组织使用 IBM 大型机来执行关键的计算任务。近年来,许多依赖大型机的公司一直在努力向云迁移。借助 Mainframe Connector,您可以将大型主机数据迁移到Google Cloud ,从而将 CPU 密集型报告工作负载分流到 Google Cloud。
Mainframe Connector 的主要优势
使用 Mainframe Connector 将大型主机数据移至 Google Cloud的主要优势如下:
- 简化数据转移:简化了将大型主机数据转移到Google Cloud Cloud Storage 和 BigQuery 等存储服务的流程。
- 批量作业集成:允许您使用在作业控制语言 (JCL) 中定义的主机批量作业提交 BigQuery 作业。在从数据集或文件中读取查询时,分析师可以使用预定作业,而无需深入了解大型机环境。
- 易于监控:大型机运营人员无需监控不同的环境,因为作业是使用 JCL 按照熟悉的调度提交的。
- 减少 MIPS:Mainframe Connector 使用 Java 虚拟机 (JVM) 进行大部分处理,以最大限度地减少数据传输期间的大型主机处理器工作负载,从而减少每秒百万条指令 (MIPS),进而降低成本。Mainframe Connector 可将大多数处理器密集型工作分流到辅助处理器。如果辅助处理器压力过大,您还可以配置 Mainframe Connector,以使用 Compute Engine 执行转码和转换。如需详细了解 Mainframe Connector 配置,请参阅 Mainframe Connector 配置。
流式转换:将文件转码为 ORC、JSON 或 CSV 格式,这些格式与 BigQuery 等 Google Cloud 服务兼容。 Mainframe Connector 支持以下文件类型的转码:
- 与扩展二进制编码十进制交换码 (EBCDIC) 中的 COBOL 复制簿相关联的排队顺序访问方法 (QSAM) 或虚拟存储访问方法 (VSAM) 大型机数据集
- 采用 ASCII UTF-8 编码的文件
默认情况下,Mainframe Connector 会将数据集从 US EBCDIC: Cp037 字符集转码为 ORC、JSON 和 CSV 格式。不过,Mainframe Connector 还支持从以下区域性 EBCDIC 字符集转码数据集:
- 法语:Cp297
- 德语:Cp1141
- 西班牙语:Cp1145
如果 IBM JVM 中未包含合适的字符集,则可以实现自定义字符集。
Mainframe Connector 的工作方式
借助 Mainframe Connector,您可以将大型主机上的数据移入和移出 Cloud Storage,并从 JCL 中定义的大型机批处理作业提交 BigQuery 作业。借助 Mainframe Connector,您可以将大型机数据集直接转码为 Optimized Row Columnar (ORC) 格式。
转码是指将信息从一种编码表示形式转换为另一种编码表示形式(在本例中为 ORC)。ORC 是一种开源列式数据格式,广泛应用于 Apache Hadoop 生态系统,并且受 BigQuery 支持。
Mainframe Connector 提供了一部分 Google Cloud SDK 命令行实用程序,可让您传输数据并与 Google Cloud 服务互动。gsutil 和 bq 命令行实用程序的 shell 解释器和基于 JVM 的实现使您能够完全从 IBM z/OS 管理完整的提取、加载、转换 (ELT) 流水线,同时保留现有的作业调度程序。
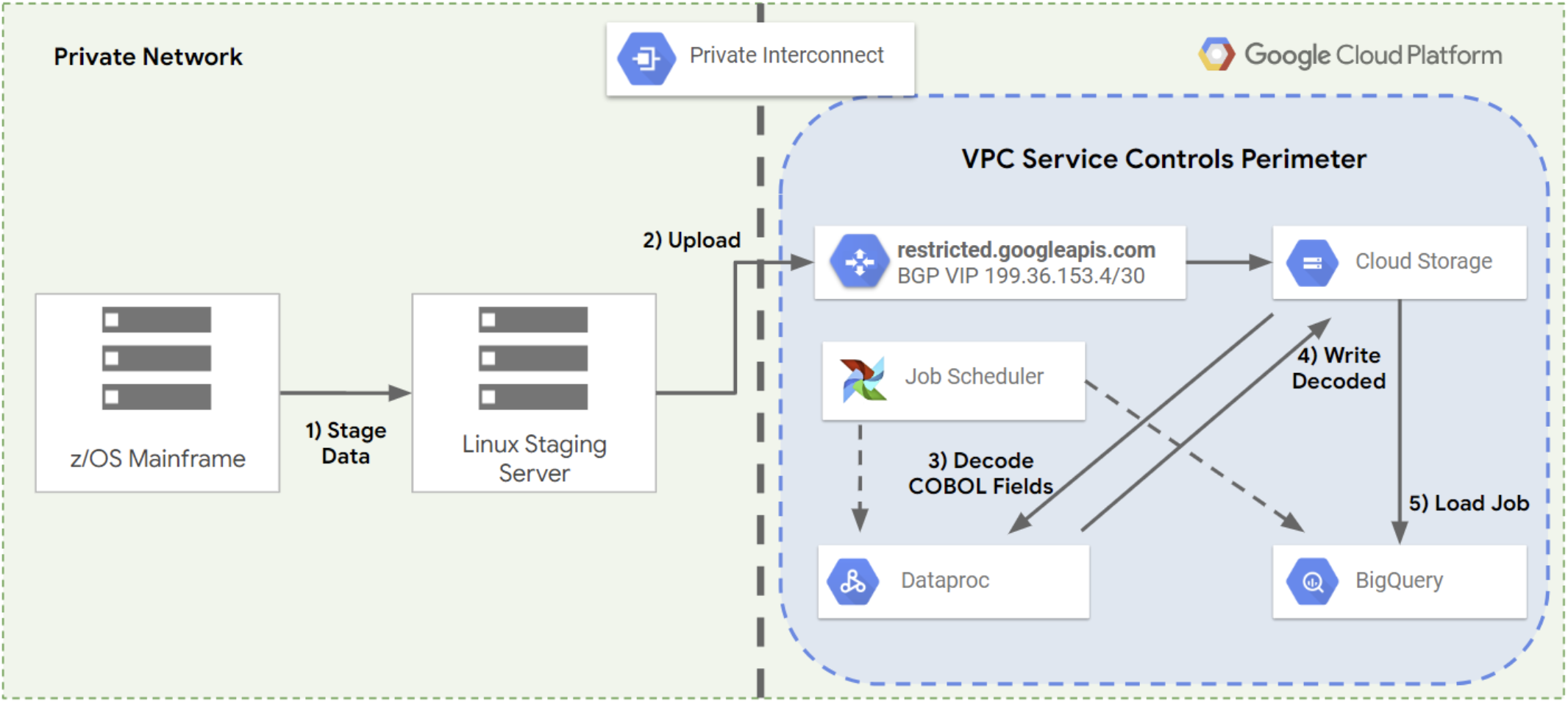
将大型主机数据转移到云端以及从云端转移大型主机数据的主要挑战之一在于,这是一个多步骤的过程,通常包括执行以下步骤:
- 将数据复制到文件服务器。
- 将文件服务器中的数据复制到其他位置以进行处理。
- 使用数据处理堆栈将数据转换为新式格式。
- 将处理后的数据写回另一个位置。
- 将处理后的数据加载到数据库或数据仓库中,以便查询或使用数据。
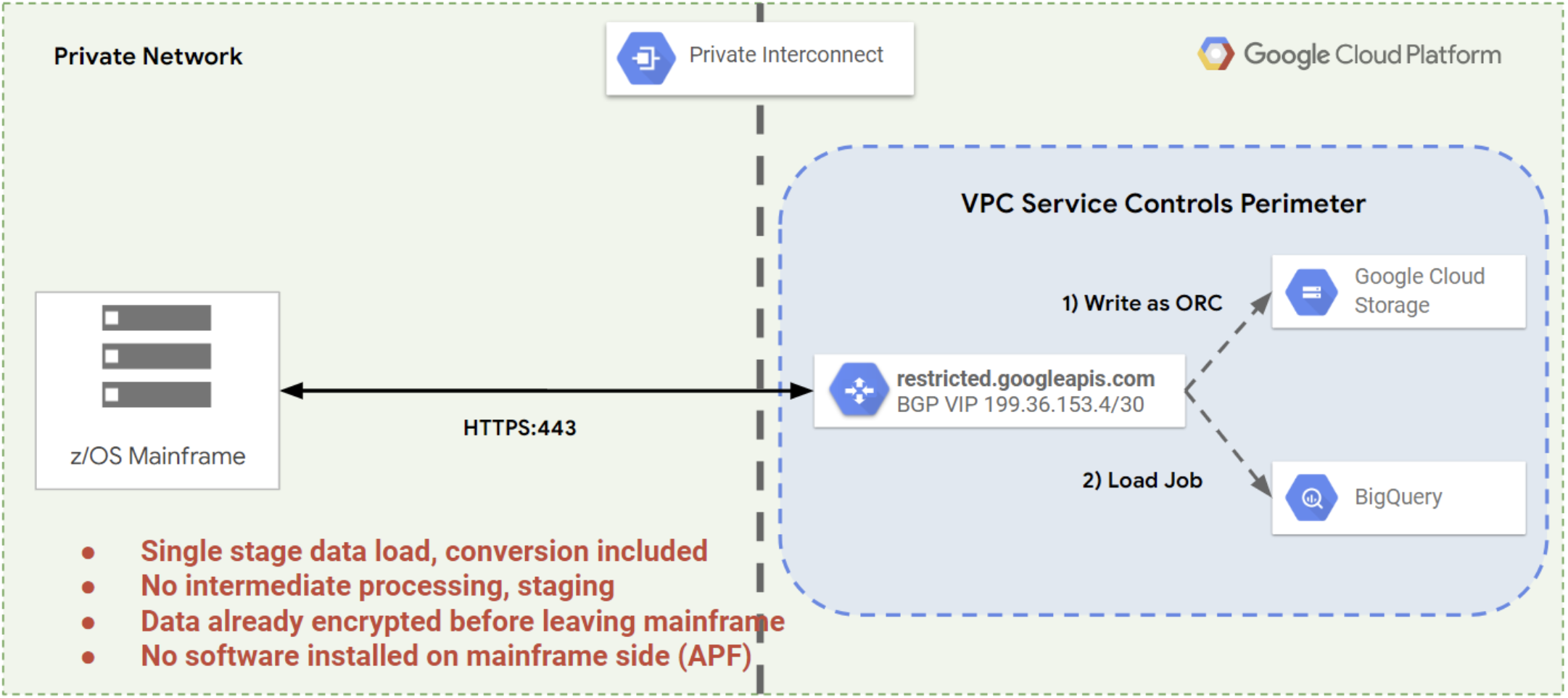
下图显示了通常用于将数据从大型机转移到 Google Cloud的多步流程。
借助 Mainframe Connector,您可以使用单个命令执行所有这些步骤,并将 Cloud Storage 用作中间存储位置。这样一来,大型机数据在数据库或数据仓库中处理并可供使用所需的时间就会缩短,如下图所示。