メインフレーム上でローカルにデータのコード変換を行うのは CPU 使用率の高いプロセスであり、100 万命令/秒(MIPS)の高い消費につながります。これを回避するには、Cloud Run を使用してGoogle Cloudでメインフレーム データをリモートで移動してコード変換します。これにより、ビジネス クリティカルなタスクにメインフレームを解放し、MIPS の消費を削減できます。
非常に大量のデータ(1 日あたり約 500 GB 以上)をメインフレームから Google Cloudに移動し、この作業にメインフレームを使用したくない場合は、クラウド対応の Virtual Tape Library(VTL)ソリューションを使用して、データを Cloud Storage バケットに転送できます。その後、Cloud Run を使用してバケット内のデータをコード変換し、BigQuery に移動できます。
このページでは、Cloud Storage バケットにコピーされたメインフレーム データを読み取り、拡張バイナリ コーディング 10 進交換コード(EBCDIC)データセットから UTF-8 の ORC 形式にコード変換し、そのデータセットを BigQuery テーブルに読み込む方法について説明します。
次の図は、VTL ソリューションを使用してメインフレーム データを Cloud Storage バケットに移動し、Cloud Run を使用してデータを ORC 形式にコード変換してから、コンテンツを BigQuery に移動する方法を示しています。
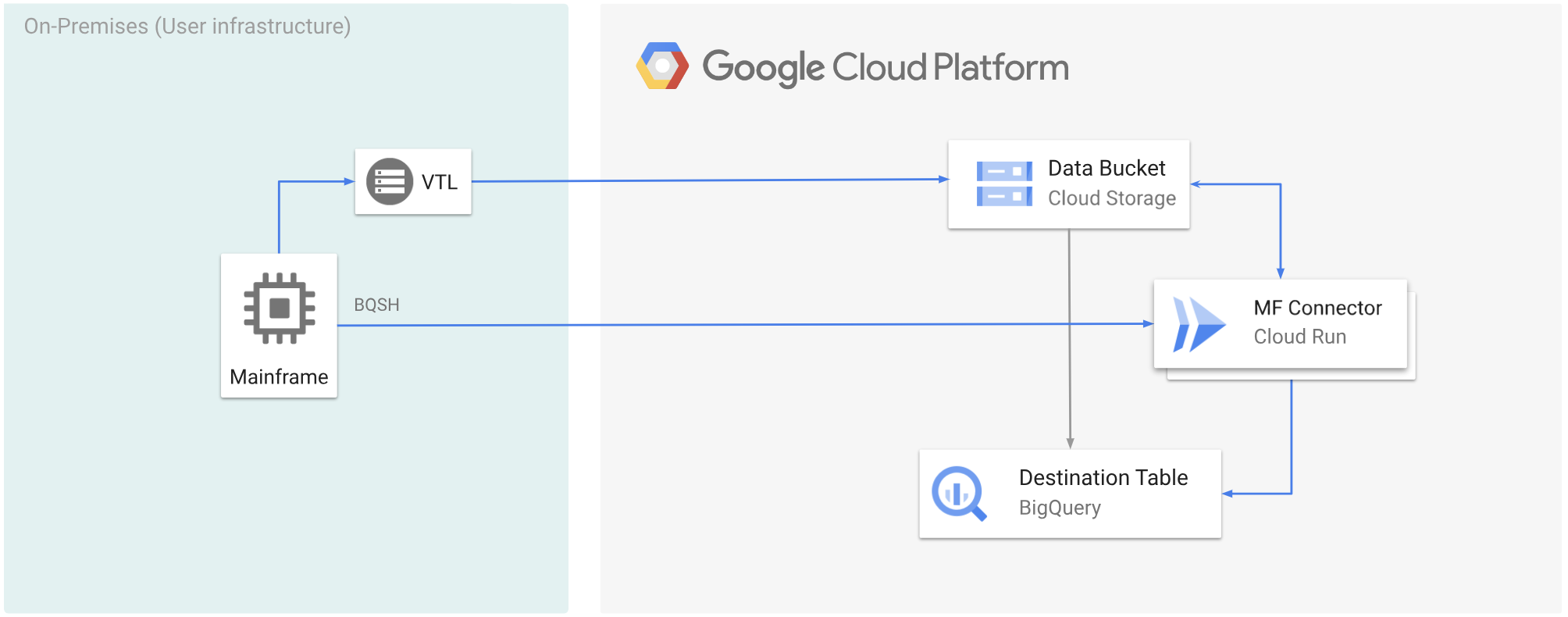
始める前に
- 要件に合った VTL ソリューションを選択し、メインフレーム データを Cloud Storage バケットに移動して
.datとして保存します。アップロードした.datファイルにx-goog-meta-lreclという名前のメタデータキーを追加していること、およびメタデータの鍵長が元のファイルのレコードの長さ(例: 80)と等しいことを確認してください。 - Mainframe Connector を Cloud Run にデプロイする。
- メインフレームで、
GCSDSNURI環境変数を、Cloud Storage バケットのメインフレーム データに使用した接頭辞に設定します。export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: Cloud Storage バケットの名前。
- PREFIX: バケットで使用する接頭辞。
- Mainframe Connector で使用するサービス アカウントを作成するか、既存のサービス アカウントを特定します。このサービス アカウントには、Cloud Storage バケット、BigQuery データセット、使用するその他のリソースにアクセスするための権限が必要です。 Google Cloud
- 作成したサービス アカウントに Cloud Run 起動元のロールが割り当てられていることを確認します。
Cloud Storage バケットにアップロードされたメインフレーム データをコード変換する
VTL を使用してメインフレーム データを Google Cloud に移動し、リモートでコード変換するには、次の作業を行う必要があります。 Google Cloud
- Cloud Storage バケットにあるデータを読み取り、ORC 形式にコード変換します。コード変換オペレーションは、メインフレームの EBCDIC データセットを UTF-8 の ORC 形式に変換します。
- データセットを BigQuery テーブルに読み込みます。
- (省略可)BigQuery テーブルに対して SQL クエリを実行します。
- (省略可)BigQuery から Cloud Storage のバイナリ ファイルにデータをエクスポートします。
これらのタスクを実行する手順は次のとおりです。
メインフレームで、Cloud Storage バケットの
.datファイルからデータを読み取り、ORC 形式にコード変換するジョブを作成します。Mainframe Connector でサポートされている環境変数の一覧については、環境変数をご覧ください。
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*以下を置き換えます。
PROJECT_NAME: クエリを実行するプロジェクトの名前。INPUT_FILENAME: Cloud Storage バケットにアップロードした.datファイルの名前。
このプロセスで実行されたコマンドをログに記録するには、負荷統計情報を有効にすることができます。
(省略可)QUERY DD ファイルから SQL 読み取りを実行する BigQuery クエリジョブを作成して送信します。 通常、クエリは
MERGEまたはSELECT INTO DMLステートメントであり、BigQuery テーブルが変換されます。Mainframe Connector は、ジョブ指標に記録しますが、クエリ結果をファイルに書き込みません。BigQuery にはさまざまな方法でクエリできます。インラインでクエリすることも、DD を使用して別のデータセットを使用してクエリすることもできます。DSN を使用して別のデータセットを使用してクエリすることもできます。
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*以下を置き換えます。
PROJECT_NAME: クエリを実行するプロジェクトの名前。LOCATION: クエリが実行されるロケーション。データに近いロケーションでクエリを実行することをおすすめします。
(省略可)QUERY DD ファイルから SQL 読み取りを実行し、結果のデータセットをバイナリ ファイルとして Cloud Storage にエクスポートするエクスポート ジョブを作成して送信します。
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*以下を置き換えます。
PROJECT_NAME: クエリを実行するプロジェクトの名前。DATASET_ID: エクスポートするテーブルを含む BigQuery データセット ID。DESTINATION_TABLE: エクスポートする BigQuery テーブル。BUCKET: 出力バイナリ ファイルを含む Cloud Storage バケット。