プロセッサ バージョンのトレーニング、アップトレーニング、評価を行うには、ドキュメントのラベル付きデータセットが必要です。
このページでは、プロセッサ スキーマのラベルを、データセットにインポートされたドキュメントに適用する方法について説明します。
このページは、トレーニング、アップトレーニング、評価をサポートするプロセッサをすでに作成していることを前提としています。プロセッサがサポートされている場合は、 Google Cloud コンソールに [トレーニング] タブが表示されます。また、データセットを作成し、ドキュメントをインポートして、プロセッサ スキーマを定義していることも前提としています。
生成 AI 抽出のフィールドに名前を付ける
フィールドの命名方法は、生成 AI を使用してフィールドを抽出する際の精度に影響します。フィールドに名前を付ける場合は、次のベスト プラクティスをおすすめします。
ドキュメントで説明されている言語と同じ言語でフィールドに名前を付けます。たとえば、ドキュメントに
Employer Addressと説明されているフィールドがある場合は、フィールドにemployer_addressという名前を付けます。emplr_addrなどの略語は使用しないでください。現在、フィールド名でスペースはサポートされていません: スペースの代わりに
_を使用します。たとえば、First Nameはfirst_nameという名前になります。名前を繰り返し処理して精度を向上させる: Document AI には、フィールド名を変更できないという制限があります。別の名前をテストするには、エンティティ名の変更ツールを使用して、データセット内の古いエンティティの名前を新しい名前に更新し、データセットをインポートして、プロセッサで新しいエンティティを有効にし、既存のフィールドを無効にするか削除します。
ゼロショット学習と少数ショット学習
Gemini を搭載したモデルは、ゼロショット学習と少数ショット学習を備えており、トレーニング データがほとんどない状態でも高性能なモデルを作成できます。
ゼロショット学習は、事前トレーニング済みのモデルが、テスト中に遭遇したことのないクラスとエンティティを認識して分類することを学習する ML の例です。
少数ショット学習は、クラスごとに少数のトレーニング例のみを使用して、新しいクラスとエンティティを認識して分類するようにモデルをトレーニングする手法です。大規模でラベル付けが適切に行われたデータセットで事前トレーニングされたモデルの知識を活用して、フューショット タスクのパフォーマンスを向上させます。
トレーニング データセットが整然としていて、ラベルが慎重に付けられている場合、フューショットはより効果的になります。通常、これはモデルが学習するためのテスト例とトレーニング例がそれぞれ 10 個以上あることを意味します。
ラベル付けのオプション
ドキュメントにラベルを付ける方法は次のとおりです。
手動: Google Cloud コンソールでドキュメントに手動でラベルを付けます。
自動ラベル付け: 既存のプロセッサ バージョンを使用してラベルを生成する
事前にラベル付けされたドキュメントをインポートする: ラベル付けされたドキュメントがすでにある場合は、時間を節約できます。
Google Cloud コンソールで手動でラベルを付ける
[トレーニング] タブで、ドキュメントを選択してラベリング ツールを開きます。
ラベリング ツールの左側にあるスキーマラベルのリストから、[追加] 記号を選択してバウンディング ボックス ツールを選択し、ドキュメント内のエンティティをハイライト表示してラベルに割り当てます。
次のスクリーンショットでは、ドキュメント内の EMPL_SSN EMPLR_ID_NUMBER、EMPLR_NAME_ADDRESS、FEDERAL_INCOME_TAX_WH、SS_TAX_WH、SS_WAGES、WAGES_TIPS_OTHER_COMP フィールドにラベルが割り当てられています。
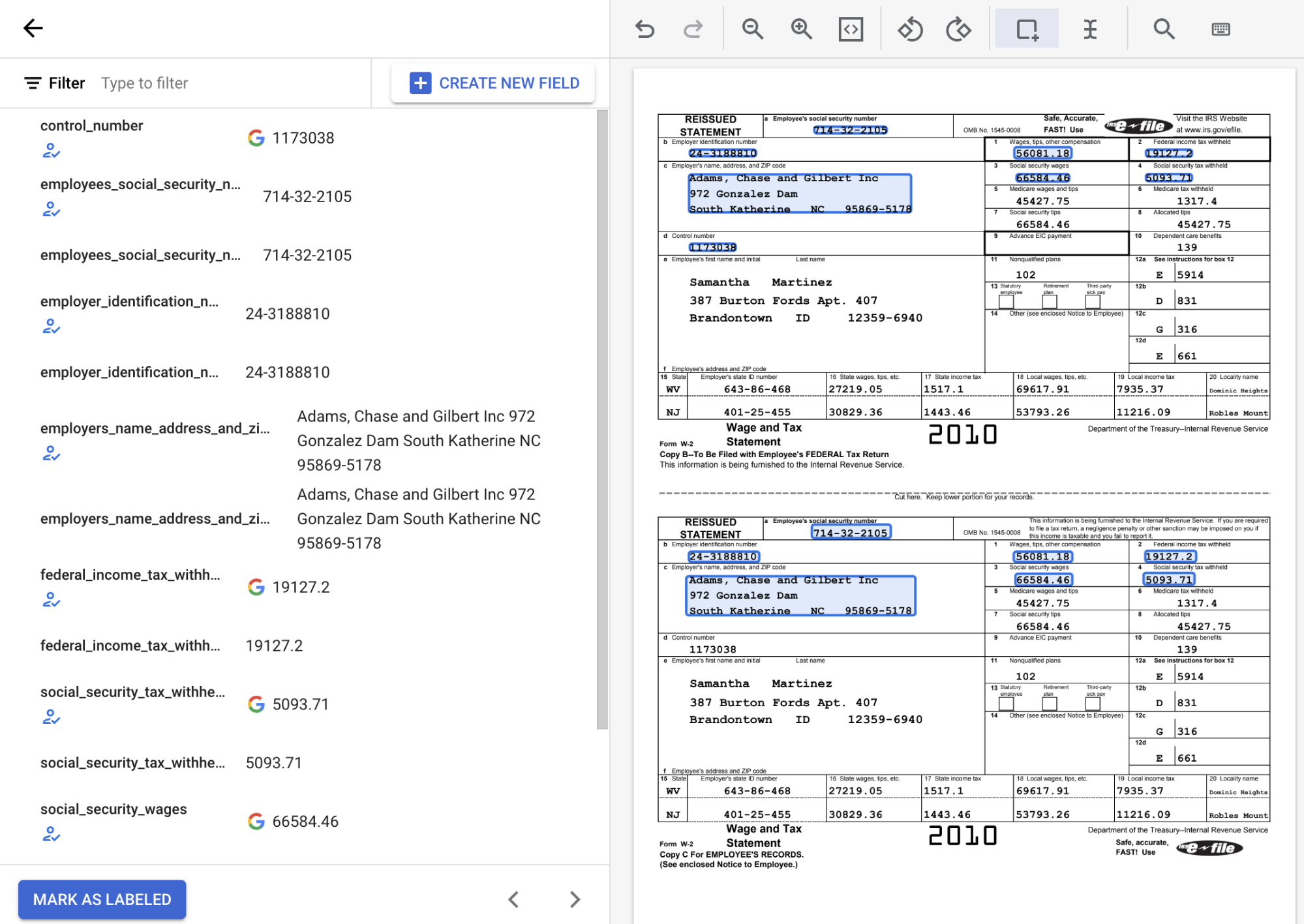
[境界ボックス] ツールでチェックボックス エンティティを選択する場合は、関連付けられたテキストではなく、チェックボックス自体のみを選択します。左側に表示されているチェックボックス エンティティが、ドキュメントの内容と一致するように選択または選択解除されていることを確認します。

親子エンティティにラベルを付ける場合は、親エンティティにラベルを付けないでください。親エンティティは、子エンティティのコンテナにすぎません。子エンティティのみにラベルを付けます。親エンティティは自動的に更新されます。
子エンティティにラベルを付ける場合は、最初の子エンティティにラベルを付け、関連する子エンティティをその行に関連付けます。このようなエンティティに初めてラベルを付けるときに、2 番目の子エンティティでこのことに気づきます。たとえば、請求書で 説明というラベルを付けると、他のエンティティと同じように見えます。ただし、次に quantity をラベル付けすると、親を選択するよう求められます。
新しい広告申込情報ごとに [新しい親エンティティ] を選択して、広告申込情報ごとにこの手順を繰り返します。
親子エンティティは、最大 3 レイヤのネストを含むテーブルでサポートされています。基盤モデルは 3 つの階層のフィールド(祖父母、親、子)をサポートしているため、子エンティティは 1 つの階層の子を持つことができます。ネストの詳細については、3 レベルのネストをご覧ください。
早見表
表にラベルを付ける場合、各行に何度もラベルを付けるのは面倒な場合があります。行エンティティ構造を複製できる非常に便利なツールがあります。この機能は、水平方向に配置された行でのみ機能します。
- まず、通常どおり 1 行目にラベルを付けます。
次に、行を表す親エンティティにポインタを合わせます。[行を追加] を選択します。行がテンプレートになり、さらに行を作成できるようになります。
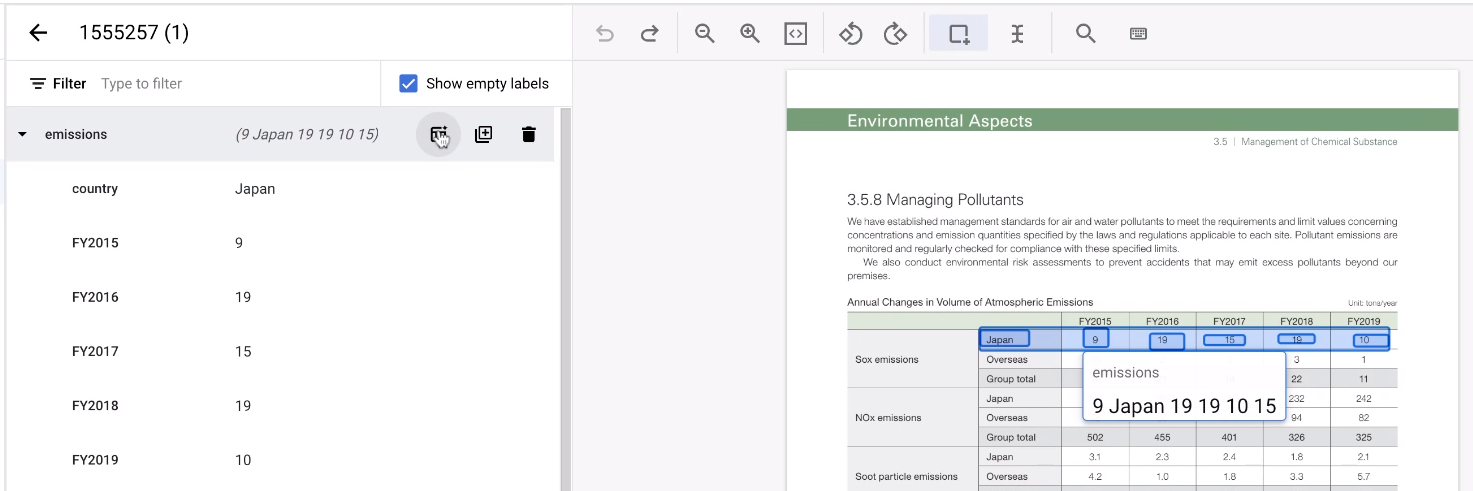
表の残りの領域を選択します。
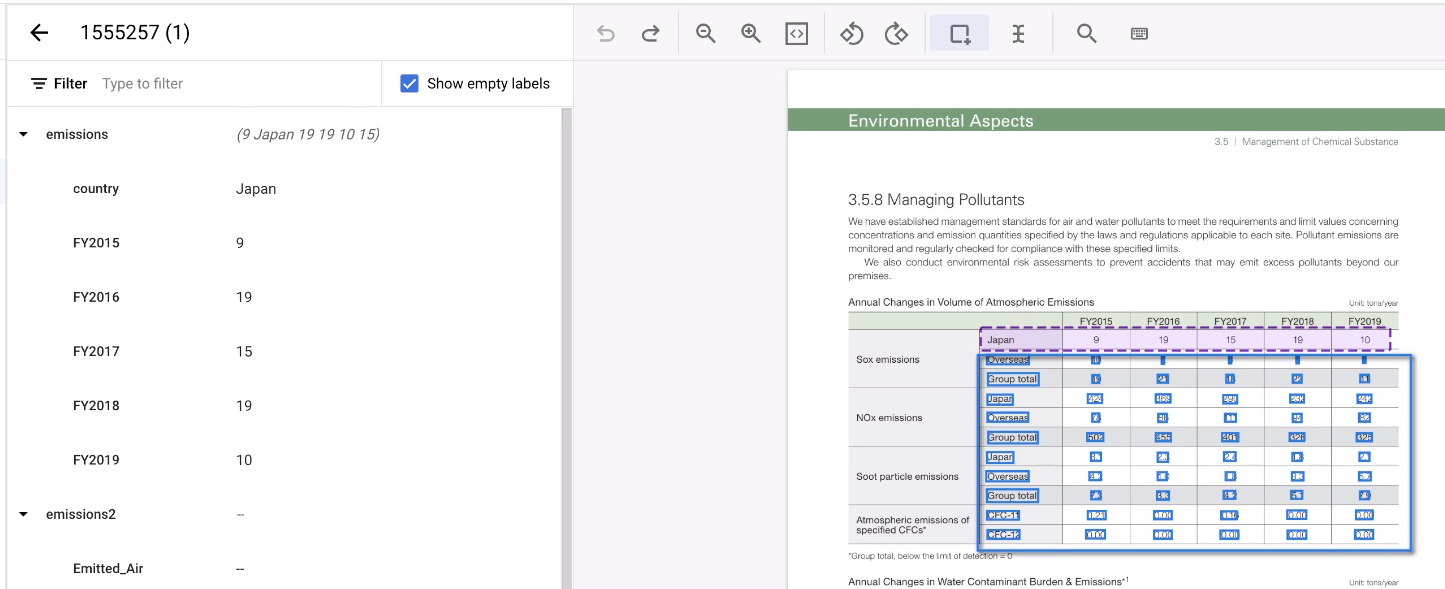
このツールはアノテーションを推測しますが、通常は機能します。処理できないテーブルについては、手動でアノテーションを付けます。
コンソールでキーボード ショートカットを使用する
使用可能なキーボード ショートカットを確認するには、ラベリング コンソールの右上にある メニューを選択します。次の表に示すように、キーボード ショートカットの一覧が表示されます。
| アクション | ショートカット |
|---|---|
| ズームイン | Alt + =(macOS では Option + =) |
| ズームアウト | Alt + -(macOS では Option + -) |
| サイズに合わせてズーム | Alt + 0(macOS では Option + 0) |
| スクロールでズーム | Alt + スクロール(macOS では Option + スクロール) |
| パン | スクロール |
| 逆パン | Shift+スクロール |
| ドラッグでパン | スペース + マウスのドラッグ |
| 元に戻す | Ctrl+Z(macOS の場合は Control+Z) |
| やり直し | Ctrl+Shift+Z(macOS の場合は Control+Shift+Z) |
自動ラベル付け
入手可能な場合、既存のバージョンのプロセッサを使用してラベル付けを開始できます。
自動ラベル付けは、インポート時に開始できます。すべてのドキュメントは、指定されたプロセッサ バージョンを使用してアノテーションが付けられます。
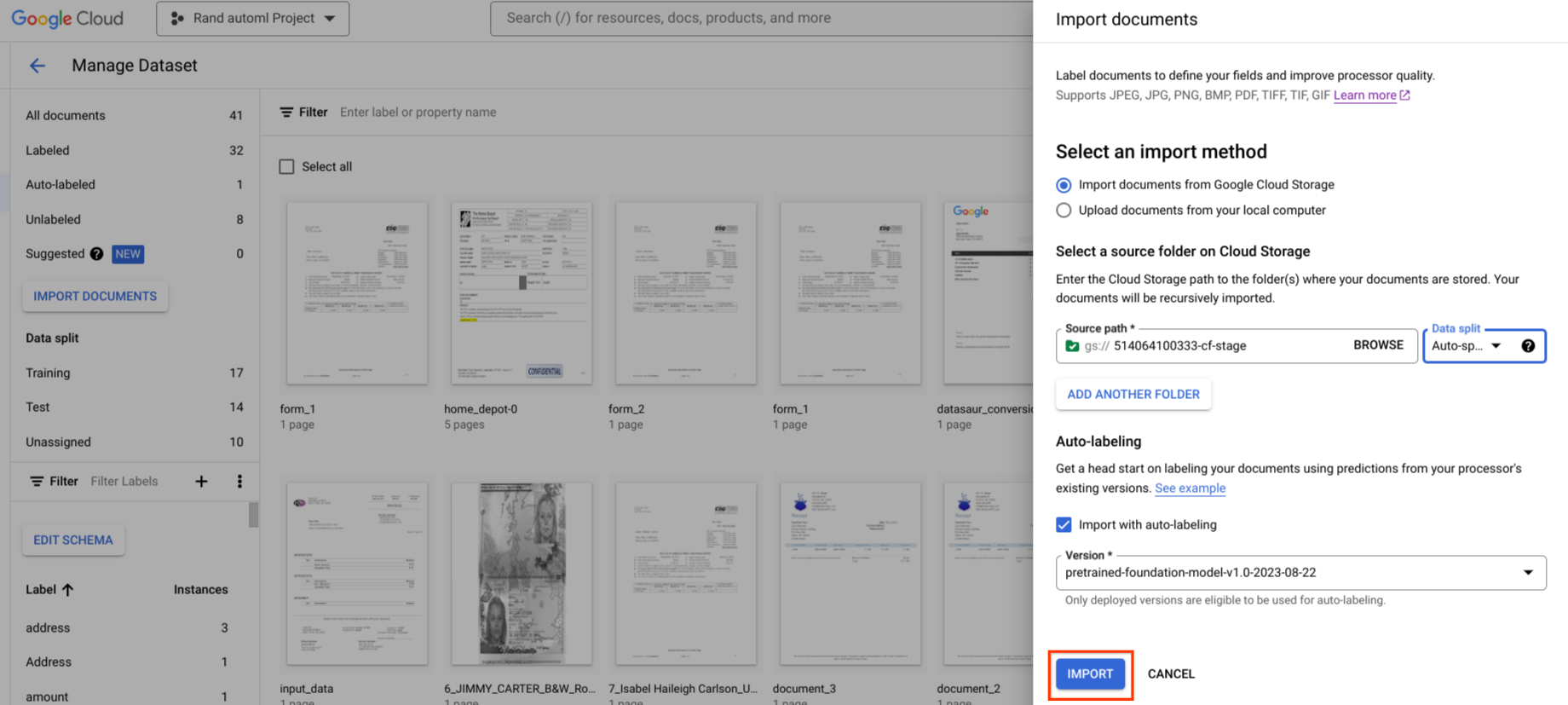
自動ラベル付けは、ラベルなしカテゴリまたは自動ラベル付けカテゴリのドキュメントのインポート後に開始できます。選択したドキュメントはすべて、指定したプロセッサ バージョンを使用してアノテーションが付けられます。
ラベル付きとマークしないと、自動ラベル付けされたドキュメントでトレーニングやアップトレーニングを行ったり、テストセットで使用したりすることはできません。自動的にラベル付けされたアノテーションを手動で確認して修正し、[ラベル付け済みとしてマーク] を選択して修正を保存します。その後、必要に応じてドキュメントを割り当てることができます。
事前にラベル付けされたドキュメントをインポートする
JSON Document ファイルをインポートできます。ドキュメントの entity がプロセッサ スキーマのラベルと一致する場合、entity はインポーターによってラベル インスタンスに変換されます。JSON ドキュメント ファイルを取得するには、いくつかの方法があります。
別のプロセッサからデータセットをエクスポートする。データセットをエクスポートするをご覧ください。
既存のプロセッサに処理リクエストを送信する。
インポート ツールキットを使用して、別のシステム(CSV 形式のラベルなど)の既存のラベルを JSON ドキュメントに変換します。
ドキュメントのラベル付けに関するベスト プラクティス
高品質のプロセッサをトレーニングするには、一貫性のあるラベル付けが必要です。次のことをおすすめします。
ラベル付けの手順を作成する: 手順には、一般的なケースと特殊なケースの両方の例を含める必要があります。ヒント:
- アノテーションすべきフィールドと、ラベル付けの一貫性を保つ方法を説明します。たとえば、「amount」にラベルを付ける場合は、通貨記号にラベルを付けるかどうかを指定します。ラベルに一貫性がない場合、プロセッサの品質が低下します。
- ラベルタイプが
REQUIRED_ONCEまたはOPTIONAL_ONCEであっても、エンティティのすべての出現箇所にラベルを付けます。たとえば、invoice_idがドキュメントに 2 回出現する場合は、その両方にラベルを付けます。 - 通常は、まずデフォルトの境界ボックスツールでラベル付けすることをおすすめします。失敗した場合は、テキスト選択ツールを使用します。
- OCR でラベルの値が正しく検出されない場合は、値を手動で修正しないでください。そうなると、トレーニング目的で使用できなくなります。
ラベル付けの手順の例を次に示します。
- アノテーターのトレーニング: アノテーターがガイドラインを理解し、体系的なエラーなしでガイドラインに沿って作業できることを確認します。これを実現する方法の 1 つは、同じドキュメント セットに異なるトレーニーがアノテーションを付けることです。トレーナーは、各受講者のアノテーション作業の品質を確認できます。このプロセスは、トレーニング対象者がベンチマーク レベルの精度に達するまで繰り返す必要がある場合があります。
- 最初のレビュー: 新しいラベラーがユースケース用にラベル付けした最初の数件(10 件程度)のドキュメントは、大量のドキュメントにラベル付けする前にレビューする必要があります。これにより、修正が必要な大量の間違いを防ぐことができます。
- アノテーションの品質レビュー: アノテーションは手間のかかる作業であるため、トレーニングを受けたアノテーターでもミスを犯す可能性があります。アノテーションは、少なくとも 1 人のトレーニングを受けたアノテーターによってチェックされることをおすすめします。
説明プロンプトを追加する
カスタム抽出ツールとカスタム分類ツールのスキーマにラベルを追加するときに、ラベルの説明を追加できます。これにより、ラベルを識別するためのプロンプトが提供され、プロセッサのトレーニングに役立ちます。言い回しを変えて、回答の質をテストできます。(例: 「合計金額」、「請求額の合計」、「請求書の合計金額」)。
データセットを再同期する
再同期により、データセットの Cloud Storage フォルダと Document AI のメタデータの内部インデックスの整合性が保たれます。これは、Cloud Storage フォルダを誤って変更してしまい、データを同期したい場合に便利です。
再同期するには:
[Processor Details] タブの [Storage location] 行の横にある を選択し、[Re-sync Dataset] を選択します。
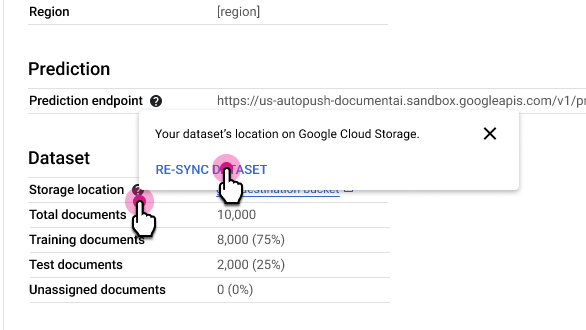
使用上の注意:
- Cloud Storage フォルダからドキュメントを削除すると、再同期によってデータセットから削除されます。
- Cloud Storage フォルダにドキュメントを追加しても、再同期ではデータセットに追加されません。ドキュメントを追加するには、ドキュメントをインポートします。
- Cloud Storage フォルダ内のドキュメント ラベルを変更すると、再同期によってデータセット内のドキュメント ラベルが更新されます。
データセットを移行する
インポートとエクスポートを使用すると、データセット内のすべてのドキュメントを 1 つのプロセッサから別のプロセッサに移動できます。これは、異なるリージョンまたは Google Cloud プロジェクトにプロセッサがある場合、ステージングと本番環境で異なるプロセッサがある場合、または一般的なオフライン消費の場合に役立ちます。
エクスポートされるのはドキュメントとそのラベルのみです。プロセッサ スキーマ、ドキュメントの割り当て(トレーニング/テスト/未割り当て)、ドキュメントのラベル付けステータス(ラベル付き、ラベルなし、自動ラベル付け)などのデータセット メタデータは、エクスポートされません。
データセットをコピーしてインポートし、ターゲット プロセッサをトレーニングすることは、ソース プロセッサをトレーニングすることとまったく同じではありません。これは、トレーニング プロセスの開始時にランダム値が使用されるためです。importProcessorVersion API 呼び出しを使用して、プロジェクト間でまったく同じモデルをインポート移行します。これは、ポリシーで許可されている場合に、プロセッサを上位環境(開発環境からステージング環境、本番環境など)に移行する場合のベスト プラクティスです。
データセットのエクスポート
すべてのドキュメントを JSON Document ファイルとして Cloud Storage フォルダにエクスポートするには、[データセットをエクスポート] を選択します。
重要な留意点:
エクスポート時に、Test、Train、Unassigned の 3 つのサブフォルダが作成されます。ドキュメントは、これらのサブフォルダに適切に配置されます。
ドキュメントのラベル付けステータスはエクスポートされません。後でドキュメントをインポートしても、自動ラベル付けはされません。
Cloud Storage が別の Google Cloud プロジェクトにある場合は、Document AI がその場所にファイルを書き込めるようにアクセス権を付与してください。具体的には、Document AI のコア サービス エージェント
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.comに Storage オブジェクト作成者ロールを付与する必要があります。詳細については、サービス エージェントをご覧ください。
データセットのインポート
手順は、ドキュメントをインポートすると同じです。
選択的ラベル付けユーザーガイド
選択的ラベル付けは、ラベル付けするドキュメントに関する推奨事項に役立ちます。多様なトレーニング データセットとテスト データセットを作成して、代表的なモデルをトレーニングできます。選択的ラベリングが実行されるたびに、データセットから最も多様なドキュメント(最大 30 個)が選択されます。
推奨ドキュメントを取得する
CDE プロセッサを作成してドキュメントをインポートします。
- トレーニングには少なくとも 100 個(テストには 25 個)が必要です。
- 十分な数のドキュメントがインポートされ、選択的ラベル付けが完了すると、情報バーが表示されます。
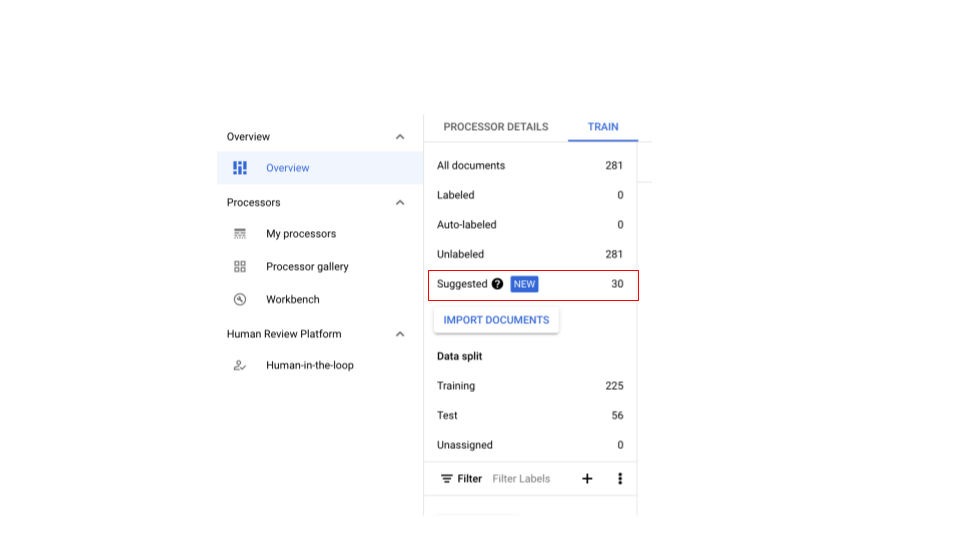
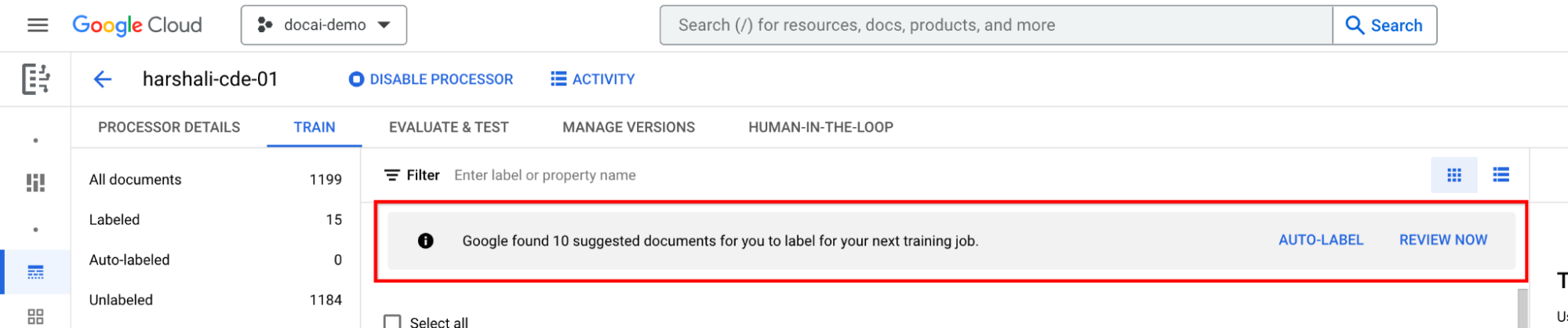
推奨ドキュメントがゼロの CDE プロセッサの場合は、サンプリング用に十分なドキュメントを分割のいずれかにインポートします。
- これにより、[候補のカテゴリ] に候補のドキュメントが表示されるようになります。提案されたドキュメントを手動でリクエストできるはずです。
- 上部に新しいフィルタが追加され、候補のドキュメントをフィルタできるようになりました。
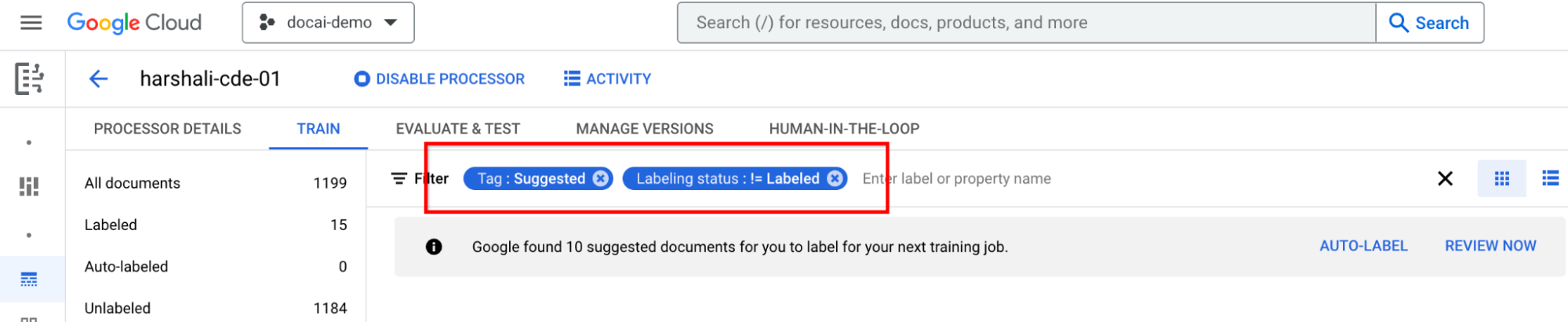
ドキュメントの候補にラベルを付ける
左側のラベルリスト パネルで [推奨カテゴリ] に移動します。これらのドキュメントのラベル付けを開始します。
プロセッサがトレーニングされている場合は、情報バーの [自動ラベル] を選択します。推奨ドキュメントにラベルを付けます。
プロセッサに移動するドキュメントが提案されたら、バーの [今すぐ確認] を選択します。自動的にラベル付けされたドキュメントはすべて、正確性を確認する必要があります。審査を開始します。
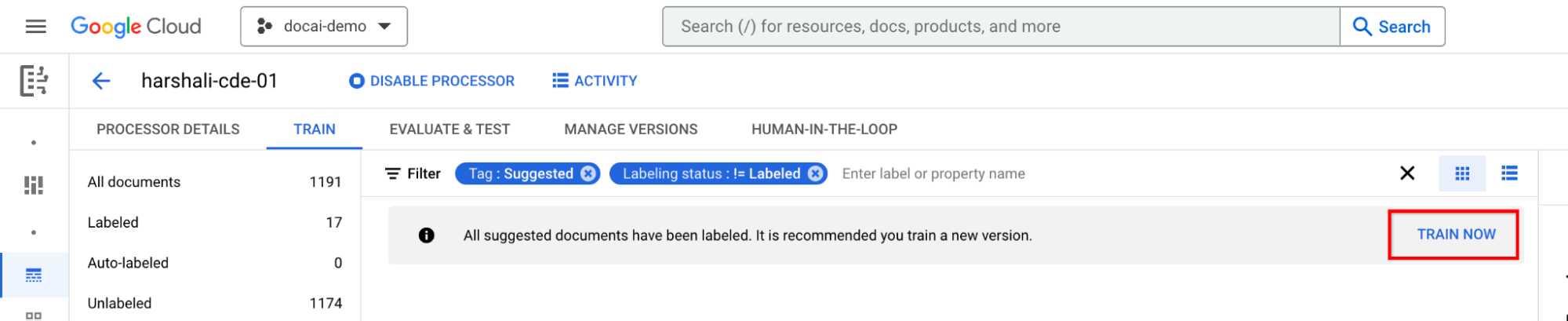
すべての推奨ドキュメントにラベルを付けた後にトレーニングする
情報バーの [今すぐトレーニング] に移動します。候補のドキュメントにラベルが付けられると、トレーニングを推奨する次の情報バーが表示されます。
サポートされている機能と制限事項
| 機能 | 説明 | サポート対象 |
|---|---|---|
| 古いプロセッサのサポート | 以前にインポートしたデータセットを含む古いプロセッサでは、うまく動作しない可能性がある |