Untuk melatih model kustom, Anda perlu memberikan sampel representatif dari jenis dokumen yang ingin dianalisis, yang diberi label dengan cara yang Anda inginkan untuk melabeli dokumen serupa oleh AutoML Natural Language. Kualitas data pelatihan Anda sangat memengaruhi efektivitas model yang Anda buat, begitu juga dengan kualitas prediksi yang ditampilkan dari model tersebut.
Mengumpulkan dan memberi label pada dokumen pelatihan
Langkah pertama adalah mengumpulkan beragam dokumen pelatihan yang mencerminkan rentang dokumen yang ingin ditangani oleh model kustom. Langkah persiapan untuk dokumen pelatihan berbeda-beda, bergantung pada apakah Anda melatih model untuk klasifikasi, ekstraksi entity, atau analisis sentimen.
Ekstraksi entity
Untuk melatih model ekstraksi entity, Anda memberikan sampel representatif dari jenis konten yang ingin dianalisis, yang dianotasi dengan label yang mengidentifikasi jenis entity yang ingin diidentifikasi oleh AutoML Natural Language.
Anda menyediakan antara 50 hingga 100.000 dokumen untuk digunakan untuk melatih model kustom Anda. Anda harus menggunakan antara satu hingga 100 label unik untuk menganotasi entity yang ingin diekstrak oleh model untuk dipelajari. Setiap anotasi merupakan rentang teks dan label terkait. Nama label dapat berisi antara 2 hingga 30 karakter, dan dapat digunakan untuk memberi anotasi antara satu hingga 10 kata. Sebaiknya gunakan setiap label minimal 200 kali dalam set data pelatihan Anda.
Jika Anda menganotasi jenis dokumen terstruktur atau semi-terstruktur, seperti invoice atau kontrak, AutoML Natural Language dapat mempertimbangkan posisi anotasi pada halaman sebagai faktor yang berkontribusi pada label yang tepat. Misalnya, kontrak real estate memiliki tanggal persetujuan dan tanggal penutupan, dan AutoML Natural Language dapat belajar untuk membedakan entitas berdasarkan posisi spasial anotasi.
Memformat dokumen pelatihan
Anda mengupload data pelatihan ke AutoML Natural Language sebagai file JSONL yang berisi dokumen contoh. Setiap baris dalam file adalah satu dokumen pelatihan, yang ditentukan dalam salah satu dari dua formulir:
- Konten lengkap dokumen, dengan panjang antara 10 dan 10.000 byte (dienkode UTF-8)
- URI file PDF atau TIFF dari bucket Cloud Storage yang terkait dengan project Anda
Pertimbangan posisi spasial hanya tersedia untuk dokumen pelatihan dalam format PDF.
Anda dapat menganotasi dokumen teks dengan tiga cara:
- Anotasikan file JSONL secara langsung sebelum menguploadnya
- Tambahkan anotasi di UI AutoML Natural Language setelah mengupload dokumen yang tidak diberi anotasi
- Meminta pelabelan dari pemberi label manusia menggunakan AI Platform Data Labeling Service
Anda dapat menggabungkan dua opsi pertama dengan mengupload file JSONL berlabel dan memodifikasinya di UI.
Anda hanya dapat menganotasi file PDF menggunakan UI AutoML Natural Language.
Dokumen JSONL
Untuk membantu Anda membuat file pelatihan JSONL, AutoML Natural Language menawarkan skrip Python yang mengonversi file teks biasa menjadi file JSONL yang diformat dengan tepat. Lihat komentar dalam skrip untuk mengetahui detailnya.
Setiap dokumen dalam file JSONL memiliki salah satu format berikut:
Setiap dokumen harus berupa satu baris di file JSONL. Contoh di bawah ini menyertakan jeda baris agar mudah dibaca; Anda harus menghapusnya dalam file JSONL. Untuk informasi selengkapnya, lihat http://jsonlines.org/.
Untuk dokumen yang tidak diberi anotasi:
{
"text_snippet":
{"content": string}
}
Untuk dokumen yang dianotasi:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Setiap elemen text_extraction mengidentifikasi anotasi dalam
text_snippet.content. Ini menunjukkan posisi teks teranotasi dengan menentukan jumlah karakter dari awal text_snippet.content ke awal (start_offset) dan akhir (end_offset) teks; display_name adalah label untuk entity.
start_offset dan end_offset` adalah offset karakter, bukan offset byte. Karakter pada end_offset
tidak disertakan dalam segmen teks. Lihat TextSegment
untuk detail selengkapnya. Elemen text_extraction bersifat opsional; Anda dapat menghilangkannya jika berencana untuk menganotasi dokumen menggunakan UI AutoML Natural Language. Setiap anotasi dapat mencakup hingga sepuluh token (kata). Anotasi tidak boleh tumpang-tindih; start_offset anotasi tidak boleh berada di antara start_offset dan end_offset dari anotasi dalam dokumen yang sama.
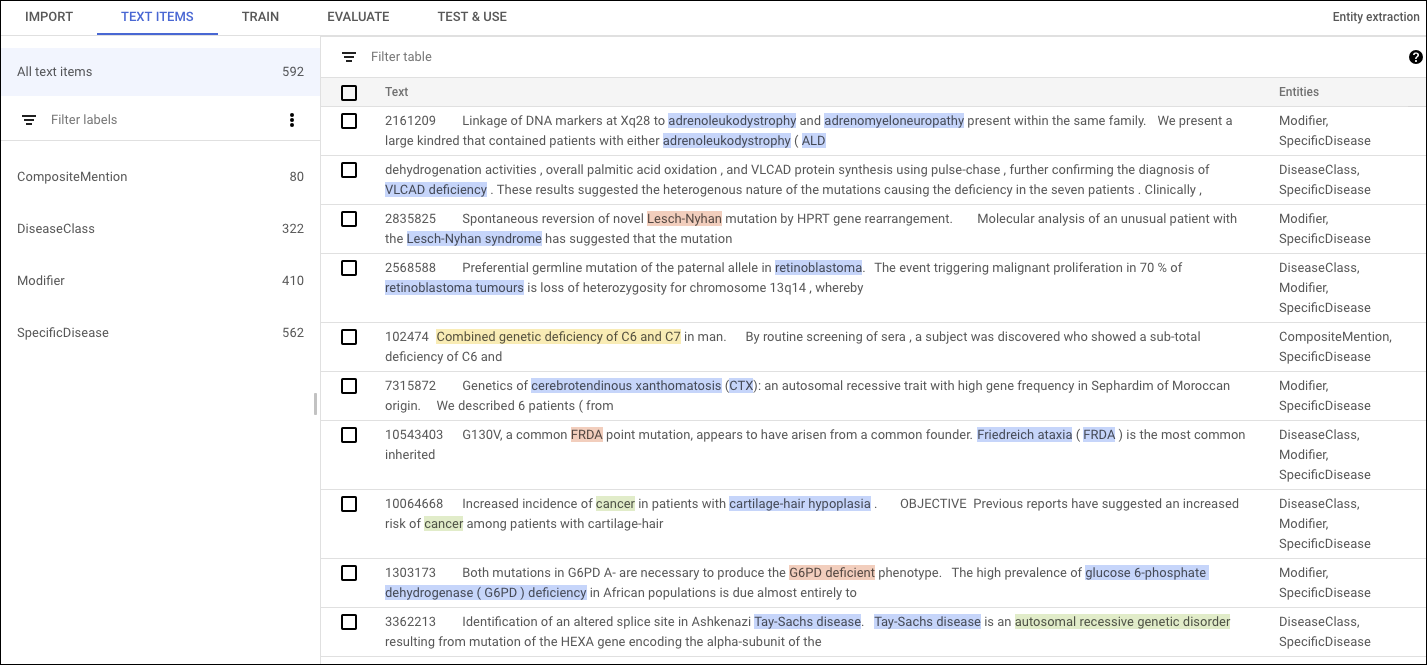
Misalnya, contoh dokumen pelatihan ini mengidentifikasi penyakit tertentu yang disebutkan secara abstrak dari korpus NCBI.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
File JSONL dapat berisi beberapa dokumen pelatihan dengan struktur ini, satu di setiap baris file.
Dokumen PDF atau TIFF
Untuk mengupload file PDF atau TIFF sebagai dokumen, gabungkan jalur file di dalam elemen document JSONL:
Setiap dokumen harus berupa satu baris di file JSONL. Contoh di bawah ini menyertakan jeda baris agar mudah dibaca; Anda harus menghapusnya dalam file JSONL. Untuk informasi selengkapnya, lihat http://jsonlines.org/.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
Nilai elemen input_uris adalah jalur ke file PDF atau TIFF di bucket Cloud Storage yang terkait dengan project Anda. Ukuran maksimum file PDF atau TIFF adalah 2 MB.
Mengimpor dokumen pelatihan
Anda mengimpor data pelatihan ke AutoML Natural Language menggunakan file CSV yang mencantumkan dokumen dan secara opsional menyertakan label kategori atau nilai sentimennya. AutoML Natural Language membuat set data dari dokumen yang tercantum.
Data pelatihan vs. evaluasi
AutoML Natural Language membagi dokumen pelatihan Anda ke dalam tiga set untuk melatih model: set pelatihan, set validasi, dan set pengujian.
AutoML Natural Language menggunakan set pelatihan untuk membangun model. Model ini mencoba beberapa algoritma dan parameter saat mencari pola dalam data pelatihan. Saat mengidentifikasi pola, model akan menggunakan set validasi untuk menguji algoritma dan pola. AutoML Natural Language memilih algoritme dan pola berperforma terbaik dari yang diidentifikasi selama tahap pelatihan.
Setelah mengidentifikasi algoritma dan pola berperforma terbaik, AutoML Natural Language menerapkannya ke set pengujian untuk menguji tingkat, kualitas, dan akurasi error.
Secara default, AutoML Natural Language membagi data pelatihan Anda secara acak ke dalam tiga set:
- 80% dokumen digunakan untuk pelatihan
- 10% dokumen digunakan untuk validasi (tuning hyper-parameter dan/atau untuk memutuskan kapan harus menghentikan pelatihan)
- 10% dokumen dicadangkan untuk pengujian (tidak digunakan selama pelatihan)
Jika ingin menentukan kumpulan yang harus dimiliki setiap dokumen dalam data pelatihan, Anda dapat secara eksplisit menetapkan dokumen ke kumpulan dalam file CSV seperti yang dijelaskan di bagian berikutnya.
Membuat file CSV impor
Setelah mengumpulkan semua dokumen pelatihan, buat file CSV yang mencantumkan semuanya. File CSV dapat memiliki nama file apa pun, harus berenkode UTF-8, dan harus diakhiri dengan ekstensi .csv. File ini harus disimpan di bucket Cloud Storage yang terkait dengan project Anda.
File CSV memiliki satu baris untuk setiap dokumen pelatihan, dengan kolom-kolom berikut di setiap baris:
Kumpulan tempat untuk menetapkan konten dalam baris ini. Kolom ini bersifat opsional dan dapat berupa salah satu dari nilai berikut:
TRAIN- Gunakan document untuk melatih model.VALIDATION- Gunakan document untuk memvalidasi hasil yang ditampilkan model selama pelatihan.TEST- Gunakan document untuk memverifikasi hasil model setelah model dilatih.
Jika Anda menyertakan nilai dalam kolom ini untuk menentukan set, sebaiknya identifikasi setidaknya 5% data untuk setiap kategori. Menggunakan kurang dari 5% data Anda untuk pelatihan, validasi, atau pengujian dapat memberikan hasil yang tidak terduga dan model yang tidak efektif.
Jika Anda tidak menyertakan nilai dalam kolom ini, mulailah setiap baris dengan koma untuk menunjukkan kolom pertama yang kosong. AutoML Natural Language secara otomatis membagi dokumen Anda menjadi tiga set, menggunakan sekitar 80% data Anda untuk pelatihan, 10% untuk validasi, dan 10% untuk pengujian (hingga 10.000 pasangan untuk validasi dan pengujian).
Konten yang akan dikategorikan. Kolom ini berisi URI Cloud Storage untuk dokumen. Cloud Storage URI peka huruf besar/kecil.
Untuk klasifikasi dan analisis sentimen, dokumen dapat berupa file teks, file PDF, file TIFF, atau file ZIP. Untuk ekstraksi entity, dokumen ini dapat berupa file JSONL.
Untuk klasifikasi dan analisis sentimen, nilai dalam kolom ini dapat dikutip dengan teks in-line, bukan URI Cloud Storage.
Untuk set data klasifikasi, Anda dapat memilih untuk menyertakan daftar label yang dipisahkan koma yang mengidentifikasi cara dokumen dikategorikan. Label harus dimulai dengan huruf dan hanya berisi huruf, angka, serta garis bawah. Anda dapat menyertakan hingga 20 label untuk setiap dokumen.
Untuk set data analisis sentimen, Anda juga dapat menyertakan bilangan bulat yang menunjukkan nilai sentimen untuk konten. Nilai sentimen berkisar dari 0 (sangat negatif) hingga nilai maksimum 10 (sangat positif).
Misalnya, file CSV untuk set data klasifikasi multi-label mungkin memiliki:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Error umum pada file .csv
- Menggunakan karakter Unicode dalam label. Misalnya, karakter Jepang tidak didukung.
- Penggunaan spasi dan karakter non-alfanumerik dalam label.
- Baris kosong
- Kolom kosong (baris dengan dua koma berturut-turut).
- Tidak ada tanda kutip di sekitar teks tersemat yang menyertakan koma.
- Kapitalisasi jalur Cloud Storage salah.
- Kontrol akses salah dikonfigurasi untuk dokumen Anda. Akun layanan Anda harus memiliki akses baca atau akses yang lebih besar, atau file harus dapat dibaca secara publik.
- Rujukan ke file non-teks, seperti file JPEG. Demikian juga, file yang bukan file teks tetapi telah diganti namanya dengan ekstensi teks akan menyebabkan error.
- URI dokumen menunjuk ke bucket yang berbeda dengan project saat ini. Hanya file dalam bucket project yang dapat diakses.
- File berformat non-CSV.
Membuat file ZIP impor
Untuk set data klasifikasi, Anda dapat mengimpor dokumen pelatihan menggunakan file ZIP. Dalam file ZIP tersebut, buat satu folder untuk setiap label atau nilai sentimen, lalu simpan setiap dokumen di dalam folder yang sesuai dengan label atau nilai untuk diterapkan ke dokumen tersebut. Misalnya, file ZIP untuk model yang mengklasifikasikan korespondensi bisnis mungkin memiliki struktur ini:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language menerapkan nama folder sebagai label ke dokumen dalam folder tersebut. Untuk {i>dataset<i} analisis sentimen, nama foldernya adalah nilai-nilai sentimen:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
Langkah selanjutnya
- Impor data Anda untuk membuat set data.