-Dokumentation.
Discovery für Cloud SQL
Wenn Sie Cloud SQL-Daten profilieren, werden Datenprofile auf Projekt-, Tabellen- und Spaltenebene generiert. Bevor die Suche beginnen kann, müssen Sie die Verbindungsdetails für jede Cloud SQL-Instanz angeben, die profiliert werden soll.
Informationen zum Erstellen von Cloud SQL-Datenprofilen finden Sie unter den folgenden Links:
- Cloud SQL-Daten in einem einzigen Projekt profilieren
- Cloud SQL-Daten in einer Organisation oder einem Ordner profilieren
Weitere Informationen zu Cloud SQL finden Sie in der Cloud SQL-Dokumentation.
Discovery für Cloud Storage
Wenn Sie Cloud Storage-Daten profilieren, werden Datenprofile auf Bucketebene generiert. Der Schutz sensibler Daten gruppiert die erkannten Dateien in Dateicluster und stellt eine Zusammenfassung für jeden Cluster bereit.
Informationen zum Erstellen von Cloud Storage-Profilen finden Sie unter den folgenden Links:
- Cloud Storage-Daten in einem einzigen Projekt profilieren
- Cloud Storage-Daten in einer Organisation oder einem Ordner erfassen
Weitere Informationen zu Cloud Storage finden Sie in der Cloud Storage-Dokumentation.
Discovery für Vertex AI
Wenn Sie ein Vertex AI-Dataset profilieren, generiert der Sensitive Data Protection-Dienst je nach Speicherort Ihrer Trainingsdaten (Cloud Storage oder BigQuery) ein Datenprofil für Dateispeicher oder ein Datenprofil für Tabellen.
Hier finden Sie weitere Informationen:
- Auffinden sensibler Daten für Vertex AI
- Vertex AI-Daten in einem einzigen Projekt profilieren
- Vertex AI-Daten in einer Organisation oder einem Ordner profilieren
Weitere Informationen zu Vertex AI finden Sie in der Dokumentation zu Vertex AI.
Discovery für Amazon S3
Wenn Sie S3-Daten profilieren, werden Datenprofile auf Bucketebene generiert. Der Schutz sensibler Daten gruppiert die erkannten Dateien in Dateicluster und stellt eine Zusammenfassung für jeden Cluster bereit.
Weitere Informationen finden Sie unter Ermittlung sensibler Daten für Amazon S3-Daten.
Cloud Run-Umgebungsvariablen
Der Discovery-Dienst kann das Vorhandensein von Secrets in Cloud Run-Funktionen und Cloud Run-Dienstüberarbeitungsumgebungsvariablen erkennen und alle Ergebnisse an das Security Command Center senden. Es werden keine Datenprofile generiert.
Weitere Informationen finden Sie unter Secrets in Umgebungsvariablen an das Security Command Center melden.
Rollen, die zum Konfigurieren und Aufrufen von Datenprofilen erforderlich sind
In den folgenden Abschnitten sind die erforderlichen Nutzerrollen nach ihrem Zweck kategorisiert. Je nachdem, wie Ihre Organisation eingerichtet ist, können Sie unterschiedliche Personen verschiedene Aufgaben ausführen lassen. Beispielsweise kann sich die Person, die Datenprofile konfiguriert, von der Person unterscheiden, die sie regelmäßig überwacht.
Rollen, die für die Arbeit mit Datenprofilen auf Organisations- oder Ordnerebene erforderlich sind
Mit diesen Rollen können Sie Datenprofile auf Organisations- oder Ordnerebene konfigurieren und aufrufen.
Achten Sie darauf, dass diese Rollen den richtigen Personen auf Organisationsebene zugewiesen werden. Alternativ kann Ihr Google Cloud Administrator benutzerdefinierte Rollen erstellen, die nur die relevanten Berechtigungen haben.
| Zweck | Vordefinierte Rolle | Relevante Berechtigungen |
|---|---|---|
| Konfiguration für die Datenerkennung erstellen und Datenprofile ansehen | DLP Administrator (roles/dlp.admin)
|
|
| Erstellen Sie ein Projekt, das als Dienst-Agent-Container verwendet werden soll.1 | Projektersteller (roles/resourcemanager.projectCreator) |
|
| Discovery-Zugriff gewähren2 | Eine der folgenden:
|
|
| Datenprofile ansehen (schreibgeschützt) | Leser von DLP-Datenprofilen (roles/dlp.dataProfilesReader) |
|
DLP-Leser (roles/dlp.reader) |
|
1 Wenn Sie nicht die Rolle „Projektersteller“ (roles/resourcemanager.projectCreator) haben, können Sie trotzdem eine Scankonfiguration erstellen. Der verwendete Dienst-Agent-Container muss jedoch ein vorhandenes Projekt sein.
2: Auch wenn Sie nicht die Rolle „Organization Administrator“ (roles/resourcemanager.organizationAdmin) oder „Security Admin“ (roles/iam.securityAdmin) haben, können Sie eine Scankonfiguration erstellen. Nachdem Sie die Scankonfiguration erstellt haben, muss eine Person in Ihrer Organisation, die eine dieser Rollen hat, dem Dienst-Agenten Zugriff auf die Suche gewähren.
Rollen, die für die Arbeit mit Datenprofilen auf Projektebene erforderlich sind
Mit diesen Rollen können Sie Datenprofile auf Projektebene konfigurieren und ansehen.
Achten Sie darauf, dass diese Rollen den richtigen Personen auf Projektebene zugewiesen werden. Alternativ kann Ihr Google Cloud Administrator benutzerdefinierte Rollen erstellen, die nur die relevanten Berechtigungen haben.
| Zweck | Vordefinierte Rolle | Relevante Berechtigungen |
|---|---|---|
| Datenprofile konfigurieren und ansehen | DLP Administrator (roles/dlp.admin)
|
|
| Datenprofile ansehen (schreibgeschützt) | Leser von DLP-Datenprofilen (roles/dlp.dataProfilesReader) |
|
DLP-Leser (roles/dlp.reader) |
|
Konfiguration des Erkennungsscans
In einer Erfassungs-Scankonfiguration (manchmal auch Erfassungskonfiguration oder Scankonfiguration genannt) wird angegeben, wie Ihre Daten mit dem Schutz sensibler Daten profiliert werden sollen. Dazu gehören die folgenden Einstellungen:
- Umfang (Organisation, Ordner oder Projekt) der Erkennungsoperation
- Art der Ressource, die profiliert werden soll
- Verfügbare Inspektionsvorlagen
- Scannfrequenz
- Bestimmte Teilmengen von Daten, die in die explorative Datenanalyse einbezogen oder daraus ausgeschlossen werden sollen
- Aktionen, die Sensitive Data Protection nach der Erkennung ausführen soll, z. B. in welchen Google Cloud Diensten die Profile veröffentlicht werden sollen
- Dienstagent für Erkennungsvorgänge
Informationen zum Erstellen einer Konfigurationsdatei für den explorativen Scan finden Sie auf den folgenden Seiten:
Discovery für BigQuery-Daten
Discovery für Cloud SQL-Daten
Discovery für Cloud Storage-Daten
Entdeckung für Vertex AI-Daten
Secrets in Cloud Run-Umgebungsvariablen an das Security Command Center melden (keine Profile generiert)
Gültigkeitsbereich der Scankonfiguration
Sie können eine Scankonfiguration auf den folgenden Ebenen erstellen:
- Organisation
- Ordner
- Projekt
- Einzelne Datenressource
Wenn zwei oder mehr aktive Scankonfigurationen auf Organisations- und Ordnerebene dasselbe Projekt in ihrem Bereich haben, ermittelt Sensitive Data Protection, welche Scankonfiguration Profile für dieses Projekt generieren kann. Weitere Informationen finden Sie auf dieser Seite unter Scankonfigurationen überschreiben.
Eine Scankonfiguration auf Projektebene kann immer ein Profil für das Zielprojekt erstellen und konkurriert nicht mit anderen Konfigurationen auf der Ebene des übergeordneten Ordners oder der Organisation.
Eine Konfiguration für den Scan einer einzelnen Ressource soll Ihnen dabei helfen, das Profiling für eine einzelne Datenressource zu untersuchen und zu testen.
Speicherort der Scankonfiguration
Wenn Sie zum ersten Mal eine Scankonfiguration erstellen, geben Sie an, wo Sensitive Data Protection sie speichern soll. Alle nachfolgenden Scankonfigurationen, die Sie erstellen, werden in derselben Region gespeichert.
Wenn Sie beispielsweise eine Scankonfiguration für Ordner A erstellen und in der Region us-west1 speichern, wird jede Scankonfiguration, die Sie später für andere Ressourcen erstellen, auch in dieser Region gespeichert.
Metadaten zu den zu profilierenden Daten werden in dieselbe Region wie Ihre Scankonfigurationen kopiert. Die Daten selbst werden jedoch nicht verschoben oder kopiert. Weitere Informationen finden Sie unter Überlegungen zum Datenstandort.
Inspektionsvorlage
Eine Inspektionsvorlage gibt an, nach welchen Informationstypen (oder infoTypes) der Schutz sensibler Daten beim Scannen Ihrer Daten sucht. Hier geben Sie eine Kombination aus integrierten infoTypes und optionalen benutzerdefinierten infoTypes an.
Außerdem können Sie eine Wahrscheinlichkeitsebene angeben, um einzugrenzen, was der Schutz sensibler Daten als Übereinstimmung betrachtet. Sie können Regelsätze hinzufügen, um unerwünschte Ergebnisse auszuschließen oder zusätzliche Ergebnisse einzubeziehen.
Wenn Sie eine Inspektionsvorlage ändern, die von der Scankonfiguration verwendet wird, werden die Änderungen standardmäßig nur auf zukünftige Scans angewendet. Ihre Aktion führt nicht zu einem erneuten Profilierungsvorgang für Ihre Daten.
Wenn Sie möchten, dass Änderungen an der Inspektionsvorlage die Neuprofilierung der betroffenen Daten auslösen, fügen Sie Ihrer Scankonfiguration einen Zeitplan hinzu oder aktualisieren Sie ihn und aktivieren Sie die Option, die Daten neu zu profilieren, wenn sich die Inspektionsvorlage ändert. Weitere Informationen finden Sie unter Häufigkeit der Datenprofilgenerierung.
Sie benötigen eine Inspektionsvorlage in jeder Region, in der Sie Daten haben, für die ein Profil erstellt werden soll. Wenn Sie eine einzelne Vorlage für mehrere Regionen verwenden möchten, können Sie eine Vorlage verwenden, die in der Region global gespeichert ist. Wenn Sie aufgrund von organisatorischen Richtlinien keine Inspektionsvorlage in der Region global erstellen können, müssen Sie für jede Region eine eigene Inspektionsvorlage festlegen. Weitere Informationen finden Sie unter Überlegungen zum Datenstandort.
Inspektionsvorlagen sind eine Kernkomponente der Plattform für den Schutz sensibler Daten. Datenprofile verwenden dieselben Inspektionsvorlagen, die Sie in allen Sensitive Data Protection-Diensten verwenden können. Weitere Informationen zu Inspektionsvorlagen finden Sie unter Vorlagen.
Dienst-Agent-Container und Dienst-Agent
Wenn Sie eine Scankonfiguration für Ihre Organisation oder einen Ordner erstellen, müssen Sie für den Schutz sensibler Daten einen Dienst-Agent-Container angeben. Ein Dienst-Agent-Container ist ein Google Cloud Projekt, mit dem Sensitive Data Protection in Rechnung gestellte Kosten im Zusammenhang mit Profiling-Vorgängen auf Organisations- und Ordnerebene erfasst.
Der Dienst-Agent-Container enthält einen Dienst-Agent, mit dem Sensitive Data Protection in Ihrem Namen Datenprofile erstellt. Sie benötigen einen Dienst-Agent, um sich bei Sensitive Data Protection und anderen APIs zu authentifizieren. Ihr Dienst-Agent muss alle erforderlichen Berechtigungen für den Zugriff auf und die Profilerstellung für Ihre Daten haben. Die ID des Dienst-Agents hat folgendes Format:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
Hier ist PROJECT_NUMBER die numerische Kennung des Dienst-Agent-Containers.
Beim Festlegen des Dienst-Agent-Containers können Sie ein vorhandenes Projekt auswählen. Wenn das ausgewählte Projekt einen Dienst-Agent enthält, gewährt Sensitive Data Protection diesem Dienst-Agent die erforderlichen IAM-Berechtigungen. Wenn für das Projekt kein Dienst-Agent vorhanden ist, erstellt Sensitive Data Protection einen Dienst-Agent und erteilt diesem automatisch Berechtigungen zur Datenprofilerstellung.
Alternativ können Sie festlegen, dass der Dienst zum Schutz sensibler Daten den Dienst-Agent-Container und den Dienst-Agent automatisch erstellt. Der Schutz sensibler Daten gewährt dem Kundenservicemitarbeiter automatisch Berechtigungen zur Datenprofilerstellung.
In beiden Fällen wird, falls Sensitive Data Protection Ihrem Dienst-Agent keinen Zugriff auf die Datenprofilerstellung gewährt, ein Fehler angezeigt, wenn Sie die Scan-Konfigurationsdetails ansehen.
Für Scankonfigurationen auf Projektebene benötigen Sie keinen Dienst-Agent-Container. Das Projekt, für das Sie ein Profil erstellen, dient dem Zweck des Dienst-Agent-Containers. Für die Ausführung von Profilerstellungsvorgängen verwendet der Schutz sensibler Daten den Dienst-Agenten des jeweiligen Projekts.
Zugriff auf die Datenprofilerstellung auf Organisations- oder Ordnerebene
Wenn Sie auf Organisations- oder Ordnerebene das Profiling konfigurieren, versucht der Schutz sensibler Daten, Ihrem Dienst-Agent automatisch Zugriff auf die Datenprofilerstellung zu gewähren. Wenn Sie jedoch nicht die Berechtigungen zum Zuweisen von IAM-Rollen haben, kann der Dienst zum Schutz sensibler Daten diese Aktion nicht in Ihrem Namen ausführen. Eine Person mit diesen Berechtigungen in Ihrer Organisation, z. B. ein Google Cloud Administrator, muss Ihrem Dienst-Agent Zugriff auf die Datenprofilerstellung gewähren.
Häufigkeit der Datenprofilerstellung
Nachdem Sie eine Scankonfiguration für die Erkennung für eine bestimmte Ressource erstellt haben, führt Sensitive Data Protection einen ersten Scan aus und erstellt Profile für die Daten im Umfang Ihrer Scankonfiguration.
Nach dem ersten Scan überwacht der Sensitive Data Protection-Dienst die profilierte Ressource kontinuierlich. Daten, die der Ressource hinzugefügt werden, werden kurz nach dem Hinzufügen automatisch profiliert.
Standardhäufigkeit der Neuprofilierung
Die Standardhäufigkeit für die Neuprofilierung hängt vom Erkennungstyp Ihrer Scankonfiguration ab:
- BigQuery-Profilierung: Warten Sie 30 Tage und erstellen Sie dann für jede Tabelle ein neues Profil, wenn sich das Schema, die Tabellenzeilen oder die Prüfvorlage geändert haben.
- Cloud SQL-Profilierung: Warten Sie 30 Tage und erstellen Sie dann für jede Tabelle ein neues Profil, wenn sich das Schema oder die Prüfvorlage geändert hat.
- Cloud Storage-Profilierung: Warten Sie für jeden Bucket 30 Tage und erstellen Sie dann ein neues Profil für den Bucket, wenn sich die Prüfungsvorlage geändert hat.
- Vertex AI-Profilierung: Warten Sie bei jedem Datensatz 30 Tage und erstellen Sie dann ein neues Profil für den Datensatz, wenn sich die Prüfungsvorlage geändert hat.
- Amazon S3-Profilierung: Warten Sie 30 Tage und erstellen Sie dann für jeden Bucket ein neues Profil, wenn sich die Inspektionsvorlage geändert hat.
Häufigkeit der Neuprofilierung anpassen
In der Scankonfiguration können Sie die Häufigkeit des Erstellens neuer Profile anpassen, indem Sie einen oder mehrere Zeitpläne für verschiedene Teilmengen Ihrer Daten erstellen.
Folgende Aktualisierungshäufigkeiten sind verfügbar:
- Profil nicht neu erstellen: Erstellen Sie nach dem Erstellen der ersten Profile keine neuen Profile.
- Profil täglich neu erstellen: Warten Sie 24 Stunden, bevor Sie das Profil neu erstellen.
- Profil wöchentlich neu erstellen: Warten Sie 7 Tage, bevor Sie das Profil neu erstellen.
- Profil monatlich neu erstellen: Warten Sie 30 Tage, bevor Sie das Profil neu erstellen.
Zeitplan für die Neuprofilierung
In der Scankonfiguration können Sie angeben, ob ein Teil der Daten regelmäßig neu profiliert werden soll, unabhängig davon, ob sich die Daten geändert haben. Mit der von Ihnen festgelegten Häufigkeit wird angegeben, wie viel Zeit zwischen den Profiling-Vorgängen vergehen muss. Wenn Sie beispielsweise die Häufigkeit auf „Wöchentlich“ festlegen, erstellt Sensitive Data Protection sieben Tage nach dem letzten Profiling ein Profil für die Datenressource.
Neuer Code bei der Aktualisierung
In der Scankonfiguration können Sie Ereignisse angeben, die Reprofilierungsvorgänge auslösen können. Beispiele für solche Ereignisse sind Aktualisierungen von Inspektionsvorlagen.
Wenn Sie diese Ereignisse auswählen, gibt der von Ihnen festgelegte Zeitplan an, wie lange der Schutz sensibler Daten wartet, bis Updates verfügbar sind, bevor Ihre Daten neu profiliert werden. Wenn innerhalb des angegebenen Zeitraums keine relevanten Änderungen wie Schemaänderungen oder Änderungen an Inspektionsvorlagen auftreten, werden keine Daten neu profiliert. Wenn die nächste relevante Änderung eintritt, werden die betroffenen Daten bei der nächsten Gelegenheit neu profiliert. Diese wird durch verschiedene Faktoren bestimmt, z. B. die verfügbare Maschinenkapazität oder die gekauften Aboeinheiten. Sensitive Data Protection wartet dann gemäß dem festgelegten Zeitplan darauf, dass wieder Updates verfügbar sind.
Angenommen, Ihre Scankonfiguration ist so festgelegt, dass bei Schemaänderungen monatlich ein neues Profil erstellt wird. Die Datenprofile wurden am 0. Tag erstellt. Bis zum 30. Tag treten keine Schemaänderungen auf, sodass keine Daten neu profiliert werden. Am 35. Tag erfolgt die erste Schemaänderung. Sensitive Data Protection erstellt bei der nächsten Gelegenheit ein neues Profil für die aktualisierten Daten. Das System wartet dann weitere 30 Tage, bis sich Schemaupdates angesammelt haben, bevor aktualisierte Daten neu profiliert werden.
Nach Beginn des Vorgangs kann es bis zu 24 Stunden dauern, bis er abgeschlossen ist. Wenn die Verzögerung länger als 24 Stunden dauert und Sie den Abopreis nutzen, prüfen Sie, ob Sie verbleibende Kapazität für den Monat haben.
Beispielszenarien finden Sie unter Preisbeispiele für Datenprofilerstellung.
Wie Sie den Discovery-Dienst dazu zwingen, Ihre Daten neu zu profilieren, erfahren Sie unter Neuprofilierung erzwingen.
Leistungsprofilierung
Wie lange es dauert, bis Ihre Daten profiliert sind, hängt von verschiedenen Faktoren ab, darunter:
- Anzahl der Datenressourcen, für die ein Profil erstellt wird
- Größe der Datenressourcen
- Bei Tabellen die Anzahl der Spalten
- Bei Tabellen: die Datentypen in den Spalten
Daher ist die Leistung von Sensitive Data Protection bei einer früheren Prüfung oder Profilierungsaufgabe kein Indikator für die Leistung bei zukünftigen Profilierungsaufgaben.
Aufbewahrung von Datenprofilen
Beim Schutz sensibler Daten wird die neueste Version eines Datenprofils 13 Monate lang aufbewahrt. Wenn der Schutz sensibler Daten ein Datenprofil neu erstellt, ersetzt das System die vorhandenen Profile dieser Datenressource durch neue.
Angenommen, in den folgenden Beispielszenarien ist die Standardprofilierungshäufigkeit für BigQuery aktiv:
Am 1. Januar erstellt der Schutz sensibler Daten ein Profil für Tabelle A. Tabelle A ändert sich mehr als ein Jahr lang nicht und daher wird kein neues Profil dafür erstellt. In diesem Fall speichert der Schutz sensibler Daten die Datenprofile für Tabelle A 13 Monate lang, bevor sie gelöscht werden.
Am 1. Januar erstellt der Schutz sensibler Daten für Tabelle A ein Profil. Innerhalb des Monats aktualisiert jemand in Ihrer Organisation das Schema dieser Tabelle. Aufgrund dieser Änderung wird im folgenden Monat automatisch ein neues Profil für Tabelle A erstellt. Die neu generierten Datenprofile überschreiben die im Januar erstellten.
Informationen zu den Preisen für die Profilerstellung von Daten mit Sensitive Data Protection finden Sie unter Erkennung – Preise.
Wenn Sie Datenprofile unbegrenzt aufbewahren oder einen Datensatz der vorgenommenen Änderungen aufbewahren möchten, sollten Sie die Datenprofile beim Konfigurieren des Profilerstellungstools in BigQuery speichern. Sie wählen, in welchem BigQuery-Dataset die Profile gespeichert werden sollen und steuern die Ablaufrichtlinie für dieses Dataset.
Scankonfigurationen überschreiben
Für jede Kombination aus Umfang und Erkennungstyp kann nur eine Scankonfiguration erstellt werden. Sie können beispielsweise nur eine Scankonfiguration auf Organisationsebene für das BigQuery-Datenprofiling und eine Scankonfiguration auf Organisationsebene für die Erkennung von Geheimnissen erstellen. Ebenso können Sie nur eine Scankonfiguration auf Projektebene für das BigQuery-Datenprofiling und eine Scankonfiguration auf Projektebene für die Geheimdatenerkennung erstellen.
Wenn zwei oder mehr aktive Scankonfigurationen dasselbe Projekt und denselben Discovery-Typ in ihrem Bereich haben, gelten die folgenden Regeln:
- Von den Scankonfigurationen auf Organisations- und Ordnerebene kann mit der Konfiguration, die dem Projekt am nächsten ist, die Datenerhebung für dieses Projekt ausgeführt werden. Diese Regel gilt auch dann, wenn für diesen Erkennungstyp auch eine Scankonfiguration auf Projektebene vorhanden ist.
- Der Schutz sensibler Daten behandelt Scankonfigurationen auf Projektebene unabhängig von Konfigurationen auf Organisations- und Ordnerebene. Eine auf Projektebene erstellte Scankonfiguration kann eine Konfiguration, die Sie für einen übergeordneten Ordner oder eine übergeordnete Organisation erstellen, nicht überschreiben.
Betrachten Sie das folgende Beispiel, in dem es drei aktive Scankonfigurationen gibt. Angenommen, alle diese Scankonfigurationen sind für das BigQuery-Datenprofiling vorgesehen.
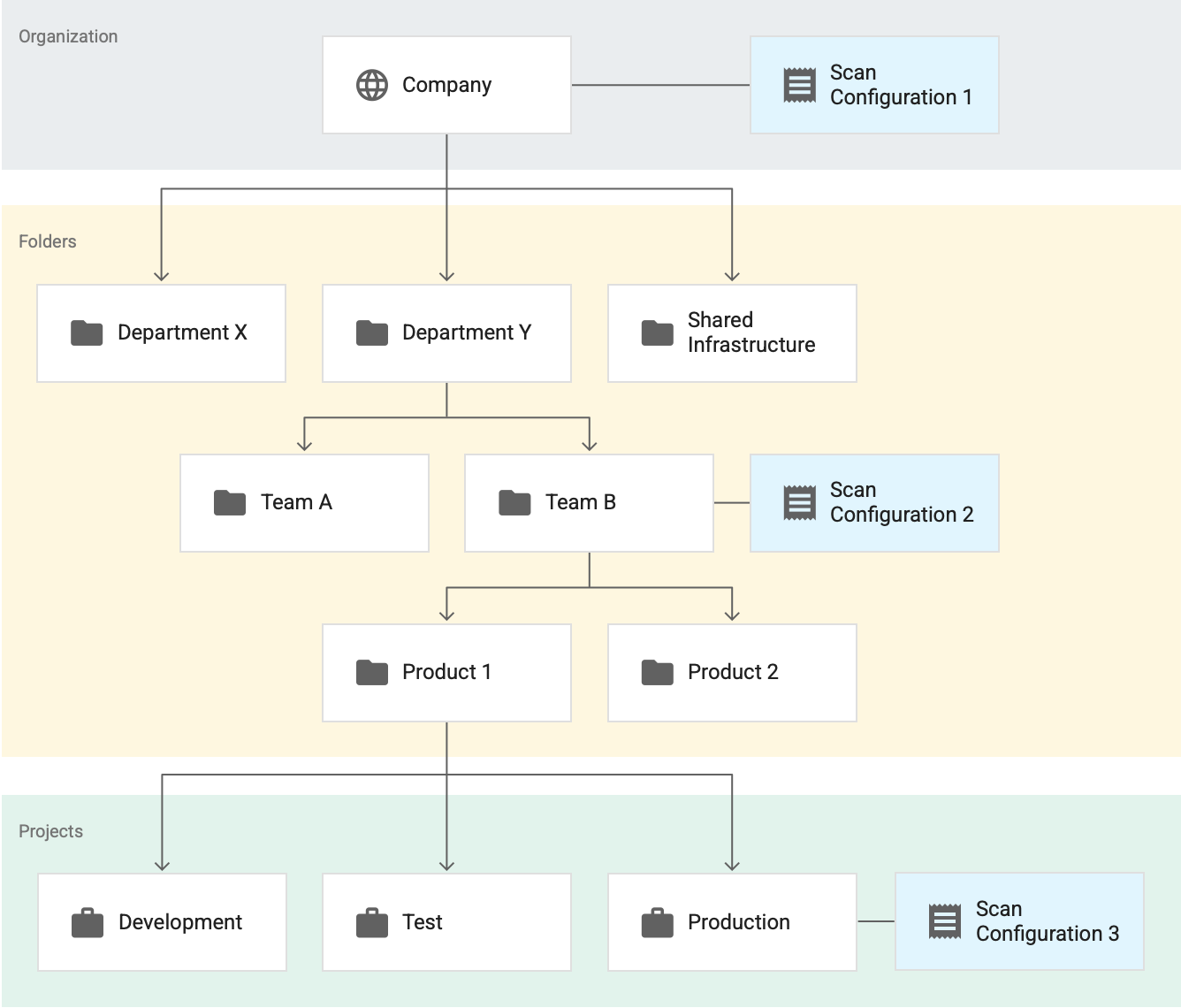
Hier gilt Scankonfiguration 1 für die gesamte Organisation, Scankonfiguration 2 gilt für den Team B-Ordner und Scankonfiguration 3 gilt für das Projekt Produktion. In diesem Fall gilt Folgendes:
- Der Schutz sensibler Daten erstellt Profile für alle Tabellen in Projekten, die sich nicht im Team B-Ordner befinden, gemäß Scankonfiguration 1.
- Der Schutz sensibler Daten erstellt Profile für alle Tabellen in Projekten im Ordner Team B, einschließlich Tabellen im Projekt Produktion, gemäß Scankonfiguration 2.
- Der Schutz sensibler Daten erstellt Profile für alle Tabellen im Projekt Produktion gemäß Scankonfiguration 3.
In diesem Beispiel generiert der Schutz sensibler Daten zwei Profilsätze für das Projekt Produktion – einen Satz für jede der folgenden Scankonfigurationen:
- Scankonfiguration 2
- Scankonfiguration 3
Obwohl es zwei Profilsätze für dasselbe Projekt gibt, können Sie sie jedoch nicht alle zusammen im Dashboard sehen. Sie sehen nur die Profile, die in der Ressource (Organisation, Ordner oder Projekt) und in der Region generiert wurden, die Sie gerade aufrufen.
Weitere Informationen zur Ressourcenhierarchie von Google Cloudfinden Sie unter Ressourcenhierarchie.
Snapshots von Datenprofilen
Jedes Datenprofil enthält einen Snapshot der Scankonfiguration und die Inspektionsvorlage, die zum Generieren verwendet wurde. Mit diesem Snapshot können Sie die Einstellungen prüfen, die Sie zum Generieren eines bestimmten Datenprofils verwendet haben.
Überlegungen zum Datenstandort für Google Cloud -Daten
Dieser Abschnitt gilt nur für die Suche nach sensiblen Daten in Google Cloud-Ressourcen. Informationen zu Datenspeicherorten im Zusammenhang mit Amazon S3-Daten finden Sie unter Ermittlung sensibler Daten für Amazon S3-Daten.
Sensitive Data Protection unterstützt den Datenstandort. Beachten Sie die folgenden Punkte, wenn Sie Anforderungen an den Datenstandort erfüllen müssen:
Regionale Inspektionsvorlagen
Dieser Abschnitt gilt nur für die Suche nach sensiblen Daten in Google Cloud-Ressourcen. Informationen zu Datenspeicherorten im Zusammenhang mit Amazon S3-Daten finden Sie unter Ermittlung sensibler Daten für Amazon S3-Daten.
Sensitive Data Protection verarbeitet Ihre Daten in derselben Region, in der diese Daten gespeichert sind. Das heißt, Ihre Daten verlassen nicht ihre aktuelle Region.
Außerdem können mit einer Inspektionsvorlage nur Profile für Daten erstellt werden, die sich in derselben Region wie diese Vorlage befinden. Wenn Sie beispielsweise die Datenermittlung so konfigurieren, dass eine in der Region us-west1 gespeicherte Inspektionsvorlage verwendet wird, kann der Dienst zum Schutz sensibler Daten nur Profile für Daten erstellen, die sich in dieser Region befinden.
Sie können für jede Region, in der Sie Daten haben, eine eigene Inspektionsvorlage festlegen.
Wenn Sie eine Inspektionsvorlage angeben, die in der Region global gespeichert ist, wird diese Vorlage von Sensitive Data Protection für Daten in Regionen verwendet, für die keine spezielle Inspektionsvorlage vorhanden ist.
Die folgende Tabelle enthält Beispielszenarien:
| Szenario | Support |
|---|---|
Scannen Sie Daten in der Region us mit einer Inspektionsvorlage aus der Region us. |
Unterstützt |
Scannen Sie Daten in der Region global mit einer Inspektionsvorlage aus der Region us. |
Nicht unterstützt |
Scannen Sie Daten in der Region us mit einer Inspektionsvorlage aus der Region global. |
Unterstützt |
Scannen Sie Daten in der Region us mit einer Inspektionsvorlage aus der Region us-east1. |
Nicht unterstützt |
Scannen Sie Daten in der Region us-east1 mit einer Inspektionsvorlage aus der Region us. |
Nicht unterstützt |
Scannen Sie Daten in der Region us mit einer Inspektionsvorlage aus der Region asia. |
Nicht unterstützt |
Konfiguration von Datenprofilen
Dieser Abschnitt gilt nur für die Suche nach sensiblen Daten in Google Cloud-Ressourcen. Informationen zu Datenspeicherorten im Zusammenhang mit Amazon S3-Daten finden Sie unter Ermittlung vertraulicher Daten für Amazon S3-Daten.
Wenn der Schutz sensibler Daten Datenprofile erstellt, wird ein Snapshot der Scankonfiguration und der Inspektionsvorlage erstellt und in jedem Tabellendatenprofil oder Dateispeicherdatenprofil gespeichert.
Wenn Sie die Suche so konfigurieren, dass eine Inspektionsvorlage aus der Region global verwendet wird, kopiert der Dienst zum Schutz sensibler Daten diese Vorlage in jede Region mit Daten, für die ein Profil erstellt werden soll. Die Scankonfiguration wird in diese Regionen kopiert.
Betrachten Sie dieses Beispiel: Projekt A enthält Tabelle 1. Tabelle 1 befindet sich in der Region us-west1. Die Scankonfiguration befindet sich in der Region us-west2 und die Inspektionsvorlage befindet sich in der Region global.
Wenn der Schutz sensibler Daten Projekt A scannt, werden Datenprofile für Tabelle 1 erstellt und in der Region us-west1 gespeichert. Das Tabellendatenprofil von Tabelle 1 enthält Kopien der Scankonfiguration und der bei der Profilerstellung verwendeten Inspektionsvorlage.
Wenn Ihre Inspektionsvorlage nicht in andere Regionen kopiert werden soll, konfigurieren Sie den Schutz vertraulicher Daten nicht so, dass Daten in diesen Regionen gescannt werden.
Regional Storage für Datenprofile
Dieser Abschnitt gilt nur für die Suche nach sensiblen Daten in Google Cloud-Ressourcen. Informationen zu Datenspeicherorten im Zusammenhang mit Amazon S3-Daten finden Sie unter Ermittlung sensibler Daten für Amazon S3-Daten.
Bei der Funktion zum Schutz sensibler Daten werden Ihre Daten in der Region oder Multi-Region verarbeitet, in der sie sich befinden, und die generierten Datenprofile werden in derselben Region oder Multi-Region gespeichert.
Wenn Sie sich Datenprofile in der Google Cloud Console ansehen möchten, müssen Sie zuerst die Region auswählen, in der sie sich befinden. Wenn Sie Daten in mehreren Regionen haben, müssen Sie die Regionen wechseln, um alle Gruppen von Profilen sehen zu können.
Nicht unterstützte Regionen
Dieser Abschnitt gilt nur für die Suche nach sensiblen Daten in Google Cloud-Ressourcen. Informationen zu Datenspeicherorten im Zusammenhang mit Amazon S3-Daten finden Sie unter Ermittlung sensibler Daten für Amazon S3-Daten.
Wenn Sie Daten in einer Region haben, die von Sensitive Data Protection nicht unterstützt wird, werden diese Datenressourcen vom Erkennungsdienst übersprungen und es wird eine Fehlermeldung angezeigt, wenn Sie sich die Datenprofile ansehen.
Multiregionen
Der Schutz sensibler Daten behandelt eine Multi-Region als eine Region, nicht als eine Sammlung von Regionen. Beispiel: Die Multi-Region us und die Region us-west1 werden im Hinblick auf den Datenstandort als zwei separate Regionen behandelt.
Zonale Ressourcen
Der Schutz sensibler Daten ist ein regionaler und multiregionaler Dienst. Es wird nicht zwischen Zonen unterschieden. Bei einer unterstützten zonalen Ressource wie einer Cloud SQL-Instanz werden die Daten in der aktuellen Region verarbeitet, aber nicht unbedingt in der aktuellen Zone. Wenn eine Cloud SQL-Instanz beispielsweise in der Zone us-central1-a gespeichert ist, werden die Datenprofile vom Schutz sensibler Daten in der Region us-central1 verarbeitet und gespeichert.
Allgemeine Informationen zu Google Cloud Standorten finden Sie unter Geografie und Regionen.
Compliance
Informationen dazu, wie der Schutz sensibler Daten Ihre Daten verarbeitet und Sie bei der Erfüllung von Compliance-Anforderungen unterstützt, finden Sie unter Datensicherheit.
Nächste Schritte
Blogbeitrag zu Identität und Sicherheit lesen: Automatisches Datenrisikomanagement für BigQuery mit dem Schutz sensibler Daten
Weitere Informationen zum Erstellen von Profildaten auf Organisations-, Ordner- oder Projektebene
Erfahren Sie, wie Sie Probleme mit dem Data Profiler beheben.