Se configurou o serviço de deteção de dados confidenciais para enviar todos os perfis de dados gerados com êxito para o BigQuery, pode consultar esses perfis de dados para obter estatísticas sobre os seus dados. Também pode usar ferramentas de visualização, como o Looker Studio, para criar relatórios personalizados adaptados às necessidades da sua empresa. Em alternativa, pode usar um relatório predefinido fornecido pela Proteção de dados confidenciais, ajustá-lo e partilhá-lo conforme necessário.
Esta página fornece exemplos de consultas SQL que pode usar para saber mais sobre os seus perfis de dados. Também mostra como pode visualizar perfis de dados no Looker Studio.
Para mais informações sobre os perfis de dados, consulte o artigo Perfis de dados.
Antes de começar
Esta página pressupõe que configurou a criação de perfis ao nível da organização, da pasta ou do projeto. Na configuração da análise de deteção, certifique-se de que a ação Guardar cópias dos perfis de dados no BigQuery está ativada. Para mais informações sobre como criar uma configuração de procura de deteção, consulte o artigo Crie uma configuração de procura.
Neste documento, a tabela que contém os perfis de dados exportados é denominada tabela de saída.
Certifique-se de que tem o ID do projeto, o ID do conjunto de dados e o ID da tabela de saída facilmente disponíveis. Precisa que a pessoa em questão realize os procedimentos descritos nesta página.
A vista latest
Quando a proteção de dados confidenciais exporta perfis de dados para a sua tabela de resultados, também cria a latest vista. Esta vista é uma tabela virtual pré-filtrada que inclui apenas os resumos mais recentes dos seus perfis de dados. A vista latest tem o mesmo esquema que a tabela de saída, pelo que pode usar as duas de forma intercambiável nas suas consultas SQL e relatórios do Looker Studio. Os resultados podem diferir porque a tabela de saída contém instantâneos mais antigos dos perfis de dados.
A vista latest é armazenada na mesma localização que a tabela de saída. O nome tem o seguinte formato:
OUTPUT_TABLE_latest_VERSION
Substitua o seguinte:
- OUTPUT_TABLE: o ID da tabela que contém os perfis de dados exportados.
- VERSION: o número da versão da vista.
Por exemplo, se o nome da tabela de saída for table-profile, a vista latest
tem um nome como table-profile_latest_v1.

Quando usar a vista latest em consultas SQL, use o nome completo da vista, que
inclui o ID do projeto, o ID do conjunto de dados, o ID da tabela e o sufixo, por exemplo,
myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Escolha entre a tabela de saída e a vista latest
A vista latest inclui apenas as capturas instantâneas do perfil de dados mais recentes, enquanto a tabela de saída tem todas as capturas instantâneas do perfil de dados, incluindo as capturas instantâneas desatualizadas. Por exemplo, uma consulta na tabela de saída pode devolver vários
perfis de dados de colunas
para a mesma coluna, um para cada vez que a coluna foi analisada.
Quando escolher entre usar a tabela de saída e a latestvista nas suas consultas SQL ou relatórios do Looker Studio, tenha em atenção o seguinte:
A vista
latesté útil se tiver recursos de dados que foram redefinidos e quiser ver apenas os perfis mais recentes, e não as respetivas versões anteriores. Ou seja, quer ver o estado atual dos seus dados com perfil.A tabela de saída é útil se quiser obter uma vista do histórico dos seus dados perfilados. Por exemplo, está a tentar determinar se a sua organização alguma vez armazenou um infoType específico ou quer ver as alterações que um perfil de dados específico sofreu.
Exemplos de consultas SQL
Esta secção fornece exemplos de consultas que pode usar quando analisa perfis de dados. Para executar estas consultas, consulte o artigo Executar consultas interativas.
Nos exemplos seguintes, substitua TABLE_OR_VIEW por uma das seguintes opções:
- O nome da tabela de resultados, que é a tabela que contém os perfis de dados exportados, por exemplo,
myproject.mydataset.table-profile. - O nome da
latestvista da tabela de resultados, por exemplo,myproject.mydataset.table-profile_latest_v1.
Em qualquer dos casos, tem de incluir o ID do projeto e o ID do conjunto de dados.
Para mais informações, consulte a secção
Escolha entre a tabela de saída e a vista latest nesta
página.
Para resolver problemas de erros que encontrar, consulte a secção Mensagens de erro.
Apresente todas as colunas que tenham uma pontuação de texto livre elevada e provas de outras correspondências de infoType
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Para informações sobre como corrigir estas conclusões, consulte o artigo Estratégias recomendadas para mitigar o risco de dados.
Para mais informações acerca das métricas Pontuação de texto livre e Outros tipos de informações, consulte Perfis de dados de colunas.
Indique todas as tabelas que contêm uma coluna de números de cartões de crédito
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER é um infoType incorporado
que representa um número de cartão de crédito.
Para informações sobre como corrigir estas conclusões, consulte o artigo Estratégias recomendadas para mitigar o risco de dados.
Liste os perfis de tabelas que contêm colunas de números de cartões de crédito, números da segurança social dos EUA e nomes de pessoas
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
Esta consulta usa os seguintes infoTypes incorporados:
CREDIT_CARD_NUMBER: representa um número de cartão de créditoPERSON_NAME: representa o nome completo de uma pessoaUS_SOCIAL_SECURITY_NUMBERrepresenta um número da segurança social dos EUA
Para informações sobre como corrigir estas conclusões, consulte o artigo Estratégias recomendadas para mitigar o risco de dados.
Liste os contentores onde a classificação de sensibilidade é SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Para mais informações, consulte o artigo Fiche os perfis de dados de lojas.
Liste todos os caminhos de contentores, clusters e extensões de ficheiros analisados onde a pontuação de sensibilidade é SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Para mais informações, consulte o artigo Fiche os perfis de dados de lojas.
Indique todos os caminhos de contentores, clusters e extensões de ficheiros analisados onde foram detetados números de cartões de crédito
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER é um infoType incorporado
que representa um número de cartão de crédito.
Para mais informações, consulte o artigo Fiche os perfis de dados de lojas.
Liste todos os caminhos de contentores, clusters e extensões de ficheiros analisados onde foi detetado um número de cartão de crédito, um nome de pessoa ou um número da segurança social dos EUA
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
Esta consulta usa os seguintes infoTypes incorporados:
CREDIT_CARD_NUMBER: representa um número de cartão de créditoPERSON_NAME: representa o nome completo de uma pessoaUS_SOCIAL_SECURITY_NUMBERrepresenta um número da segurança social dos EUA
Para mais informações, consulte o artigo Fiche os perfis de dados de lojas.
Trabalhe com perfis de dados no Looker Studio
Para visualizar os seus perfis de dados no Looker Studio, pode usar um relatório predefinido ou criar o seu próprio.
Use um relatório predefinido
A Proteção de dados confidenciais fornece um relatório do Looker Studio pré-criado que realça as informações detalhadas dos perfis de dados. O painel de controlo de proteção de dados confidenciais é um relatório de várias páginas que lhe dá uma vista geral rápida dos seus perfis de dados, incluindo discriminações por risco, por infoType e por localização. Explore os outros separadores para ver as visualizações por região geográfica e risco de postura, ou ver detalhes de métricas específicas. Pode usar este relatório predefinido tal como está ou personalizá-lo conforme necessário. Esta é a versão recomendada do relatório predefinido.
Para ver o relatório predefinido com os seus dados, introduza os valores necessários no seguinte URL. Em seguida, copie o URL resultante para o navegador.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Substitua o seguinte:
- PROJECT_ID: o projeto que contém a tabela de saída.
- DATASET_ID: o conjunto de dados que contém a tabela de saída.
TABLE_OR_VIEW: qualquer uma das seguintes opções:
- O nome da tabela de resultados, que é a tabela que contém os perfis de dados exportados, por exemplo,
myproject.mydataset.table-profile. - O nome da
latestvista da tabela de resultados, por exemplo,myproject.mydataset.table-profile_latest_v1.
Para mais informações, consulte a secção Escolha entre a tabela de saída e a vista
latestnesta página.- O nome da tabela de resultados, que é a tabela que contém os perfis de dados exportados, por exemplo,
O Looker Studio pode demorar alguns minutos a carregar o relatório com os seus dados. Se encontrar erros ou se o relatório não for carregado, consulte a secção Resolva problemas com o relatório predefinido nesta página.
No exemplo seguinte, o painel de controlo mostra que os dados de sensibilidade baixa e alta estão presentes em vários países em todo o mundo.
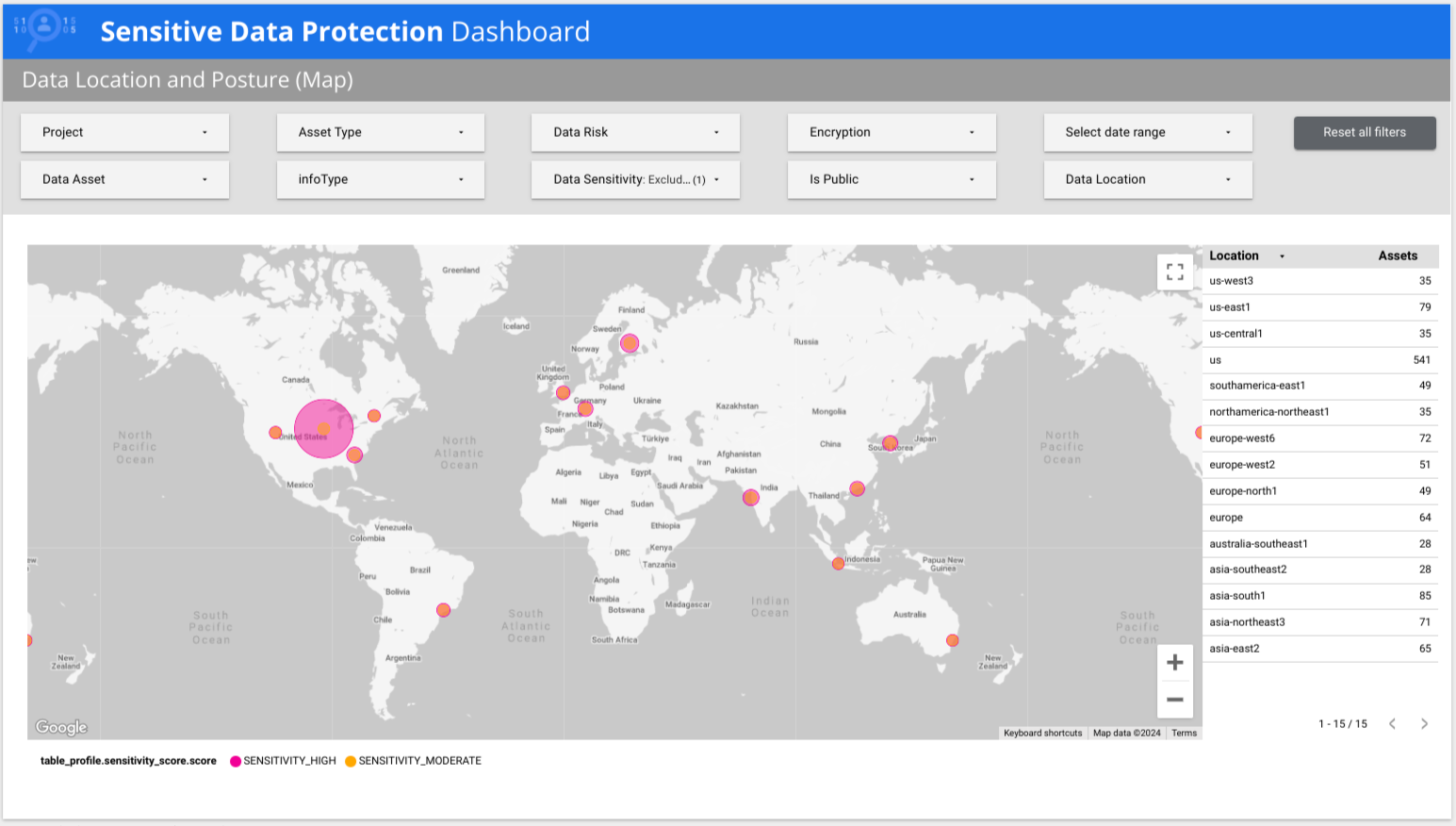
Versão anterior do relatório pré-criado
A primeira versão do relatório predefinido ainda está disponível no seguinte endereço:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Crie um relatório
O Looker Studio permite-lhe criar relatórios interativos. Nesta secção, cria um relatório de tabela simples no Looker Studio com base nos perfis de dados exportados para a tabela de saída no BigQuery.
Certifique-se de que tem o ID do projeto, o ID do conjunto de dados e o ID da tabela de saída ou a vista latest facilmente disponíveis. Precisa delas para realizar este
procedimento.
Este exemplo mostra como criar um relatório que contém uma tabela que apresenta cada infoType comunicado nos seus perfis de dados e a respetiva frequência.
Em geral, incorre em custos de utilização do BigQuery quando acede ao BigQuery através do Looker Studio. Para mais informações, consulte o artigo Visualizar dados do BigQuery com o Looker Studio.
Para criar um relatório, faça o seguinte:
- Abra o Looker Studio e inicie sessão.
- Clique em Relatório em branco.
- No separador Associar a dados, clique no cartão BigQuery.
- Se lhe for pedido, autorize o Looker Studio a aceder aos seus projetos do BigQuery.
Estabeleça ligação aos seus dados do BigQuery:
- Para Projeto, selecione o projeto que contém a tabela de saída. Pode pesquisar o projeto nos separadores Projetos recentes, Os meus projetos e Projetos partilhados.
- Para Conjunto de dados, selecione o conjunto de dados que contém a tabela de saída.
Para Tabela, selecione a tabela de saída ou a
latestvista da tabela de saída.Para mais informações, consulte a secção Escolha entre a tabela de resultados e a vista
latestnesta página.Clique em Adicionar.
Na caixa de diálogo apresentada, clique em Adicionar ao relatório.
Para adicionar uma tabela que mostre cada infoType comunicado e a respetiva frequência (contagem de registos), siga estes passos:
- Clique em Adicionar um gráfico.
- Selecione um estilo de tabela.
Clique na área onde quer posicionar o gráfico.
O gráfico aparece no formato de tabela.
Redimensione a tabela conforme necessário.
Enquanto a tabela estiver selecionada, as respetivas propriedades aparecem no painel Gráfico.
No painel Gráfico, no separador Configuração, remova as dimensões e as métricas pré-selecionadas.
Para Dimensão, adicione
column_profile.column_info_type.info_type.nameoufile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name.Estes exemplos fornecem dados ao nível da coluna e do cluster de ficheiros. Também pode experimentar outras dimensões. Por exemplo, pode usar dimensões ao nível da tabela e ao nível do grupo.
Para Métrica, adicione Contagem de registos.
A tabela resultante tem um aspeto semelhante ao seguinte:
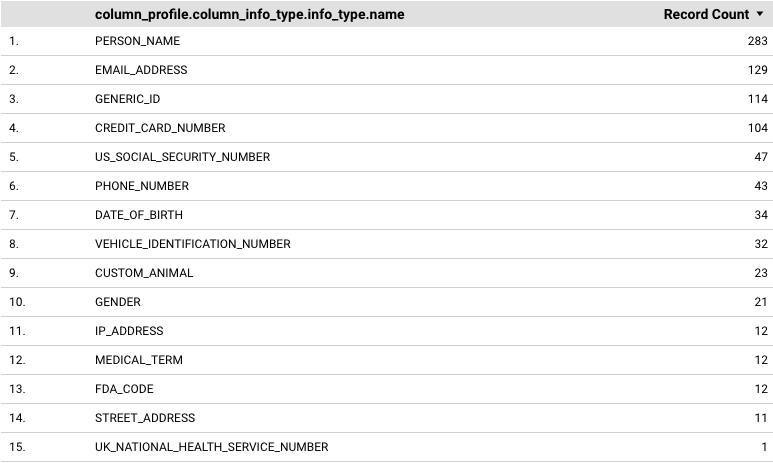
Saiba mais sobre as tabelas no Looker Studio.
Resolva problemas relacionados com erros no relatório predefinido
Se vir erros, controlos em falta ou gráficos em falta ao carregar o relatório predefinido, certifique-se de que o relatório predefinido está a usar os campos mais recentes:
Se o relatório predefinido estiver associado à tabela de saída, confirme se esta tabela está anexada a uma configuração de análise de deteção ativa. Para ver as definições das configurações de análise, consulte o artigo Ver uma configuração de análise.
Se o relatório predefinido estiver associado à visualização de propriedade
latest, confirme se esta visualização de propriedade ainda está presente no BigQuery. Se estiver presente, experimente fazer uma alteração à vista. Em alternativa, crie uma cópia da visualização de propriedade e associe o relatório predefinido a essa cópia. Para mais informações sobre a vistalatest, consulte A vistalatestnesta página.
Se continuar a ver erros depois de experimentar estes passos, contacte o apoio técnico do Google Cloud.
O que se segue?
Saiba mais sobre as ações que pode realizar para corrigir as conclusões do perfil de dados.