FHIR R4 データを医療検索アプリにインポートしたら、インポートしたデータに対してクエリを実行して関連する結果を取得できます。次のタイプのクエリを使用して検索できます。
- キーワード検索
- 自然言語によるクエリ
- 生成 AI の回答を含む自然言語クエリ
また、日付でフィルタされたクエリを使用して検索をフィルタすることもできます。詳細については、resource_datetime フィルタを定義するをご覧ください。
Google Cloud コンソールで検索する場合は、まず患者 ID を指定し、一度に 1 人の患者のデータを検索する必要があります。REST API を使用して検索する場合、データストア全体を検索できます。
このページでは、さまざまなタイプのクエリを使用して医療データを検索する方法について説明します。
医療データの検索に対する Vertex AI Search の意図する使用
Vertex AI Search の意図する使用は、病気や疾患の予防、診断、治療に関する情報を提供することです。診断や治療の推奨に関する質問は、このプロダクトでの対応を意図していません。このプロダクトが意図する使用は、ユーザーから提供された既存の医療情報を取得して要約することです。
テストデータが限られているため、このプロダクトは年齢層 0 から 18 歳と 85 歳以上に適している場合とそうでない場合があります。したがって、生成された出力を確認する際は、ソースデータ内のサブポピュレーションの代表性を考慮する必要があります。
このプロダクトの意図する用途の例を以下に示します。
トピックに関連する患者の情報を検索するための探索的クエリ:
- 「アスピリンの用途を要約してください」
- 「血圧」
- 「糖尿病の管理とは?」
構造化クエリにマッピングできる特定のリソースを見つけるためのナビゲーション クエリ:
- 「最新の A1C 値を表示」
抽出型の質問と回答。証拠が複数のリソースに分散している可能性がある特定の質問に回答します。
- 「この患者はセファロスポリンで治療されたことがありますか」
- 「患者は精神科の評価を受けたことがありますか」
以下は、このプロダクトの意図する使用ではありません。
診断の推奨事項と治療の推奨事項:
- 「この患者の鑑別診断は何ですか?」
- 「患者にどの薬を処方すべきですか?」
クエリのガイドライン
次のガイドラインは、より適切な検索結果を得られるクエリを作成するのに役立ちます。
特定の意図を持つクエリを検索する: モデルはユーザーが探しているものを把握していないため、曖昧なクエリではなく、ターゲットを絞ったクエリを指定することをおすすめします。たとえば、「高血圧」というキーワードで検索する方が、「概要」というキーワードで検索するよりも適しています。「高血圧」というクエリでは、関連するドキュメントから特定の検索結果が返されますが、「要約」というクエリでは、関連性のないドキュメントから検索結果が返されることがあります。
コンテキストを保持する: 検索は会話型ではないため、各クエリのコンテキスト全体を提供することをおすすめします。たとえば、最初のクエリが「高血圧」で、同じトピックについてフォローアップしたい場合は、「高血圧と診断されたのはいつですか」という 2 番目のクエリの方が、「いつ診断されましたか」というクエリよりも適切です。
クエリを簡素化する: 可能な限り、複雑なクエリをより単純なクエリに分割します。たとえば、「クレアチニンとアルブミン」を検索する代わりに、目的に応じて「クレアチニン」、「アルブミン」、「クレアチニン アルブミン比」の異なるクエリを作成します。
推論を求めない: 検索では、モデルが検索した情報から計算や推論を行うのではなく、検索したドキュメントから情報をそのまま返すことができる場合に、より正確な結果が得られます。たとえば、「患者の体重はどのくらい変化したか」をクエリする代わりに、「過去 10 回の診察での患者の体重を一覧表示する」をクエリしてから、体重の変化を個別に計算できます。
結果の一致のハイライト表示
一致のハイライト表示は、検索結果のテキストのうち、検索クエリと文脈的に一致する部分をハイライト表示する構成です。
次のリソースタイプの結果では、一致する部分のハイライト表示がサポートされています。
- 構成:
Composition.section[].text.divフィールドのコンテキスト テキストをハイライト表示します。 - DiagnosticReport:
DiagnosticReport.conclusionフィールドのコンテキスト テキストをハイライト表示します。 DocumentReference:
DocumentReference.content[0].attachment.urlフィールドで参照されているドキュメントからコンテキスト テキストをハイライト表示します。ハイライト表示されたテキストは境界ボックスで囲まれます。境界ボックスは、検索レスポンス内の 2 組の正規化された座標で表されます。一致する単語のハイライト表示に対応しているドキュメントは、PDF ファイルと、サポートされているタイプの画像ファイルです。次の図は、DocumentReference リソースタイプからスキャンされたドキュメントでテキストがハイライト表示される様子を示しています。
図 1. DocumentReference でスキャンされたドキュメント内のハイライトを一致させます。
REST API を使用して検索する場合は、matchHighlightingCondition フィールドを使用して、検索リクエストで一致するハイライト表示を有効にする必要があります。レスポンスには match_highlighting フィールドが含まれています。このフィールドを使用して、検索アプリケーションでハイライト表示されたテキストをレンダリングできます。
- Composition ドキュメントと DiagnosticReport ドキュメントの場合、
match_highlightingフィールドには、ハイライト表示する必要があるトークンの開始インデックスと終了インデックスが含まれます。 - DocumentReference ドキュメントの場合、
match_highlightingフィールドには、テキストをハイライト表示する境界ボックスの座標が含まれます。境界ボックスは、ドキュメントの左上隅を原点とする 2 組の正規化された座標で表されます。このフィールドにはpage_numberフィールドもネストされています。このフィールドは、画像の場合は0に、PDF ファイルの最初のページの場合は1に設定されます。
Google Cloud コンソールを使用して検索結果をプレビューすると、一致のハイライト表示がデフォルトで有効になります。
始める前に
検索する前に、次の操作を行います。
- 医療検索アプリと医療検索データストアを作成し、FHIR R4 データをインポートします。詳細については、医療検索アプリを作成すると医療検索データストアを作成するをご覧ください。
- 医療データの検索結果を構成します。
- 検索時に役立つクエリ候補を表示するには、予測入力をオンにします。これはプレビュー機能です。
- Vertex AI Search でサポートされている FHIR R4 リソースのリストを確認します。詳細については、Healthcare FHIR R4 データスキーマ リファレンスをご覧ください。
キーワードを使用した検索
キーワードを使用して、医療データストアを検索できます。たとえば、「a1c」、「インシュリン」、「潰瘍」などのキーワードを使用して検索すると、関連する FHIR リソースを取得できます。
次の画像は、キーワードが「脂質」の場合の検索結果を示しています。この例には、サマリーや生成 AI の回答は含まれていません。
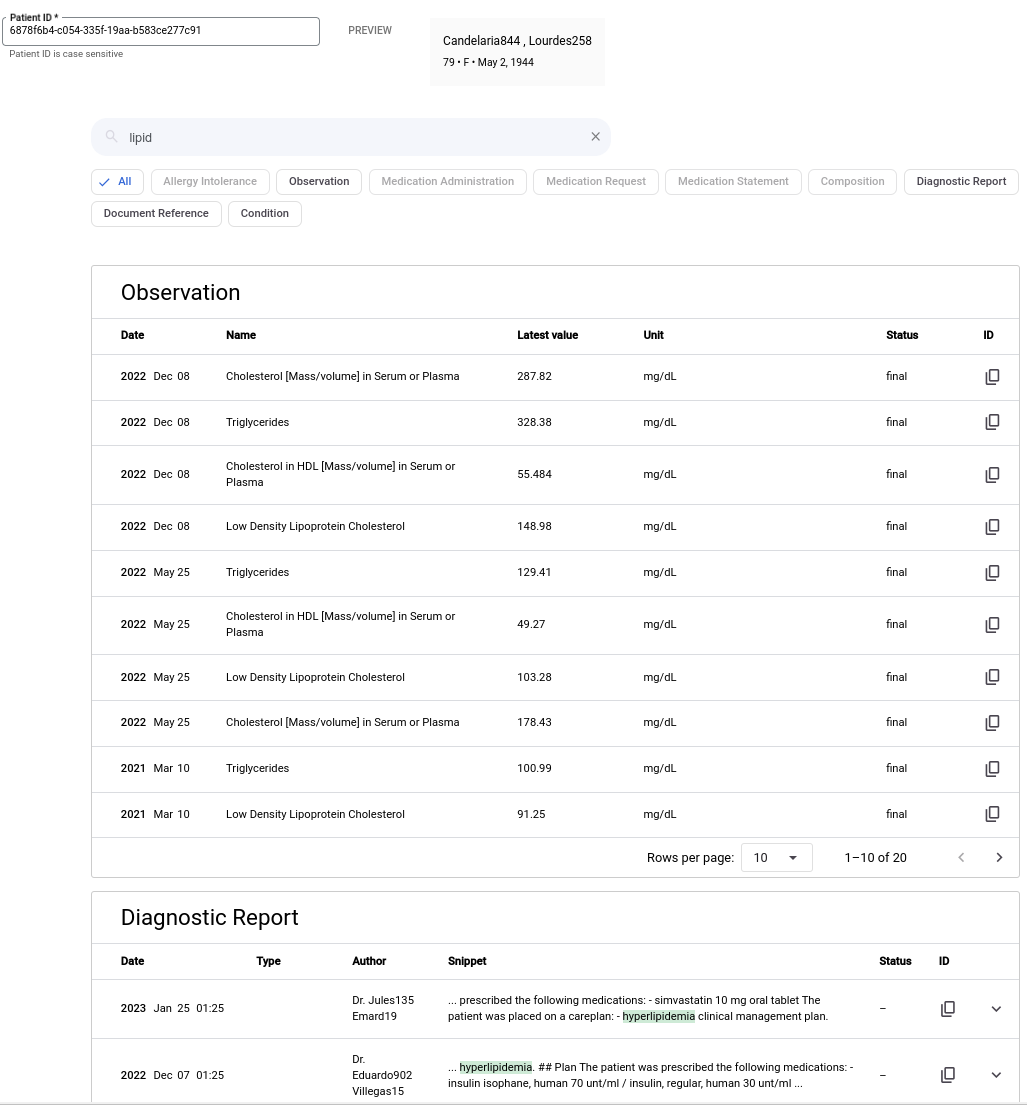
キーワードを使用して検索するには、次の手順を行います。
コンソール
Google Cloud コンソールで、[AI Applications] ページに移動します。
クエリを実行する医療検索アプリを選択します。
ナビゲーション メニューで [プレビュー] をクリックします。
[患者 ID] フィールドに、クエリする患者の ID を入力します。患者 ID では大文字と小文字が区別されます。
Enter キーを押すか、[プレビュー] をクリックして、患者 ID を送信します。
[ここで検索] 検索バーに検索キーワードを入力します。
予測入力を有効にしている場合は、入力すると検索バーの下に予測入力候補のリストが表示されます。
Enter キーを押してクエリを送信します。
- 検索結果は、FHIR リソースタイプに基づいて分類された、ページネーションされた表に表示されます。
- デフォルトでは、すべての FHIR リソースタイプの検索結果は時系列の逆順に表示されます。
省略可。結果をフィルタリングするには、検索バーの下にある 1 つ以上の FHIR リソース カテゴリを選択します。
省略可。Composition、DocumentReference、DiagnosticReport リソースとの関連性に応じて結果を並べ替えるには、[並べ替え: 時系列逆順] フィルタをクリックし、リストから [関連性] を選択します。詳細については、医療検索結果を並べ替えるをご覧ください。
REST
次のサンプルは、キーワードを使用して医療検索アプリで 1 人の患者の FHIR R4 データを検索する方法を示しています。このサンプルでは、servingConfigs.search メソッドを使用します。
デフォルトでは、検索結果は時系列の逆順に返されます。 Composition、DiagnosticReport、DocumentReference リソースを検索するときに、関連性に応じて検索結果を並べ替えることができます。詳細については、医療検索結果を並べ替えるをご覧ください。
キーワードを使用して検索します。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "KEYWORD_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}} "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'次のように置き換えます。
PROJECT_ID: 実際の Google Cloud プロジェクト ID。APP_ID: クエリする Vertex AI Search アプリの ID。KEYWORD_QUERY: フィルタされた患者の臨床データ全体で検索するキーワード(「糖尿病」や「a1c」など)。PATIENT_ID: データを検索する患者のリソース ID。MATCH_HIGHLIGHTING_CONDITION: 次の値を使用できる文字列。MATCH_HIGHLIGHTING_DISABLED: すべてのドキュメントで一致する単語のハイライト表示をオフにします。MATCH_HIGHLIGHTING_ENABLED: すべてのドキュメントで一致する部分のハイライト表示をオンにします。このフィールドを空のままにするか、指定しない場合、一致する単語のハイライト表示はMATCH_HIGHLIGHTING_DISABLEDに設定され、すべてのドキュメントでオフになります。
自然言語クエリを使用して検索する
Vertex AI Search を使用すると、複雑な自然言語クエリの結果を取得できます。たとえば、次の画像は、自然言語クエリ「糖尿病に関連する検査結果」の結果を示しています。
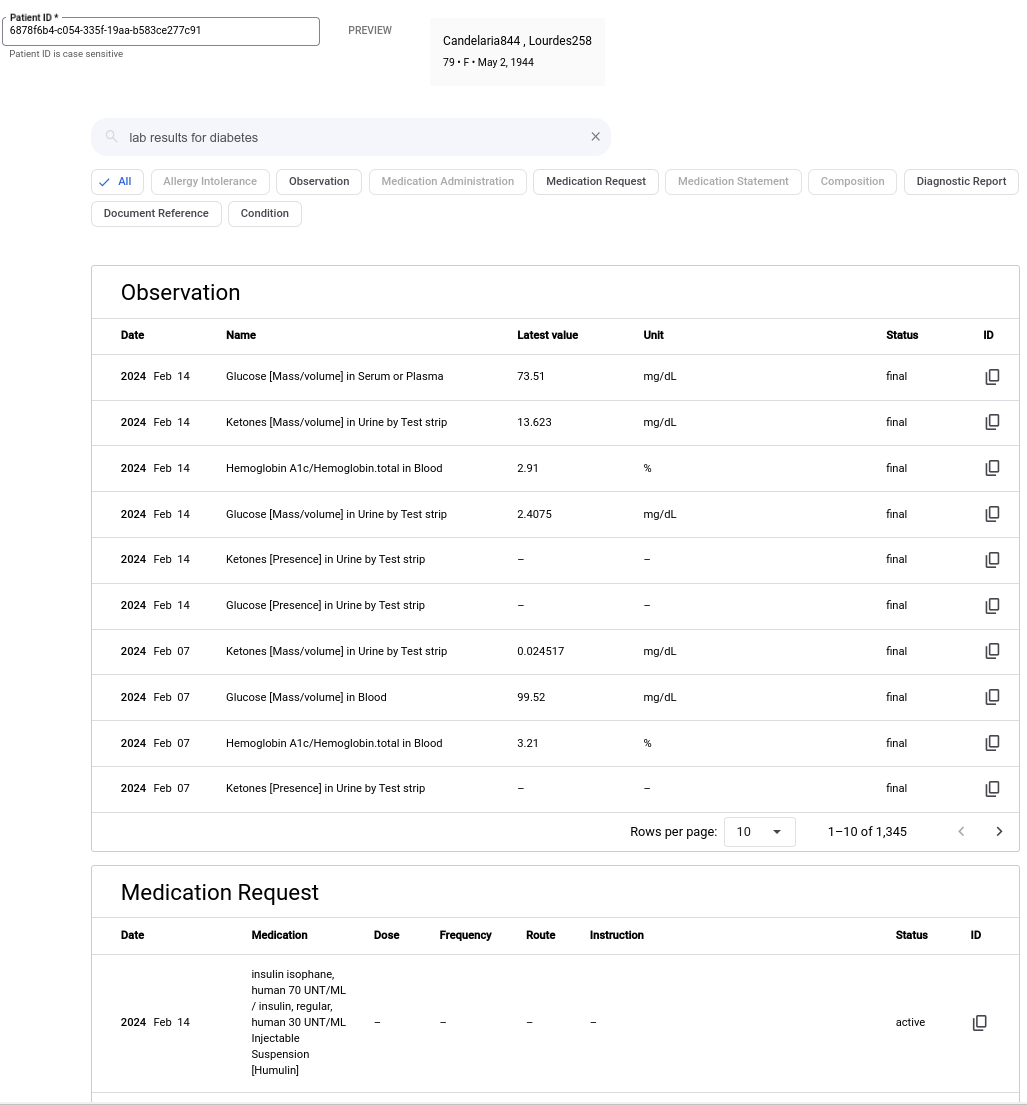
自然言語クエリを使用して検索するには、次の手順を完了します。
コンソール
Google Cloud コンソールで、[AI Applications] ページに移動します。
クエリを実行する医療検索アプリを選択します。
ナビゲーション メニューで [プレビュー] をクリックします。
[患者 ID] フィールドに、データをクエリする患者の患者 ID を入力します。患者 ID では大文字と小文字が区別されます。
Enter キーを押すか、[プレビュー] をクリックして、患者 ID を送信します。
[ここで検索] 検索バーに、「糖尿病に関連する検査結果」などの自然言語のクエリを入力します。
予測入力を有効にしている場合は、入力すると検索バーの下に予測入力候補のリストが表示されます。
Enter キーを押してクエリを送信します。
- 検索結果は、FHIR リソースタイプに基づいて分類された、ページネーションされた表に表示されます。
- デフォルトでは、すべての FHIR リソースタイプの検索結果は時系列の逆順に表示されます。
省略可。検索バーの下にある 1 つ以上の FHIR リソース カテゴリを選択して、結果をフィルタします。
省略可。Composition、DocumentReference、DiagnosticReport リソースとの関連性に応じて結果を並べ替えるには、[並べ替え: 時系列逆順] フィルタをクリックし、リストから [関連性] を選択します。詳細については、医療検索結果を並べ替えるをご覧ください。
REST
次のサンプルは、自然言語クエリを使用して、医療検索アプリで 1 人の患者の FHIR R4 データを検索する方法を示しています。このサンプルでは、servingConfigs.search メソッドを使用します。自然言語クエリを使用して検索するには、リクエストの本文に naturalLanguageQueryUnderstandingSpec フィールドを追加する必要があります。
デフォルトでは、検索結果は時系列の逆順に返されます。 Composition、DiagnosticReport、DocumentReference リソースを検索するときに、関連性に応じて検索結果を並べ替えることができます。詳細については、医療検索結果を並べ替えるをご覧ください。
自然言語でクエリを投稿します。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "NATURAL_LANGUAGE_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}}, "naturalLanguageQueryUnderstandingSpec":{"filterExtractionCondition":"ENABLED"}, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'次のように置き換えます。
PROJECT_ID: 実際の Google Cloud プロジェクト ID。APP_ID: クエリする Vertex AI Search アプリの ID。NATURAL_LANGUAGE_QUERY: 自然言語のクエリ(「糖尿病に関連する検査結果」、「患者は現在薬を服用していますか」など)。PATIENT_ID: データを検索する患者のリソース ID。MATCH_HIGHLIGHTING_CONDITION: 次の値を使用できる文字列。MATCH_HIGHLIGHTING_DISABLED: すべてのドキュメントで一致する単語のハイライト表示をオフにします。MATCH_HIGHLIGHTING_ENABLED: すべてのドキュメントで一致する部分のハイライト表示をオンにします。このフィールドを空のままにするか、指定しない場合、一致する単語のハイライト表示はMATCH_HIGHLIGHTING_DISABLEDに設定され、すべてのドキュメントでオフになります。
生成 AI の回答を含む自然言語クエリを使用した検索
自然言語クエリを使用して患者の FHIR データを検索するときに、検索結果とともに生成 AI の回答を取得するように選択できます。回答には検索結果のサマリーと、回答の生成に使用された参照が表示されます。
コンソールを使用する場合は、生成 AI の回答に使用する大規模言語モデル(LLM)を選択できます。詳細については、医療データの検索結果を構成するをご覧ください。
REST API を使用する場合、次のいずれかの LLM モデルを指定して、version フィールドで生成 AI の回答を取得できます。
gemini-1.5-flash-001/answer_gen/v1またはstable:gemini-1.5-flash-001モデルに基づく安定した一般提供モデル。詳細については、一般提供(GA)モデルをご覧ください。gemini-1.5-pro-002またはpreview:gemini-1.5-proモデルに基づくプレビュー モデル。
次の図は、生成 AI の回答を含む自然言語クエリの例を示しています。検索サマリーは、関連する検索結果から得られた情報を要約して、クエリの回答を提供します。引用のあるセグメントを展開すると、選択したセグメントの生成に使用された参照を確認できます。生成された回答に引用が含まれていない場合があります。
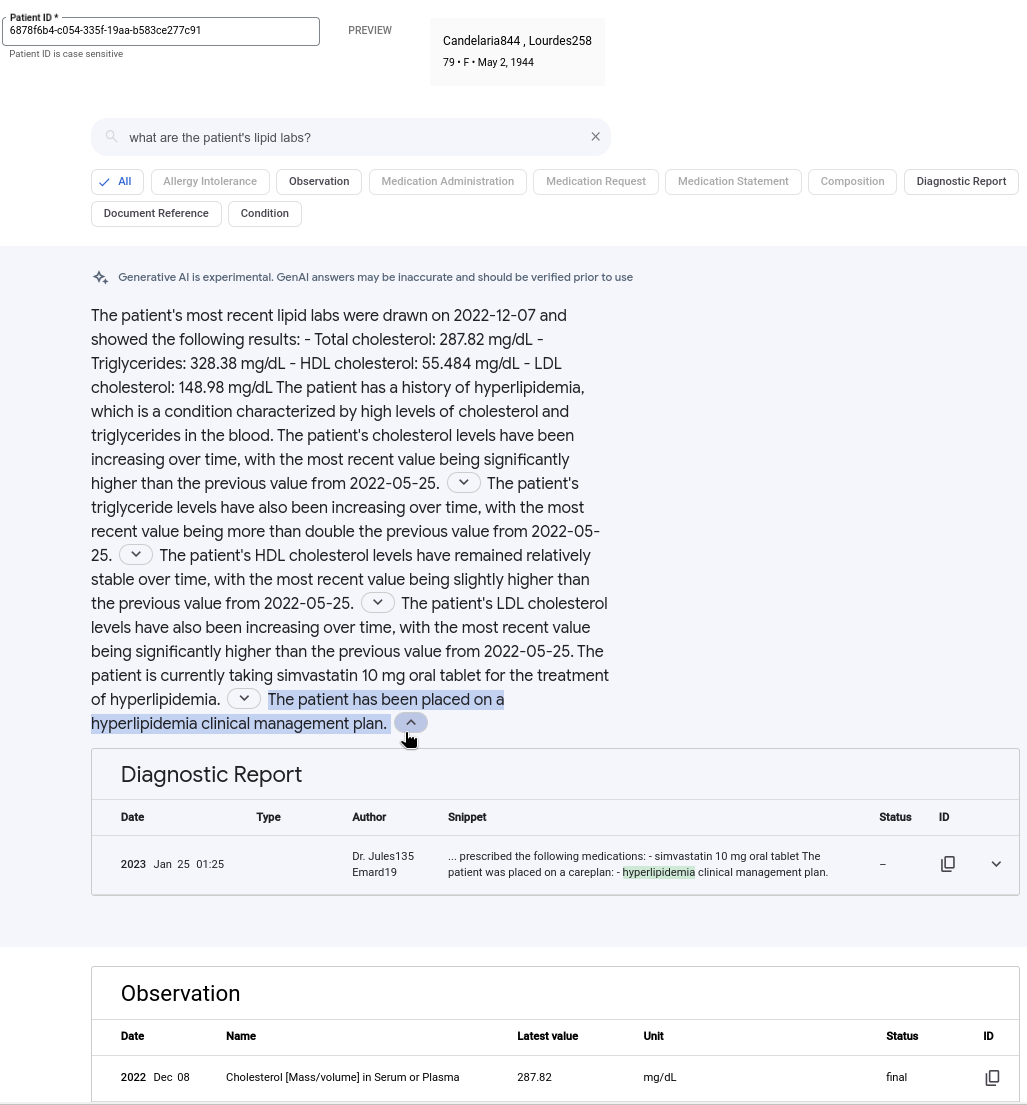
生成 AI の回答付きで検索するには、次の操作を行います。
コンソール
Google Cloud コンソールで、[AI Applications] ページに移動します。
クエリを実行する医療検索アプリを選択します。
ナビゲーション メニューで [構成] をクリックします。
検索ウィジェットをカスタマイズします。
- [検索タイプ] フィールドで、[回答付きで検索] を選択します。
- サマリーの生成に使用するモデルを選択します。詳細については、医療データの検索結果を構成するをご覧ください。
- 設定を保存して公開します。
ナビゲーション メニューで [プレビュー] をクリックします。
[患者 ID] フィールドに、データをクエリする患者の患者 ID を入力します。患者 ID では大文字と小文字が区別されます。
Enter キーを押すか、[プレビュー] をクリックして、患者 ID を送信します。
[Search here] 検索バーに、「nsaids」、「患者の脂質検査結果は何ですか」、「最新の A1C の結果は何ですか」などの自然言語クエリを入力します。
予測入力を有効にしている場合は、入力すると検索バーの下に予測入力候補のリストが表示されます。
Enter キーを押してクエリを送信します。
- 生成 AI の回答が検索バーの下に表示されます。
- 検索結果は、FHIR リソースタイプに基づいて分類された、ページネーションされた表に表示されます。
- デフォルトでは、すべての FHIR リソースタイプの検索結果は時系列の逆順に表示されます。
省略可。引用を含む回答のセグメントを展開すると、検索結果からの参照が表示されます。
省略可。検索バーの下にある 1 つ以上の FHIR リソース カテゴリを選択して、結果をフィルタします。
省略可。Composition、DocumentReference、DiagnosticReport リソースとの関連性に応じて結果を並べ替えるには、[並べ替え: 時系列逆順] フィルタをクリックし、リストから [関連性] を選択します。詳細については、医療検索結果を並べ替えるをご覧ください。
REST
次のサンプルは、生成 AI の回答を含む自然言語クエリを使用して、医療検索アプリで 1 人の患者の FHIR R4 データを検索する方法を示しています。このサンプルでは、servingConfigs.search メソッドを使用します。
- 自然言語クエリを使用して検索するには、リクエストの本文に
naturalLanguageQueryUnderstandingSpecフィールドを追加する必要があります。 - インライン引用インデックスを含めるには、
includeCitationsフィールドを追加する必要があります。これはブール値のフィールドで、デフォルトはfalseに設定されています。
デフォルトでは、検索結果は時系列の逆順に返されます。 Composition、DiagnosticReport、DocumentReference リソースを検索するときに、関連性に応じて検索結果を並べ替えることができます。詳細については、医療検索結果を並べ替えるをご覧ください。
自然言語でクエリを投稿します。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec": { "snippetSpec": { "returnSnippet": true }, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } "summarySpec": { "summaryResultCount": 1, "includeCitations": true, "modelSpec": { "version": "MODEL_VERSION" } } }, "naturalLanguageQueryUnderstandingSpec": { "filterExtractionCondition": "ENABLED" } }'次のように置き換えます。
PROJECT_ID: 実際の Google Cloud プロジェクト ID。APP_ID: クエリする Vertex AI Search アプリの ID。QUERY: 自然言語のクエリ(「nsaids」、「患者の脂質検査結果は何ですか」、「最新の A1C の結果は何ですか」など)。クエリにアポストロフィ'が含まれている場合は、アポストロフィの数値文字参照'に置き換える必要があります。PATIENT_ID: データを検索する患者のリソース ID。MODEL_VERSION: 回答の生成に使用するモデル バージョン。MATCH_HIGHLIGHTING_CONDITION: 次の値を使用できる文字列。MATCH_HIGHLIGHTING_DISABLED: すべてのドキュメントで一致する単語のハイライト表示をオフにします。MATCH_HIGHLIGHTING_ENABLED: すべてのドキュメントで一致する部分のハイライト表示をオンにします。このフィールドを空のままにするか、指定しない場合、一致する単語のハイライト表示はMATCH_HIGHLIGHTING_DISABLEDに設定され、すべてのドキュメントでオフになります。