メディア レコメンデーションを使ってみる
最先端のメディアのおすすめアプリを簡単に作成できます。メディアのおすすめを使用すると、最適化目標によってカスタマイズされた Google の高精度な検索結果により、オーディエンスは、次に視聴するコンテンツや読むコンテンツなど、よりパーソナライズされたコンテンツを見つけることができます。
メディア向け Vertex AI Search の一般的な情報については、メディア検索とレコメンデーションの概要をご覧ください。この入門チュートリアルでは、Movielens データセットを使用して、メディア コンテンツ カタログとユーザー イベントを Vertex AI Search にアップロードし、パーソナライズされたムービーのおすすめモデルをトレーニングする方法を示します。 MovieLens データセットには、映画(ドキュメント)とユーザーによる映画の評価(ユーザー イベント)のカタログが含まれています。
このチュートリアルでは、クリック率(CTR)向けに最適化された「その他のおすすめ」タイプのレコメンデーション モデルをトレーニングします。トレーニングが完了すると、モデルはユーザー ID またはシードの映画に基づいて映画をおすすめできるようになります。
モデルの最小データ要件を満たすために、映画の評価が 4 以上であるものはそれぞれ視聴アイテム イベントとして扱われます。
このチュートリアルの所要時間:
- モデルのトレーニングを開始するための最初の手順: 約 1.5 時間。
- モデルのトレーニングを待機時間: 最大 24 時間。 (モデルのトレーニング)
- モデル予測の評価とクリーンアップ: 約 30 分。 (レコメンデーションをプレビューする)
メディア検索のスタートガイド チュートリアルを完了していて、データストア(推奨名 quickstart-media-data-store)が残っている場合は、別のデータストアを作成する代わりに、そのデータストアを使用できます。この場合は、メディア レコメンデーション用のアプリを作成するからチュートリアルを開始する必要があります。
目標
- メディア ドキュメントとユーザー イベント データを BigQuery から Vertex AI Search にインポートする方法を学習します。
- レコメンデーション モデルをトレーニングして評価します。
このチュートリアルに進む前に、始める前にの手順が完了していることを確認してください。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、「ガイドを表示」をクリックしてください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM に移動 - プロジェクトを選択します。
- [ アクセスを許可] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [ロールを選択] リストでロールを選択します。
- 追加のロールを付与するには、 [別のロールを追加] をクリックして各ロールを追加します。
- [保存] をクリックします。
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM に移動 - プロジェクトを選択します。
- [ アクセスを許可] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [ロールを選択] リストでロールを選択します。
- 追加のロールを付与するには、 [別のロールを追加] をクリックして各ロールを追加します。
- [保存] をクリックします。
-
- Google Cloud コンソールを開きます。
- Google Cloud プロジェクトを選択します。
- ダッシュボード ページの [プロジェクト情報] カードのプロジェクト ID をメモします。以降の手順では、このプロジェクト ID が必要です。
コンソールの上部にある [Cloud Shell をアクティブにする] ボタンをクリックします。Google Cloud コンソールの下部の新しいフレーム内で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。 Cloud Shell を起動する他の方法については、Cloud Shell を起動するをご覧ください。

プロジェクト ID を使用して次のコマンドを実行し、コマンドラインのデフォルト プロジェクトを設定します。
gcloud config set project PROJECT_IDBigQuery データセットを作成します。
bq mk movielensmovies.csvを新しいmoviesBigQuery テーブルに読み込みます。bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresratings.csvを新しいratingsBigQuery テーブルに読み込みます。bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestampmovies テーブルを Google 定義の
Documentスキーマに変換するビューを作成します。bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_view新しいビューに、Discovery Engine API で想定されるスキーマが含まれるようになりました。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインでプロジェクト名を展開し、
movielensデータセットを展開し、[movies_view] をクリックしてこのビューのクエリページを開きます。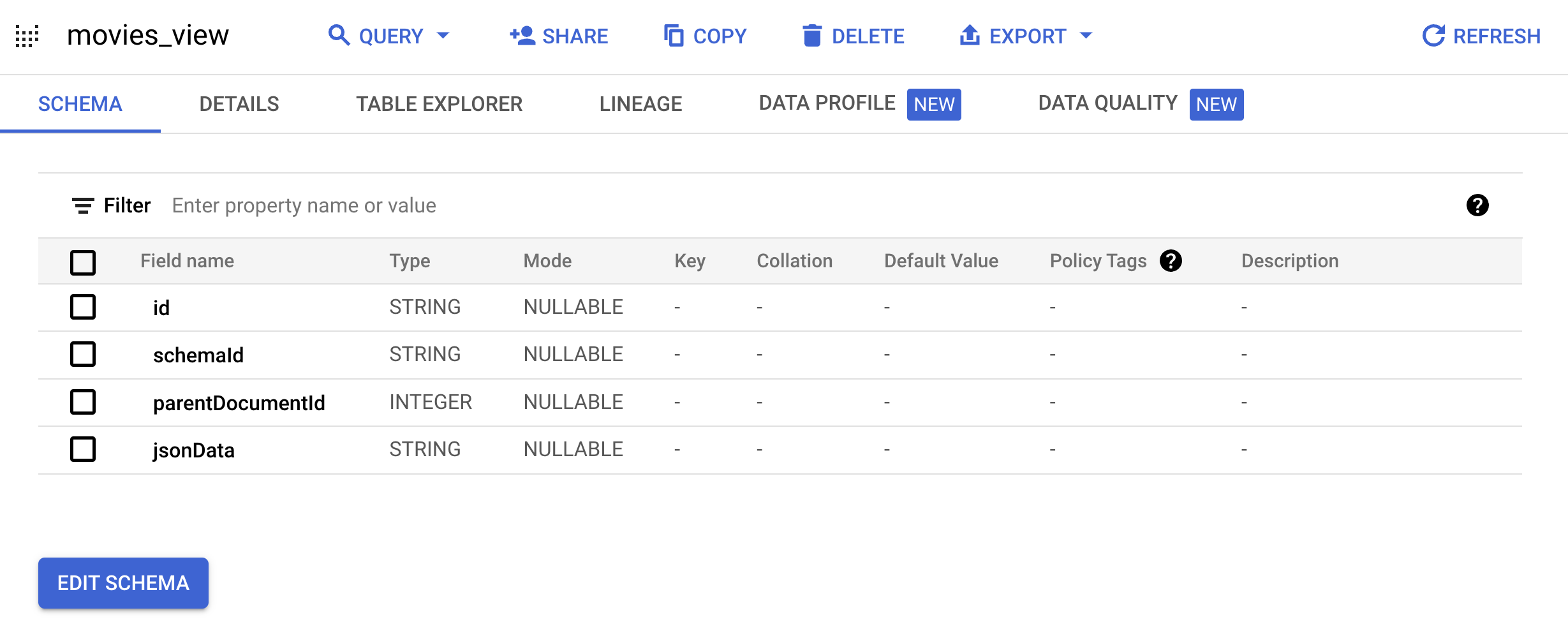
[テーブル エクスプローラ] タブに移動します。
[生成されたクエリ] ペインで、[クエリにコピー] ボタンをクリックします。クエリエディタが開きます。
[実行] をクリックすると、作成したビューで映画のデータが表示されます。
次の Cloud Shell コマンドを実行して、映画の評価から架空のユーザー イベントを作成します。
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsGoogle Cloud コンソールで、[AI Applications] ページに移動します。
省略可: [モデルの入力と回答の選択的サンプリングを Google に許可する] をクリックします。
[続行して API を有効化] をクリックします。
Google Cloud コンソールで、[AI Applications] ページに移動します。
[
アプリを作成 ] をクリックします。[アプリを作成する] ページの [メディア レコメンデーション] で [作成] をクリックします。
[アプリ名] フィールドに、アプリの名前(
quickstart-media-recommendationsなど)を入力します。アプリ名の下にアプリ ID が表示されます。[おすすめの種類] で [関連商品のおすすめ] が選択されていることを確認します。
[ビジネスの目標] で [クリック率(CTR)] が選択されていることを確認します。
[続行] をクリックします。
データストアを作成します。
[データストア] ページで、[データストアを作成] をクリックします。
データストアの表示名(
quickstart-media-data-storeなど)を入力し、[作成] をクリックします。
作成したデータストアを選択し、[作成] をクリックしてアプリを作成します。
[ドキュメントのインポート] ページの [ネイティブ ソース] で、BigQuery を選択します。
作成した
moviesBigQuery ビューの名前を入力し、[インポート] をクリックします。PROJECT_ID.movielens.movies_viewすべてのドキュメントがインポートされるまで待ちます。インポートには 15 分ほどかかります。 完了すると、86,537 個のドキュメントが作成されます。
インポート オペレーションのステータスは [アクティビティ] タブで確認できます。インポートが完了すると、インポート オペレーションのステータスが [完了] に変わります。
[イベント] タブで、[イベントをインポート] をクリックします。
[ドキュメントのインポート] ページの [ネイティブ ソース] で、BigQuery を選択します。
作成した
user_eventsBigQuery ビューの名前を入力し、[インポート] をクリックします。PROJECT_ID.movielens.user_events新しいモデルのトレーニングに対するデータ要件を満たすには、少なくとも 100 万件のイベントがインポートされるのを待ってから次の手順に進んでください。
オペレーションのステータスは [アクティビティ] タブで確認できます。何百万もの行をインポートするため、このプロセスには約 1 時間かかります。
要件が満たされているかどうかを確認するには、[データ品質] > [要件] タブに移動します。ユーザー イベントをインポートしてから、[要件] タブのステータスが [データ要件を満たしています] に更新されるまで、しばらく時間がかかることがあります。
[構成] ページに移動します。
[サービス] タブをクリックします。サービス構成はすでに作成されています。
トレーニング タブをクリックします。
データ要件が満たされると、自動的にモデルのトレーニングが開始されます。このページでトレーニングとチューニングのステータスを確認できます。
モデルがトレーニングされ、クエリの準備が完了するまでに数日かかることがあります。[クエリの準備完了] フィールドには、プロセスが完了している場合には [はい] と表示されます。[いいえ] が [はい] に変わったことを確認するには、ページを更新する必要があります。
ナビゲーション メニューで [
プレビュー ] をクリックします。[ドキュメント ID] フィールドをクリックします。ドキュメント ID のリストが表示されます。
シードの映画 ID を入力してください。たとえば、「ロード・オブ・ザ・リング: 旅の仲間(2001)」の場合は、
4993になります。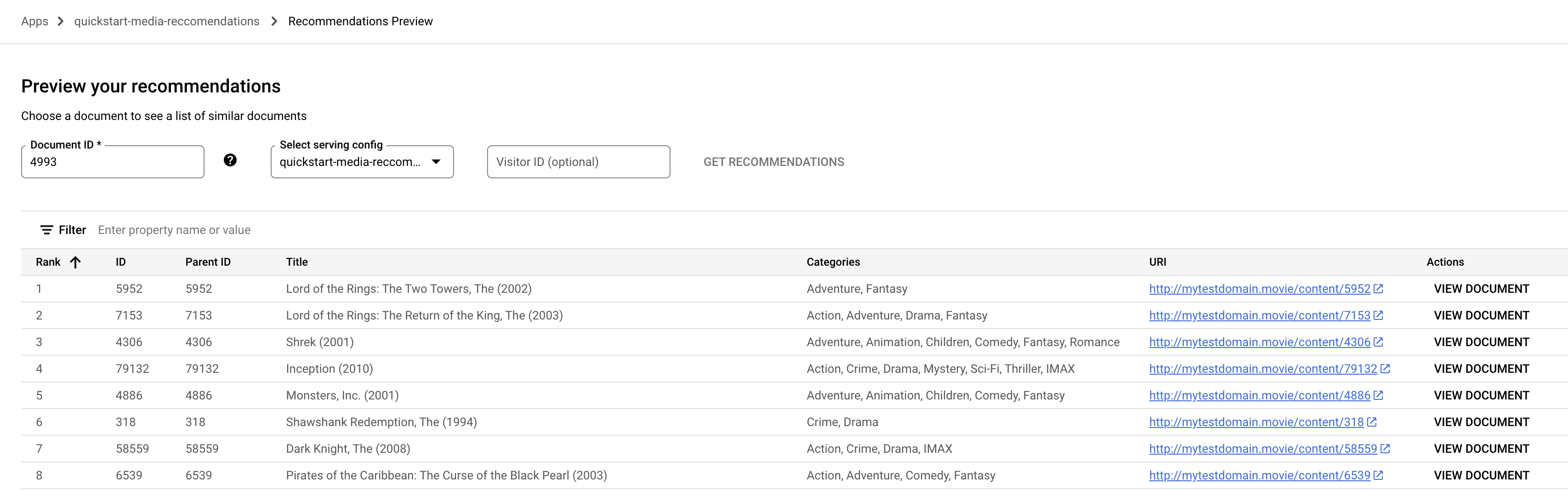
プルダウン メニューからサービス構成名を選択します。
[レコメンデーションを表示] をクリックします。おすすめのドキュメントのリストが表示されます。
[データ] ページの [ドキュメント] タブに移動し、ドキュメントの ID をコピーします。
[統合] ページに移動します。このページには、REST API の
servingConfigs.recommendメソッドのサンプル コマンドが含まれます。先ほどコピーしたドキュメント ID を [ドキュメント ID] フィールドに貼り付けます。
[ユーザー Pseudo ID] 欄はそのままにします。
サンプル リクエストをコピーして、Cloud Shell で実行します。
- 不要な Google Cloud 料金が発生しないようにするには、Google Cloud console を使用して、不要なプロジェクトを削除します。
- Vertex AI Search の学習用に新しいプロジェクトを作成し、そのプロジェクトが不要になった場合は、プロジェクトを削除します。
- 既存の Google Cloud プロジェクトを使用した場合は、作成したリソースを削除して、アカウントに課金されないようにします。詳細については、アプリを削除するをご覧ください。
- Vertex AI Search を無効にするの手順に沿って操作します。
BigQuery データセットを作成した場合は、Cloud Shell でそれを削除します。
bq rm --recursive --dataset movielens
データセットを準備する
Cloud Shell を使用して Movielens のデータセットをインポートし、メディア用の Vertex AI Search 用にデータセットを再構築します。
Cloud Shell を開く
データセットのインポート
Movielens データセットは、公開の Cloud Storage バケットで利用できるため、簡単にインポートできます。
BigQuery ビューを作成する
このステップでは、メディアのおすすめの想定される形式に沿って Movielens データセットを再構成します。
メディアのおすすめでは、モデルを作成するためのユーザー イベント データが必要です。このガイドでは、過去 90 日間の肯定的な評価(>= 4)からフェイクの view-item イベントを作成します。
Vertex AI Search を有効にする
メディアのおすすめのアプリを作成する
このセクションの手順では、メディアのおすすめアプリの作成とデプロイについて説明します。
データのインポート
次に、先ほどフォーマットした映画とユーザー イベントのデータをインポートします。
ドキュメントのインポート
BigQuery ビューを作成するで作成した movies_view ドキュメントを quickstart-media-data-store データストアにインポートします。
ユーザー イベントのインポート
BigQuery ビューを作成するで作成した user_events レコードをデータストアにインポートします。
レコメンデーション モデルをモデルをトレーニングする。
レコメンデーションをプレビューする
モデルでクエリの準備が完了したら、次の手順を行います。
構造化データ用にアプリをデプロイする
アプリをデプロイするためのレコメンデーション ウィジェットはありません。デプロイ前にアプリをテストするには、以下の手順を行います。
レコメンデーション アプリをウェブアプリに統合する方法については、メディアのおすすめを使ってみるのコードサンプルをご覧ください。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。
メディア検索を使ってみるのチュートリアルでメディア検索用に作成したデータストアを再利用できます。 このクリーンアップ手順を行う前に、そのチュートリアルをお試しください。