このページでは、Consent Management API にユーザーデータを登録する方法について説明します。
データ要素は Consent Management API に登録され、ユーザーデータのマッピングを使用して同意に関連付けられます。ユーザーデータは Consent Management API には保存されません。
UserDataMappings リソースとして表現されるユーザーデータのマッピングには、次の要素が含まれます。
- ユーザーを識別するユーザー ID。この ID は、同意の登録時にアプリケーションが Consent Management API に提供した ID と一致します。
- Google Cloud やオンプレミスなど、他の場所に格納されているユーザーデータを識別するデータ ID。データ ID には、不透明 ID や URL などの識別子を使用できます。
- リソース属性。属性定義を使用して Consent Store 用に構成されたリソース属性値を使用して、ユーザーデータの特性を記述します。たとえば、データには、
de-identifiedの値を持つattribute_definition_iddata_identifiableを含めることができます。
次の図は、データ マッピングを作成するためのデータフローを示しています。
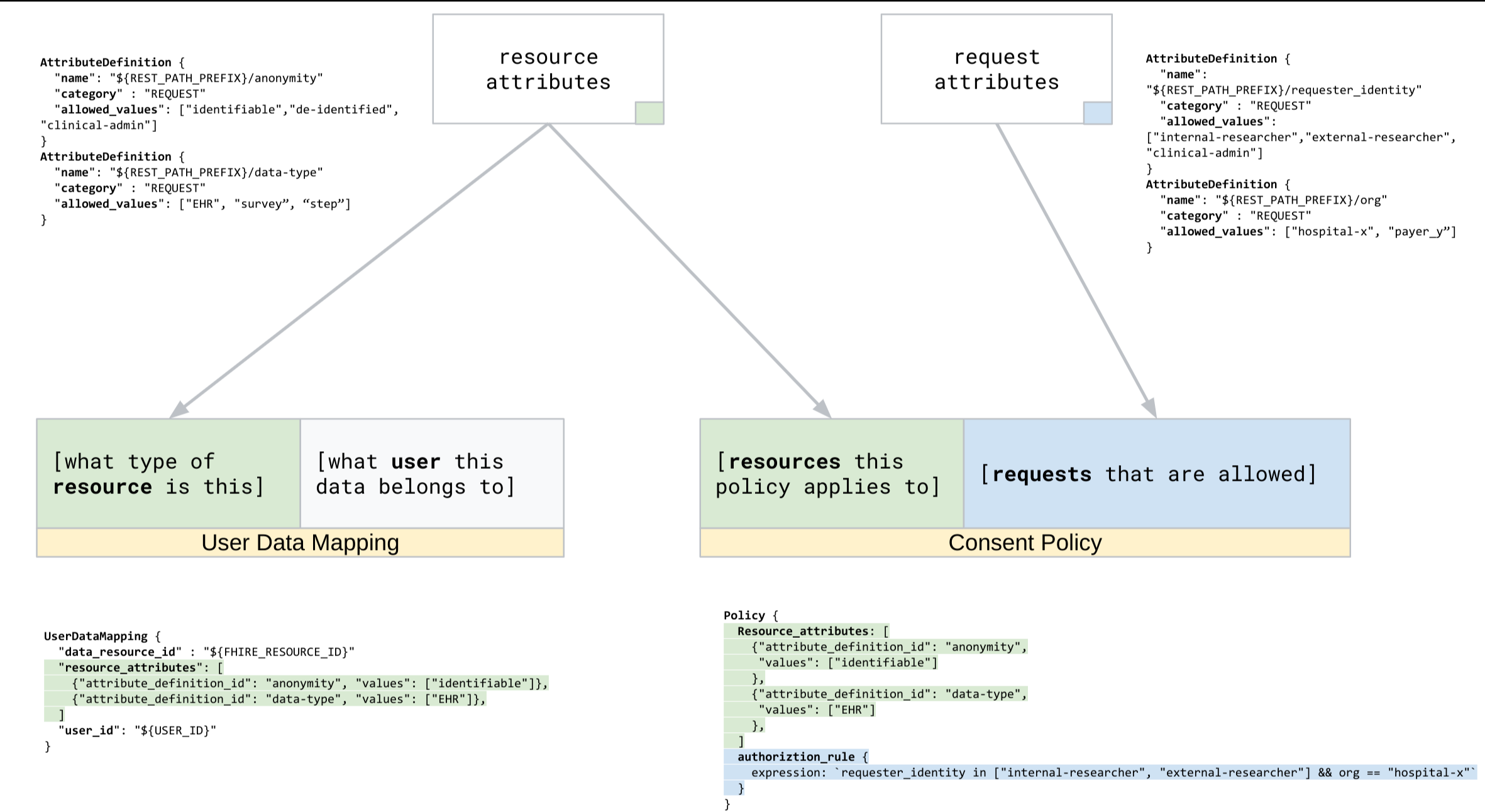
ユーザーデータのマッピングの登録
ユーザー データ マッピングを作成するには、projects.locations.datasets.consentStores.userDataMappings.create メソッドを使用します。POST リクエストを行い、リクエストで次の値を指定します。
- 親 Consent Store の名前
- データ要素が関連付けられているユーザーを表す、一意の不透明
userID - 一意のリソースへの REST パスなど、ユーザーデータ リソースの識別子
- データ要素を記述する
RESOURCE属性のセット - アクセス トークン
curl
次のサンプルは、curl を使用した POST リクエストを示しています。
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/consent+json; charset=utf-8" \ --data "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" \ "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings"
リクエストが成功すると、サーバーは JSON 形式の次のサンプルのようなレスポンスを返します。
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
PowerShell
次のサンプルは、Windows PowerShell を使用した POST リクエストを示しています。
$cred = gcloud auth application-default print-access-token $headers = @{ Authorization = "Bearer $cred" } Invoke-WebRequest ` -Method Post ` -Headers $headers ` -ContentType: "application/consent+json; charset=utf-8" ` -Body "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" ` -Uri "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings" | Select-Object -Expand Content
リクエストが成功すると、サーバーは JSON 形式の次のサンプルのようなレスポンスを返します。
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
データ ID の構成
ユーザーデータ マッピング リソースの data_id フィールドには、ユーザーデータ マッピング リソースによって参照されるデータを記述するお客様指定の文字列が含まれます。不透明な ID や URI などの任意の文字列が許可されます。
データ ID は、アプリケーションで必要とされる条件に応じて細かく指定できます。登録するデータをテーブルレベルまたはバケットレベルで記述できる場合は、そのリソースの REST パスとして data_id を定義します。登録するデータで精度が必要な場合は、特定の行またはセルを指定することをおすすめします。許可されたアクションやデータのクラスなど、概念的なリソースをアプリケーションで使用する場合は、それらのユースケースをサポートする規則で data_id を定義する必要があります。
異なるサービスやさまざまな精度レベルで保存されるデータを記述する data_id の例には、次のようなものがあります(ただし、これらに限定されません)。
Google Cloud Storage オブジェクト
'data_id' : 'gs://BUCKET_NAME/OBJECT_NAME'
Amazon S3 オブジェクト
'data_id' : 'https://BUCKET_NAME.s3.REGION.amazonaws.com/OBJECT_NAME'
BigQuery テーブル
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID'
BigQuery 行(BigQuery 行では REST パスがないため、独自の識別子が必要です。以下はその方法の 1 つです)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID'
BigQuery セル(BigQuery セルでは REST パスがないため、独自の識別子が必要です。以下はその方法の 1 つです)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID/myColumns/COLUMN_ID'
FHIR リソース
'data_id' : 'https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/fhirStores/FHIR_STORE_ID/fhir/Patient/PATIENT_ID'
概念表現
'data_id' : 'wearables/fitness/step_count/daily_sum'