Pour entraîner votre modèle personnalisé, vous fournissez des échantillons représentatifs du type de documents à analyser, étiquetés de la manière dont vous souhaitez qu'AutoML Natural Language étiquette des documents semblables. La qualité de vos données d'entraînement influe fortement sur l'efficacité du modèle que vous créez et, par extension, sur la qualité des prédictions renvoyées par ce modèle.
Collecter et étiqueter des documents d'entraînement
La première étape consiste à collecter un ensemble varié de documents d'entraînement représentatifs de la gamme de documents que le modèle personnalisé doit traiter. Les étapes de préparation des documents d'entraînement diffèrent selon que vous entraînez un modèle de classification, d'extraction d'entités ou d'analyse des sentiments.
Extraction d'entités
Pour entraîner un modèle d'extraction d'entités, vous fournissez des échantillons représentatifs du type de contenu à analyser, annotés avec des étiquettes qui identifient les types d'entités qu'AutoML Natural Language doit identifier.
Vous fournissez entre 50 et 100 000 documents qui serviront à entraîner votre modèle personnalisé. Vous pouvez utiliser entre une et 100 étiquettes uniques pour annoter les entités que le modèle doit extraire. Chaque annotation est une plage de texte associée à une étiquette. Les noms des étiquettes peuvent comporter entre 2 et 30 caractères. Ils peuvent être utilisés pour annoter entre un et 10 mots. Nous vous recommandons d'utiliser chaque étiquette au moins 200 fois dans votre ensemble de données d'entraînement.
Si vous annotez un type de document structuré ou semi-structuré, tel que des factures ou des contrats, AutoML Natural Language peut considérer la position d'une annotation comme un facteur permettant d'attribuer une étiquette correcte. Par exemple, un contrat immobilier comporte à la fois une date d'acceptation et une date de clôture. AutoML Natural Language peut apprendre à distinguer les entités en fonction de la position spatiale de l'annotation.
Mettre en forme des documents d'entraînement
Vous importez les données d'entraînement vers AutoML Natural Language sous forme de fichiers JSONL contenant les échantillons de documents. Chaque ligne du fichier correspond à un seul document d'entraînement, spécifié sous l'une des deux formes suivantes :
- Contenu complet du document, d'une longueur comprise entre 10 et 10 000 octets (codage UTF-8)
- L'URI d'un fichier PDF ou TIFF à partir d'un bucket Cloud Storage associé à votre projet
La prise en compte de la position spatiale n'est disponible que pour les documents d'entraînement au format PDF.
Vous pouvez annoter les documents texte de trois manières:
- en annotant les fichiers JSONL directement avant de les importer ;
- en ajoutant des annotations dans l'interface utilisateur d'AutoML Natural Language après l'importation de documents non annotés ;
- En confiant l'étiquetage à des professionnels via le service d'étiquetage de données AI Platform
Vous pouvez combiner les deux premières options en important des fichiers JSONL étiquetés et en les modifiant dans l'interface utilisateur.
Vous ne pouvez annoter des fichiers PDF qu'à l'aide de l'interface utilisateur d'AutoML Natural Language.
Documents JSONL
Pour vous aider à créer des fichiers d'entraînement JSONL, AutoML Natural Language propose un script Python qui convertit les fichiers en texte brut en fichiers JSONL au format approprié. Pour en savoir plus, consultez les commentaires fournis dans le script.
Chaque document du fichier JSONL a l'un des formats suivants :
Chaque document du fichier JSONL doit comporter une ligne. L'exemple ci-dessous inclut des sauts de ligne pour des raisons de lisibilité, mais vous devez les supprimer dans le fichier JSONL. Pour en savoir plus, rendez-vous sur http://jsonlines.org/.
Pour les documents non annotés :
{
"text_snippet":
{"content": string}
}
Pour les documents annotés :
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Chaque élément text_extraction identifie une annotation dans text_snippet.content. Cette annotation indique la position du texte annoté en spécifiant le nombre de caractères entre le début de text_snippet.content et le début (start_offset) et la fin (end_offset) du texte. display_name correspond à l'étiquette de l'entité.
start_offset et end_offset sont des décalages de caractères et non pas des décalages d'octets. Le caractère de end_offset n'est pas inclus dans le segment de texte. Pour en savoir plus, consultez la section TextSegment. Les éléments text_extraction sont facultatifs. Vous pouvez les omettre si vous souhaitez annoter le document à l'aide de l'interface utilisateur d'AutoML Natural Language. Chaque annotation peut couvrir jusqu'à 10 jetons (mots). Ces jetons ne peuvent pas se chevaucher. L'élément start_offset d'une annotation ne peut pas être compris entre les éléments start_offset et end_offset d'une même annotation dans le même document.
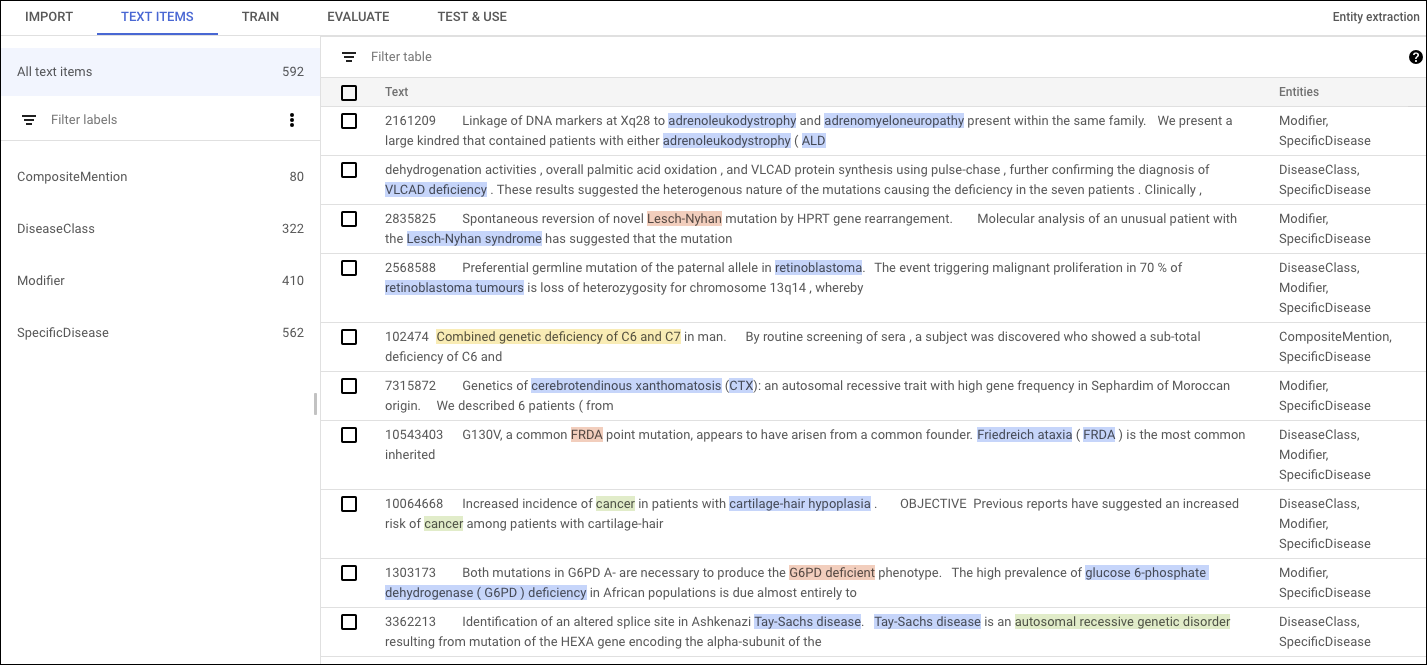
Cet exemple de document d'entraînement identifie les maladies spécifiques mentionnées dans un extrait du corps NCBI.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
Un fichier JSONL peut contenir plusieurs documents d'entraînement structurés de cette façon, un sur chaque ligne du fichier.
Documents PDF ou TIFF
Pour importer un fichier PDF ou TIFF comme document, encapsulez son chemin d'accès à l'intérieur d'un élément JSONL document :
Chaque document du fichier JSONL doit comporter une ligne. L'exemple ci-dessous inclut des sauts de ligne pour des raisons de lisibilité, mais vous devez les supprimer dans le fichier JSONL. Pour en savoir plus, rendez-vous sur http://jsonlines.org/.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
La valeur de l'élément input_uris est le chemin d'accès à un fichier PDF ou TIFF dans un bucket Cloud Storage associé à votre projet. La taille maximale du fichier PDF ou TIFF est de 2 Mo.
Importer des documents d'entraînement
Vous importez des données d'entraînement vers AutoML Natural Language sous forme de fichier CSV qui répertorie les documents et indique éventuellement les étiquettes des catégories auxquelles ils appartiennent ou les valeurs de sentiment correspondantes. AutoML Natural Language crée un ensemble de données à partir des documents répertoriés.
Données d'entraînement et données d'évaluation
Pour entraîner un modèle, AutoML Natural Language répartit vos documents d'entraînement en trois ensembles : un ensemble d'entraînement, un ensemble de validation et un ensemble de test.
AutoML Natural Language utilise l'ensemble d'entraînement pour créer le modèle. Le modèle essaie plusieurs algorithmes et paramètres pour rechercher des schémas dans les données d'entraînement. Lorsque le modèle identifie des schémas, il utilise l'ensemble de validation pour tester les algorithmes et les schémas. AutoML Natural Language sélectionne alors les algorithmes et les schémas les plus performants parmi ceux identifiés au cours de l'entraînement.
Après avoir identifié les algorithmes et les schémas les plus performants, AutoML Natural Language les applique à l'ensemble de test afin de déterminer le taux d'erreur, la qualité et la précision.
Par défaut, AutoML Natural Language répartit vos données d'entraînement de manière aléatoire dans les trois ensembles comme suit :
- 80 % des documents sont utilisés pour l'entraînement.
- 10 % des documents sont utilisés pour la validation (réglage des hyper-paramètres et/ou pour décider quand arrêter l'entraînement).
- 10 % des documents sont réservés aux tests (et ne sont pas utilisés pendant l'entraînement).
Si vous souhaitez spécifier l'ensemble auquel chaque document constituant vos données d'entraînement doit appartenir, vous pouvez attribuer explicitement des documents aux ensembles dans le fichier CSV, comme décrit dans la section suivante.
Créer un fichier CSV d'importation
Une fois que vous avez collecté tous vos documents d'entraînement, vous créez un fichier CSV où ils sont tous répertoriés. Ce fichier CSV peut porter n'importe quel nom. Il doit être codé en UTF-8 et doit se terminer par une extension .csv. Il doit être stocké dans le bucket Cloud Storage associé à votre projet.
Le fichier CSV comporte une ligne par document d'entraînement, ainsi que les colonnes suivantes dans chaque ligne :
L'ensemble auquel assigner le contenu de cette ligne. Cette colonne est facultative et peut contenir l'une des valeurs suivantes :
TRAIN: utilisez les données de type document pour entraîner le modèle.VALIDATION: utilisez les données de type document pour valider les résultats renvoyés par le modèle pendant l'entraînement.TEST: utilisez les données de type document pour vérifier les résultats du modèle après l'entraînement.
Si vous incluez des valeurs dans cette colonne afin de spécifier les ensembles, nous vous recommandons d'identifier au moins 5 % de vos données pour chaque catégorie. Si vous utilisez moins de 5 % de vos données pour l'apprentissage, la validation ou l'évaluation, les résultats obtenus pourraient être inattendus, et les modèles inefficaces.
Si vous ne spécifiez pas de valeur dans cette colonne, commencez chaque ligne par une virgule afin d'indiquer la première colonne vide. AutoML Natural Language répartit automatiquement vos documents en trois ensembles, utilisant environ 80 % de vos données pour l'entraînement, 10 % pour la validation et 10 % pour les tests.
Les contenus à classifier. Cette colonne contient l'URI Cloud Storage pour le document. Les URI Cloud Storage sont sensibles à la casse.
Pour la classification et l'analyse des sentiments, le document peut être un fichier texte, PDF, TIFF ou ZIP ; pour l'extraction d'entités, il s'agit d'un fichier JSONL.
Pour la classification et l'analyse des sentiments, la valeur de cette colonne peut apparaître en toutes lettres plutôt que sous forme d'URI Cloud Storage.
Pour les ensembles de données de classification, vous pouvez éventuellement inclure une liste d'étiquettes séparées par une virgule, indiquant la façon dont le document est classé. Les étiquettes doivent commencer par une lettre et ne contenir que des lettres, des chiffres et des traits de soulignement. Vous pouvez inclure jusqu'à 20 étiquettes pour chaque document.
Pour les ensembles de données d'analyse des sentiments, vous pouvez éventuellement inclure un entier indiquant la valeur du sentiment correspondant au contenu. La valeur du sentiment varie de 0 (fortement négatif) à une valeur maximale de 10 (fortement positif).
Par exemple, le fichier CSV d'un ensemble de données de classification multi-étiquettes peut comporter les éléments suivants :
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Erreurs courantes concernant les fichiers .csv
- Utilisation de caractères Unicode dans les étiquettes. Par exemple, les caractères japonais ne sont pas acceptés.
- Utilisation d'espaces et de caractères non alphanumériques dans les étiquettes.
- Lignes vides.
- Colonnes vides (lignes avec deux virgules successives).
- Guillemets manquants autour d'un texte intégré comportant des virgules
- Utilisation incorrecte des majuscules dans les chemins d'accès à Google Cloud Storage.
- Mauvaise configuration du contrôle des accès à vos documents. Votre compte de service doit avoir un accès en lecture ou plus étendu, ou les fichiers doivent être lisibles publiquement.
- Références à des fichiers non textuels, tels que des fichiers JPEG. De même, les fichiers qui ne sont pas des fichiers texte mais qui ont été renommés avec une extension de type texte renverront une erreur.
- L'URI d'un document pointe vers un bucket différent de celui du projet actuel. Seuls les fichiers présents dans le bucket du projet sont accessibles.
- Fichiers non CSV
Créer un fichier ZIP d'importation
Pour les ensembles de données de classification, vous pouvez importer des documents d'entraînement à l'aide d'un fichier ZIP. Dans le fichier ZIP, vous créez un dossier pour chaque étiquette ou valeur de sentiment, puis vous enregistrez chaque document dans le dossier correspondant à l'étiquette ou à la valeur à appliquer à ce document. Par exemple, le fichier ZIP d'un modèle qui classe les correspondances professionnelles peut présenter la structure suivante :
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language applique les noms de dossier aux documents du dossier sous forme d'étiquettes. Dans le cas d'un ensemble de données d'analyse des sentiments, les noms de dossiers sont les valeurs de sentiment :
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
Étapes suivantes
- Importez vos données pour créer votre ensemble de données.