La transcodification de données localement sur un mainframe est un processus gourmand en processeur qui entraîne une consommation élevée de millions d'instructions par seconde (MIPS). Pour éviter cela, vous pouvez utiliser Cloud Run pour déplacer et transcoder des données de mainframe à distance surGoogle Cloud. Cela libère votre mainframe pour les tâches critiques pour l'entreprise et réduit également la consommation de MIPS.
Si vous souhaitez déplacer de très grands volumes de données (environ 500 Go par jour ou plus) de votre mainframe vers Google Cloud, et que vous ne souhaitez pas utiliser votre mainframe pour cette tâche, vous pouvez utiliser une solution de bibliothèque de bandes virtuelles (VTL) compatible avec le cloud pour transférer les données vers un bucket Cloud Storage. Vous pouvez ensuite utiliser Cloud Run pour transcoder les données présentes dans le bucket et les déplacer vers BigQuery.
Cette page explique comment lire les données de mainframe copiées dans un bucket Cloud Storage, les transcoder du format EBCDIC (Extended Binary Coded Decimal Interchange Code) au format ORC en UTF-8, puis les charger dans une table BigQuery.
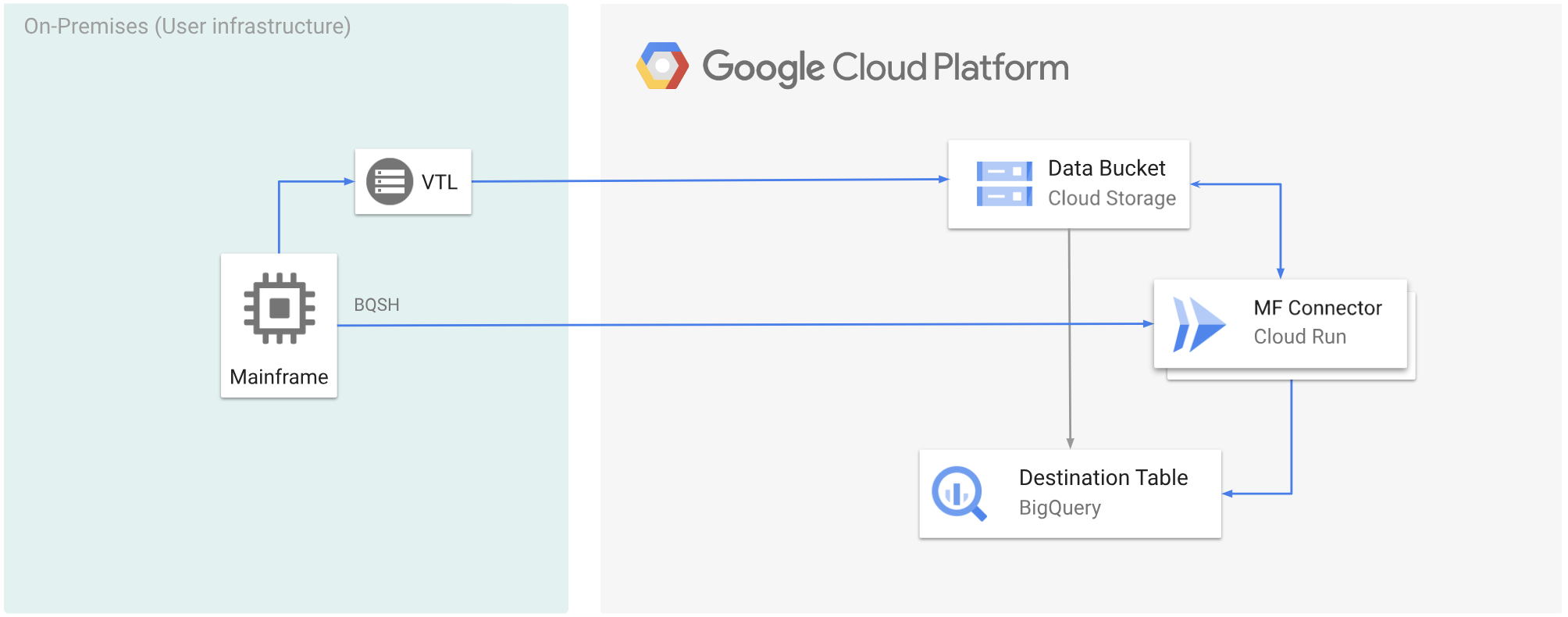
Le diagramme suivant montre comment déplacer vos données de mainframe vers un bucket Cloud Storage à l'aide d'une solution VTL, transcoder les données au format ORC à l'aide de Cloud Run, puis déplacer le contenu vers BigQuery.
Avant de commencer
- Choisissez une solution VTL adaptée à vos besoins, puis déplacez vos données de mainframe vers un bucket Cloud Storage et enregistrez-les en tant que
.dat. Assurez-vous d'ajouter une clé de métadonnées nomméex-goog-meta-lreclau fichier.datimporté et que la longueur de la clé de métadonnées est égale à la longueur d'enregistrement du fichier d'origine, par exemple 80. - Déployez Mainframe Connector sur Cloud Run.
- Dans votre mainframe, définissez la variable d'environnement
GCSDSNURIsur le préfixe que vous avez utilisé pour vos données mainframe sur le bucket Cloud Storage.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: nom du bucket Cloud Storage.
- PREFIX: préfixe que vous souhaitez utiliser dans le bucket.
- Créez un compte de service ou identifiez un compte de service existant à utiliser avec Mainframe Connector. Ce compte de service doit disposer d'autorisations pour accéder aux buckets Cloud Storage, aux ensembles de données BigQuery et à toute autre ressource que vous souhaitez utiliser. Google Cloud
- Assurez-vous que le compte de service que vous avez créé dispose du rôle Demandeur Cloud Run.
Transcoder des données de mainframe importées dans un bucket Cloud Storage
Pour déplacer des données de mainframe vers Google Cloud à l'aide de VTL et effectuer une transcodage à distance, vous devez effectuer les tâches suivantes:
- Lire et transcoder les données présentes dans un bucket Cloud Storage au format ORC L'opération de transcodage convertit un jeu de données EBCDIC de mainframe au format ORC en UTF-8.
- Chargez l'ensemble de données dans une table BigQuery.
- (Facultatif) Exécutez une requête SQL sur la table BigQuery.
- (Facultatif) Exporter des données de BigQuery vers un fichier binaire dans Cloud Storage.
Pour effectuer ces tâches, procédez comme suit:
Dans votre mainframe, créez une tâche pour lire les données d'un fichier
.datdans un bucket Cloud Storage et les transcoder au format ORC, comme suit.Pour obtenir la liste complète des variables d'environnement compatibles avec le connecteur Mainframe, consultez la section Variables d'environnement.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*Remplacez les éléments suivants :
PROJECT_NAME: nom du projet dans lequel vous souhaitez exécuter la requête.INPUT_FILENAME: nom du fichier.datque vous avez importé dans un bucket Cloud Storage.
Si vous souhaitez consigner les commandes exécutées au cours de ce processus, vous pouvez activer les statistiques de charge.
(Facultatif) Créez et envoyez une tâche de requête BigQuery qui exécute une lecture SQL à partir du fichier DD QUERY. En règle générale, la requête est une instruction
MERGEouSELECT INTO DMLqui entraîne la transformation d'une table BigQuery. Notez que le connecteur Mainframe consigne les métriques de tâche, mais n'écrit pas les résultats de la requête dans un fichier.Vous pouvez interroger BigQuery de différentes manières : en ligne, avec un ensemble de données distinct à l'aide de DD ou avec un ensemble de données distinct à l'aide de DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*Remplacez les éléments suivants :
PROJECT_NAME: nom du projet dans lequel vous souhaitez exécuter la requête.LOCATION: emplacement où la requête sera exécutée. Nous vous recommandons d'exécuter la requête dans un emplacement proche des données.
(Facultatif) Créez et envoyez un job d'exportation qui exécute une lecture SQL à partir du fichier DD QUERY et exporte le jeu de données obtenu vers Cloud Storage en tant que fichier binaire.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Remplacez les éléments suivants :
PROJECT_NAME: nom du projet dans lequel vous souhaitez exécuter la requête.DATASET_ID: ID de l'ensemble de données BigQuery contenant la table que vous souhaitez exporter.DESTINATION_TABLE: table BigQuery que vous souhaitez exporter.BUCKET: bucket Cloud Storage qui contiendra le fichier binaire de sortie.