Set data berlabel dokumen diperlukan untuk melatih, melatih ulang, atau mengevaluasi versi pemroses.
Halaman ini menjelaskan cara membuat set data, mengimpor dokumen, dan menentukan skema. Untuk memberi label pada dokumen yang diimpor, lihat Memberi label pada dokumen.
Halaman ini mengasumsikan bahwa Anda telah membuat pemroses yang mendukung pelatihan, pelatihan ulang, atau evaluasi. Jika prosesor Anda didukung, Anda akan melihat tab Train di konsol Google Cloud .
Opsi penyimpanan set data
Anda dapat memilih antara dua opsi untuk menyimpan set data:
- Dikelola oleh Google
- Cloud Storage lokasi kustom
Kecuali Anda memiliki persyaratan khusus (misalnya, untuk menyimpan dokumen dalam serangkaian folder yang mendukung CMEK), sebaiknya gunakan opsi penyimpanan yang dikelola Google yang lebih sederhana. Setelah dibuat, opsi penyimpanan set data tidak dapat diubah untuk pemroses.
Folder atau subfolder untuk lokasi Cloud Storage kustom harus kosong saat dimulai dan diperlakukan sebagai hanya baca. Setiap perubahan manual pada isinya dapat membuat set data tidak dapat digunakan, sehingga berisiko hilang. Opsi penyimpanan yang dikelola Google tidak memiliki risiko ini.
Ikuti langkah-langkah berikut untuk menyediakan lokasi penyimpanan Anda.
Penyimpanan yang dikelola Google (direkomendasikan)
Menampilkan opsi lanjutan saat membuat pemroses baru.
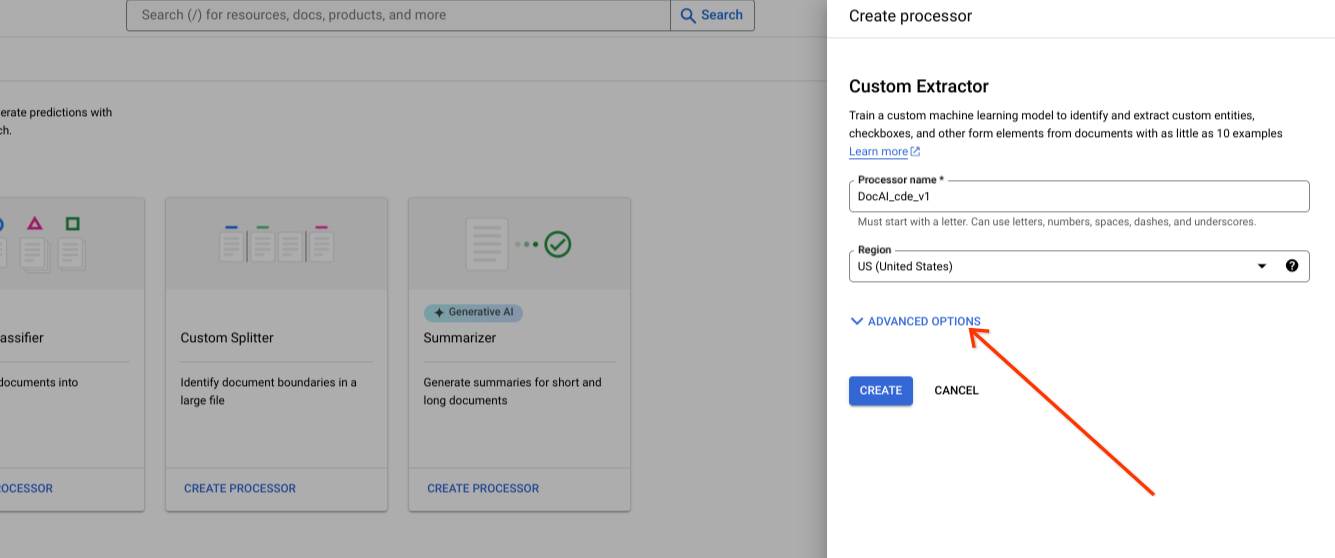
Pertahankan opsi grup tombol pilihan default ke penyimpanan yang dikelola Google.
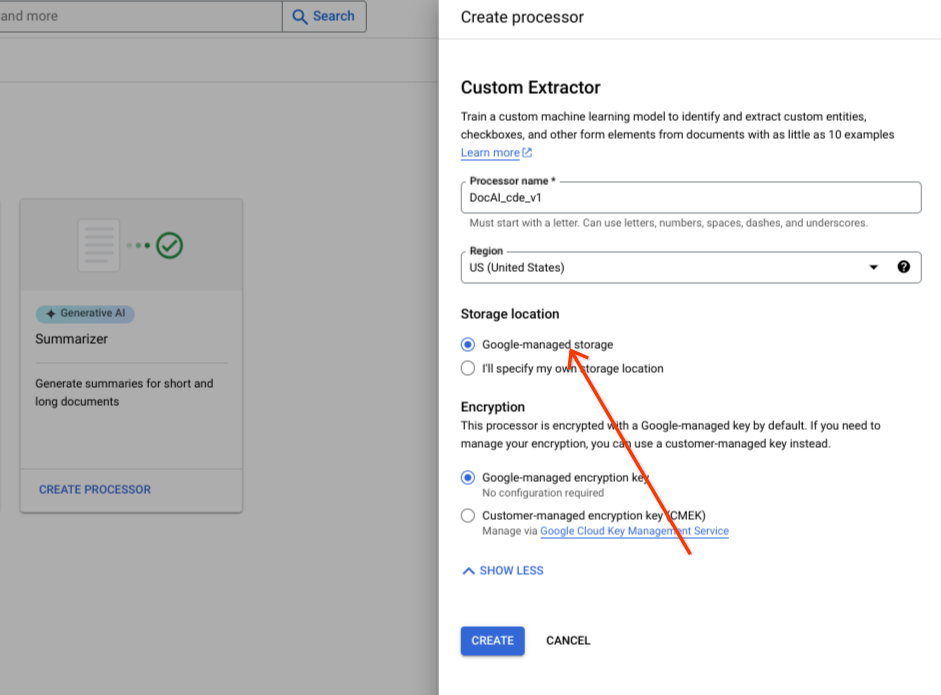
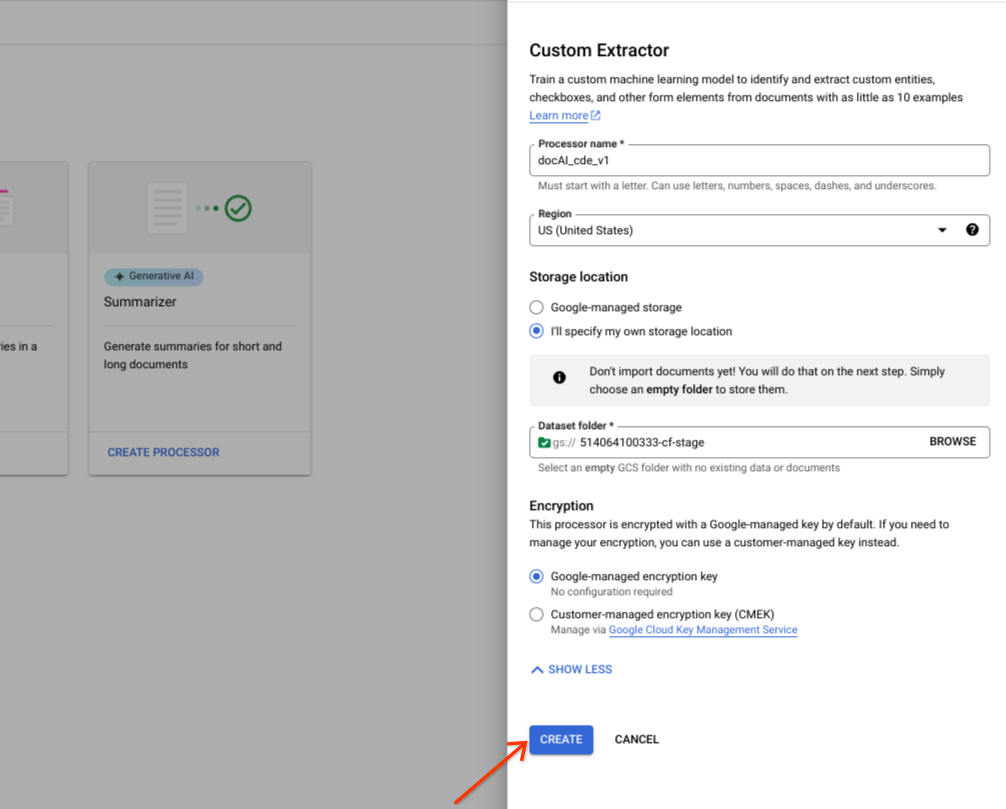
Pilih Create.
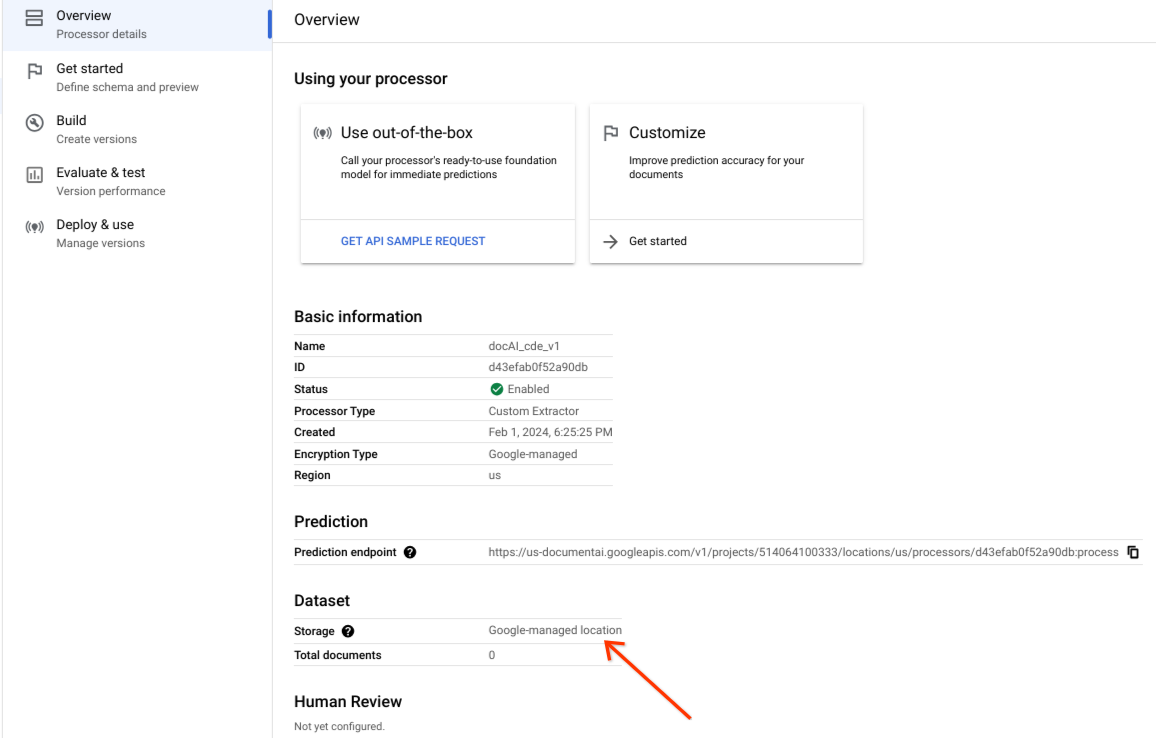
Pastikan set data berhasil dibuat dan lokasi set data adalah Lokasi yang dikelola Google.
Opsi penyimpanan kustom
Aktifkan atau nonaktifkan opsi lanjutan.
Pilih Saya akan menentukan lokasi penyimpanan saya sendiri.
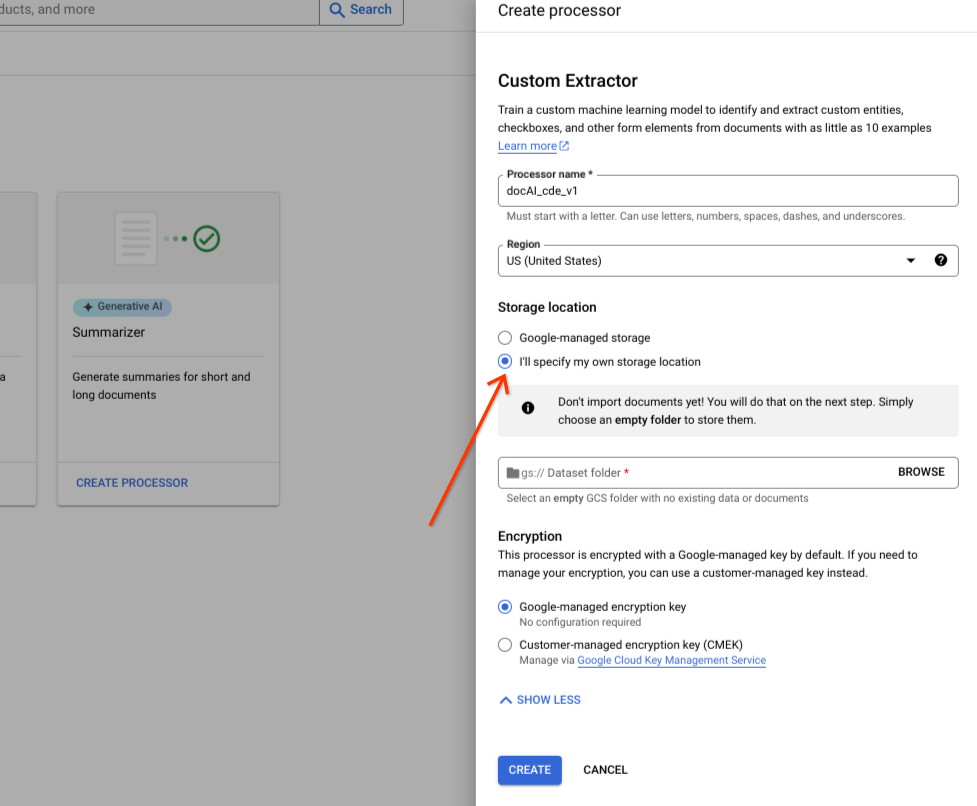
Pilih folder Cloud Storage dari komponen input.
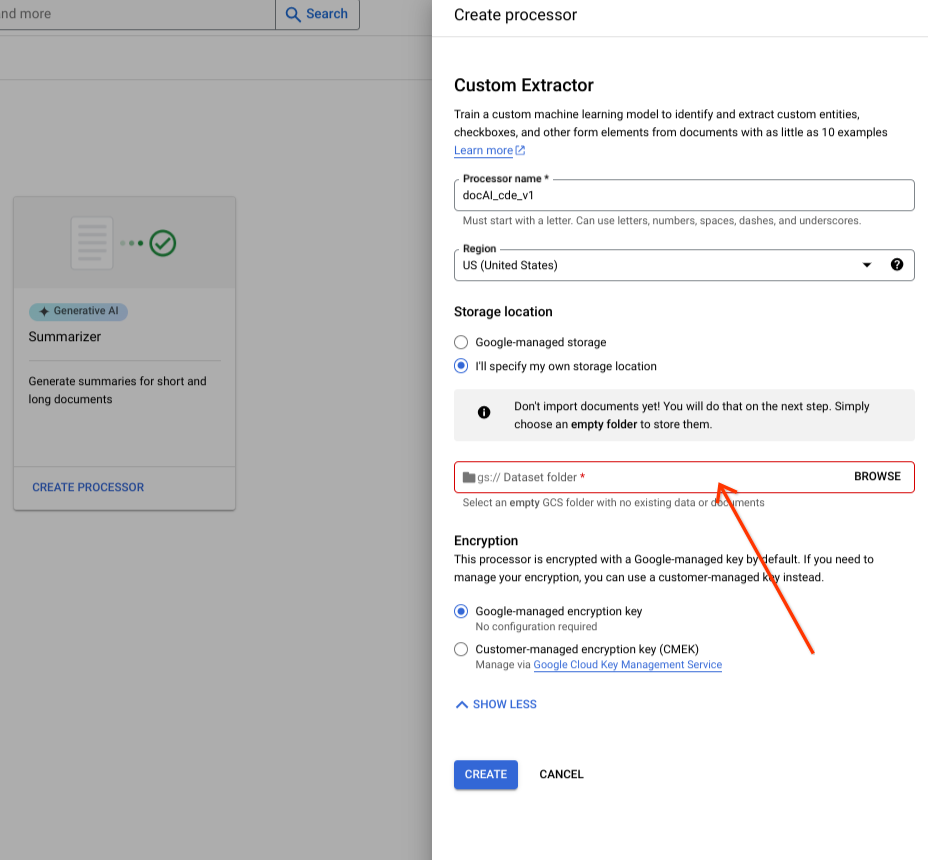
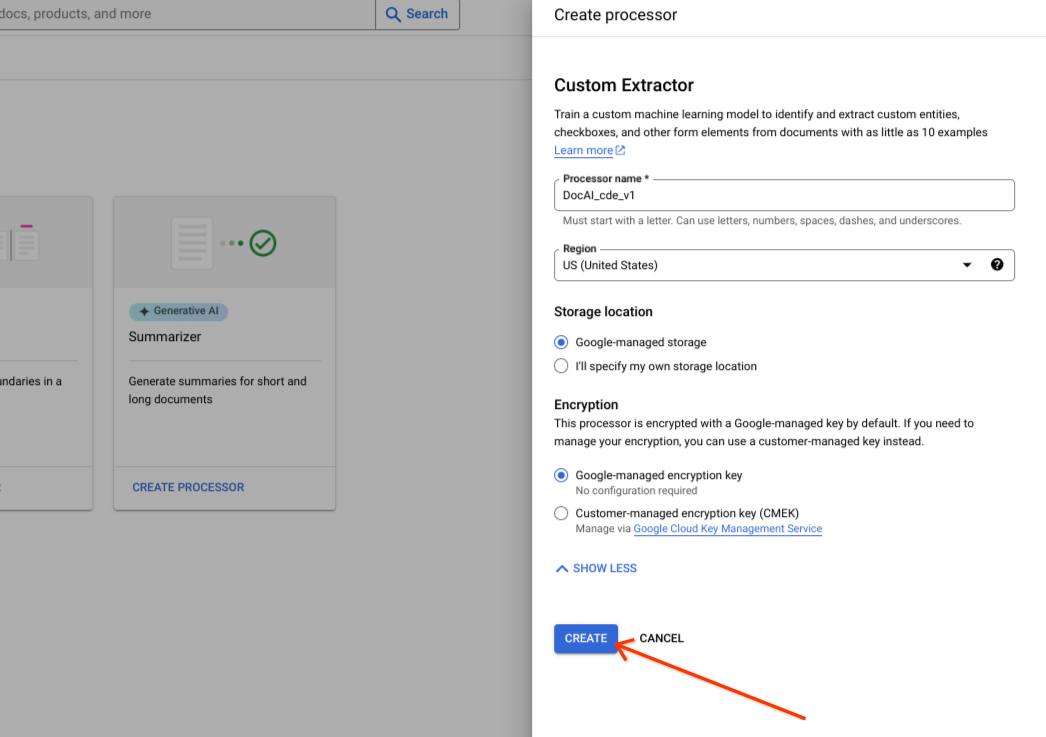
Pilih Create.
Operasi Dataset API
Contoh ini menunjukkan cara menggunakan metode
processors.updateDataset
untuk membuat set data. Resource set data adalah resource singleton di pemroses,
yang berarti tidak ada RPC resource buat. Sebagai gantinya, Anda dapat menggunakan
RPC updateDataset untuk menetapkan preferensi. Document AI menyediakan opsi untuk menyimpan dokumen set data di bucket Cloud Storage yang Anda berikan atau agar dokumen tersebut dikelola secara otomatis oleh Google.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Bucket yang disediakan
Ikuti langkah-langkah berikutnya untuk membuat permintaan set data dengan bucket Cloud Storage yang Anda berikan.
Metode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetMeminta JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Dikelola Google
Jika Anda ingin membuat set data yang dikelola Google, perbarui informasi berikut:
Metode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetMeminta JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Untuk mengirim permintaan, Anda dapat menggunakan Curl:
Simpan isi permintaan dalam file bernama request.json. Jalankan perintah berikut:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Mengimpor dokumen
Set data yang baru dibuat kosong. Untuk menambahkan dokumen, pilih Impor Dokumen dan pilih satu atau beberapa folder Cloud Storage yang berisi dokumen yang ingin Anda tambahkan ke set data.
Jika Cloud Storage Anda berada di project Google Cloud lain, pastikan untuk memberikan akses agar Document AI diizinkan membaca file dari lokasi tersebut. Secara khusus, Anda harus memberikan peran
Storage Object Viewer kepada
agen layanan inti Document AI
service-{project-id}@gcp-sa-prod-dai-core.. Untuk mengetahui informasi selengkapnya, lihat Agen layanan.
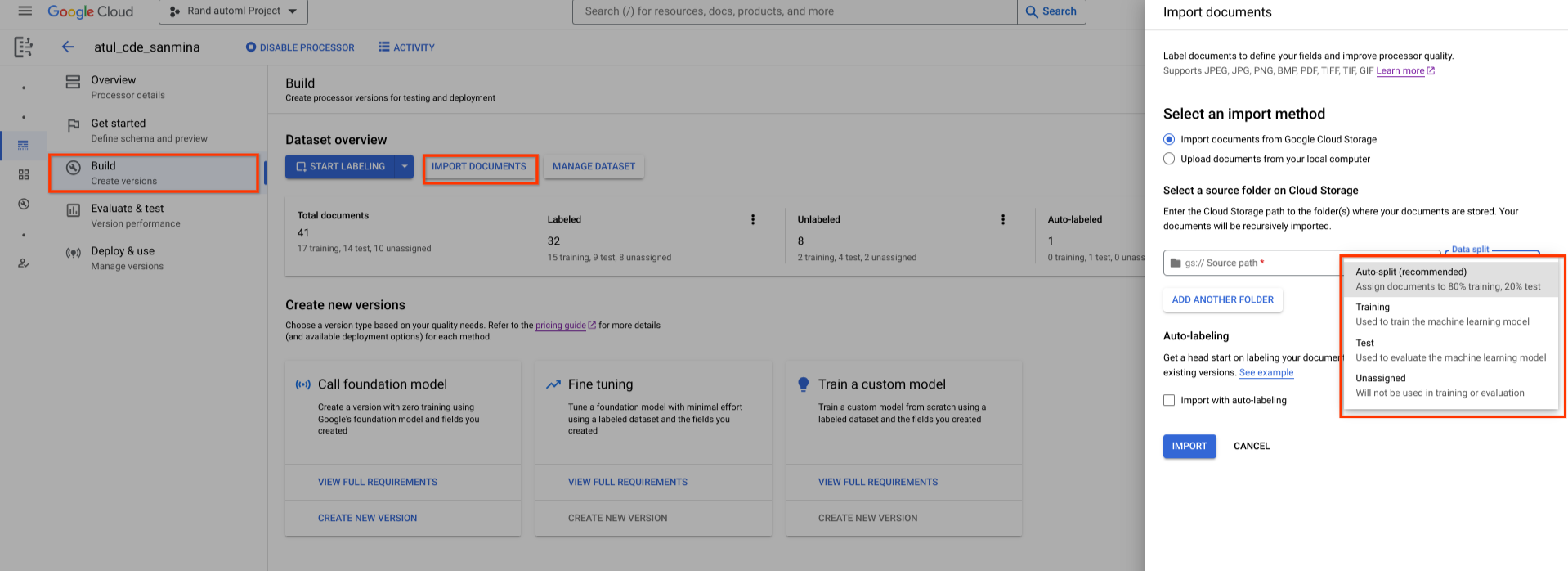
Kemudian, pilih salah satu opsi penugasan berikut:
- Pelatihan: Tetapkan ke set pelatihan.
- Pengujian: Tetapkan ke set pengujian.
- Pembagian otomatis: Mengacak dokumen secara acak dalam set pelatihan dan pengujian.
- Tidak ditetapkan: Tidak digunakan dalam pelatihan atau evaluasi. Anda dapat menetapkan secara manual nanti.
Anda dapat mengubah penetapan tugas nanti.
Saat Anda memilih Impor, Document AI akan mengimpor semua
jenis file yang didukung serta file
Document JSON ke dalam
set data. Untuk file JSON Document, Document AI mengimpor dokumen dan mengonversi entities-nya menjadi instance label.
Document AI tidak mengubah folder impor atau membaca dari folder setelah impor selesai.
Pilih Aktivitas di bagian atas halaman untuk membuka panel Aktivitas, yang mencantumkan file yang berhasil diimpor serta file yang gagal diimpor.
Jika sudah memiliki versi prosesor, Anda dapat memilih kotak centang Import with auto-labeling di dialog Import documents. Dokumen akan diberi label otomatis menggunakan prosesor sebelumnya saat diimpor. Anda tidak dapat melatih atau meningkatkan kualitas pelatihan pada dokumen berlabel otomatis, atau menggunakannya dalam set pengujian, tanpa menandainya sebagai berlabel. Setelah mengimpor dokumen berlabel otomatis, tinjau dan perbaiki dokumen berlabel otomatis secara manual. Kemudian, pilih Simpan untuk menyimpan koreksi dan menandai dokumen sebagai berlabel. Kemudian, Anda dapat menetapkan dokumen tersebut sesuai kebutuhan. Lihat Pemberian label otomatis.
RPC impor dokumen
Contoh ini menunjukkan cara menggunakan metode dataset.importDocuments untuk mengimpor dokumen ke dalam set data.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Set data pelatihan atau pengujian
Jika Anda ingin menambahkan dokumen ke set data pelatihan atau pengujian:
Metode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsMeminta JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Set data pelatihan & pengujian
Jika Anda ingin memisahkan dokumen secara otomatis antara set data pelatihan dan pengujian:
Metode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsMeminta JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Simpan isi permintaan dalam file bernama request.json, lalu jalankan perintah berikut:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}RPC hapus dokumen
Contoh ini menunjukkan cara menggunakan metode dataset.batchDeleteDocuments untuk menghapus dokumen dari set data.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Menghapus dokumen
Metode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsMeminta JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Simpan isi permintaan dalam file bernama request.json, lalu jalankan perintah berikut:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Menetapkan dokumen ke set pelatihan atau pengujian
Di bagian Pemisahan data, pilih dokumen dan tetapkan ke set pelatihan, set pengujian, atau tidak ditetapkan.
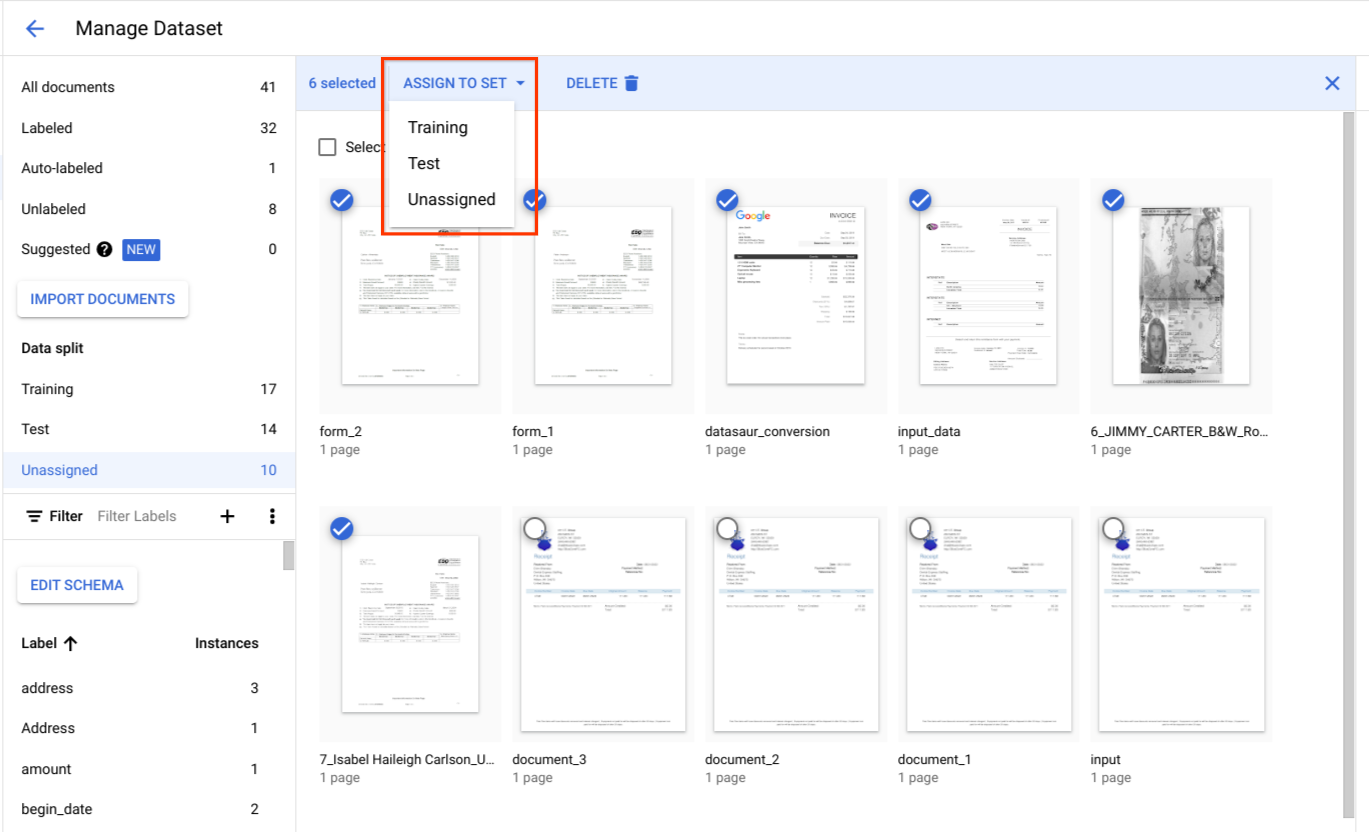
Praktik terbaik untuk set pengujian
Kualitas set pengujian Anda menentukan kualitas evaluasi Anda.
Set pengujian harus dibuat di awal siklus pengembangan prosesor dan dikunci sehingga Anda dapat melacak kualitas prosesor dari waktu ke waktu.
Sebaiknya gunakan minimal 100 dokumen per jenis dokumen untuk set pengujian. Sangat penting untuk memastikan bahwa set pengujian bersifat representatif untuk jenis dokumen yang digunakan pelanggan untuk model yang sedang dikembangkan.
Set pengujian harus mewakili traffic produksi dalam hal frekuensi. Misalnya, jika Anda memproses formulir W2 dan memperkirakan 70% untuk tahun 2020 dan 30% untuk tahun 2019, maka ~70% set pengujian harus terdiri dari dokumen W2 2020. Komposisi set pengujian seperti ini memastikan setiap subtipe dokumen diberi kepentingan yang sesuai saat mengevaluasi performa pemroses. Selain itu, jika Anda mengekstrak nama orang dari formulir internasional, pastikan bahwa set pengujian Anda menyertakan formulir dari semua negara target.
Praktik terbaik untuk set pelatihan
Dokumen apa pun yang telah disertakan dalam set pengujian tidak boleh disertakan dalam set pelatihan.
Tidak seperti set pengujian, set pelatihan akhir tidak perlu merepresentasikan penggunaan pelanggan secara ketat dalam hal keragaman atau frekuensi dokumen. Beberapa label lebih sulit dilatih daripada yang lain. Oleh karena itu, Anda mungkin mendapatkan performa yang lebih baik dengan memiringkan set pelatihan ke arah label tersebut.
Pada awalnya, tidak ada cara yang baik untuk mengetahui label mana yang sulit. Anda harus memulai dengan set pelatihan awal kecil yang diambil secara acak menggunakan pendekatan yang sama seperti yang dijelaskan untuk set pengujian. Kumpulan data pelatihan awal ini harus berisi sekitar 10% dari jumlah total dokumen yang akan Anda beri anotasi. Kemudian, Anda dapat mengevaluasi kualitas pemroses secara berulang (mencari pola error tertentu) dan menambahkan lebih banyak data pelatihan.
Menentukan skema pemroses
Setelah membuat set data, Anda dapat menentukan skema pemroses sebelum atau setelah mengimpor dokumen.
schema prosesor menentukan label, seperti nama dan alamat, yang akan diekstrak dari dokumen Anda.
Pilih Edit Skema, lalu buat, edit, aktifkan, dan nonaktifkan label sesuai kebutuhan.
Pastikan untuk memilih Simpan setelah Anda selesai.
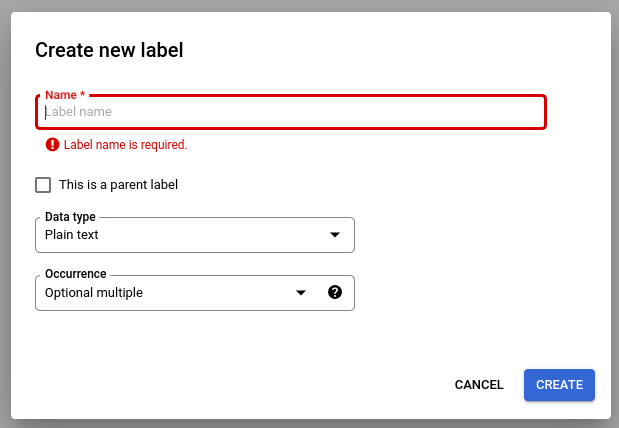
Catatan tentang pengelolaan label skema:
Setelah label skema dibuat, nama label skema tidak dapat diedit.
Label skema hanya dapat diedit atau dihapus jika tidak ada versi prosesor terlatih. Hanya jenis data dan jenis kemunculan yang dapat diedit.
Menonaktifkan label juga tidak memengaruhi prediksi. Saat Anda mengirim permintaan pemrosesan, versi prosesor akan mengekstrak semua label yang aktif pada saat pelatihan.
Mendapatkan skema data
Contoh ini menunjukkan cara menggunakan set data.
getDatasetSchema
untuk mendapatkan skema saat ini. DatasetSchema adalah resource singleton, yang
dibuat secara otomatis saat Anda membuat resource set data.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Mendapatkan skema data
Metode HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Memperbarui skema dokumen
Contoh ini menunjukkan cara menggunakan
dataset.updateDatasetSchema
untuk memperbarui skema saat ini. Contoh ini menunjukkan perintah untuk memperbarui skema set data agar memiliki satu label. Jika Anda ingin menambahkan label baru, bukan menghapus
atau memperbarui label yang ada, Anda dapat memanggil getDatasetSchema terlebih dahulu dan membuat
perubahan yang sesuai dalam responsnya.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Memperbarui skema
Metode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaMeminta JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Simpan isi permintaan dalam file bernama request.json, lalu jalankan perintah berikut:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Pilih atribut label
Data type
Plain text: nilai string.Number: angka - bilangan bulat atau floating point.Money: jumlah nilai uang. Saat memberi label, jangan sertakan simbol mata uang.- Saat diekstrak, entitas dinormalisasi menjadi
google.type.Money.
- Saat diekstrak, entitas dinormalisasi menjadi
Currency: simbol mata uang.Datetime: nilai tanggal atau waktu.- Saat entity diekstrak, entity tersebut dinormalisasi ke format teks
ISO 8601.
- Saat entity diekstrak, entity tersebut dinormalisasi ke format teks
Address- alamat lokasi.- Saat diekstrak, entitas akan dinormalisasi dan diperkaya dengan EKG.
Checkbox- nilai booleantrueataufalse.Signature- nilai booleantrueataufalsedinormalized_value.signature_valueyang menunjukkan apakah Tanda Tangan ada. API ini mendukung metodederive.mention_text- nilai booleanDetectedatau""kosong dihas_signedyang menunjukkan apakah Tanda Tangan ada. API ini mendukung metodederive.normalized_value.text- nilai booleanDetectedatau""kosong dihas_signedyang menunjukkan apakah Tanda Tangan ada. API ini mendukung metodederive.normalized_value.boolean_valuetidak diisi.
Metode
- Jika entitas adalah
extracted, entitas tersebut memiliki kolomtextAnchor,type,mentionText, danpageAnchoryang diisi. - Jika entity adalah
derived, nilai turunan mungkin tidak ada dalam teks dokumen. KolomtextAnchordanpageAnchor.pageRefs[].bounding_polybelum diisi.
Occurrence
Pilih REQUIRED jika entitas diharapkan selalu muncul dalam dokumen dari jenis tertentu. Pilih OPTIONAL jika tidak ada ekspektasi tersebut.
Pilih ONCE jika suatu entitas diharapkan memiliki satu nilai, meskipun nilai yang sama muncul beberapa kali dalam dokumen yang sama. Pilih MULTIPLE jika
entitas diharapkan memiliki beberapa nilai.
Label induk dan turunan
Label induk-turunan (juga dikenal sebagai entitas tabular) digunakan untuk memberi label pada data dalam tabel. Tabel berikut berisi 3 baris dan 4 kolom.

Anda dapat menentukan tabel tersebut menggunakan label induk-turunan. Dalam contoh ini, label
induk line-item menentukan baris tabel.
Membuat label induk
Di halaman Edit skema, pilih Buat Label.
Centang kotak Ini adalah label orang tua, lalu masukkan informasi lainnya. Label induk harus memiliki kemunculan
optional_multipleataurequire_multiplesehingga dapat diulang untuk mengambil semua baris dalam tabel.Pilih Save.
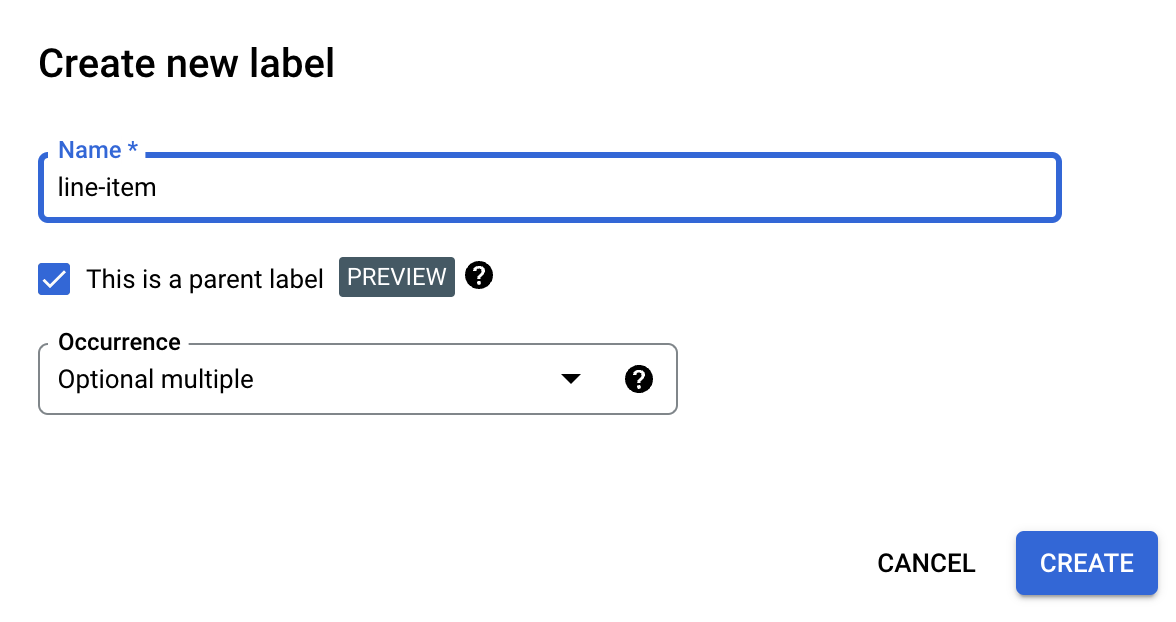
Label induk muncul di halaman Edit skema, dengan opsi Tambahkan Label Turunan di sampingnya.
Untuk membuat label turunan
Di samping label induk pada halaman Edit skema, pilih Tambahkan Label Turunan.
Masukkan informasi untuk label turunan.
Pilih Save.
Ulangi untuk setiap label turunan yang ingin Anda tambahkan.
Label turunan muncul dengan indentasi di bawah label induk pada halaman Edit skema.

Label induk-turunan adalah fitur pratinjau dan hanya didukung untuk tabel. Kedalaman bertingkat dibatasi hingga 1, yang berarti bahwa entitas turunan tidak dapat berisi entitas turunan lainnya.
Membuat Label Skema dari Dokumen Berlabel
Membuat label skema secara otomatis dengan mengimpor file JSON Document yang telah diberi label.
Saat impor Document sedang berlangsung, label skema yang baru ditambahkan akan ditambahkan ke Editor Skema. Pilih 'Edit Skema' untuk memverifikasi atau mengubah jenis data dan jenis kemunculan label skema baru. Setelah dikonfirmasi, pilih
label skema, lalu pilih Aktifkan.
Contoh set data
Untuk membantu memulai penggunaan Document AI Workbench, set data disediakan di bucket Cloud Storage publik yang mencakup file JSON Document sampel yang telah diberi label dan tidak diberi label dari beberapa jenis dokumen.
Data ini dapat digunakan untuk pelatihan ulang atau ekstraktor kustom, bergantung pada jenis dokumen.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/