このページでは、Kubernetes の CI / CD GitOps パイプラインの計画と設計を行う際の出発点となる情報を提供します。GitOps は、Config Sync などのツールとともに、コードの安定性、可読性、自動化の向上などのメリットを提供します。
GitOps は、Kubernetes 構成を大規模に管理するための、急速に成長しているアプローチです。CI / CD パイプラインの要件に応じて、アプリケーション コードと構成コードを設計して整理する方法は多数あります。GitOps のベスト プラクティスを学ぶことで、安定し、整理された安全なアーキテクチャを構築できます。
このページは、環境に GitOps を実装する管理者、アーキテクト、オペレーターを対象にしています。 Google Cloud のコンテンツで使用されている一般的なロールとタスクの例の詳細については、一般的な GKE ユーザーのロールとタスクをご覧ください。
リポジトリを整理する
GitOps アーキテクチャを設定するときは、各リポジトリに保存されている構成ファイルのタイプに基づいてリポジトリを分離します。大まかには、少なくとも 4 種類のリポジトリが必要になります。
- 関連する構成のグループ用のパッケージ リポジトリ。
- クラスタと Namespace のフリート全体の構成用のプラットフォーム リポジトリ。
- アプリケーション構成リポジトリ。
- アプリケーション コード リポジトリ。
次の図は、これらのリポジトリのレイアウトを示しています。
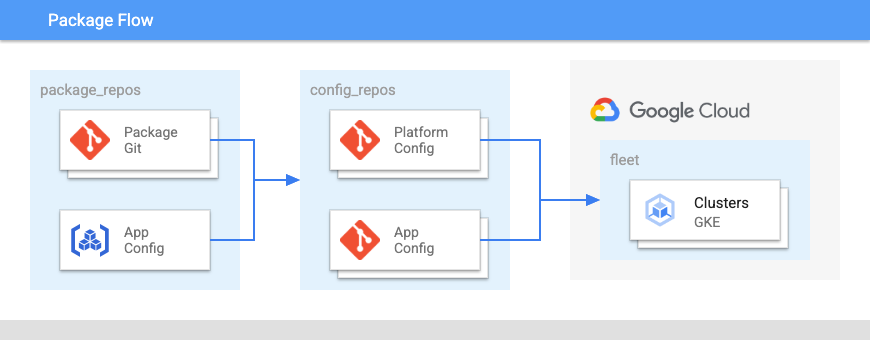
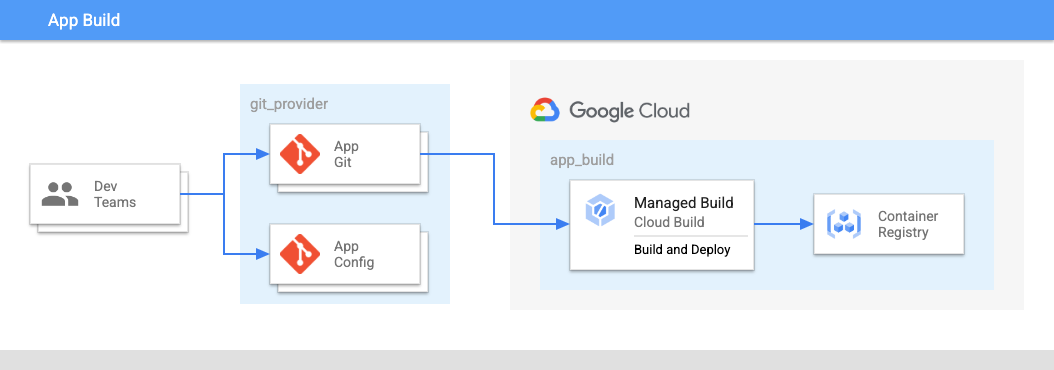
図 2 で:
- 開発チームは、アプリケーションとアプリケーション構成のコードをリポジトリに push します。
- アプリと構成ファイルの両方のコードが同じ場所に保存され、アプリケーション チームがこれらのリポジトリを管理できます。
- アプリケーション チームはコードをビルドに push します。
一元化されたプライベート パッケージ リポジトリを使用する
パブリック パッケージまたは内部パッケージ(Helm チャートなど)に中央リポジトリを使用して、チームがパッケージを見つけやすくします。たとえば、リポジトリが論理的に構造化されている場合や readme が含まれている場合は、一元化されたプライベート パッケージ リポジトリを使用すると、チームが情報をすばやく見つけることができます。Artifact Registry や Git リポジトリなどのサービスを使用して、中央リポジトリを整理できます。
たとえば、組織のプラットフォーム チームは、アプリケーション チームが中央リポジトリのパッケージのみを使用できるようにするポリシーを実装できます。
リポジトリへの書き込み権限を付与する対象は少数のエンジニアに限定できます。組織の他のメンバーには読み取りアクセス権を付与できます。パッケージを中央リポジトリにプロモートし、更新をブロードキャストするプロセスを実装することをおすすめします。
中央リポジトリを管理する場合、誰かが中央リポジトリを維持する必要があり、アプリケーション チームに新たなプロセスが追加されるため、オーバーヘッドが増加する可能性がありますが、このアプローチには多くのメリットがあります。
- 中央のチームは、決められた頻度でパブリック パッケージを追加できます。これにより、接続やアップストリームの離脱による中断を回避できます。
- 自動審査と人間による審査を組み合わせて、パッケージに問題がないか確認してから一般公開できます。
- 中央リポジトリを使用すると、チームは使用中のものとサポートされているものを確認できます。たとえば、チームは中央リポジトリに保存されている標準の Redis デプロイを見つけることができます。
- デフォルト値、ラベルの追加、コンテナ イメージ リポジトリなどの内部標準を満たすように、アップストリーム パッケージの変更を自動化できます。
WET リポジトリを作成する
WET は「Write Everything Twice(すべてを 2 回書き込む)」の略です。これは、「Don't Repeat Yourself」の略である DRY とは対照的です。これらのアプローチでは、次の 2 種類の構成ファイルを使用します。
- DRY 構成ファイル: 単一の構成ファイルが変換アクションを受け、環境ごとに異なる値がフィールドに入力されます。たとえば、環境ごとに異なるリージョンまたは異なるセキュリティ設定で挿入される共有クラスタ構成を使用できます。
- WET(または「完全にハイドレートされた」)構成。各構成ファイルが最終状態を表します。
WET リポジトリでは構成ファイルが重複する可能性がありますが、GitOps ワークフローには次のメリットがあります。
- チームメンバーが変更を確認しやすくなります。
- 構成ファイルの望ましい状態を確認するための処理は必要ありません。
構成の検証時に早期にテストする
Config Sync が同期を開始して問題をチェックするまで、不要な Git commit と長いフィードバック ループが発生する可能性があります。kpt バリデータの機能を使用すると、構成ファイルがクラスタに適用される前に、さまざまな問題が見つかる可能性があります。
構成を適用する前にテストを行うには、commit プロセスにツールとロジックを追加する必要がありますが、次のようなメリットがあります。
- 変更リクエストで構成の変更を表示すると、エラーがリポジトリに波及することを回避できます。
- 共有された構成の問題の影響を軽減できます。
ブランチではなくフォルダを使用する
構成ファイルのバリアントには、ブランチではなくフォルダを使用します。フォルダを使用すると、tree コマンドでバリアントを表示できます。ブランチを使用すると、本番環境ブランチと開発ブランチ間の差分が次の構成変更の対象なのか、prod 環境と dev 環境間に永続的な相違があるのかを判別できません。
このアプローチの主な欠点は、フォルダを使用すると、同じファイルに対する変更リクエストを使用して構成変更をプロモートできないことです。ただし、ブランチではなくフォルダを使用すると、次のような利点があります。
- ブランチよりもフォルダのほうが簡単に検出できます。
- 多くの CLI や GUI ツールでは、フォルダの差分を調べることは可能ですが、Git プロバイダ以外ではブランチの差分取得はあまり一般的ではありません。
- フォルダの場合は、永続的な違いとプロモートされていない違いをより簡単に区別できます。
- 1 つの変更リクエストで複数のクラスタと Namespace に変更をデプロイできます。ブランチの場合は、異なるブランチに対して複数の変更リクエストを行う必要があります。
ClusterSelectors の使用を最小限に抑える
ClusterSelectors を使用すると、構成の特定部分をクラスタのサブセットに適用できます。RootSync または RepoSync オブジェクトを構成する代わりに、適用されているリソースを変更したり、クラスタにラベルを追加できます。これはクラスタに特性を追加する簡単な方法ですが、ClusterSelectors の数が増えると、クラスタの最終状態の把握が複雑になる可能性があります。
Config Sync を使用すると、複数の RootSync と RepoSync オブジェクトを一度に同期できるため、関連する構成を別のリポジトリに追加して、目的のクラスタに同期できます。これにより、クラスタの最終状態を簡単に把握できます。また、構成の決定をクラスタに直接適用するのではなく、クラスタの構成をフォルダにまとめることができます。
Config Sync を使用した Job の管理を回避する
ほとんどの場合、Job やその他の状況タスクは、ライフサイクル管理を処理するサービスによって管理する必要があります。この場合、Job 自体ではなく、Config Sync で対象のサービスを管理できます。
Config Sync は Job を適用できますが、次の理由から Job は GitOps のデプロイには適していません。
変更不可のフィールド: 多くの Job フィールドは変更不可です。変更不可のフィールドを変更するには、オブジェクトを削除してから再作成する必要があります。ただし、ソースからオブジェクトを削除しない限り、Config Sync によってオブジェクトは削除されません。
意図しない Job の実行: Job を Config Sync と同期した後、対象の Job がクラスタから削除された場合、Config Sync は選択した状態からのドリフトを考慮し、Job を再作成します。Job の有効期間(TTL)を指定すると、信頼できる情報源から Job を削除するまで、Config Sync によって Job が自動的に削除され、自動的に再作成および再起動されます。
調整に関する問題: 通常、Config Sync は適用後にオブジェクトの調整を待機します。ただし、Job は実行を開始した時点で調整済みとみなされます。つまり、Config Sync は Job の完了を待たずに、他のオブジェクトの適用を続行します。ただし、後で Job が失敗した場合は、調整に失敗したとみなされます。場合によっては、これにより他のリソースの同期がブロックされ、修正するまでエラーが発生する可能性があります。また、同期に成功し、調整のみが失敗する場合もあります。
こうした理由から、Job を Config Sync と同期することはおすすめしません。
非構造化リポジトリを使用する
Config Sync では、リポジトリを編成するための 2 つの構造(非構造化と階層型)がサポートされています。
非構造化は、最もニーズに適した方法でリポジトリを整理できるため、推奨されるアプローチです。これに対して、階層型リポジトリは、cluster ディレクトリのカスタム リソース定義(CRD)などの特定の構造を適用します。このため、構成ファイルを共有する必要がある場合に問題が生じる可能性があります。たとえば、あるチームが CRD を含むパッケージを公開した場合、そのパッケージを使用する別のチームは CRD を cluster ディレクトリに移動する必要があるため、プロセスのオーバーヘッドが増加します。
非構造化リポジトリを使用すると、構成パッケージの共有と再利用が大幅に容易になります。ただし、リポジトリを整理するための定義済みのプロセスやガイドラインがないと、リポジトリの構造はチームによって異なるため、フリート全体のツールの実装が困難になる可能性があります。
階層型リポジトリを変換する方法については、階層型リポジトリを非構造化リポジトリに変換するをご覧ください。
コードと構成のリポジトリを分離する
モノリポジトリをスケールアップする場合は、各フォルダに固有のビルドが必要です。通常、コードの担当者とクラスタ構成の担当者では、権限と懸念事項が異なります。
コードと構成リポジトリを分離すると、次のようなメリットがあります。
- commit のループ回避できます。たとえば、コード リポジトリに commit すると CI リクエストがトリガーされて、イメージが生成され、コードの commit が必要になる場合があります。
- 必要な commit 数が、参加しているチームメンバーにとって負担になる可能性があります。
- アプリケーション コードとクラスタ構成の担当者に異なる権限を付与できます。
コードと構成リポジトリを分離することには、次のようなデメリットがあります。
- アプリケーション コードと同じリポジトリにないため、アプリケーション構成の検出件数が減少します。
- 多数のリポジトリが存在する場合、管理に時間がかかる場合があります。
別個のリポジトリを使用して変更を分離する
モノリポジトリをスケールアップする場合は、フォルダごとに異なる権限が必要です。このため、リポジトリを分離することで、セキュリティ、プラットフォーム、アプリケーションの構成間にセキュリティ境界を設定できます。また、本番環境と非本番環境でリポジトリを分離することをおすすめします。
多くのリポジトリの管理は、それ自体が大きなタスクになる可能性がありますが、異なるリポジトリに異なるタイプの構成を分離すると、次のようなメリットがあります。
- 組織にプラットフォーム、セキュリティ、アプリケーションのチームがある場合、チームごとに変更の頻度と権限が異なります。
- 権限はリポジトリ レベルで保持されます。
CODEOWNERSファイルを使用すると、組織は読み取り権限を維持したまま、書き込み権限を制限できます。 - Config Sync は Namespace ごとに複数の同期をサポートしているため、複数のリポジトリからファイルを取得する場合と同様の効果を得ることができます。
パッケージのバージョンを固定する
Helm と Git のいずれを使用する場合でも、構成パッケージのバージョンは、明示的なロールアウトなしで誤って移動しないように固定する必要があります。
これにより、共有構成が更新されたときにロールアウトに追加のチェックが追加されますが、共有更新が意図した以上の影響を及ぼすリスクは軽減されます。
Workload Identity Federation for GKE を使用する
GKE クラスタで Workload Identity Federation for GKE を有効にすると、Kubernetes ワークロードは安全かつ管理しやすい方法で Google サービスにアクセスできます。
GitHub や GitLab など、Google Cloud 以外のサービスの中には、Workload Identity Federation for GKE をサポートしていないものもありますが、セキュリティが強化され、Secret とパスワードの管理の複雑さが軽減されるため、可能な限り Workload Identity Federation for GKE を使用することをおすすめします。