En esta guía de inicio rápido, se muestra cómo usar AutoML Natural Language para crear un modelo personalizado de aprendizaje automático. Puedes crear un modelo para clasificar documentos, identificar entidades en documentos o analizar la actitud emocional predominante en un documento.
Para obtener una guía paso a paso sobre esta tarea directamente en Cloud Console, haz clic en Guiarme:
En las siguientes secciones, se explican los mismos pasos que cuando se hace clic en Guiarme.
Configure su proyecto
Antes de poder usar AutoML Natural Language, debes crear un proyecto de Google Cloud y habilitar AutoML Natural Language para ese proyecto.
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Cloud AutoML and Storage.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Cloud AutoML and Storage.
Objetivos del modelo
AutoML Natural Language puede entrenar modelos personalizados para que realicen cuatro tareas distintas, conocidas como objetivos del modelo:
- La clasificación con una sola etiqueta consiste en clasificar los documentos mediante la asignación de una etiqueta.
- La clasificación con varias etiquetas permite asignar varias etiquetas a un documento.
- La extracción de entidades consiste en identificar entidades en los documentos.
- El análisis de opiniones significa analizar las actitudes de los autores de los documentos.
Para esta guía de inicio rápido, puedes elegir qué tipo de modelo crear mediante la selección de uno de los tres conjuntos de datos de muestra alojados en un bucket público de Cloud Storage:
Para crear un modelo de clasificación con una sola etiqueta, usa el conjunto de datos de "momentos felices" derivado del conjunto de datos de código abierto de Kaggle HappyDB. El modelo resultante clasifica los momentos felices en categorías que reflejan las causas de la felicidad.
Los datos están disponibles a través de una licencia CCO: de dominio público de Creative Commons.
Para crear un modelo de extracción de entidades, usa un corpus de resúmenes de investigaciones biomédicas en los que se mencionan cientos de enfermedades y conceptos. El modelo resultante identificará estas entidades médicas en otros documentos.
Este conjunto de datos es de dominio público porque es una "Obra gubernamental de los Estados Unidos" según los términos de la Ley de Derechos de Autor de los Estados Unidos.
Para crear un modelo de análisis de opiniones, usa el conjunto de datos abierto de FigureEight que analiza las menciones en Twitter del medicamento para las alergias Claritin.
Cree un conjunto de datos
Abre la IU de AutoML Natural Language y selecciona Comenzar en el cuadro correspondiente al tipo de modelo que planeas entrenar.
Haz clic en el botón Conjunto de datos nuevo en la barra de título.
Ingresa un nombre para el conjunto de datos y selecciona el objetivo del modelo que coincida con el conjunto de datos de muestra que elegiste.
Deja la Ubicación establecida en Global.
En la sección Importar elementos de texto, elige Seleccionar un archivo CSV en Cloud Storage y, luego, ingresa la ruta de acceso del conjunto de datos que deseas usar en el cuadro de texto.
- Para el conjunto de datos de "momentos felices":
cloud-ml-data/NL-classification/happiness.csv - Para el conjunto de datos de investigación biomédica:
cloud-ml-data/NL-entity/dataset.csv - Para el conjunto de datos con opiniones sobre Claritin:
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(El prefijo
gs://se agrega automáticamente). Como alternativa, puedes hacer clic en Explorar y navegar hasta el archivo CSV.Si eliges el conjunto de datos de opiniones, AutoML Natural Language solicita el valor de opinión máximo. El valor máximo para este conjunto de datos es 4.
- Para el conjunto de datos de "momentos felices":
Haz clic en Create dataset.
Regresarás a la página Datasets (Conjuntos de datos). El conjunto de datos mostrará una animación de proceso en curso mientras se importan tus documentos. Este proceso suele tardar alrededor de 10 minutos por cada 1,000 documentos, aunque el tiempo puede variar.
Una vez que el conjunto de datos se haya creado correctamente, recibirás un mensaje en la dirección de correo electrónico asociada a tu proyecto.
Entrena tu modelo
Luego de que tus datos se importaron con éxito, selecciona el conjunto de datos de la página de la lista de conjuntos de datos para ver los detalles. El nombre del conjunto de datos seleccionado aparece en la barra de título, y se muestran los documentos individuales del conjunto junto con las etiquetas de cada uno. La barra de navegación a la izquierda resume el número de documentos etiquetados y no etiquetados, y te permite filtrar la lista de documentos por etiqueta.
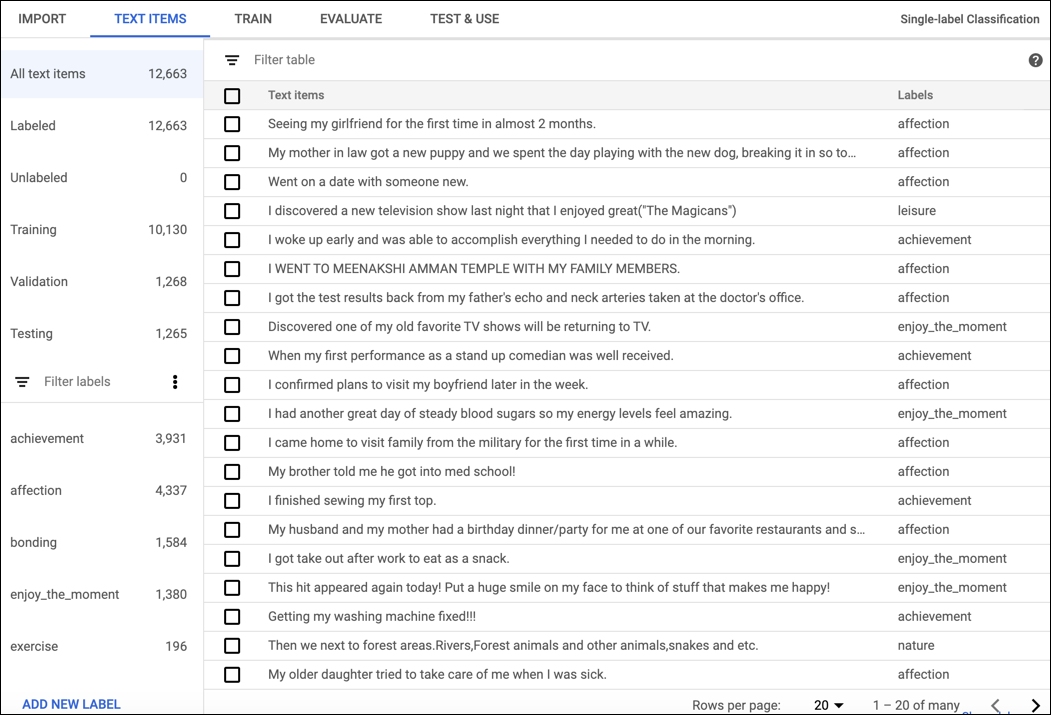
Cuando hayas terminado de revisar el conjunto de datos, haz clic en la pestaña Entrenar justo debajo de la barra de título.
Haz clic en Comenzar entrenamiento.
Escribe un nombre para el modelo nuevo y marca la casilla de verificación Implementa el modelo después de finalizar el entrenamiento.
Haz clic en Comenzar entrenamiento.
El entrenamiento de un modelo puede tomar varias horas en completarse. Una vez que el modelo esté entrenado correctamente, recibirás un mensaje en la dirección de correo electrónico asociada a tu proyecto.
Después del entrenamiento, la parte inferior de la página Train (Entrenar) muestra las métricas de nivel alto para el modelo, como la precisión y recuperación. Para ver más detalles, haz clic en la pestaña Evaluar.
Usa el modelo personalizado
Una vez que el modelo se haya entrenado correctamente, podrás usarlo para analizar otros documentos. Haz clic en la pestaña Prueba y uso que se encuentra debajo de la barra de título. Ingresa el texto en el cuadro Texto de entrada o la URL de un archivo PDF o TIFF en un bucket de Cloud Storage. Luego, haga clic en Predecir. AutoML Natural Language analiza el texto con tu modelo y muestra las anotaciones.
Limpia
A fin de evitar cargos innecesarios en Google Cloud Platform, usa Cloud Console para borrar tu proyecto si no lo necesitas.