ML-Modell mithilfe von AutoML Natural Language erstellen
In dieser Kurzanleitung erfahren Sie, wie Sie mit AutoML Natural Language ein benutzerdefiniertes Modell für das maschinelle Lernen erstellen. Sie können ein Modell erstellen, um Dokumente zu klassifizieren, Entitäten in Dokumenten zu erkennen oder die vorherrschende emotionale Stimmung in einem Dokument zu ermitteln.
Hinweise
Projekt einrichten
Bevor Sie AutoML Natural Language verwenden können, müssen Sie ein Google Cloud-Projekt erstellen und AutoML Natural Language für dieses Projekt aktivieren.
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Cloud AutoML and Storage APIs aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Cloud AutoML and Storage APIs aktivieren.
Modellziele
AutoML Natural Language kann benutzerdefinierte Modelle für vier verschiedene Aufgaben trainieren, die als Modellziele bezeichnet werden:
- Die Klassifizierung mit einem einzigen Label klassifiziert Dokumente, indem ihnen ein Label zugewiesen wird
- Durch die Klassifizierung mit mehreren Labels können einem Dokument mehrere Labels zugewiesen werden
- Die Entitätsextraktion erkennt Entitäten in Dokumenten
- Die Sentimentanalyse ermittelt subjektive Einstellungen in Dokumenten
Für diese Kurzanleitung können Sie auswählen, welcher Modelltyp erstellt werden soll, indem Sie eines von drei Beispiel-Datasets auswählen, die in einem öffentlichen Cloud Storage-Bucket gehostet werden:
Wenn Sie ein Modell zur Klassifizierung mit einem einzigen Label erstellen möchten, verwenden Sie das Dataset "glückliche Momente", das aus dem Open-Source-Dataset HappyDB von Kaggle stammt. Das resultierende Modell klassifiziert glückliche Momente in Kategorien, die jeweils die Ursachen von Glück angeben.
Die Daten werden über eine Creative Commons CCO: Public Domain-Lizenz zur Verfügung gestellt.
Für die Erstellung eines Modells zur Entitätenextraktion verwenden Sie einen Korpus von Zusammenfassungen biomedizinischer Forschungsarbeiten, die Hunderte von Krankheiten und Konzepten erwähnen. Das resultierende Modell erkennt diese medizinischen Entitäten in anderen Dokumenten.
Dieses Dataset befindet sich gemäß den Bestimmungen des US-Urheberrechtsgesetzes in der Public Domain als "Werk der Regierung der Vereinigten Staaten".
Für die Erstellung eines Modells zur Sentimentanalyse verwenden Sie das offene Dataset von FigureEight, das Erwähnungen des Allergie-Medikaments Claritin auf Twitter erfasst.
Dataset erstellen
Öffnen Sie die AutoML Natural Language UI und wählen Sie Erste Schritte in dem Feld für den Modelltyp aus, den Sie trainieren möchten.
Klicken Sie in der Titelleiste auf die Schaltfläche Neues Dataset.
Geben Sie einen Namen für das Dataset ein und wählen Sie das Modellziel aus, das mit dem ausgewählten Beispiel-Dataset übereinstimmt.
Lassen Sie den Standort auf global festgelegt.
Wählen Sie im Bereich Text importieren die Option CSV-Datei in Cloud Storage auswählen aus und geben Sie den Pfad zu dem Dataset, das Sie verwenden möchten, in das Textfeld ein.
- Für das Dataset "glückliche Momente":
cloud-ml-data/NL-classification/happiness.csv - Für das Dataset der biomedizinischen Forschung:
cloud-ml-data/NL-entity/dataset.csv - Für das Sentiment-Dataset zu Claritin:
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(Das Präfix
gs://wird automatisch hinzugefügt.) Alternativ können Sie auch auf Durchsuchen klicken und die CSV-Datei aufrufen.Wenn Sie sich für das Sentiment-Dataset entscheiden, fragt AutoML Natural Language nach dem maximalen Sentimentwert. Der Höchstwert für dieses Dataset ist 4.
- Für das Dataset "glückliche Momente":
Klicken Sie auf Dataset erstellen.
Sie werden zur Seite Datasets zurückgeleitet. Für Ihr Dataset wird während des Imports der Dokumente eine animierte Fortschrittsanzeige eingeblendet. Dieser Vorgang dauert ungefähr 10 Minuten pro 1.000 Dokumente, kann jedoch auch mehr oder weniger Zeit in Anspruch nehmen.
Nachdem das Dataset erfolgreich erstellt wurde, erhalten Sie eine Nachricht an die mit Ihrem Projekt verknüpfte E-Mail-Adresse.
Modell trainieren
Nachdem Ihre Trainingsdaten erfolgreich importiert wurden, wählen Sie auf der Seite mit der Dataset-Liste das Dataset für weitere Details dazu aus. Der Name des ausgewählten Datasets wird in der Titelleiste angezeigt. Die einzelnen Dokumente im Dataset werden zusammen mit ihren Labels aufgelistet. Die Navigationsleiste auf der linken Seite fasst die Anzahl der Dokumente mit und ohne Label zusammen und ermöglicht Ihnen, die Dokumentliste nach Label zu filtern.
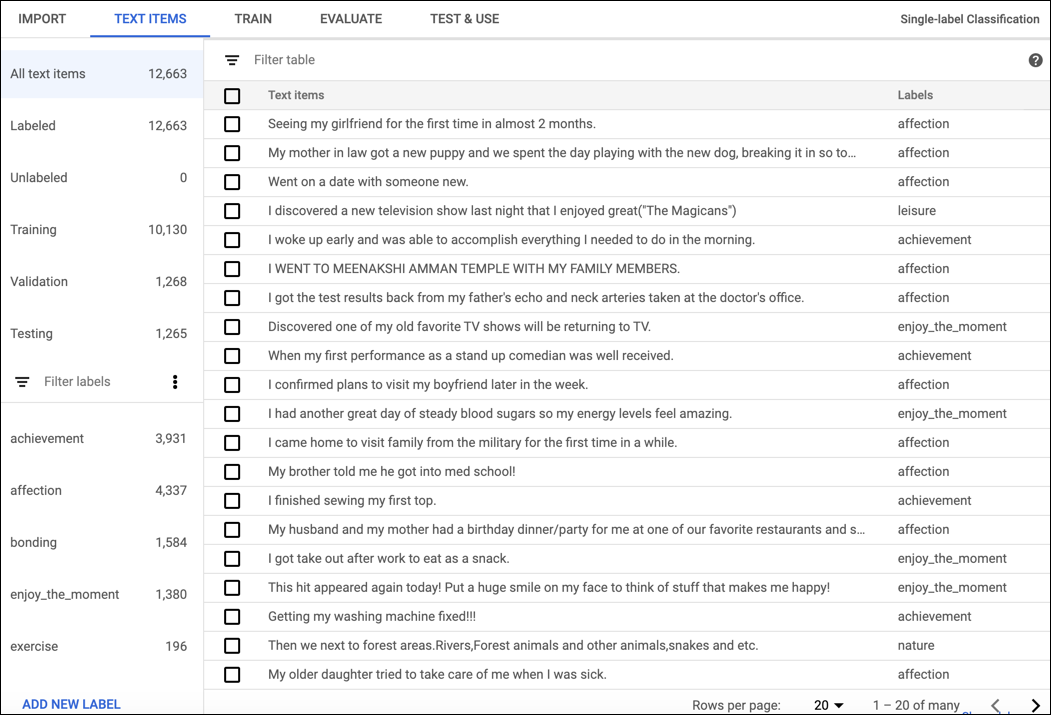
Nachdem Sie die Datasets überprüft haben, klicken Sie unterhalb der Titelleiste auf den Tab Trainieren.
Klicken Sie auf Training starten.
Geben Sie einen Namen für das neue Modell ein und klicken Sie das Kästchen Modell nach Abschluss des Trainings bereitstellen an.
Klicken Sie auf Training starten.
Das Trainieren eines Modells kann mehrere Stunden dauern. Nachdem das Modell erfolgreich trainiert wurde, erhalten Sie eine Nachricht an die mit Ihrem Projekt verknüpfte E-Mail-Adresse.
Nach dem Training zeigt der untere Teil der Train-Seite hochrangige Metriken für das Modell an, z. B. Präzision und Abruf. Klicken Sie auf den Tab Auswerten für weitere Details.
Benutzerdefiniertes Modell verwenden
Nachdem das Modell erfolgreich trainiert wurde, können Sie es zur Analyse anderer Dokumente verwenden. Klicken Sie auf den Tab Testen und verwenden direkt unter der Titelleiste. Geben Sie im Feld Eingabetext den Text einer PDF- oder TIFF-Datei in einem Cloud Storage-Bucket ein und klicken Sie auf Vorhersagen. AutoML Natural Language analysiert den Text anhand Ihres Modells und zeigt die Anmerkungen an.
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden.
Löschen Sie das Projekt mit der Google Cloud Console, wenn Sie es nicht benötigen. Damit vermeiden Sie unnötige Kosten für die Google Cloud Platform.