Depois de proteger e configurar a base de dados, tem tudo pronto para associá-la ao Looker.
Cria uma ligação à base de dados no Looker na página Associe a sua base de dados ao Looker. Existem duas opções para abrir a página Associe a sua base de dados ao Looker:
- Selecione Associações na secção Base de dados do painel Administração. Na página Ligações, clique no botão Adicionar ligação.
- Clique no botão Criar no painel de navegação do lado esquerdo e, de seguida, selecione o item de menu Associação.
Para mais informações sobre a aplicação de atributos do utilizador às definições de associação, consulte a secção Associações da página de documentação Atributos do utilizador.
Esta página descreve os campos comuns que o Looker apresenta na página Associe a sua base de dados ao Looker. Os campos exatos que a página apresenta dependem da sua definição de variante.
Clique aqui para ver os links para as instruções específicas do dialeto na documentação do Looker.
- Actian Avalanche
- AlloyDB para PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS for MySQL
- Amazon RDS para PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3+ e 3.1.2+
- Apache Spark 3 ou superior
- ClickHouse
- Cloudera Impala 3.1 ou superior
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- SQL antigo do Google BigQuery
- SQL padrão do Google BigQuery
- Google Cloud SQL para MySQL
- Google Cloud SQL para PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 no AS400
- IBM DB2 no LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL Database
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- Conetor do MongoDB para BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (anteriormente MemSQL)
- Snowflake
- Teradata
- Trino
- Vector
- Vertica
Depois de introduzir as definições de ligação da base de dados, pode selecionar o botão Testar na página Ligue a sua base de dados ao Looker para testar a ligação e certificar-se de que está configurada corretamente. Clique em Testar para verificar se a associação foi bem-sucedida. Consulte a página de documentação Testar a conetividade da base de dados para ver informações de resolução de problemas. Se o Looker apresentar a mensagem Can Connect (É possível estabelecer ligação), prima Connect (Estabelecer ligação) para criar a ligação. A ligação à base de dados é adicionada à lista na página de administração Ligações do Looker.
Definições gerais
Nome
O nome da associação como quer referir-se a ela. Precisa deste nome de ligação à base de dados para usar no parâmetro connection do seu modelo LookML. O nome da associação à base de dados também é a forma como a associação é identificada na página Associações Administração do Looker. Não use o nome de nenhuma pasta para esta definição. Este valor não tem de corresponder a nada na sua base de dados. Name é uma etiqueta que identifica esta ligação na IU do Looker.
Âmbito da ligação
Selecione se a associação deve poder ser usada com todos os projetos ou apenas com um projeto:
- Todos os projetos: todos os projetos do LookML na instância podem ter acesso à ligação, pelo que o nome da ligação pode ser especificado no parâmetro
connectiondos ficheiros de modelo nesse projeto. - Projeto selecionado: apenas um projeto do LookML na instância pode ter acesso à ligação. Quando seleciona esta opção, o ecrã de associação apresenta um menu pendente dos projetos na instância. Selecione o projeto que pode ter acesso a esta associação.
Use esta opção juntamente com as seguintes autorizações para delegar a gestão de associações e a configuração de modelos:
Dialeto
O dialeto de SQL que corresponde à ligação. É importante escolher o valor correto para ver as opções de ligação adequadas e para o Looker poder converter corretamente o seu LookML em SQL.
ID do projeto de faturação
Apenas para ligações do Google BigQuery, o ID do projeto de faturação é o Google Cloud ID do projeto.
Anfitrião
O nome de anfitrião da base de dados que o Looker deve usar para estabelecer ligação ao anfitrião da base de dados.
Se trabalhou com um analista do Looker para configurar um túnel SSH para a sua base de dados, no campo Anfitrião, introduza "localhost".
Porta
A porta da base de dados que o Looker deve usar para estabelecer ligação ao anfitrião da base de dados.
Se trabalhou com um analista do Looker para configurar um túnel SSH para a sua base de dados, no campo Porta, introduza o número da porta que redireciona para a sua base de dados, que o analista do Looker lhe deve ter fornecido.
Bases de dados
O nome da base de dados no anfitrião. Por exemplo, pode ter um nome do anfitrião de my-instance.us-east-1.redshift.amazonaws.com no qual existe uma base de dados denominada sales_info. Introduziria sales_info neste campo. Se tiver várias bases de dados no mesmo anfitrião, pode ter de criar várias ligações para as usar (com exceção do MySQL, em que a palavra base de dados significa algo ligeiramente diferente do que na maioria dos dialetos SQL).
Esquema
O esquema predefinido que o Looker usa quando não é especificado um esquema. Isto aplica-se quando usa a execução de SQL, durante a geração do projeto do LookML e quando consulta tabelas.
Autenticação
Para as ligações Google BigQuery, Snowflake, Trino e Databricks, selecione o tipo de autenticação que quer que o Looker use para aceder à sua base de dados:
- Para associações do Google BigQuery, tem a opção de configurar o OAuth ou uma conta de serviço para o Looker usar para autenticar na sua base de dados.
- Para as ligações do Snowflake, Trino e Databricks, tem a opção de configurar o OAuth ou uma conta de base de dados para o Looker usar na autenticação na sua base de dados.
Quando usa o OAuth, os utilizadores têm de iniciar sessão na base de dados para emitir consultas do Looker. Para mais informações sobre a configuração do OAuth numa associação ao Looker, consulte os procedimentos de associação do Google BigQuery, Snowflake, Trino ou Databricks.
Nome de utilizador
O nome de utilizador de uma conta de utilizador na sua base de dados que o Looker pode usar para estabelecer ligação à base de dados.
Palavra-passe
A palavra-passe de uma conta de utilizador na sua base de dados que o Looker pode usar para estabelecer ligação à base de dados.
Definições opcionais
Servidor SSH
A opção Servidor SSH só está disponível se a instância estiver implementada na infraestrutura do Kubernetes e se a capacidade de adicionar informações de configuração do servidor SSH à sua instância do Looker tiver sido ativada. Se esta opção não estiver ativada na sua instância do Looker e quiser ativá-la, contacte um Google Cloud especialista de vendas ou abra um pedido de apoio técnico.
O servidor SSH escolhe automaticamente a porta de anfitrião local para si e não é possível especificar a porta de anfitrião local. Se precisar de criar uma ligação SSH que exija que especifique uma porta localhost, abra um pedido de apoio técnico.
Para estabelecer ligação à sua base de dados através de um túnel SSH, ative o botão e selecione uma configuração do servidor SSH na lista pendente.
Porta local
Por predefinição, o Looker seleciona automaticamente uma porta local disponível para o túnel SSH. Para escolher manualmente uma porta local, selecione Entrada manual e introduza um número de porta no campo Porta local personalizada. Certifique-se de que a porta local está disponível na sua instância.
Tabelas derivadas persistentes (PDTs)
Ativar PDTs
Ative o botão Ativar PDTs para ativar as tabelas derivadas persistentes. Quando as PDTs estão ativadas, a janela Associação revela campos de PDTs adicionais e a secção Substituições de PDTs. O Looker apresenta o botão Ativar PDTs apenas se o dialeto da base de dados suportar a utilização de PDTs.
Tenha em atenção o seguinte acerca das PDTs:
- As PDTs não são suportadas para associações ao Snowflake que usam o OAuth.
- A desativação dos PDTs numa associação não desativa os grupos de dados associados aos seus PDTs. Mesmo que desative os PDTs, os grupos de dados existentes continuam a executar as respetivas consultas
sql_triggerna base de dados. Se quiser impedir que um grupo de dados execute a respetiva consultasql_triggerna sua base de dados, tem de eliminar ou comentar o parâmetrodatagroupdo seu projeto LookML. Em alternativa, pode atualizar a definição Agenda de manutenção de grupos de dados e PDTs para a ligação, de modo que o Looker verifique os PDTs e os grupos de dados com pouca frequência ou nunca. - Para as ligações Snowflake, o Looker define o valor do parâmetro
AUTOCOMMITcomoTRUE(o valor predefinido do Snowflake).AUTOCOMMITé necessário para os comandos SQL que o Looker executa para manter o respetivo sistema de registo de PDT.
Base de dados temporária
Embora tenha a etiqueta de Base de dados temporária, vai introduzir o nome da base de dados ou o nome do esquema, conforme adequado para o dialeto SQL, que o Looker deve usar para criar tabelas derivadas persistentes. Deve configurar esta base de dados ou esquema antecipadamente, com as autorizações de escrita adequadas. Na página de documentação Instruções de configuração da base de dados, selecione o dialeto da base de dados para ver as instruções desse dialeto.
Cada ligação tem de ter um esquema ou uma base de dados temporária próprios, uma vez que não podem ser partilhados entre ligações.
Número máximo de ligações do compilador de PDTs
A definição Número máximo de ligações de compilador de PDTs permite-lhe especificar quantas compilações de tabelas simultâneas o gerador do Looker pode iniciar na ligação da base de dados. A definição Número máximo de ligações de compilador de PDTs aplica-se apenas aos tipos de tabelas para os quais o regenerador do Looker inicia reconstruções:
- Tabelas de acionador persistentes (tabelas derivadas persistentes e tabelas agregadas que usam a estratégia de persistência
datagroup_triggerousql_trigger_value). - Tabelas persistentes que usam a estratégia
persist_for, mas apenas quando a tabelapersist_forfaz parte de uma cascata de tabelas derivadas em que depende de uma tabela que usa a estratégia de persistênciadatagroup_triggerousql_trigger_value. Neste caso, o regenerador do Looker vai reconstruir uma tabelapersist_for, uma vez que a tabela é necessária para reconstruir outra tabela na cascata. Caso contrário, o regenerador não inicia compilações para tabelaspersist_for.
A definição Número máximo de ligações do compilador de PDTs está predefinida como 1, mas pode ser definida até 10. No entanto, o valor não pode ser superior ao valor definido no campo Máximo de ligações por nó ou no per-user-query-limit definido nas opções de arranque do Looker.
Defina este valor com cuidado. Se o valor for demasiado elevado, pode sobrecarregar a base de dados. Se o valor for baixo, as PDTs de execução prolongada ou as tabelas agregadas podem atrasar a criação de outras tabelas persistentes ou tornar outras consultas na ligação mais lentas. As bases de dados que suportam a multi-posse, como o BigQuery, o Snowflake e o Redshift, podem ter um melhor desempenho no processamento de compilações de consultas paralelas.
Se quiser aumentar a definição Número máximo de ligações de compilador de PDTs, uma boa regra geral é aumentá-la em 1. Se ocorrer algum comportamento inesperado, defina-o novamente para o valor predefinido de 1. Caso contrário, se o desempenho das consultas não for afetado, pode continuar a aumentá-lo gradualmente em 1 e verificar o desempenho em cada incremento antes de aumentar ainda mais a definição.
Tenha em atenção o seguinte acerca da definição Número máximo de ligações de compilador de PDTs:
- A definição Número máximo de ligações do compilador de PDTs aplica-se apenas às ligações necessárias para a reconstrução de tabelas e não às ligações necessárias para verificações de acionadores. Uma verificação de acionador é uma consulta que verifica se a estratégia de persistência da tabela é acionada. Uma vez que estas consultas de verificação de acionador são sempre executadas sequencialmente, a definição Número máximo de ligações do compilador de PDT não se aplica.
- Numa instância do Looker agrupada, o regenerador é executado apenas no nó principal. A definição Número máximo de ligações de compilador de PDTs aplica-se apenas ao nó principal e, por isso, define o limite para todo o cluster.
- A definição Número máximo de ligações de compilador de PDTs não se aplica aos seguintes tipos de tabelas. Estes tipos de tabelas são criados consecutivamente:
- Tabelas mantidas através do parâmetro
persist_for(a menos que a tabela dependa de tabelas que usam as estratégiasdatagroup_triggerousql_trigger_value). - Tabelas no modo de programação.
- Tabelas recompiladas com a opção Recompilar tabelas derivadas e executar.
- Tabelas em que uma depende da outra numa cascata de dependências. Não é possível criar uma tabela ao mesmo tempo que uma tabela da qual depende. Por exemplo, se
table_Bdepender detable_A,table_Atem de terminar a recriação antes detable_Bpoder começar a recriação.
- Tabelas mantidas através do parâmetro
Agendamento de manutenção de grupos de dados e PDTs
O regenerador do Looker verifica os grupos de dados e as tabelas persistentes (tabelas agregadas e tabelas derivadas persistentes) baseadas em sql_trigger_value. Com base nestas verificações, o regenerador do Looker recompila ou elimina tabelas persistentes do esquema de rascunho da sua base de dados.
O valor Agendamento de manutenção de grupos de dados e PDTs define o intervalo cron para o regenerador do Looker. O regenerador do Looker inicia um ciclo de regeneração para verificar os grupos de dados e as tabelas persistentes no intervalo cron. Se um ciclo do regenerador do Looker ainda estiver em curso no intervalo de cron seguinte, o regenerador do Looker conclui o ciclo do regenerador em curso e, em seguida, aguarda até ao intervalo de cron subsequente para iniciar o ciclo do regenerador seguinte.
A definição Agendamento de manutenção de grupos de dados e PDTs aceita uma expressão cron. O valor predefinido é */5 * * * *, o que significa que o ciclo do regenerador do Looker inicia um ciclo no intervalo de cinco minutos, se o ciclo do regenerador anterior tiver sido concluído. Se o ciclo do regenerador anterior não tiver sido concluído, o regenerador do Looker é iniciado no intervalo de cinco minutos seguinte após a conclusão do ciclo.
O valor predefinido de cinco minutos também é o intervalo mais frequente suportado para o agendamento de manutenção de grupos de dados e PDTs. O Looker não aplica um intervalo máximo para o agendamento de manutenção de grupos de dados e PDTs, o que significa que pode prolongar o intervalo entre os ciclos de regeneração do Looker durante o tempo que puder ser especificado por uma expressão cron. Tenha em atenção que os ciclos de regeneração do Looker mais longos podem afetar negativamente a atualização dos dados na cache e nas tabelas persistentes.
Depois de o regenerador do Looker concluir todas as verificações e as reconstruções de PDT num ciclo, aguarda o intervalo cron seguinte para iniciar o ciclo seguinte. Se tiver compilações de PDTs de execução prolongada, pode ter longos períodos entre ciclos de regeneração do Looker. Outros fatores podem afetar o tempo necessário para reconstruir as tabelas, conforme descrito na secção Considerações importantes para implementar tabelas persistentes na página Tabelas derivadas no Looker.
Se a sua base de dados não estiver disponível 24 horas por dia, 7 dias por semana, é recomendável limitar as verificações aos momentos em que a base de dados está disponível. Seguem-se algumas expressões cron adicionais:
cron expressão |
Definição |
|---|---|
*/5 8-17 * * MON-FRI |
Verifique os grupos de dados e os PDTs a cada 5 minutos durante o horário de funcionamento, de segunda a sexta-feira |
*/5 8-17 * * * |
Verificar grupos de dados e PDTs a cada 5 minutos durante o horário de funcionamento, todos os dias |
0 8-17 * * MON-FRI |
Verificar grupos de dados e PDTs a cada hora durante o horário de funcionamento, de segunda a sexta-feira |
1 3 * * * |
Verificar grupos de dados e PDTs todos os dias às 03:01 |
Alguns aspetos a ter em conta quando cria uma expressão cron:
- O Looker usa o parse-cron v0.1.3, que não suporta
?em expressõescron. - A expressão
cronusa o fuso horário da aplicação do Looker para determinar quando são feitas as verificações. - Se as PDTs não estiverem a ser criadas, reponha a string cron para a predefinição de
*/5 * * * *.
Seguem-se alguns recursos que ajudam a criar strings cron:
- https://crontab.guru: ajuda a editar e testar strings
cron. - http://www.crontab-generator.org: selecione as definições de tempo e o gerador cria a string
croncorrespondente.
Repetir compilações de PDTs falhadas
O botão Repetir compilações de PDTs falhadas configura a forma como o regenerador do Looker tenta recompilar tabelas persistentes acionadas que falharam no ciclo do regenerador anterior. O regenerador do Looker é o processo que recompila tabelas persistentes acionadas (PDTs e tabelas agregadas) de acordo com o intervalo configurado na definição de ligação Agendamento de manutenção de grupos de dados e PDTs. Quando o botão Repetir compilações de PDTs falhadas está ativado, o regenerador do Looker tenta recompilar uma PDT que falhou no ciclo do regenerador anterior, mesmo que a condição de acionamento da PDT não seja cumprida. Quando esta definição está desativada, o regenerador do Looker tenta recompilar uma PDT com falhas anteriores apenas quando a condição de acionamento da PDT é cumprida. A opção Repetir compilações de PDTs falhadas está desativada por predefinição.
Consulte a página de documentação Tabelas derivadas no Looker para ver mais informações sobre o regenerador do Looker.
Controlo da API PDT
O botão Controlo da API PDT determina se as chamadas API start_pdt_build, check_pdt_build e stop_pdt_build podem ser usadas para esta associação. Quando o botão Controlo da API PDT está desativado, estas chamadas API falham quando fazem referência a PDTs nesta ligação. O botão Controlo da API PDT está desativado por predefinição.
Substituições de PDTs
Se a sua base de dados suportar tabelas derivadas persistentes e tiver ativado o botão Ativar PDTs nas definições de ligação, o Looker apresenta a secção Substituições de PDTs. Na secção Substituições de PDT, pode introduzir parâmetros JDBC separados (anfitrião, porta, base de dados, nome de utilizador, palavra-passe, esquema, parâmetros adicionais e declarações após a ligação) específicos para processos de PDT. Isto pode ser valioso por vários motivos:
- Ao criar um utilizador da base de dados separado para processos PDT, pode usar PDTs no seu projeto do Looker, mesmo que atribua atributos de utilizador às suas credenciais de início de sessão na base de dados ou use o OAuth para a ligação à base de dados.
- Os processos PDT podem ser autenticados através de um utilizador da base de dados separado com uma prioridade mais elevada. Desta forma, a base de dados pode dar prioridade às tarefas PDT em detrimento das consultas de utilizadores menos críticas.
- O acesso de escrita pode ser revogado para a associação padrão da base de dados do Looker e concedido apenas a um utilizador especial que os processos de PDT vão usar para autenticação. Esta é uma melhor estratégia de segurança para a maioria das organizações.
- Para bases de dados como o Snowflake, os processos de PDT podem ser encaminhados para hardware mais potente que não é partilhado com os restantes utilizadores do Looker. Desta forma, os PDTs podem ser criados rapidamente sem incorrer no custo de execução de hardware dispendioso a tempo inteiro.
Por exemplo, a configuração seguinte mostra uma associação em que os campos de nome de utilizador e palavra-passe estão definidos como atributos do utilizador. Desta forma, cada utilizador pode aceder à base de dados através das respetivas credenciais individuais. A secção Substituições de PDT cria um utilizador separado (pdt_user) com a sua própria palavra-passe. A conta pdt_user vai ser usada para todos os processos da PDT, com níveis de acesso adequados à criação e atualização da PDT.
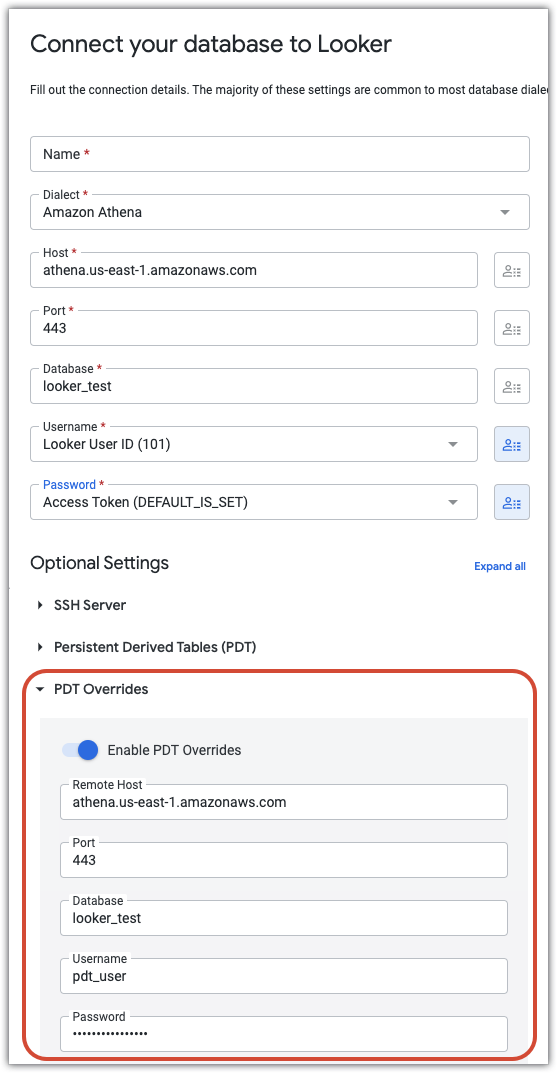
Fuso horário
Fuso horário da base de dados
O fuso horário no qual a base de dados armazena informações baseadas no tempo. O Looker precisa de saber isto para poder converter valores de tempo para os utilizadores, o que facilita a compreensão e a utilização de dados baseados no tempo. Consulte a página de documentação Usar definições de fuso horário para mais informações.
Fuso horário da consulta
A opção Fuso horário da consulta só é visível se tiver desativado os fusos horários específicos do utilizador.
Quando os fusos horários específicos do utilizador estão desativados, o fuso horário da consulta é o fuso horário apresentado aos utilizadores quando consultam dados baseados na hora, e o fuso horário para o qual o Looker converte dados baseados na hora do fuso horário da base de dados.
Consulte a página de documentação Usar definições de fuso horário para mais informações.
Definições adicionais
Parâmetros JDBC adicionais
Se necessário, pode incluir aqui outros parâmetros Java Database Connectivity (JDBC) para as suas consultas.
Para fazer referência a um atributo do utilizador num parâmetro JDBC, use a sintaxe de modelos Liquid: _user_attributes['name_of_attribute']. Por exemplo:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Máximo de ligações por nó
Aqui, pode definir o número máximo de ligações que o Looker pode estabelecer com a sua base de dados. Na maioria dos casos, está a definir o número de consultas simultâneas que o Looker pode executar na sua base de dados. O Looker também reserva até três associações para a eliminação de consultas. Se o conjunto de ligações for muito pequeno, o Looker reserva menos ligações.
Defina este valor com cuidado. Se o valor for demasiado elevado, pode sobrecarregar a base de dados. Se o valor for demasiado baixo, as consultas têm de partilhar um pequeno número de ligações. Assim, muitas consultas podem parecer lentas aos utilizadores, pois têm de aguardar a devolução de outras consultas anteriores.
O valor predefinido (que varia consoante o seu dialeto de SQL) é normalmente um ponto de partida razoável. A maioria das bases de dados também tem as suas próprias definições para o número máximo de ligações que aceitam. Se a configuração da base de dados limitar as ligações, certifique-se de que o valor de Ligações máximas por nó é igual ou inferior ao limite da base de dados.
Limite de tempo do conjunto de ligações
Se os seus utilizadores pedirem mais ligações do que a definição Max Connections per node, os pedidos vão aguardar que outros terminem antes de serem executados. Aqui, configura o período máximo de tempo que um pedido vai esperar. A predefinição é de 120 segundos.
Deve definir este valor com cuidado. Se for demasiado baixo, os utilizadores podem ver as respetivas consultas canceladas porque não existe tempo suficiente para que as consultas de outros utilizadores terminem. Se for demasiado elevado, podem acumular-se um grande número de consultas, o que faz com que os utilizadores esperem muito tempo. Normalmente, o valor predefinido é um ponto de partida razoável.
Máximo de consultas simultâneas para esta ligação
Este valor opcional limita o número de consultas simultâneas que o Looker envia para esta ligação da base de dados de uma só vez. Se chegarem mais pedidos simultâneos a exigir a mesma ligação, o Looker coloca-os em fila internamente e processa-os por ordem. A definição deste valor substitui um valor Max connections per node existente.
Máximo de consultas simultâneas por utilizador para esta ligação
Este valor opcional limita o número de consultas simultâneas que o Looker envia para esta ligação à base de dados de uma só vez. Se chegarem mais pedidos simultâneos a exigir a mesma ligação, o Looker coloca-os em fila internamente e processa-os por ordem.
SSL
Escolha se quer ou não usar a encriptação SSL para proteger os dados à medida que são transferidos entre o Looker e a sua base de dados. O SSL é apenas uma opção que pode ser usada para proteger os seus dados. Outras opções seguras são descritas na página de documentação Ativar o acesso seguro à base de dados.
Validar SSL
Escolha se quer exigir a validação do certificado SSL usado pela ligação. Se for necessária a validação, a autoridade de certificação (AC) SSL que assinou o certificado SSL tem de constar da lista de origens fidedignas do cliente. Se a AC não for uma origem fidedigna, a ligação à base de dados não é estabelecida.
Se esta caixa não estiver selecionada, a encriptação SSL continua a ser usada na ligação, mas a validação da ligação SSL não é necessária. Por isso, é possível estabelecer uma ligação quando a AC não está na lista de origens fidedignas do cliente.
Pré-cache da execução de SQL
Na execução de SQL, todas as informações das tabelas são pré-carregadas assim que seleciona uma ligação e um esquema. Isto permite que o SQL Runner apresente rapidamente as colunas da tabela assim que clicar no nome de uma tabela. No entanto, para associações e esquemas com muitas tabelas ou tabelas muito grandes, pode não querer que o SQL Runner pré-carregue todas as informações.
Se preferir que o SQL Runner carregue as informações da tabela apenas quando uma tabela é selecionada, pode desmarcar a opção SQL Runner Precache para desativar o pré-carregamento do SQL Runner para a ligação.
Obtenha o esquema de informações para escrita SQL
Para algumas funcionalidades de escrita de SQL, como a consciência de agregação, o Looker usa o esquema de informações da sua base de dados para otimizar a escrita de SQL. Se o esquema de informações não estiver em cache, o Looker pode ter de bloquear ocasionalmente a escrita de SQL na base de dados para poder obter o esquema de informações. Para dialetos que usam o Hadoop Distributed File System (HDFS), a obtenção do esquema de informações pode demorar o suficiente para afetar significativamente o desempenho das suas consultas do Looker. Se souber que o seu esquema de informações é lento, pode desativar a opção Obter esquema de informações para escrita SQL para a sua ligação. Se desativar esta funcionalidade, impede a otimização de SQL do Looker para determinadas funcionalidades. Por isso, deve ativar a opção Obter esquema de informações para escrita SQL, a menos que saiba que o esquema de informações da sua ligação é particularmente lento.
Estimativa de custos
O botão Estimativa de custos aplica-se apenas às seguintes ligações à base de dados:
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL para PostgreSQL e Microsoft Azure PostgreSQL
O botão Estimativa de custos ativa as seguintes funcionalidades na associação:
- Estimativas de custos para consultas de exploração
- Estimativas de custos para consultas do SQL Runner
- Cálculo das estimativas de poupança para consultas de notoriedade agregadas
Consulte a página de documentação Explorar dados no Looker para mais informações.
Agrupamento de ligações da base de dados
Para dialetos que suportam o agrupamento de ligações à base de dados, esta funcionalidade permite que o Looker use conjuntos de ligações através do controlador JDBC. A partilha de ligações à base de dados permite um desempenho mais rápido das consultas. Uma nova consulta não precisa de criar uma nova ligação à base de dados, mas pode usar uma ligação existente da partilha de ligações. A capacidade de agrupamento de ligações garante que uma ligação é limpa após a execução de uma consulta e está disponível para reutilização após o fim da execução da consulta. Consulte a página de documentação Pool de ligações à base de dados para mais informações.
Testar as definições de ligação
Pode testar as definições de ligação a partir de alguns locais na IU do Looker:
- Selecione o botão Testar na parte inferior da página Definições de associações.
- Selecione o botão Testar junto à ficha da associação na página de administração Associações, conforme descrito na página de documentação Associações.
Depois de introduzir as definições de associação, clique em Testar para verificar se as informações estão corretas e se a base de dados consegue estabelecer ligação.
Se a sua ligação não passar um ou mais testes, seguem-se algumas opções de resolução de problemas:
- Experimente alguns dos passos de resolução de problemas na página de documentação Testar a conetividade da base de dados.
- Se estiver a executar a versão 3.6 ou anterior do Mongo no Atlas e receber uma falha de ligação de comunicações, consulte a página de documentação do conector do Mongo.
- Para receber mensagens de ligação bem-sucedida relativamente ao esquema temporário e aos PDTs, tem de permitir essa funcionalidade quando configurar a base de dados do Looker. Pode encontrar instruções para o fazer na página de documentação Instruções de configuração da base de dados.
Se continuar a ter problemas, abra um pedido de apoio técnico.
Teste como utilizador
Se tiver definido um ou mais valores de parâmetros de ligação para um atributo do utilizador, é apresentada a opção Testar como utilizador. Selecione um utilizador e, em seguida, clique em Testar para verificar se a base de dados consegue estabelecer ligação e executar consultas como este utilizador.
Passos seguintes
Depois de associar a base de dados ao Looker, pode configurar as opções de início de sessão para os utilizadores.