Type
Manufacturing Data Engine (MDE) helps you transform a class of source messages into records of a specific type through parsing.
Types are configuration entities that represent the target of the parsing operation, and describe a set of structurally and semantically similar records with a common level of granularity that, optionally, share specific metadata context.
For example, you can create "machine state" and "vibration sensor readings" types. The first type could be used to model machine state change events, such as "Running", "Idle", "Scheduled Maintenance," and "Unscheduled Maintenance" while the second one could be used to model a stream of numeric vibration sensor readings.
MDE ships with a set of default types, but you can create new ones. Types are defined by the following characteristics:
- Name: The name of the type.
- Archetype: The name of the archetype on which a type is based. A type in MDE is always associated to exactly one archetype
- Storage specifications: A list of settings per data sink. Storage specifications allow configuring whether records are written to a data sink and allow providing further sink-specific settings.
- Optional configuration parameters, including:
- The JSON schema of the data field (only applicable to types of discrete and continuous archetypes).
- Metadata bucket associations: A list of metadata buckets for which records of the type must provide instance references.
Types and data sinks
The stream of records of a given type is processed by data sinks enabled for a type. Data sinks can be activated (enabled or disabled) for types. For example, the records of a type can be configured to be written in BigQuery, but not in Cloud Storage.
Supported data sinks
MDE supports the following data sinks:
- BigQuery
- Bigtable/Federation API
- Cloud Storage
- Pub/Sub (JSON and Protobuf)
BigQuery data sink
When a new type is created, MDE automatically creates a
corresponding type table in BigQuery in the mde_data dataset.
The records of each type are written to the corresponding type table.
Cloud Storage data sink
Records are stored in a Cloud Storage bucket called
<project_id>-gcs-ingestion in AVRO files using Hive partitioning using a 10
minute window and 10 partitions per window. Records are grouped in folders by
type.
Pub/Sub data sink
The Pub/Sub sink publishes records to a dedicated topic. Pub/Sub message schema is described in the Pub/Sub sink message schema.
Metadata materialization
Each data sink on a type can be be configured to materialize metadata in
records. If this setting is enabled, metadata instance references are resolved to
metadata instance objects, and the objects are included in the records. The
precise way in which metadata is persisted or outputted depends on the data sink.
In BigQuery, for example, materialized metadata is written to the
materialized_metadata_field with the following schema:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
Archetypes
Archetypes represent a superclass of types, and each archetype is designed to provide an optimal processing and storage model for records. Archetypes define the core mandatory fields that must be present in a record of a given type emitted by a parser. MDE ships with a set of six system-defined standard and clustered archetypes grouped in three archetype families:
- Numeric data series (NDS)
- Discrete data series (DDS)
- Continuous data series (CDS)
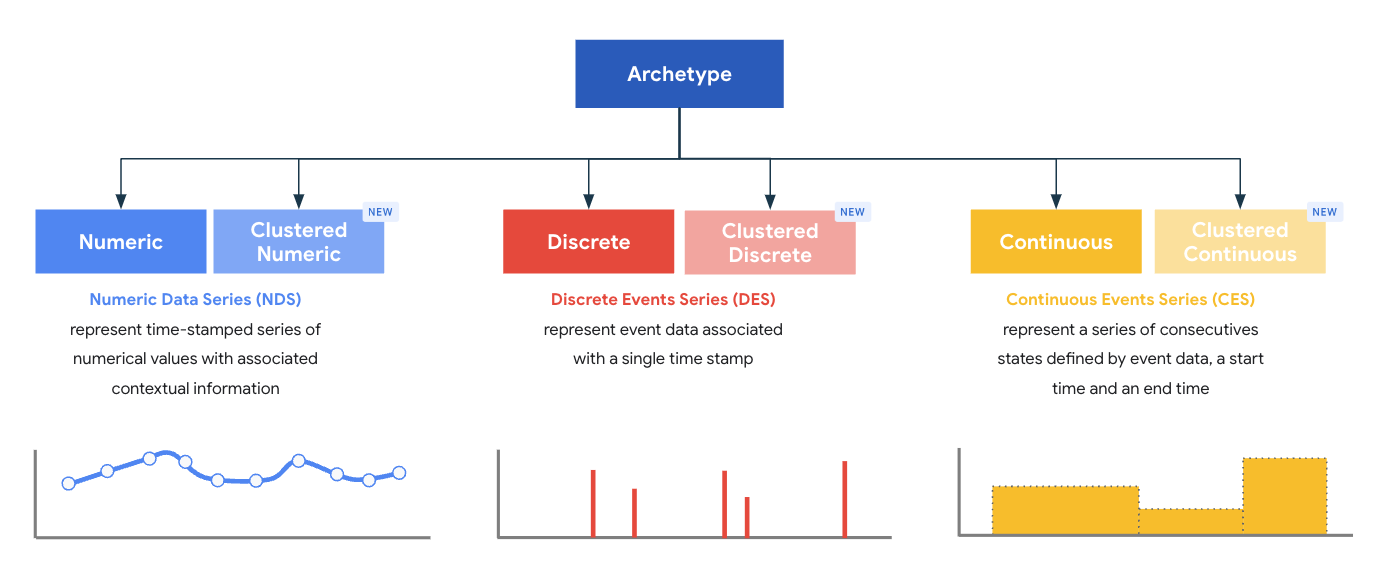
A type in MDE is always associated with exactly one archetype, and the archetype of a type is defined at creation time.
You can use types to define further constraints on proto records emitted by
parsers beyond those imposed by archetypes. For example, you can specify the
shape of the data field for a type, or you can define that records of a type
must be contextualized by specific metadata.
In summary, the proto record schema is a combination of:
- Archetype schema
- Type schema
Archetype families
Each archetype family contains two types of archetypes:
- Standard
- Clustered
MDE v1.3 introduces the concept of clustered archetypes, which extend the functionality of the standard archetypes. Clustered archetypes provide four generic fields that can be populated with values in the parser. Each data sink uses these four fields to provide additional query and data access capabilities:
- BigQuery: Clustered type tables in BigQuery are clustered by the four generic fields in order. This lets you filter data in BigQuery efficiently on the clustered fields.
- Bigtable Federation API: The Federation API used the clustered fields to construct row-keys in Bigtable enabling new data access patterns.
- Pub/Sub: Pub/Sub messages pass on the fields as first-level fields in the Pub/Sub message.
Numeric archetype family
The numeric archetype family is designed to serve as the base for types that model a series of time-stamped numerical messages, for example, a temperature sensor emitting a stream of readings.
The standard and clustered versions of the archetype define the following base record schemas:
Standard
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
value |
Numeric | Yes |
eventTimestamp |
Integer (formatted as epoch ms) | Yes |
Clustered
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
value |
Numeric | Yes |
eventTimestamp |
Integer (formatted as epoch ms) | Yes |
clustered_column_1 |
String | No |
clustered_column_2 |
String | No |
clustered_column_3 |
String | No |
clustered_column_4 |
String | No |
Discrete archetype family
The discrete archetype family is designed to serve as the base for types that model time-stamped events, for example, an operator driven parameter change in a specific machine or a process.
The standard and clustered versions of the archetype define the following base record schemas:
Standard
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
data |
JSON object | Yes |
eventTimestamp |
Integer (formatted as epoch ms) | Yes |
Clustered
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
data |
JSON object | Yes |
eventTimestamp |
Integer (formatted as epoch ms) | Yes |
clustered_column_1 |
String | No |
clustered_column_2 |
String | No |
clustered_column_3 |
String | No |
clustered_column_4 |
String | No |
Continuous archetype family
The continuous archetype family is designed to serve as the base for types that model series of consecutive states defined by a start and end timestamp, for example, the operating state of a machine for a continuous period of time.
The standard and clustered versions of the archetype define the following base record schemas:
Standard
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
data |
JSON object | Yes |
eventTimestampStart |
Integer (formatted as epoch ms ) | Yes |
eventTimestampEnd |
Integer (formatted as epoch ms ) | Yes |
Clustered
| Field | Data type | Required |
|---|---|---|
tagName |
String | Yes |
data |
JSON object | Yes |
eventTimestampStart |
Integer (formatted as epoch ms ) | Yes |
eventTimestampEnd |
Integer (formatted as epoch ms ) | Yes |
clustered_column_1 |
String | No |
clustered_column_2 |
String | No |
clustered_column_3 |
String | No |
clustered_column_4 |
String | No |
Data field
The discrete data series and continuous data series archetypes accept a JSON
schema for the data field. If a JSON schema for the field is defined, at
the value of the data field contained by a record emitted by a parser is
validated against the schema at runtime. For example, imagine you define the
following schema for a discrete time series type:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
With the previous schema for a discrete time series type, the following (partial) record of that type emitted by a parser isn't valid:
{
"data": {
"complex": {
"machineName": "example"
}
}
}
If data validation fails, records are moved to the dead letter queue. Records in the dead letter queue can be manually processed later on.
Metadata buckets
Types can reference metadata buckets. A metadata bucket reference on a type
defines whether records may or must (depending on the value of the required
attribute) provide a reference to a metadata bucket instance.
Metadata bucket references on a type define the metadata contract for records of that type. For example, you can define that all records of a type must be contextualized with device metadata (provide a reference to a metadata instance in a metadata bucket called device).
If a metadata bucket is associated to a type and the required flag is set to
true, records of that type emitted by a parser that don't provide a reference
to a metadata bucket instance are are moved to the dead letter queue. For
more information, see See
How to reprocess messages.
Type versioning
There are different versioning types and the following sections describe each one.
New type version creation
You can create new versions for a specific type. Each new version can specify additional metadata bucket associations or modify the schema of the data field. However, to ensure data consistency across the lifetime of a type, new type versions may only evolve forward, and they must observe versioning rules. New versions of a type can make the following changes:
May:
- Add new optional fields to the data schema.
- Mark a required field optional to the data schema.
- Add new metadata bucket references.
May not:
- Remove fields from the data schema.
- Change data type of existing fields in the data schema.
- Mark an an optional attribute required in the data schema.
- Remove metadata bucket references.
Existing type version editing
Storage specifications and transformations may be updated on an existing type version without the need to create a new type version.
Type editing
Most operations on types require either creating a new type version or editing an existing type version. The only operation that can be performed on type independent of its version is enabling or disabling it. When a type is disabled all versions of that type stop accepting data.
Naming restrictions for Types
A type name can contain the following:
- Letters (uppercase and lowercase), numbers and the special characters
-and_. - Can be up to 255 characters long.
You can use the following regular expression for validation: ^[a-z][a-z0-9\\-_]{1,255}$.
If you try to create an entity violating the naming restrictions you will get a 400 error.