Pemisah kustom
Pemisah khusus dirancang untuk memisahkan dokumen komposit (dokumen yang terdiri dari beberapa kelas) menjadi sejumlah dokumen kelas tunggal dengan mengidentifikasi setiap dokumen logis. Misalnya, paket hipotek berisi beberapa kelas di dalamnya seperti pendaftaran, verifikasi penghasilan, dan tanda pengenal berfoto. Prosesor pemisah kustom, agar dapat digunakan, dilatih dari awal menggunakan dokumen Anda sendiri dan kelas kustom.
Deskripsi dan penggunaan pemisah
Anda membuat pemisah kustom yang secara khusus cocok dengan dokumen Anda, serta dilatih dan dievaluasi dengan data Anda. Pemroses ini mengidentifikasi kelas dokumen dari serangkaian kelas yang ditentukan pengguna. Kemudian, Anda dapat menggunakan prosesor terlatih ini pada dokumen produksi. Biasanya, Anda akan menggunakan pemisah kustom pada file yang terdiri dari berbagai jenis dokumen logis, lalu menggunakan identifikasi kelas masing-masing untuk meneruskan dokumen ke pemroses ekstraksi yang sesuai guna mengekstrak entitas.
Karena model ML tidak sempurna dan memiliki tingkat error tertentu, dan karena error dalam pemisahan biasanya sangat bermasalah (pemisahan yang buruk membuat dua dokumen salah dan menyebabkan error ekstraksi), praktik terbaiknya adalah selalu melakukan langkah peninjauan oleh manusia setelah prediksi pemisahan, tetapi sebelum pemisahan file yang sebenarnya. Berdasarkan persyaratan bisnis, ada alternatif untuk tidak selalu melakukan peninjauan oleh manusia:
- Gunakan skor keyakinan dalam prediksi untuk memutuskan apakah akan melewati peninjauan manual (jika cukup tinggi). Nilai minimum skor keyakinan tersebut harus ditentukan berdasarkan data historis tentang tingkat error pada skor keyakinan tertentu. Hal ini harus menjadi keputusan bisnis berdasarkan toleransi proses bisnis terhadap error dan persyaratan untuk melewati peninjauan manual.
- Dalam beberapa kasus penggunaan, dokumen yang dibagi dapat langsung diarahkan ke pengekstrakan yang sesuai menurut kelas yang diprediksi. Kemudian, jika ekstraksi tidak lengkap atau memiliki skor keyakinan yang rendah, pisahkan dokumen yang dibagi dan picu dokumen komposit asli dan keputusan pemisahan untuk ditinjau. Hal ini memiliki persyaratan alur kerja yang cukup kompleks.
Membuat pemisah kustom di konsol Google Cloud
Panduan memulai ini menjelaskan cara menggunakan Document AI untuk membuat dan melatih pemisah kustom yang memisahkan dan mengklasifikasikan dokumen pengadaan. Sebagian besar persiapan dokumen telah selesai, sehingga Anda dapat berfokus pada pembuatan pemisah kustom.
Alur kerja umum untuk membuat dan menggunakan pemisah kustom adalah sebagai berikut:
- Buat pemisah kustom di Document AI.
- Buat set data menggunakan bucket Cloud Storage kosong.
- Tentukan dan buat skema prosesor (kelas).
- Mengimpor dokumen.
- Tetapkan dokumen ke set pelatihan dan pengujian.
- Menganotasi dokumen secara manual di Document AI atau dengan tugas pelabelan.
- Latih pemroses.
- Evaluasi pemroses.
- Deploy pemroses.
- Uji prosesor.
- Gunakan pemroses pada dokumen Anda.
Jika Anda menyimpan dokumen dalam folder terpisah menurut kelas, Anda dapat melewati langkah 6 dengan menentukan kelas pada saat impor.
Untuk mengikuti panduan langkah demi langkah tugas ini langsung di Google Cloud konsol, klik Pandu saya:
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Di konsol Google Cloud , di bagian Document AI, buka halaman Workbench.
Untuk Custom Document Splitter, pilih
Create processor .
Di menu Buat pemroses, masukkan nama untuk pemroses Anda, seperti
my-custom-document-splitter.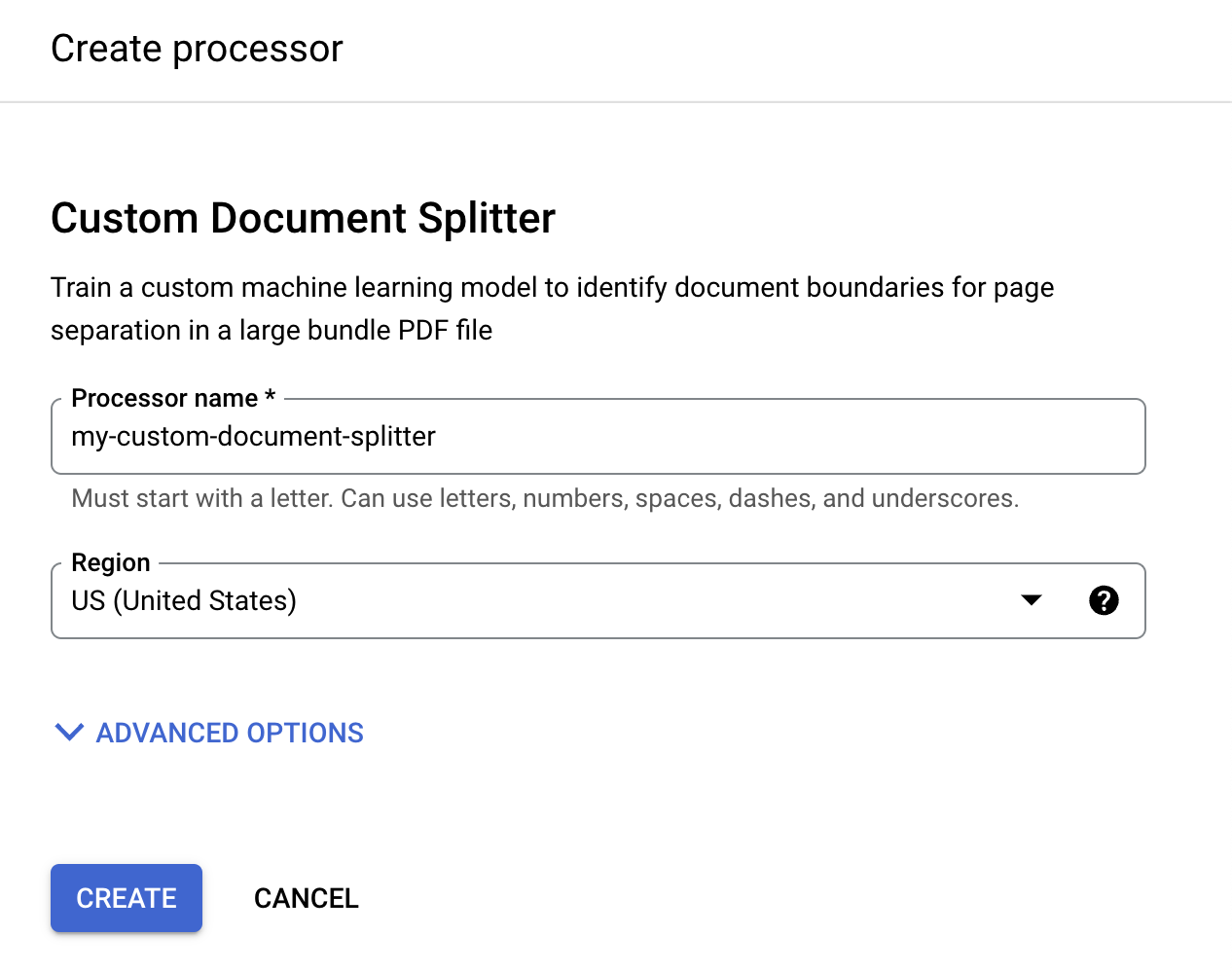
Pilih wilayah yang terdekat dengan Anda.
Pilih Create. Tab Processor Details akan muncul.
- Jika Anda menginginkan penyimpanan yang dikelola Google, pilih opsi tersebut.
- Jika Anda ingin menggunakan penyimpanan Anda sendiri untuk menggunakan Kunci Enkripsi yang Dikelola Pelanggan (CMEK), pilih Saya akan menentukan lokasi penyimpanan saya sendiri dan ikuti prosedur selanjutnya.
Buka tab
Latih prosesor Anda.Pilih Tetapkan lokasi set data. Anda akan diminta untuk memilih atau membuat bucket atau folder Cloud Storage yang kosong.
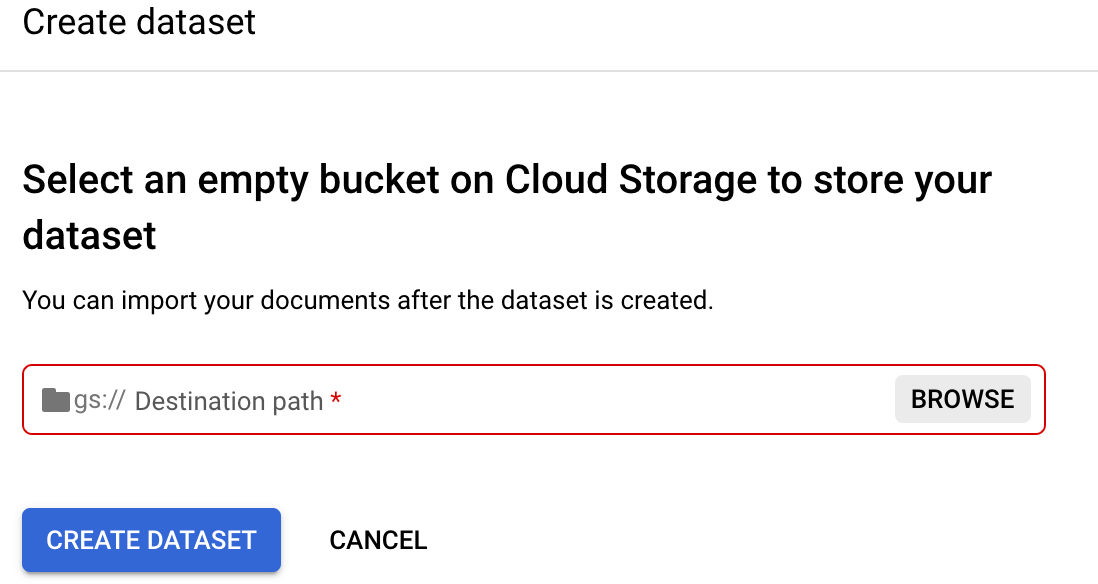
Pilih Jelajahi untuk membuka Pilih folder.
Pilih ikon Buat bucket baru dan ikuti perintah untuk membuat bucket baru. Setelah Anda membuat bucket, halaman Pilih folder akan muncul untuk bucket tersebut. Untuk mengetahui informasi selengkapnya tentang cara membuat bucket Cloud Storage, lihat Bucket Cloud Storage.
Di halaman Pilih folder untuk bucket Anda, pilih tombol Pilih di bagian bawah dialog.
Di tab Latih, pilih
Edit Skema di kiri bawah. Halaman Kelola label akan terbuka.Pilih
Buat label .Masukkan nama untuk label. Pilih Create. Lihat Menentukan skema pemroses untuk mengetahui petunjuk mendetail tentang cara membuat dan mengedit skema.
Buat setiap label berikut untuk skema prosesor.
bank_statementform_1040form_w2form_w9paystub
Pilih
Simpan setelah label selesai.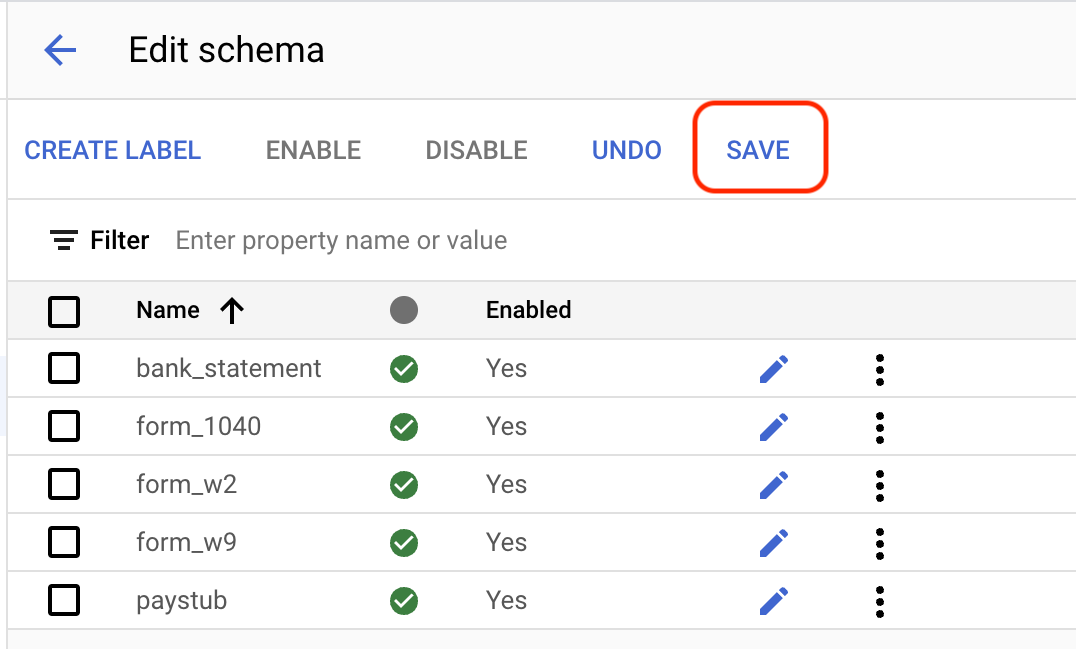
Di tab Train, pilih
Impor dokumen .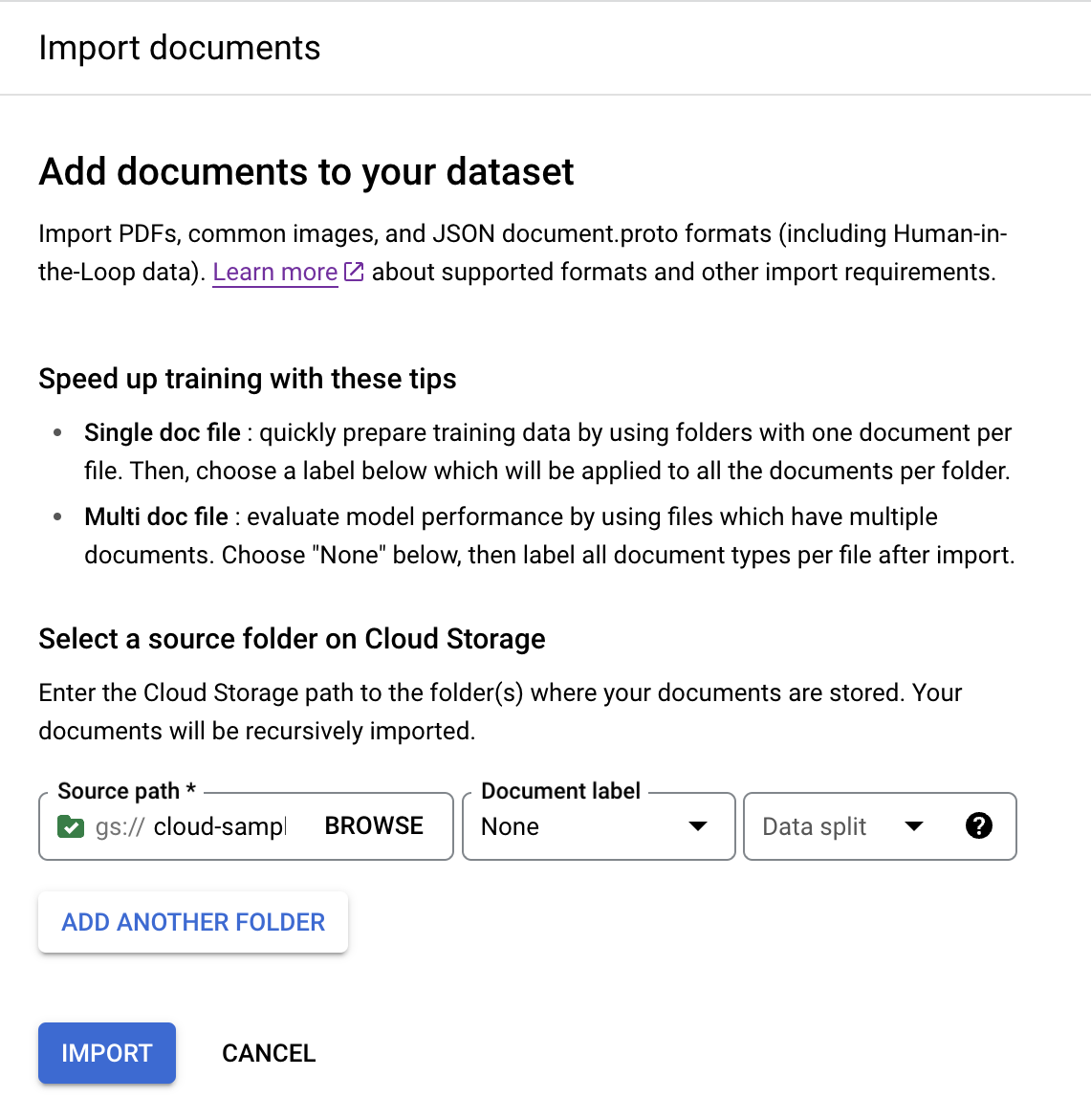
Untuk contoh ini, masukkan jalur ini di
Jalur sumber . Ini berisi satu PDF dokumen.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-UnlabeledTetapkan
Label dokumen sebagai Tidak ada.Tetapkan dropdown
Dataset split ke Unassigned.Dokumen dalam folder ini tidak diberi label atau ditetapkan ke set pengujian atau pelatihan secara default.
Pilih
Impor . Document AI membaca dokumen dari bucket ke dalam set data. Bucket impor tidak diubah atau dibaca dari bucket setelah impor selesai.- Klik Impor dokumen.
Masukkan jalur berikut di Source path. Bucket ini berisi dokumen tanpa label dalam format PDF.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelDari daftar Data split, pilih Auto-split. Hal ini akan otomatis membagi dokumen dengan 80% di set pelatihan, dan 20% di set pengujian.
Di bagian Terapkan label, pilih Pilih label.
Untuk contoh dokumen ini, pilih lainnya.
Klik Import dan tunggu hingga dokumen selesai diimpor. Anda dapat keluar dari halaman ini dan kembali lagi nanti.
Kembali ke tab Train, lalu pilih
dokumen untuk membuka konsol Label management.Dokumen ini berisi beberapa grup halaman yang perlu diidentifikasi dan diberi label. Pertama, Anda perlu mengidentifikasi titik pemisahan. Gerakkan kursor di antara halaman 1 dan 2 dalam tampilan gambar, lalu pilih simbol
+ .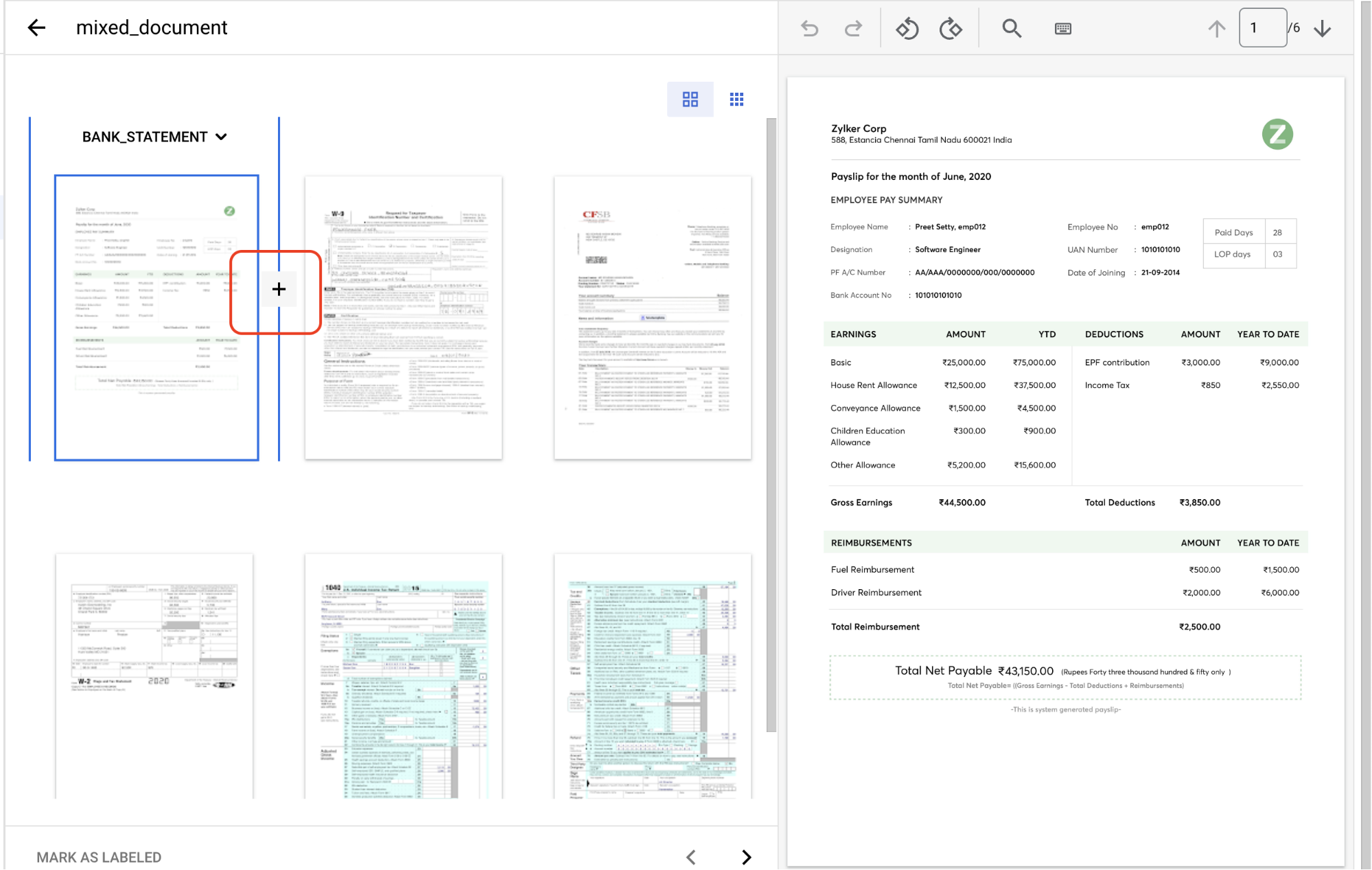
Buat titik pemisahan sebelum nomor halaman berikut: 2, 3, 4, 5.
Konsol Anda akan terlihat seperti ini setelah selesai.
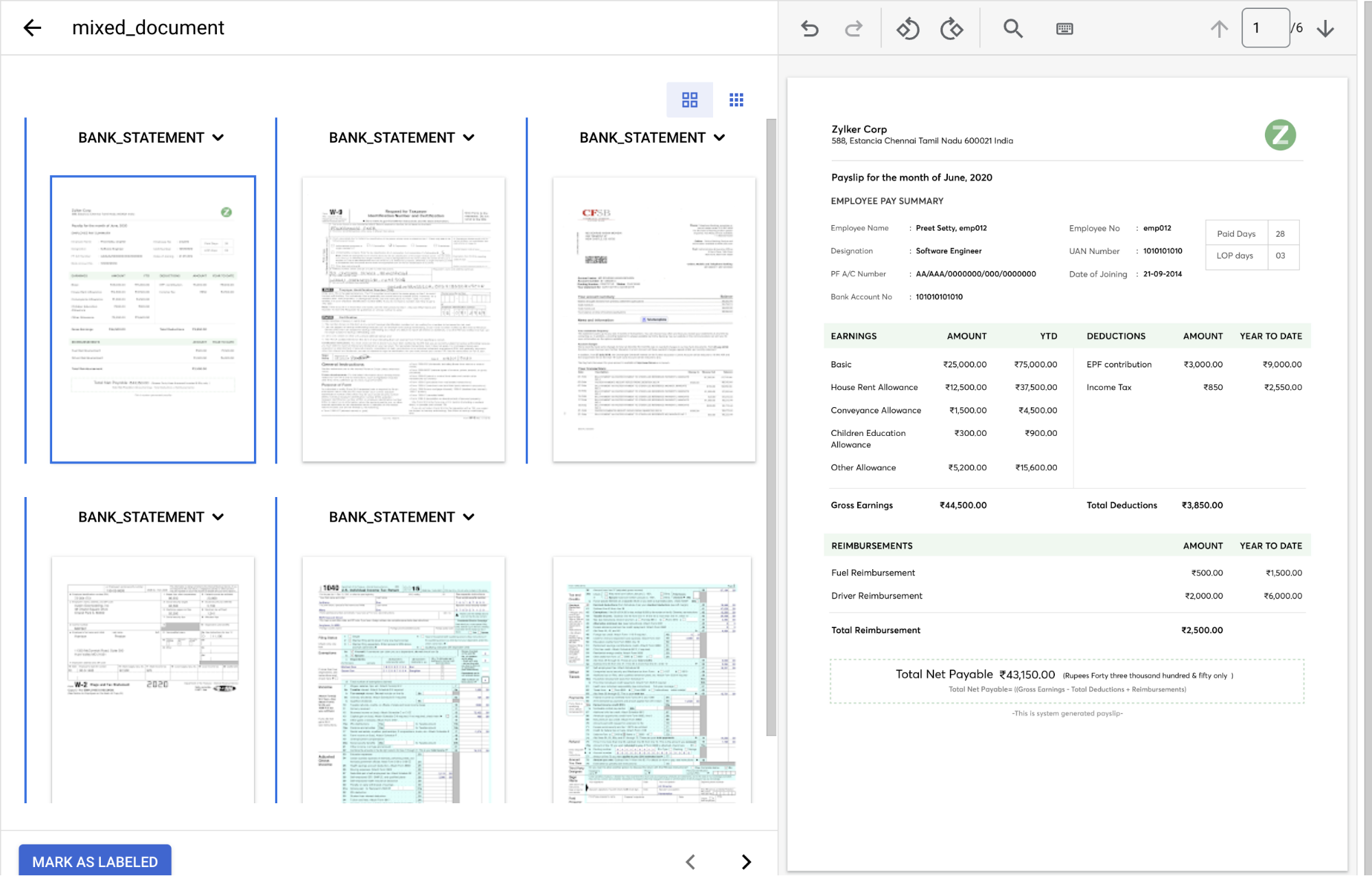
Di
dropdown Jenis dokumen , pilih label yang sesuai untuk setiap grup halaman.Halaman Jenis dokumen 1 paystub2 form_w93 bank_statement4 form_w25 & 6 form_1040Dokumen berlabel akan terlihat seperti ini setelah selesai:
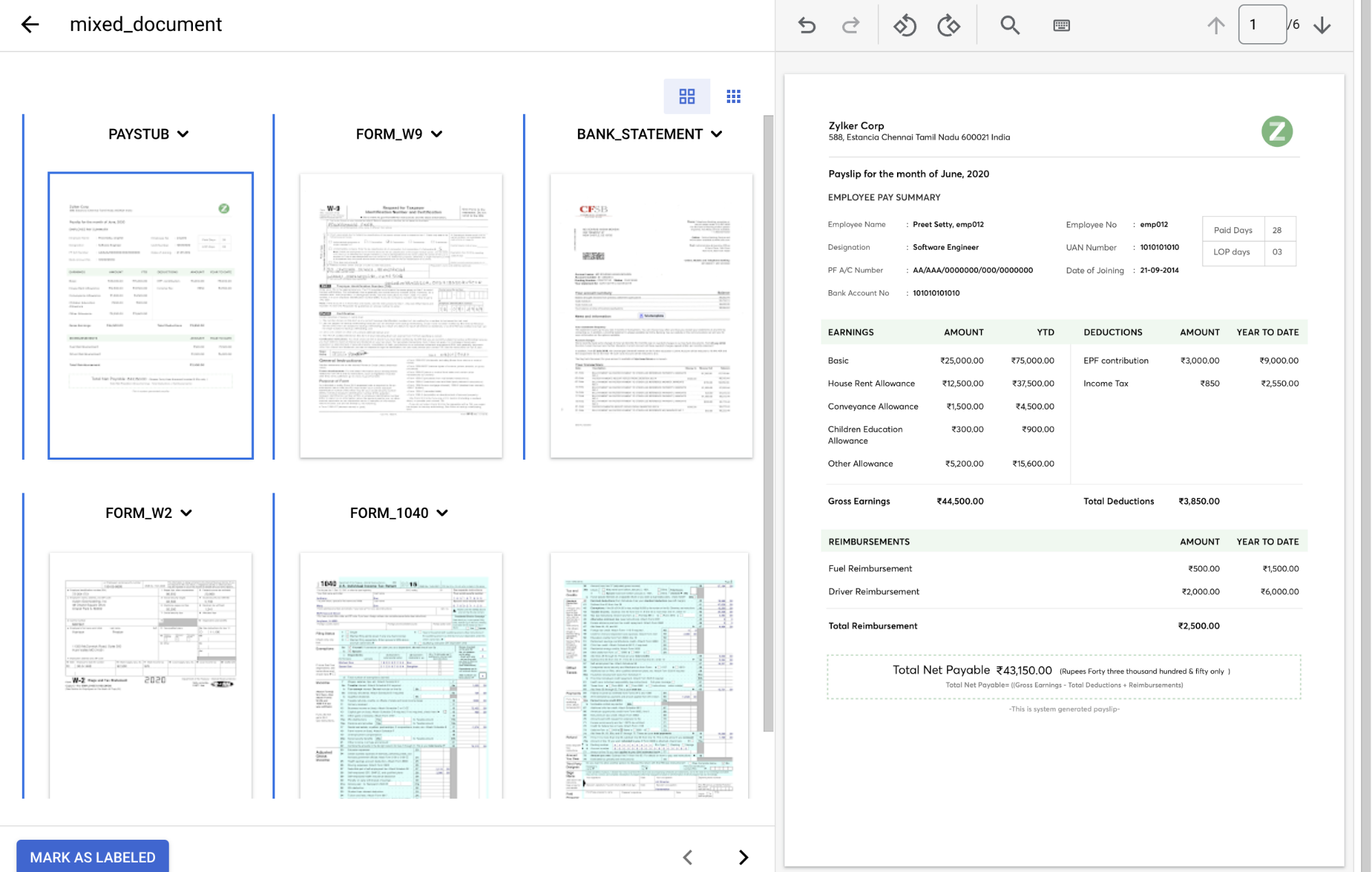
Pilih
Tandai sebagai Berlabel setelah Anda selesai memberi anotasi pada dokumen.Di tab Train, panel sebelah kiri menunjukkan bahwa 1 dokumen telah diberi label.
Di tab Train, centang kotak
Pilih Semua .Dari daftar
Tetapkan ke Set , pilih Training.Di tab Train, pilih
Impor dokumen .Masukkan jalur berikut di
Source path . Folder ini berisi PDF laporan mutasi bank.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statementTetapkan
Label dokumen sebagaibank_statement.Di menu
Pemisahan set data , tetapkan ke Pemisahan otomatis. Hal ini akan otomatis membagi dokumen menjadi 80% dalam set pelatihan dan 20% dalam set pengujian.Pilih
Tambahkan Folder Lain untuk menambahkan folder lainnya.Ulangi langkah-langkah sebelumnya dengan jalur dan label dokumen berikut:
Jalur bucket Label dokumen cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystubKonsol akan terlihat seperti ini setelah selesai:
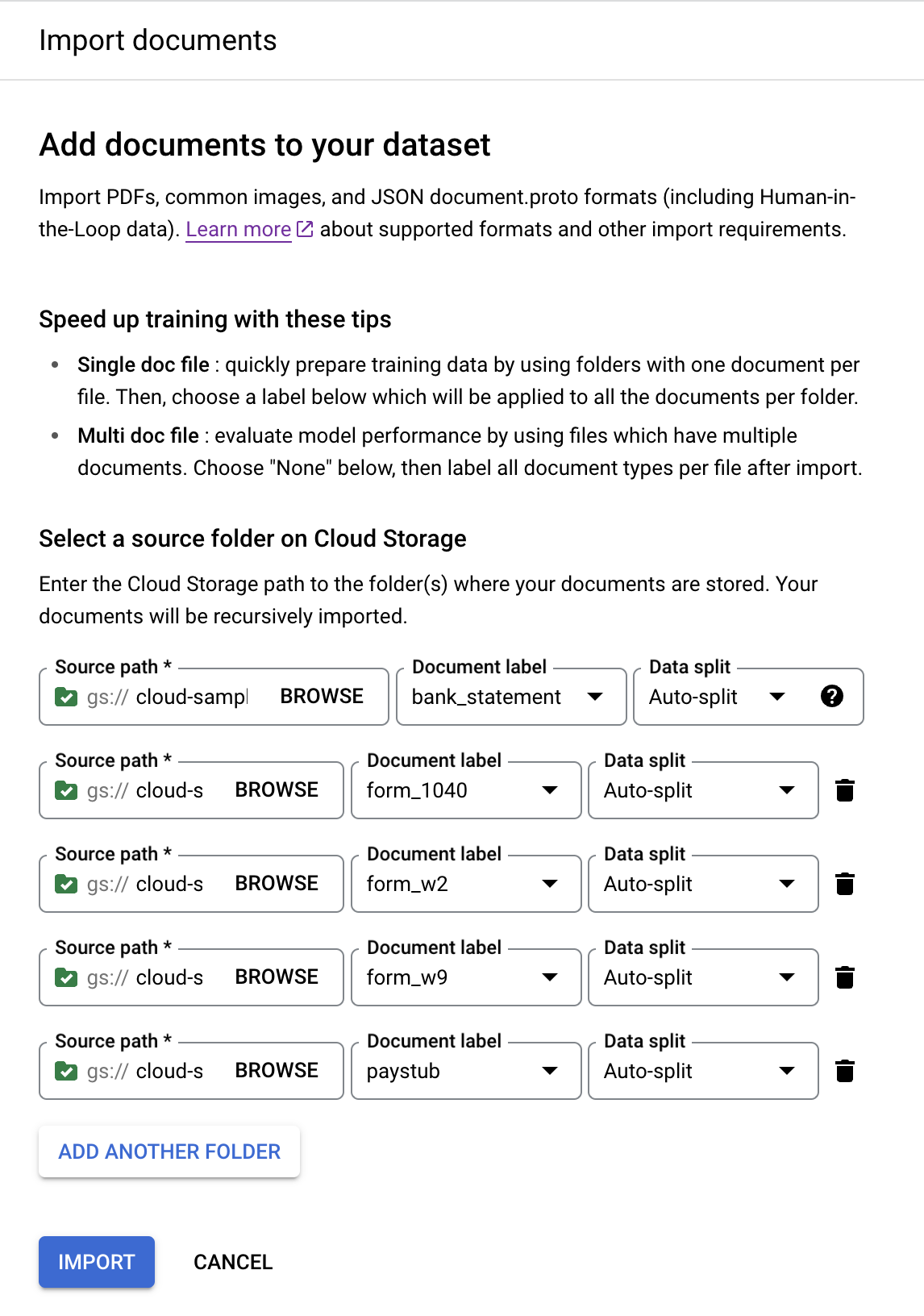
Pilih
Impor . Proses impor memerlukan waktu beberapa menit.Di tab Train, pilih
Impor dokumen .Masukkan jalur berikut di
Source path .cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-LabeledTetapkan
Label dokumen sebagai Tidak ada.Setel dropdown
Dataset split ke Auto-split.Pilih
Impor .Pilih
Train New Version .Di kolom
Nama versi , masukkan nama untuk versi pemroses ini, sepertimy-cds-version-1.(Opsional) Pilih Lihat Statistik Label untuk menemukan informasi tentang label dokumen. Hal ini dapat membantu menentukan cakupan Anda. Pilih Tutup untuk kembali ke penyiapan pelatihan.
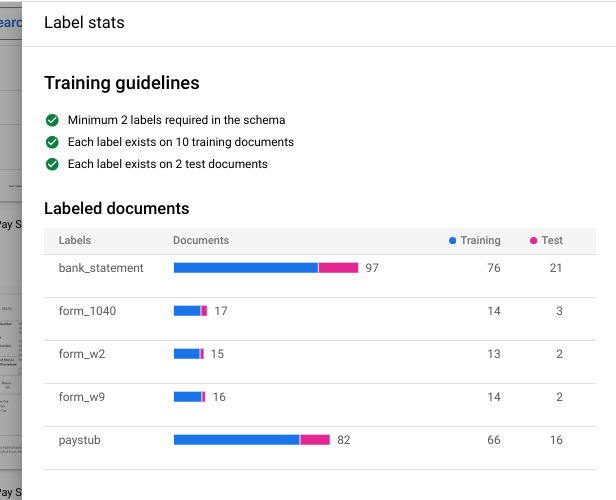
Pilih
Mulai pelatihan Anda dapat memeriksa status di panel sebelah kanan.Setelah pelatihan selesai, buka tab
Kelola Versi . Anda dapat melihat detail tentang versi yang baru saja Anda latih.Pilih
tiga titik vertikal di sebelah kanan versi yang ingin Anda deploy, lalu pilih Deploy version.Pilih
Deploy dari jendela pop-up.Proses deployment memerlukan waktu beberapa menit hingga selesai.
Setelah deployment selesai, buka tab
Evaluate & Test .Di halaman ini, Anda dapat melihat metrik evaluasi termasuk skor F1, presisi, dan perolehan untuk dokumen lengkap, dan masing-masing label. Untuk mengetahui informasi selengkapnya tentang evaluasi dan statistik, lihat Mengevaluasi prosesor.
Download dokumen yang belum pernah digunakan dalam pelatihan atau pengujian sebelumnya agar Anda dapat menggunakannya untuk mengevaluasi versi pemroses. Jika menggunakan data Anda sendiri, Anda akan menggunakan dokumen yang disisihkan untuk tujuan ini.
Pilih
Upload Test Document , lalu pilih dokumen yang baru saja Anda download.Halaman Analisis pemisah kustom akan terbuka. Output layar menunjukkan seberapa baik dokumen dibagi dan diklasifikasikan.
Konsol akan terlihat seperti ini setelah selesai:
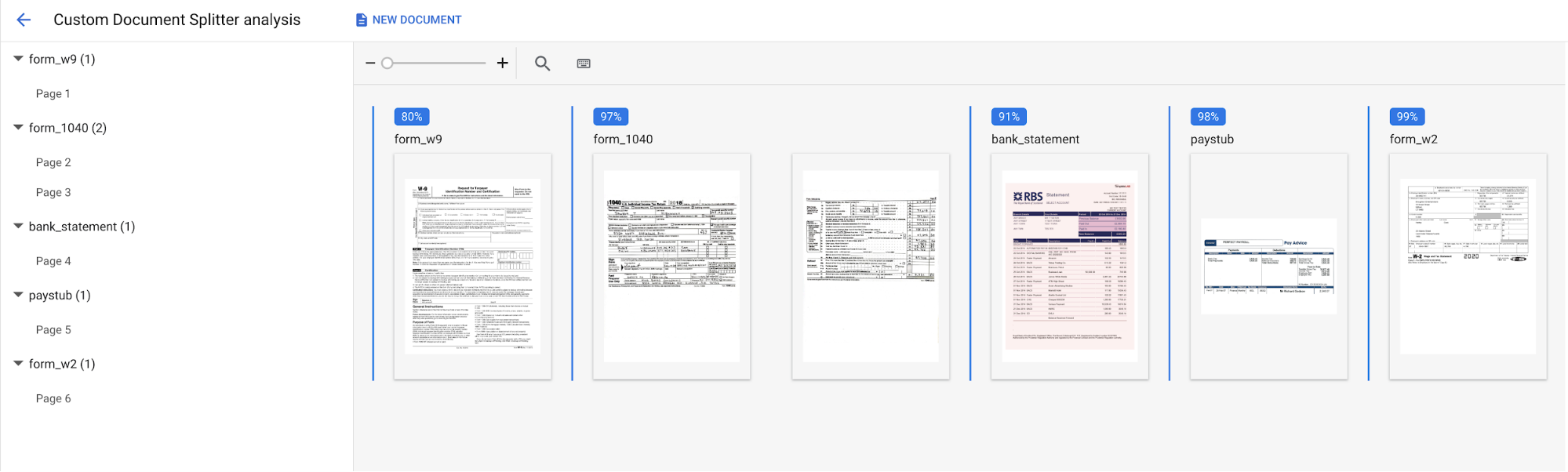
Anda juga dapat menjalankan kembali evaluasi terhadap set pengujian atau versi prosesor yang berbeda.
Di tab Train, pilih
Impor dokumen .Masukkan jalur berikut di
Source path . Folder ini berisi PDF tanpa label dari beberapa jenis dokumen.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabelTetapkan
Label dokumen sebagai Label otomatis.Setel dropdown
Dataset split ke Auto-split.Di bagian Auto-labeling, tetapkan
Version sebagai versi yang sebelumnya Anda latih.- Contoh:
2af620b2fd4d1fcf
- Contoh:
Pilih
Impor dan tunggu hingga dokumen selesai diimpor.Anda tidak dapat menggunakan dokumen berlabel otomatis untuk pelatihan atau pengujian tanpa menandainya sebagai berlabel. Buka bagian
Berlabel otomatis untuk melihat dokumen berlabel otomatis.Pilih dokumen pertama untuk masuk ke konsol pelabelan.
Verifikasi label untuk memastikan label sudah benar, dan sesuaikan jika tidak.
Pilih
Tandai sebagai Berlabel setelah selesai.Ulangi verifikasi label untuk setiap dokumen yang diberi label otomatis.
Kembali ke halaman Train, lalu pilih Train New Version untuk menggunakan data tersebut dalam pelatihan.
Di Google Cloud menu navigasi konsol, pilih Document AI, lalu pilih My Processors.
Pilih
Tindakan lainnya di baris yang sama dengan pemroses yang ingin Anda hapus.Pilih Hapus prosesor, ketik nama prosesor, lalu pilih Hapus lagi untuk mengonfirmasi.
Membuat pemroses
Mengonfigurasi set data
Untuk melatih prosesor baru ini, Anda harus membuat set data dengan data pelatihan dan pengujian untuk membantu prosesor mengidentifikasi dokumen yang ingin Anda pisahkan dan klasifikasikan.
Set data ini memerlukan lokasi baru. Ini dapat berupa bucket Cloud Storage atau folder yang kosong, atau Anda dapat mengizinkan lokasi Dikelola Google (internal).

Buat bucket Cloud Storage untuk set data
Pastikan jalur tujuan diisi dengan nama bucket yang Anda pilih. Pilih Buat set data. Pembuatan set data dapat memerlukan waktu hingga beberapa menit.
Tentukan skema pemroses
Anda dapat membuat skema pemroses sebelum atau setelah mengimpor dokumen ke dalam set data. Skema ini menyediakan label yang Anda gunakan untuk menganotasi dokumen.
Mengimpor dokumen tidak berlabel ke dalam set data
Langkah berikutnya adalah mulai mengimpor dokumen tanpa label ke dalam set data Anda dan memberinya label. Alternatif yang direkomendasikan adalah mengimpor dokumen yang disusun dalam folder menurut kelas, jika tersedia.
Jika mengerjakan project sendiri, Anda menentukan cara memberi label pada data. Lihat Opsi pemberian label.
Prosesor kustom Document AI memerlukan minimal 10 dokumen dalam set pelatihan dan pengujian, bersama dengan 10 instance dari setiap label di setiap set. Sebaiknya tambahkan minimal 50 dokumen di setiap set, dengan 50 instance dari setiap label untuk mendapatkan performa terbaik. Secara umum, makin banyak data pelatihan, makin tinggi akurasinya.
Saat mengimpor dokumen, Anda dapat secara opsional menetapkan dokumen ke set Pelatihan atau Pengujian saat diimpor, atau menunggu untuk menetapkannya nanti.
Jika Anda ingin menghapus dokumen yang telah diimpor, pilih dokumen tersebut di tab Latih, lalu pilih Hapus.
Untuk mengetahui informasi selengkapnya tentang cara menyiapkan data untuk diimpor, lihat Panduan persiapan data.
Opsional: Melabeli dokumen secara berkelompok saat mengimpor
Anda dapat memberi label pada semua dokumen yang ada di direktori tertentu saat mengimpor untuk menghemat waktu dalam memberi label. Jika dokumen pelatihan Anda disusun berdasarkan kelas dalam folder, Anda dapat menggunakan kolom Label dokumen untuk menentukan kelas dokumen tersebut dan menghindari pemberian label manual pada setiap dokumen.
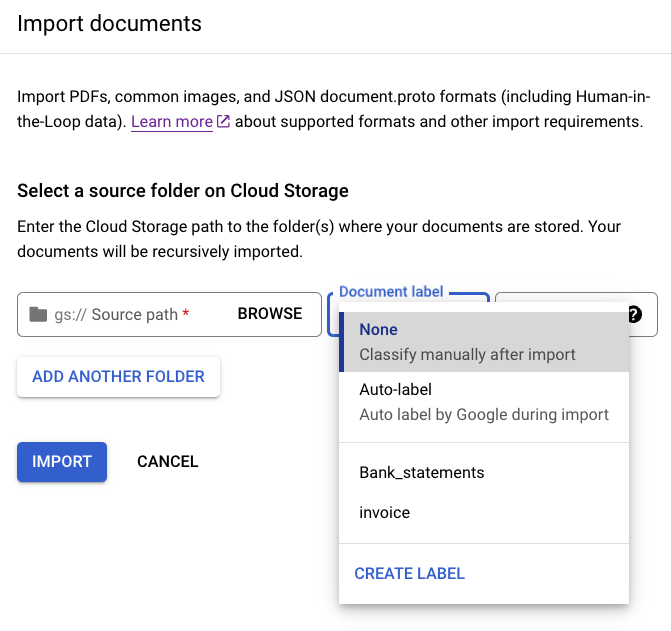
Dalam gambar, Bank_statements dan Invoice adalah label yang ditentukan yang tersedia (kelas dokumen) yang dapat Anda pilih. Atau, Anda dapat menggunakan CREATE LABEL dan menentukan class
baru.
Memberi label dokumen
Proses penerapan label ke dokumen dikenal sebagai anotasi.
Menetapkan dokumen beranotasi ke set pelatihan
Setelah memberi label pada contoh dokumen ini, Anda dapat menetapkannya ke set pelatihan.
Di panel sebelah kiri, Anda dapat melihat bahwa 1 dokumen telah ditetapkan ke set pelatihan.
Mengimpor data dengan pelabelan batch
Selanjutnya, Anda mengimpor file PDF tak berlabel yang diurutkan ke dalam berbagai folder Cloud Storage menurut jenisnya. Pemberian label batch membantu menghemat waktu dalam pemberian label dengan menetapkan label pada waktu impor berdasarkan jalur.
Setelah impor selesai, temukan dokumen di tab Train.
Mengimpor data yang sudah diberi label
Dalam panduan ini, Anda akan mendapatkan data yang telah diberi label dalam format Document sebagai file JSON.
Format ini sama dengan yang dihasilkan Document AI saat memproses dokumen, memberi label dengan Human-in-the-Loop, atau mengekspor set data.
Setelah impor selesai, temukan dokumen di tab Train.
Melatih pemroses
Setelah mengimpor data pelatihan dan pengujian, Anda dapat melatih prosesor. Karena pelatihan mungkin memerlukan waktu beberapa jam, pastikan Anda telah menyiapkan pemroses dengan data dan label yang sesuai sebelum memulai pelatihan.
Men-deploy versi pemroses
Mengevaluasi dan menguji pemroses
(Opsional) Mengimpor data dengan pelabelan otomatis
Setelah menerapkan versi prosesor terlatih, Anda dapat menggunakan Pelabelan otomatis untuk menghemat waktu pelabelan saat mengimpor dokumen baru.
Menggunakan prosesor
Anda telah berhasil membuat dan melatih pemroses pemisah kustom.
Anda dapat mengelola versi prosesor yang dilatih kustom seperti versi prosesor lainnya. Untuk mengetahui informasi selengkapnya, lihat Mengelola versi pemroses.
Setelah di-deploy, Anda dapat Mengirim permintaan pemrosesan ke pemroses kustom, dan respons dapat ditangani sama seperti pemroses pemisah lainnya.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan pada halaman ini, ikuti langkah-langkah berikut.
Untuk menghindari tagihan yang tidak perlu, gunakan Google Cloud console untuk menghapus prosesor dan project Anda jika Anda tidak memerlukannya. Google Cloud
Jika Anda membuat project baru untuk mempelajari Document AI dan Anda tidak lagi memerlukan project tersebut, hapus project tersebut.
Jika Anda menggunakan project Google Cloud yang sudah ada, hapus resource yang Anda buat untuk menghindari tagihan pada akun Anda: