Questa pagina fornisce strategie consigliate per identificare e mitigare il rischio di perdita di dati nella tua organizzazione.
La protezione dei tuoi dati inizia con la comprensione di quali dati stai gestendo, dove si trovano i dati sensibili e come vengono protetti e utilizzati. Quando hai una visione completa dei tuoi dati e della loro postura di sicurezza, puoi adottare le misure appropriate per proteggerli e monitorare continuamente la conformità e il rischio.
Questa pagina presuppone che tu abbia familiarità con i servizi di rilevamento e ispezione e le loro differenze.
Attiva rilevamento di dati sensibili
Per determinare dove si trovano i dati sensibili nella tua attività, configura il rilevamento a livello di organizzazione, cartella o progetto. Questo servizio genera profili di dati contenenti metriche e approfondimenti sui tuoi dati, inclusi i livelli di sensibilità e di rischio.
In quanto servizio, il rilevamento funge da fonte di riferimento per le risorse di dati e può generare automaticamente metriche per i report di audit. Inoltre, l'individuazione può connettersi ad altri servizi Google Cloud come Security Command Center, Google Security Operations e Dataplex Universal Catalog per arricchire le operazioni di sicurezza e la gestione dei dati.
Il servizio di rilevamento viene eseguito continuamente e rileva nuovi dati man mano che la tua organizzazione opera e cresce. Ad esempio, se qualcuno nella tua organizzazione crea un nuovo progetto e carica una grande quantità di nuovi dati, il servizio di rilevamento può rilevare, classificare e generare report sui nuovi dati automaticamente.
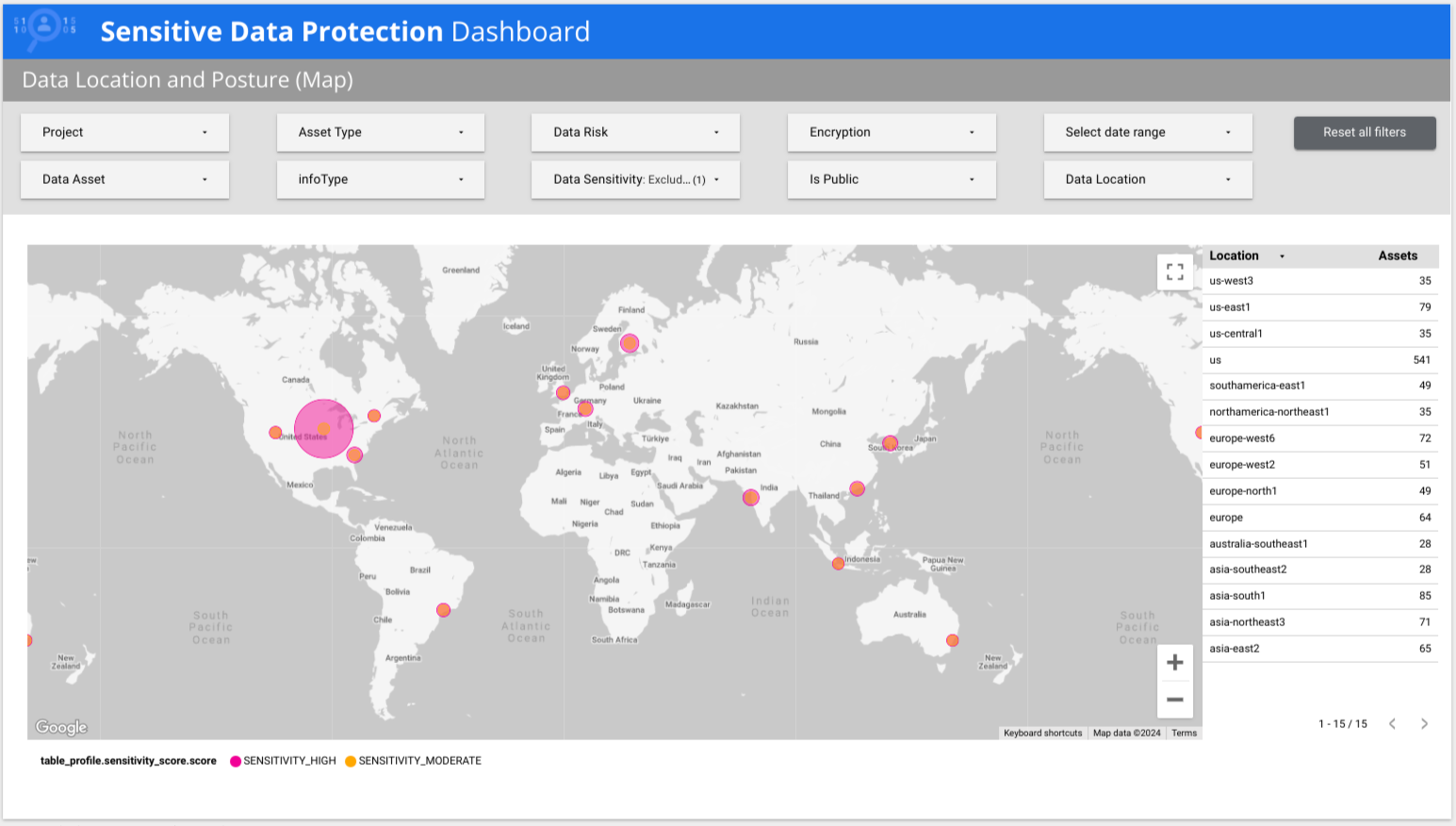
Sensitive Data Protection fornisce un report Looker multipage predefinito che offre una visione di alto livello dei tuoi dati, incluse suddivisioni per rischio, per infoType e per posizione. Nell'esempio seguente, il report mostra che i dati a bassa sensibilità e ad alta sensibilità sono presenti in più paesi in tutto il mondo.
Intervenire in base ai risultati del rilevamento
Dopo aver acquisito una visione generale della tua postura di sicurezza dei dati, puoi risolvere eventuali problemi riscontrati. In generale, i risultati del rilevamento rientrano in uno dei seguenti scenari:
- Scenario 1: sono stati trovati dati sensibili in un workload in cui sono previsti e sono protetti correttamente.
- Scenario 2: sono stati trovati dati sensibili in un workload in cui non erano previsti o in cui non sono in atto controlli adeguati.
- Scenario 3: sono stati trovati dati sensibili, ma è necessario approfondire l'indagine.
Scenario 1: sono stati trovati dati sensibili e sono protetti correttamente
Sebbene questo scenario non richieda un'azione specifica, devi includere i profili dei dati nei report di controllo e nei flussi di lavoro di analisi della sicurezza e continuare a monitorare le modifiche che possono mettere a rischio i tuoi dati.
Ti consigliamo di procedere come segue:
Pubblica i profili dei dati negli strumenti per monitorare la tua postura di sicurezza e analizzare le cyber minacce. I profili di dati possono aiutarti a determinare la gravità di una minaccia o vulnerabilità alla sicurezza che potrebbe mettere a rischio i tuoi dati sensibili. Puoi esportare automaticamente i profili dei dati in:
Pubblica i profili di dati in Dataplex Universal Catalog o in un sistema di inventario per monitorare le metriche del profilo di dati insieme a qualsiasi altro metadato aziendale appropriato. Per informazioni sull'esportazione automatica dei profili dei dati in Dataplex Universal Catalog, consulta Aggiungere aspetti di Dataplex Universal Catalog in base agli approfondimenti dei profili dei dati.
Scenario 2: sono stati trovati dati sensibili che non sono protetti correttamente
Se il rilevamento trova dati sensibili in una risorsa non protetta correttamente dai controlli dell'accesso, prendi in considerazione i suggerimenti descritti in questa sezione.
Dopo aver stabilito i controlli e la postura di sicurezza dei dati corretti per i tuoi dati, monitora eventuali modifiche che possono metterli a rischio. Consulta i suggerimenti nello scenario 1.
Consigli generali
Ti consigliamo di procedere nel seguente modo:
Crea una copia anonimizzata dei tuoi dati per mascherare o tokenizzare le colonne sensibili in modo che i tuoi analisti e ingegneri dei dati possano continuare a lavorare con i tuoi dati senza rivelare identificatori sensibili non elaborati come le informazioni che consentono l'identificazione personale (PII).
Per i dati di Cloud Storage, puoi utilizzare una funzionalità integrata in Sensitive Data Protection per creare copie anonimizzate.
Se non ti servono, valuta la possibilità di eliminarli.
Suggerimenti per proteggere i dati BigQuery
- Modifica le autorizzazioni a livello di tabella utilizzando IAM.
Imposta controlli di accesso granulari a livello di colonna utilizzando i tag di criteri di BigQuery per limitare l'accesso alle colonne sensibili e ad alto rischio. Questa funzionalità ti consente di proteggere queste colonne consentendo l'accesso al resto della tabella.
Puoi anche utilizzare i tag di criteri per attivare il mascheramento dei dati automatico, che può fornire agli utenti dati parzialmente offuscati.
Utilizza la funzionalità di sicurezza a livello di riga di BigQuery per nascondere o mostrare determinate righe di dati, a seconda se un utente o un gruppo fa parte di un elenco consentito.
Anonimizza i dati BigQuery al momento della query con funzioni remote (UDF).
Consigli per proteggere i dati di Cloud Storage
Scenario 3: sono stati trovati dati sensibili, ma sono necessarie ulteriori indagini
In alcuni casi, potresti ottenere risultati che richiedono ulteriori indagini. Ad esempio, un profilo dei dati potrebbe specificare che una colonna ha un punteggio di testo libero elevato con prove di dati sensibili. Un punteggio elevato di testo libero indica che i dati non hanno una struttura prevedibile e potrebbero contenere istanze intermittenti di dati sensibili. Potrebbe trattarsi di una colonna di note in cui alcune righe contengono PII, come nomi, dati di contatto o identificatori rilasciati dal governo. In questo caso, ti consigliamo di impostare controlli dell'accesso aggiuntivi sulla tabella ed eseguire altre correzioni descritte nello scenario 2. Inoltre, ti consigliamo di eseguire un'ispezione più approfondita e mirata per identificare l'entità del rischio.
Il servizio di ispezione consente di eseguire una scansione approfondita di una singola risorsa, ad esempio una singola tabella BigQuery o un bucket Cloud Storage. Per le origini dati non supportate direttamente dal servizio di ispezione, puoi esportare i dati in un bucket Cloud Storage o in una tabella BigQuery ed eseguire un job di ispezione su questa risorsa. Ad esempio, se hai dati che devi esaminare in un database Cloud SQL, puoi esportarli in un file CSV o AVRO in Cloud Storage ed eseguire un job di ispezione.
Un job di ispezione individua singole istanze di dati sensibili, ad esempio un numero di carta di credito al centro di una frase all'interno di una cella di una tabella. Questo livello di dettaglio può aiutarti a capire il tipo di dati presente nelle colonne non strutturate o negli oggetti dati, inclusi file di testo, PDF, immagini e altri formati di documenti richi. Puoi quindi correggere i risultati seguendo uno dei consigli descritti nello scenario 2.
Oltre ai passaggi consigliati nello scenario 2, valuta la possibilità di adottare misure per
impedire l'inserimento di informazioni sensibili nell'archivio dati di backend.
I metodi content
dell'API Cloud Data Loss Prevention possono accettare dati da qualsiasi carico di lavoro o applicazione
per l'ispezione e la mascheratura dei dati in movimento. Ad esempio, la tua applicazione può
fare quanto segue:
- Accettare un commento fornito dall'utente.
- Esegui
content.deidentifyper anonimizzare i dati sensibili dalla stringa. - Salva la stringa de-identificata nello spazio di archiviazione backend anziché nella stringa originale.
Riepilogo delle best practice
La tabella seguente riepiloga le best practice consigliate in questo documento:
| La sfida | Azione |
|---|---|
| Vuoi sapere che tipo di dati sta archiviando la tua organizzazione. | Esegui il rilevamento a livello di organizzazione, cartella o progetto. |
| Hai trovato dati sensibili in una risorsa già protetta. | Monitora continuamente la risorsa eseguendo il rilevamento ed esportando automaticamente i profili in Security Command Center, Google SecOps e Dataplex Universal Catalog. |
| Hai trovato dati sensibili in una risorsa non protetta. | Nascondi o visualizza i dati in base a chi li visualizza; utilizza IAM, la sicurezza a livello di colonna o la sicurezza a livello di riga. Puoi anche utilizzare gli strumenti di anonimizzazione di Sensitive Data Protection per trasformare o rimuovere gli elementi sensibili. |
| Hai trovato dati sensibili e devi approfondire l'analisi per comprendere l'entità del rischio dei dati. | Esegui un job di ispezione sulla risorsa. Puoi anche impedire in modo proattivo l'inserimento di dati sensibili nell'archiviazione di backend utilizzando i metodi sincroni content dell'API DLP, che elaborano i dati quasi in tempo reale. |