Apache Kafka for BigQuery deploys clusters in a Google-managed Virtual Private Cloud (VPC). A cluster is exposed in your VPCs by using Private Service Connect (PSC) endpoints. This section explains the details of this architecture.
Before you begin
This section discusses features from several Google Cloud services that are used in Apache Kafka for BigQuery networking.
Tenant network: The Google Cloud-managed VPC that hosts Apache Kafka for BigQuery clusters. Each Kafka cluster resides within its own isolated tenant network. This ensures security and isolation.
Consumer network: The VPC where you run your Kafka clients. Note that this is not relevant to the clients that connect to the Google APIs since these are not served on a VPC.
PSC: PSC connects the tenant network to the consumer network. It lets you create IP addresses for the Kafka cluster, including the bootstrap server and brokers, in a specific subnet.
Cloud DNS: The Google Cloud service creates DNS entries associated with PSC IP addresses. These entries are registered in Cloud DNS using a split-horizon DNS zone. The registered URLs are a property of the cluster, rather than a VPC.
To know more about these concepts, see Components of an Apache Kafka for BigQuery service.
Required permissions
To enable cross-project access using PSC, you must grant
specific permissions to the Google-managed service agent,
service-<project_number>@gcp-sa-managed-kafka.iam.gserviceaccount.com.
Replace <project_number> with the project number of the project that contains
the Apache Kafka for BigQuery cluster. This service account is automatically
created for each project and is responsible for managing your clusters.
Assign the Apache Kafka for BigQuery service agent role
(roles/managedkafka.serviceAgent) to this service account in each project
where you want to create PSC endpoints. This role includes the specific
permissions needed for PSC configuration.
For more information on how to grant a role to a service account, see Manage access to service accounts.
Networking workflow
The following is a brief overview of the steps that you need to take to set up networking for your clusters:
Determine the projects where you want your Kafka clients to access the Apache Kafka for BigQuery cluster.
In each of the projects that contains the VPC network, grant the
roles/managedkafka.serviceAgentrole to theservice-<project_number>@gcp-sa-managed-kafka.iam.gserviceaccount.comservice agent associated with the project that hosts the Apache Kafka for BigQuery cluster.Choose a subnet within each VPC to assign IP addresses for your cluster. You'll need one IP address for the initial setup server and one for each data processing node.
Start with at least 3 data processing nodes (one in each zone) and add more nodes as needed when the cluster in a specific zone reaches around 10 vCPUs worth of usage.
Set up your cluster to connect to the chosen subnets.
For more information about creating the cluster, see Create an Apache Kafka for BigQuery cluster.
Your applications within those VPC networks can now connect to your clusters using the PSC endpoints.
Network architecture of a cluster
A Kafka cluster spans a tenant network and one or more VPC networks.
The cluster bootstrap servers are load balanced and served by using a single IP address and URL for the cluster. This configuration is in contrast to a basic deployment of open source Apache Kafka where one or more brokers can act as bootstrap servers.
Within each VPC, a single PSC endpoint is provisioned for the bootstrap servers and one for each broker. The URL for the bootstrap server is the same across the consumer VPCs to which a cluster is connected.
PSC lets you associate a unique IP address for each Kafka server. This IP address is local to the consumer VPC.
Clients can connect to Kafka brokers using either internal IP addresses or DNS names. However, using DNS names is recommended. These names are registered automatically in every VPC to which a Kafka cluster is connected. The bootstrap server is typically accessible at
bootstrap.CLUSTER_NAME.LOCATION_NAME.managedkafka.myproject.cloud.goog, while brokers are usually registered asbroker-N.CLUSTER_NAME.LOCATION_NAME.managedkafka.myproject.cloud.goog:9092. The bootstrap server and its port number are also available as a property of the cluster.The bootstrap server is used by clients to retrieve broker URLs that are resolved to IP addresses local to each VPC. You can, however, find actual broker IP addresses and URLs in Cloud DNS.
The following image shows a sample architecture of a Kafka cluster network.
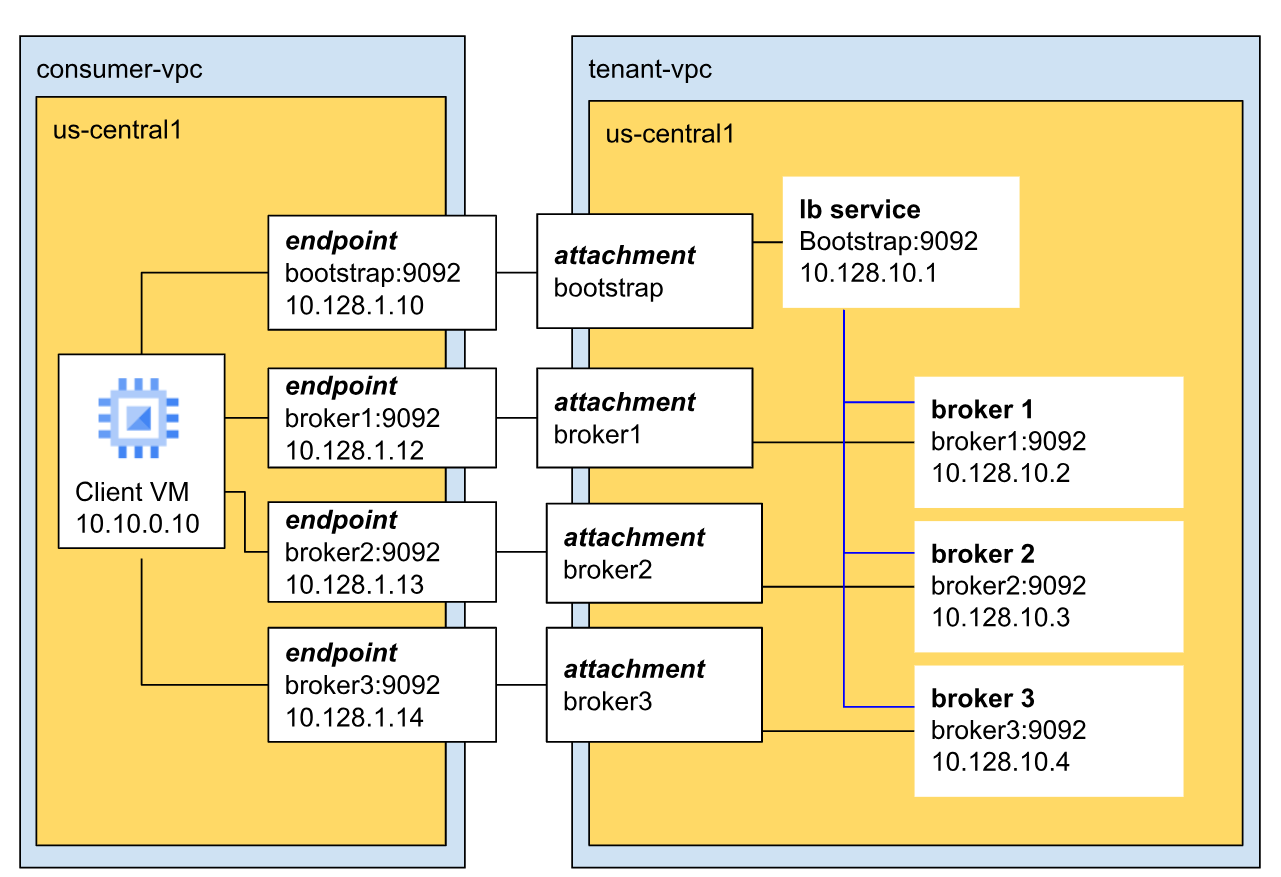
In this example, the cluster has three brokers and the cluster is in the tenant VPC.
Brokers communicate over the default Apache Kafka for BigQuery port (9092) and have unique IP addresses, facilitating their coordination within the cluster. In this example, the three brokers have IP addresses 10.128.10.1, 10.128.10.2, and 10.128.10.3 respectively.
All three brokers connect to the bootstrap service, which is accessed through a load balancer and runs on some or all of the brokers. This ensures high availability and regional fault tolerance, as the bootstrap service is not confined to a single broker or zone.