本主题介绍如何将 GKE on AWS 用户集群的日志和指标导出到 Cloud Logging 和 Cloud Monitoring。
概览
GKE on AWS 有多个日志记录和监控选项。GKE Enterprise 可与 Cloud Logging 和 Cloud Monitoring 集成。由于 GKE Enterprise 基于开源 Kubernetes,因此许多开源工具和第三方工具都兼容。
日志记录和监控选项
您可将多个日志记录和监控选项用于 GKE Enterprise 集群:
部署 Cloud Logging 和 Cloud Monitoring 代理,以在 Google Cloud 控制台中监控和查看来自工作负载的日志。本主题介绍了此解决方案。
使用 Prometheus、Grafana 和 Elasticsearch 等开源工具。本主题未介绍此解决方案。
使用第三方解决方案,如 Datadog。本主题未介绍此解决方案。
Cloud Logging 和 Cloud Monitoring
借助 GKE Enterprise、Cloud Logging 和 Cloud Monitoring,您可以为集群上运行的工作负载创建信息中心、发送提醒、监控和查看日志。必须配置 Cloud Logging 和 Cloud Monitoring 代理以将日志和指标收集到您的 Google Cloud项目中。如果您未配置这些代理,GKE on AWS 就不会收集日志记录或监控数据。
收集哪些数据
配置完成后,代理会从集群以及集群上运行的工作负载收集日志和指标数据。这些数据会存储在您的Google Cloud 项目中。安装日志转发器时,您需要在配置文件的 project_id 字段中配置项目 ID。
收集的数据包括以下各项:
- 每个工作器节点上的系统服务日志。
- 集群上运行的所有工作负载的应用日志。
- 集群和系统服务的指标。如需详细了解特定指标,请参阅 GKE Enterprise 指标。
- Pod 的应用指标(如果您的应用配置了 Prometheus 抓取目标,并且包括
prometheus.io/scrape、prometheus.io/path和prometheus.io/port等配置的注释)。
您可以随时停用这些代理。如需了解详情,请参阅清理。 代理收集的数据可以像任何其他指标和日志数据一样进行管理和删除,如 Cloud Monitoring 和 Cloud Logging 文档中所述。
日志数据会按照您配置的保留规则进行存储。指标数据保留因类型而异。
日志记录和监控组件
如需将 GKE on AWS 中的集群级遥测导出到Google Cloud,请将以下组件部署到集群中:
- Stackdriver Log Forwarder (stackdriver-log-forwarder-*)。一个 Fluentbit DaemonSet,用于将每个 Kubernetes 节点的日志转发到 Cloud Logging。
- GKE Metrics Agent (gke-metrics-agent-*)。一个基于 OpenTelemetry 收集器的 DaemonSet,用于收集指标数据并将其转发到 Cloud Monitoring。
这些组件的清单位于 GitHub 上的 anthos-samples 代码库中。
前提条件
启用了结算功能的 Google Cloud 项目。如需详细了解费用,请参阅 Google Cloud Observability 的价格。
该项目还必须启用 Cloud Logging 和 Cloud Monitoring API。 如需启用这些 API,请运行以下命令:
gcloud services enable logging.googleapis.com gcloud services enable monitoring.googleapis.comGKE on AWS 环境,包括向 Connect 注册的用户集群。运行以下命令来验证集群是否已注册。
gcloud container fleet memberships list如果集群已注册,Google Cloud CLI 会输出集群的名称和 ID。
NAME EXTERNAL_ID cluster-0 1abcdef-1234-4266-90ab-123456abcdef如果没有看到您的集群,请参阅使用 Connect 连接到集群。
在机器上安装
git命令行工具。
为 Google Cloud Observability 设置权限
日志记录和监控代理使用 Fleet Workload Identity 与 Cloud Logging 和 Cloud Monitoring 进行通信。该身份需要具备在项目中写入日志和指标的权限。如需添加权限,请运行以下命令:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/logging.logWriter
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/monitoring.metricWriter
将 PROJECT_ID 替换为您的 Google Cloud 项目。
连接到堡垒主机
如需连接到 GKE on AWS 资源,请执行以下步骤。选择您是拥有现有 AWS VPC(或者与 VPC 的直接连接)还是在创建管理服务时创建了专用 VPC。
现有 VPC
如果您拥有与现有 VPC 的直接连接或 VPN 连接,请省略本主题的命令中的行 env HTTP_PROXY=http://localhost:8118。
专用 VPC
如果您在专用 VPC 中创建管理服务,则 GKE on AWS 会在公共子网中添加一个堡垒主机。
如需连接到您的管理服务,请执行以下步骤:
切换到您的 GKE on AWS 配置所在的目录。 您在安装管理服务时创建了此目录。
cd anthos-aws
要打开隧道,请运行
bastion-tunnel.sh脚本。隧道会转发到localhost:8118。如需打开堡垒主机的隧道,请运行以下命令:
./bastion-tunnel.sh -N来自 SSH 隧道的消息会显示在此窗口中。准备好关闭连接后,请使用 Control+C 或关闭窗口来停止该进程。
打开新终端并切换到您的
anthos-aws目录。cd anthos-aws
检查您是否能够使用
kubectl连接到集群。env HTTPS_PROXY=http://localhost:8118 \ kubectl cluster-info输出包括管理服务 API 服务器的网址。
控制平面节点上的 Cloud Logging 和 Cloud Monitoring
使用 GKE on AWS 1.8.0 及更高版本,可以在创建新用户集群时自动配置控制平面节点的 Cloud Logging 和 Cloud Monitoring。如需启用 Cloud Logging 或 Cloud Monitoring,您需要填充 AWSCluster 配置的 controlPlane.cloudOperations 部分。
cloudOperations:
projectID: PROJECT_ID
location: GC_REGION
enableLogging: ENABLE_LOGGING
enableMonitoring: ENABLE_MONITORING
请替换以下内容:
PROJECT_ID:您的项目 ID。GC_REGION:您要在其中存储日志的 Google Cloud 区域。选择 AWS 区域附近的区域。如需了解详情,请参阅全球位置 - 区域和可用区(例如us-central1)。ENABLE_LOGGING:true或false,表示是否在控制平面节点上启用 Cloud Logging。ENABLE_MONITORING:true或false,表示是否在控制平面节点上启用 Cloud Monitoring。
接下来,按照创建自定义用户集群中的步骤操作。
工作器节点上的 Cloud Logging 和 Cloud Monitoring
移除先前版本
如果您设置的早期版本的日志记录和监控代理包含 stackdriver-log-aggregator (Fluentd) 和 stackdriver-prometheus-k8s (Prometheus),则建议先将其卸载,然后再继续操作。
安装日志记录转发器
在本部分中,您将在您的集群上安装 Stackdriver Log Forwarder。
从
anthos-samples/aws-logging-monitoring/目录转到logging/目录。cd logging/修改文件
forwarder.yaml以与您的项目配置匹配:sed -i "s/PROJECT_ID/PROJECT_ID/g" forwarder.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" forwarder.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" forwarder.yaml请替换以下内容:
PROJECT_ID:您的项目 ID。CLUSTER_NAME:您的集群的名称,例如cluster-0GC_REGION:您要在其中存储日志的 Google Cloud 区域。选择 AWS 区域附近的区域。如需了解详情,请参阅全球位置 - 区域和可用区(例如us-central1)。
(可选)根据您的工作负载、集群中的节点数和每个节点的 Pod 数,您可能需要设置内存和 CPU 资源请求。如需了解详情,请参阅建议的 CPU 和内存分配。
在
anthos-aws目录中,使用anthos-gke将上下文切换到用户集群。cd anthos-aws env HTTPS_PROXY=http://localhost:8118 \ anthos-gke aws clusters get-credentials CLUSTER_NAME
创建
stackdriver服务账号(如果不存在),并将日志转发器部署到集群。env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f forwarder.yaml使用
kubectl验证 Pod 是否已启动。env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep stackdriver-log您应该会在节点池中看到每个节点有一个转发器 pod。例如,在一个包含 6 个节点的集群中,您应该会看到 6 个转发器 pod。
stackdriver-log-forwarder-2vlxb 2/2 Running 0 21s stackdriver-log-forwarder-dwgb7 2/2 Running 0 21s stackdriver-log-forwarder-rfrdk 2/2 Running 0 21s stackdriver-log-forwarder-sqz7b 2/2 Running 0 21s stackdriver-log-forwarder-w4dhn 2/2 Running 0 21s stackdriver-log-forwarder-wrfg4 2/2 Running 0 21s
测试日志转发
在本部分中,您将包含基本 HTTP Web 服务器和负载生成器的工作负载部署到集群。然后,您可以测试 Cloud Logging 中是否存在日志。
在安装此工作负载之前,您可以验证 Web 服务器和负载生成器的清单。
将 Web 服务器和负载生成器部署到您的集群。
env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yaml如需验证您是否可以在 Cloud Logging 信息中心内查看来自集群的日志,请前往 Google Cloud 控制台中的 Logs Explorer:
将以下示例查询复制到查询构建器字段中。
resource.type="k8s_container" resource.labels.cluster_name="CLUSTER_NAME"将 CLUSTER_NAME 替换为您的集群名称。
点击运行查询。您应该会在查询结果下方看到最近的集群日志。
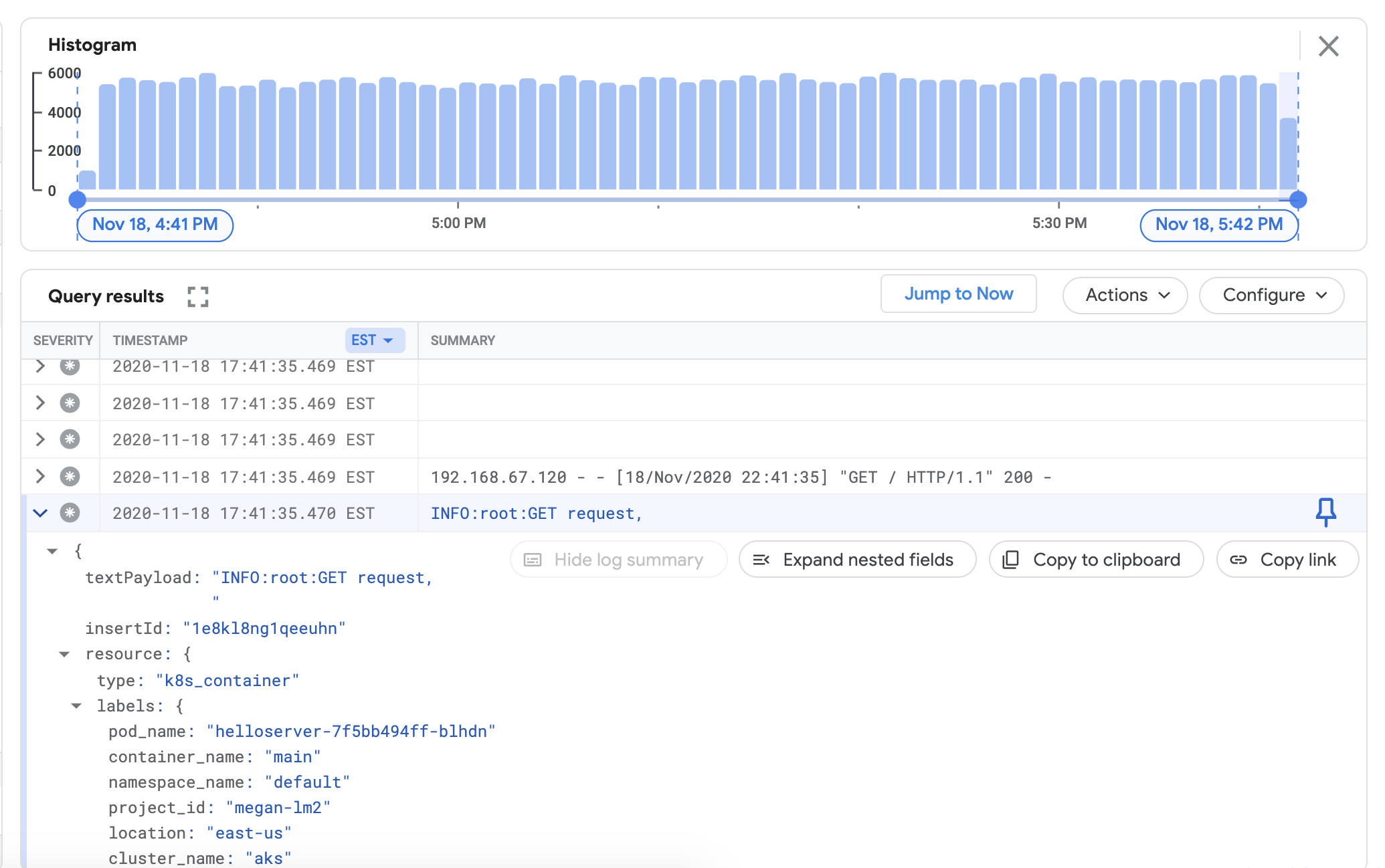
确认日志显示在查询结果后,移除加载生成器和 Web 服务器。
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml
安装指标收集器
在本部分中,您将安装代理以将数据发送到 Cloud Monitoring。
从
anthos-samples/aws-logging-monitoring/logging/目录转到anthos-samples/aws-logging-monitoring/monitoring/目录。cd ../monitoring修改文件
gke-metrics-agent.yaml以与您的项目配置匹配:sed -i "s/PROJECT_ID/PROJECT_ID/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" gke-metrics-agent.yaml请替换以下内容:
PROJECT_ID:您的项目 ID。CLUSTER_NAME:您的集群的名称,例如cluster-0GC_REGION:您要在其中存储日志的 Google Cloud 区域。选择 AWS 区域附近的区域。如需了解详情,请参阅全球位置 - 区域和可用区(例如us-central1)。
(可选)根据您的工作负载、集群中的节点数和每个节点的 Pod 数,您可能需要设置内存和 CPU 资源请求。如需了解详情,请参阅建议的 CPU 和内存分配。
创建
stackdriver服务账号(如果不存在),并将指标代理部署到您的集群。env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f gke-metrics-agent.yaml使用
kubectl工具验证gke-metrics-agentpod 是否为运行状态。env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep gke-metrics-agent您应该会在节点池中看到每个节点有一个代理 pod。例如,在一个包含 3 个节点的集群中,您应该会看到 3 个代理 pod。
gke-metrics-agent-gjxdj 2/2 Running 0 102s gke-metrics-agent-lrnzl 2/2 Running 0 102s gke-metrics-agent-s6p47 2/2 Running 0 102s
如需验证集群指标是否导出到 Cloud Monitoring,请前往 Google Cloud 控制台中的 Metrics Explorer:
在 Metrics Explorer 中,点击查询编辑器,然后复制以下命令:
fetch k8s_container | metric 'kubernetes.io/anthos/otelcol_exporter_sent_metric_points' | filter resource.project_id == 'PROJECT_ID' && (resource.cluster_name =='CLUSTER_NAME') | align rate(1m) | every 1m请替换以下内容:
PROJECT_ID:您的项目 ID。CLUSTER_NAME:您在创建用户集群时使用的集群名称,例如cluster-0。
点击运行查询。系统会显示从集群中的每个
gke-metrics-agentpod 发送到 Cloud Monitoring 的指标点的速率。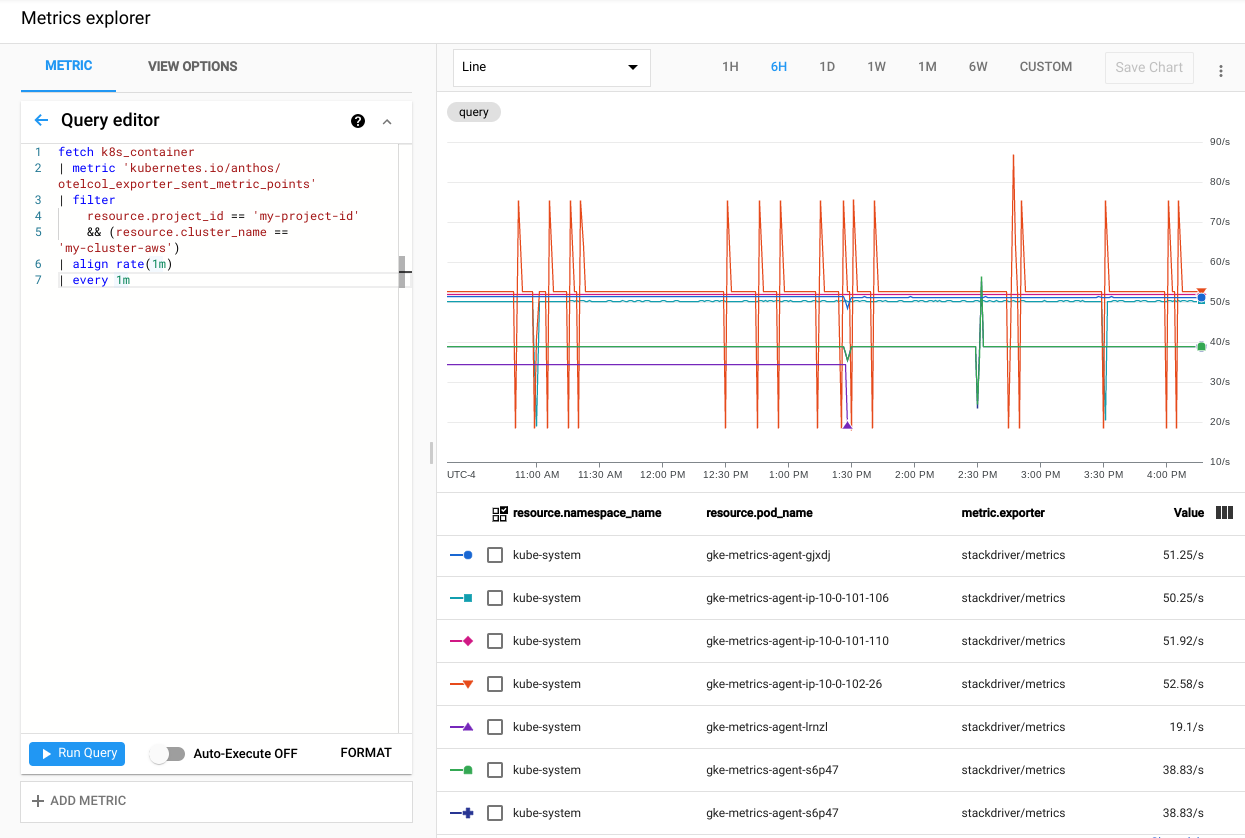
一些值得尝试的其他指标包括但不限于:
kubernetes.io/anthos/container_memory_working_set_bytes:容器内存用量;kubernetes.io/anthos/container_cpu_usage_seconds_total:容器 CPU 使用率;kubernetes.io/anthos/apiserver_aggregated_request_total:kube-apiserver 请求计数,仅在控制平面上启用 Cloud Monitoring 时可用。
如需查看可用指标的完整列表,请参阅 Anthos 指标。如需了解如何使用界面,请参阅 Metrics Explorer。
在 Cloud Monitoring 中创建信息中心
在本部分中,您将创建一个 Cloud Monitoring 信息中心,用于监控集群中的容器状态。
从
anthos-samples/aws-logging-monitoring/monitoring/目录转到anthos-samples/aws-logging-monitoring/monitoring/dashboards目录。cd dashboards将
pod-status.json中CLUSTER_NAME字符串的实例替换为您的集群名称。sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" pod-status.json将
CLUSTER_NAME替换为您的集群名称。运行以下命令,使用配置文件创建自定义信息中心:
gcloud monitoring dashboards create --config-from-file=pod-status.json如需验证您的信息中心是否已创建,请前往 Google Cloud 控制台中的 Cloud Monitoring 信息中心。
打开新创建的信息中心,其名称应为
CLUSTER_NAME (Anthos cluster on AWS) pod status。
清理
在本部分中,您将从集群移除日志记录和监控组件。
在Google Cloud 控制台中的“信息中心”列表视图中删除监控信息中心,方法是点击与该信息中心名称关联的删除按钮。
切换到
anthos-samples/aws-logging-monitoring/目录。cd anthos-samples/aws-logging-monitoring要移除本指南中创建的所有资源,请运行以下命令:
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f logging/ env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f monitoring/
建议的 CPU 和内存分配
本部分介绍了在日志记录和监控中使用的各个组件建议的 CPU 和分配。以下每个表格列出了具有各种节点大小的集群的 CPU 和内存请求。您可以在表中列出的文件中为组件设置资源请求。
如需了解详情,请参阅 Kubernetes 最佳做法:资源请求和限制以及管理容器的资源。
1-10 个节点
| 文件 | 资源 | CPU 请求 | CPU 上限 | 内存请求 | 内存限制 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 30 分钟 | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 50m | 100m | 100Mi | 600Mi |
10-100 个节点
| 文件 | 资源 | CPU 请求 | CPU 上限 | 内存请求 | 内存限制 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |
超过 100 个节点
| 文件 | 资源 | CPU 请求 | CPU 上限 | 内存请求 | 内存限制 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 100Mi | 不适用 |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |