Wenn Sie Ihr benutzerdefiniertes Modell trainieren möchten, stellen Sie repräsentative Stichproben für den zu analysierenden Dokumenttyp bereit, die so mit Labeln versehen sind, wie AutoML Natural Language ähnliche Dokumente mit Labeln versehen soll. Die Qualität der Trainingsdaten beeinflusst stark die Effizienz des von Ihnen erstellten Modells und folglich die Qualität der damit generierten Vorhersagen.
Trainingsdokumente erfassen und mit Labeln versehen
Der erste Schritt besteht darin, eine Reihe verschiedener Trainingsdokumente zu erfassen, die die Bandbreite an Dokumenten widerspiegeln, die das benutzerdefinierte Modell verarbeiten soll. Die vorbereitenden Schritte für Trainingsdokumente unterscheiden sich je nachdem, ob Sie ein Modell für die Klassifizierung, die Entitätsextraktion oder die Sentimentanalyse trainieren.
Entitätsextraktion
Zum Trainieren eines Entitätsextraktionsmodells stellen Sie repräsentative Stichproben des zu analysierenden Inhaltstyps bereit. Diese sind mit Labels versehen, die die Entitätstypen angeben, die AutoML Natural Language identifizieren soll.
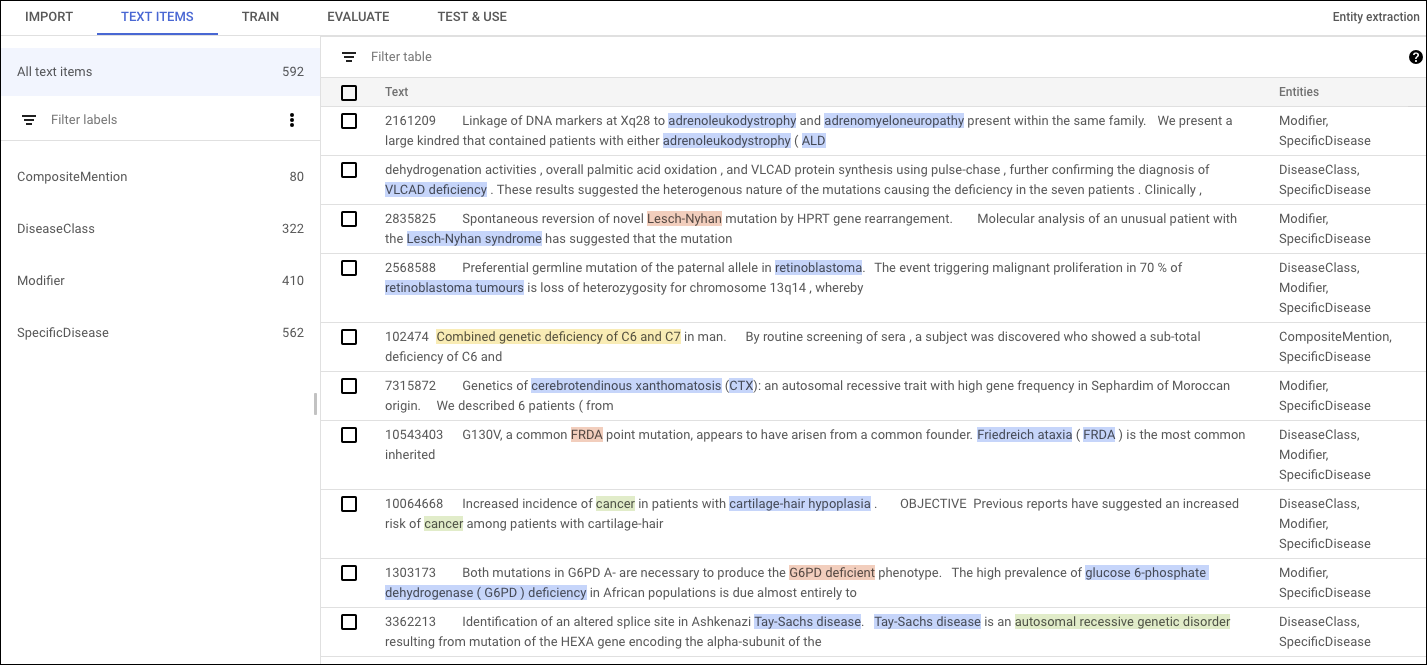
Sie stellen zwischen 50 und 100.000 Dokumente bereit, die Sie für das Training des benutzerdefinierten Modells verwenden. Sie verwenden bis zu 100 eindeutige Labels, um die Entitäten zu annotieren, für die das Modell lernen soll, wie es diese extrahiert. Jede Annotation besteht aus einem Textbereich und einem zugehörigen Label. Labelnamen können zwischen 2 und 30 Zeichen lang sein und dazu verwendet werden, zwischen 1 und 10 Wörtern zu annotieren. Wir empfehlen, jedes Label mindestens 200 Mal in Ihrem Trainings-Dataset zu verwenden.
Wenn Sie einen strukturierten oder halbstrukturierten Dokumenttyp annotieren, z. B. Rechnungen oder Verträge, kann AutoML Natural Language die Position einer Annotation auf der Seite als Faktor berücksichtigen, der zum richtigen Label des Dokuments beiträgt. Wenn beispielsweise ein Immobilienvertrag sowohl einen Abnahmetermin als auch ein Vollzugsdatum aufweist, kann AutoML Natural Language anhand der räumlichen Position der Annotation lernen, zwischen den Entitäten zu unterscheiden.
Trainingsdokumente formatieren
Sie laden die Trainingsdaten als JSONL, die die Stichprobendokumente enthalten, in AutoML Natural Language hoch. Jede Zeile in der Datei entspricht einem einzelnen Trainingsdokument, das auf eine der beiden folgenden Arten angegeben wird:
- Der vollständige Inhalt des Dokuments, zwischen 10 und 10.000 Byte lang (UTF-8-codiert)
- Der URI einer PDF- oder TIFF-Datei aus einem Cloud Storage-Bucket, der Ihrem Projekt zugeordnet ist
Die Berücksichtigung der räumlichen Position ist nur für Trainingsdokumente im PDF-Format verfügbar.
Sie können die Textdokumente auf drei Arten annotieren:
- Direktes Annotieren der JSONL-Dateien vor deren Upload
- Hinzufügen von Annotationen über die AutoML Natural Language-Benutzeroberfläche nach dem Upload von Dokumenten ohne Annotationen
- Anfordern von Labeling durch Menschen über den AI Platform Data Labeling Service
Sie können die ersten beiden Optionen kombinieren, indem Sie mit Labels versehene JSONL-Dateien hochladen und sie in der Benutzeroberfläche ändern.
Sie können PDF-Dateien nur mit der AutoML Natural Language UI mit Anmerkungen versehen.
JSONL-Dokumente
Als Unterstützung beim Erstellen von JSONL-Trainingsdateien bietet AutoML Natural Language ein Python-Skript, das reine Textdateien in entsprechend formatierte JSONL-Dateien umwandelt. Weitere Informationen finden Sie in den Kommentaren im Skript.
Jedes Dokument in der JSONL-Datei hat eines der folgenden Formate:
Jedes Dokument muss einer Zeile in der JSONL-Datei entsprechen. Das folgende Beispiel enthält zur besseren Lesbarkeit Zeilenumbrüche. Sie müssen diese in der JSONL-Datei entfernen. Weitere Informationen finden Sie unter http://jsonlines.org/.
Für Dokumente ohne Annotationen:
{
"text_snippet":
{"content": string}
}
Für Dokumente mit Annotationen:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Jedes text_extraction-Element identifiziert eine Annotation in text_snippet.content. Es gibt die Position des annotierten Textes an, indem die Anzahl der Zeichen ab dem Anfang von text_snippet.content bis zum Beginn (start_offset) und Ende (end_offset) des Textes angegeben wird. display_name ist das Label für die Entität.
Sowohl start_offset als auch end_offset sind Zeichen-Offsets und keine Byte-Offsets. Das Zeichen am end_offset ist nicht in dem Textsegment enthalten. Weitere Informationen finden Sie unter TextSegment. Die text_extraction-Elemente sind optional. Sie können diese weglassen, wenn Sie beabsichtigen, das Dokument mit der AutoML Natural Language UI zu annotieren. Jede Annotation kann sich auf bis zu zehn Tokens (Wörter) beziehen. Sie dürfen sich nicht überschneiden. Der start_offset einer Annotation kann sich nicht zwischen dem start_offset und end_offset einer anderen Annotation im selben Dokument befinden.
Dieses beispielhafte Trainingsdokument identifiziert beispielsweise die spezifischen Krankheiten, die in einem Auszug aus dem NCBI-Korpus erwähnt werden.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
Eine JSONL-Datei kann mehrere Trainingsdokumente mit dieser Struktur enthalten – eines pro Zeile der Datei.
PDF- oder TIFF-Dokumente
Umschließen Sie den Dateipfad mit einem JSONL-document-Element, um eine PDF- oder TIFF-Datei als Dokument hochzuladen:
Jedes Dokument muss einer Zeile in der JSONL-Datei entsprechen. Das folgende Beispiel enthält zur besseren Lesbarkeit Zeilenumbrüche. Sie müssen diese in der JSONL-Datei entfernen. Weitere Informationen finden Sie unter http://jsonlines.org/.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
Der Wert des Elements input_uris ist der Pfad zu einer PDF- oder TIFF-Datei in einem Cloud Storage-Bucket, der Ihrem Projekt zugeordnet ist. Die maximale Größe der PDF- oder TIFF-Datei beträgt 2 MB.
Trainingsdokumente importieren
Sie importieren die Trainingsdaten mithilfe einer CSV-Datei in AutoML Natural Language, die die Dokumente auflistet und optional deren Kategorielabels und Sentimentwerte enthält. AutoML Natural Language erstellt dann aus den aufgeführten Dokumenten ein Dataset.
Trainingsdaten im Vergleich zu Bewertungsdaten
AutoML Natural Language unterteilt die Trainingsdokumente in drei Datasets, um das Modell zu trainieren: ein Trainings-Dataset, ein Validierungs-Dataset und ein Test-Dataset
AutoML Natural Language verwendet das Trainings-Dataset, um das Modell zu erstellen. Bei der Suche nach Mustern in den Trainingsdaten probiert das Modell mehrere Algorithmen und Parameter aus. Wenn das Modell Muster erkennt, verwendet es das Validierungs-Dataset, um die Algorithmen und Muster zu testen. AutoML Natural Language wählt aus den während der Trainingsphase identifizierten Algorithmen und Mustern die mit der besten Leistung aus.
Nachdem die Algorithmen und Muster mit der besten Leistung ermittelt wurden, wendet AutoML Natural Language sie auf das Test-Dataset an, um hinsichtlich Fehlerrate, Qualität und Genauigkeit zu testen.
AutoML Natural Language teilt die Trainingsdaten standardmäßig auf folgende Weise nach dem Zufallsprinzip auf die drei Datasets auf:
- 80 % der Dokumente werden für das Training verwendet.
- 10 % der Dokumente werden für die Validierung verwendet (Hyperparameter-Abstimmung und/oder die Entscheidung, wann das Training beendet werden soll).
- 10 % der Dokumente sind zum Testen reserviert und werden während des Trainings nicht verwendet.
Wenn Sie angeben möchten, zu welchem Dataset die einzelnen Dokumente der Trainingsdaten gehören sollen, können Sie in der CSV-Datei Dokumente explizit einem der Datasets zuweisen, wie im nächsten Abschnitt beschrieben.
Import-CSV-Datei erstellen
Sobald Sie Ihre Trainingsdokumente erfasst haben, erstellen Sie eine CSV-Datei, die diese auflistet. Die CSV-Datei kann einen beliebigen Dateinamen haben, muss UTF-8-codiert sein und muss auf die .csv-Erweiterung enden. Sie muss im Cloud Storage-Bucket gespeichert sein, der Ihrem Projekt zugeordnet ist.
Die CSV-Datei enthält für jedes Trainingsdokument eine Zeile mit folgenden Spalten:
Das Set, dem der Inhalt in der jeweiligen Zeile zugewiesen werden soll. Diese Spalte ist optional und kann einen der folgenden Werte enthalten:
TRAIN: document wird zum Trainieren des Modells verwendet.VALIDATION: document wird zum Validieren der Ergebnisse verwendet, die das Modell während des Trainings zurückgibt.TEST: document wird nach dem Trainieren des Modells zum Prüfen der Ergebnisse des Modells verwendet.
Wenn Sie in diese Spalte Werte aufnehmen, um die Datasets anzugeben, empfehlen wir, dass Sie für jede Kategorie mindestens 5 % Ihrer Daten angeben. Die Verwendung von weniger als 5 % Ihrer Daten für Training, Validierung oder Tests kann zu unerwarteten Ergebnissen und ineffektiven Modellen führen.
Wenn Sie keine Werte in diese Spalte aufnehmen möchten, beginnen Sie jede Zeile mit einem Komma, um die leere erste Spalte zu kennzeichnen. AutoML Natural Language teilt Ihre Dokumente automatisch auf die drei Datasets auf, wobei ungefähr 80 % der Daten zum Trainieren, 10 % zum Validieren und 10 % zum Testen verwendet werden (bis zu 10.000 Paare zum Validieren und Testen).
Den zu kategorisierenden Inhalt. Diese Spalte enthält den Cloud Storage-URI für das Dokument. Bei Cloud Storage-URIs wird zwischen Groß- und Kleinschreibung unterschieden.
Zur Klassifizierung und Sentimentanalyse kann das Dokument eine Textdatei, eine PDF-Datei, eine TIFF-Datei oder eine ZIP-Datei sein. Für die Entitätsextraktion muss es eine JSONL-Datei sein.
Bei der Klassifizierung und Sentimentanalyse kann der Wert in dieser Spalte statt eines Cloud Storage-URIs auch zitierter Inline-Text sein.
Für Klassifizierungs-Datasets können Sie optional Folgendes einschließen: eine durch Kommas getrennte Liste von Labels, die angeben, wie das Dokument zu kategorisieren ist. Labels müssen mit einem Buchstaben beginnen und dürfen nur Buchstaben, Zahlen und Unterstriche enthalten. Sie können für jedes Dokument bis zu 20 Labels hinzufügen.
Für Sentimentanalyse-Datasets können Sie optional Folgendes einschließen: eine Ganzzahl, die den Sentimentwert für den Inhalt angibt. Der Sentimentwert reicht von 0 (sehr negativ) bis zu einem maximalen Wert von 10 (sehr positiv).
Die CSV-Datei für ein Klassifizierungs-Dataset mit mehreren Labels kann beispielsweise Folgendes enthalten:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Häufige .csv-Fehler
- Verwendung von Unicode-Zeichen für Labels. Japanische Schriftzeichen werden z. B. nicht unterstützt.
- Verwendung von Leerzeichen und nicht alphanumerischen Zeichen für Labels.
- Leere Zeilen.
- Leere Spalten (Zeilen mit zwei aufeinanderfolgenden Kommas).
- Fehlende Anführungszeichen für eingebetteten Text, der Kommas enthält.
- Falsche Großschreibung von Cloud Storage-Pfaden.
- Zugriffssteuerung für Ihre Dokumente falsch konfiguriert. Ihr Dienstkonto muss mindestens Leseberechtigungen haben oder Dateien müssen öffentlich lesbar sein.
- Verweise auf Nicht-Textdateien, z. B. JPEG-Dateien. Ebenso führen Dateien, die keine Textdateien sind, aber mit einer Texterweiterung umbenannt wurden, zu einem Fehler.
- Der URI eines Dokuments verweist auf einen anderen Bucket als das aktuelle Projekt. Zugriff ist nur auf Dateien im Projekt-Bucket möglich.
- Nicht CSV-formatierte Dateien
Import-ZIP-Datei erstellen
Für Klassifizierungs-Datasets können Sie Trainingsdokumente mithilfe einer ZIP-Datei importieren. Erstellen Sie innerhalb der ZIP-Datei einen Ordner für jedes Label bzw. jeden Sentimentwert und speichern Sie jedes Dokument in dem Ordner, der dem Label bzw. Wert entspricht, das bzw. der auf das Dokument angewendet werden soll. Beispielsweise könnte die ZIP-Datei für ein Modell, das Geschäftskorrespondenz klassifiziert, folgende Struktur aufweisen:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language wendet die Ordnernamen als Labels auf die Dokumente im jeweiligen Ordner an. Bei einem Sentimentanalyse-Dataset sind die Ordnernamen die Sentimentwerte:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt