Meccanismi di estrattore personalizzato
Puoi creare estrattori personalizzati specifici per i tuoi documenti, addestrati e valutati in base ai tuoi dati. Questo processore identifica ed estrae le entità dai tuoi documenti. Quindi puoi utilizzare questo processore addestrato su documenti aggiuntivi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Nella Google Cloud console, nella sezione Document AI, vai alla pagina Workbench.
Per l'estrattore personalizzato, seleziona
Crea processore .
Nel menu Crea processore, inserisci un nome per il processore, ad esempio
my-custom-document-extractor.
Seleziona la regione più vicina a te.
(Facoltativo) Apri Opzioni avanzate.
Puoi scegliere di consentire a Google di creare un bucket Cloud Storage per te oppure puoi crearne uno tuo. Per questo tutorial, seleziona Spazio di archiviazione gestito da Google.
Puoi anche scegliere di utilizzare chiavi di crittografia gestite dal cliente (CMEK) o da Google. Per questo tutorial, seleziona Google-managed encryption key.
Seleziona Crea per creare il tuo processore.
Seleziona la scheda
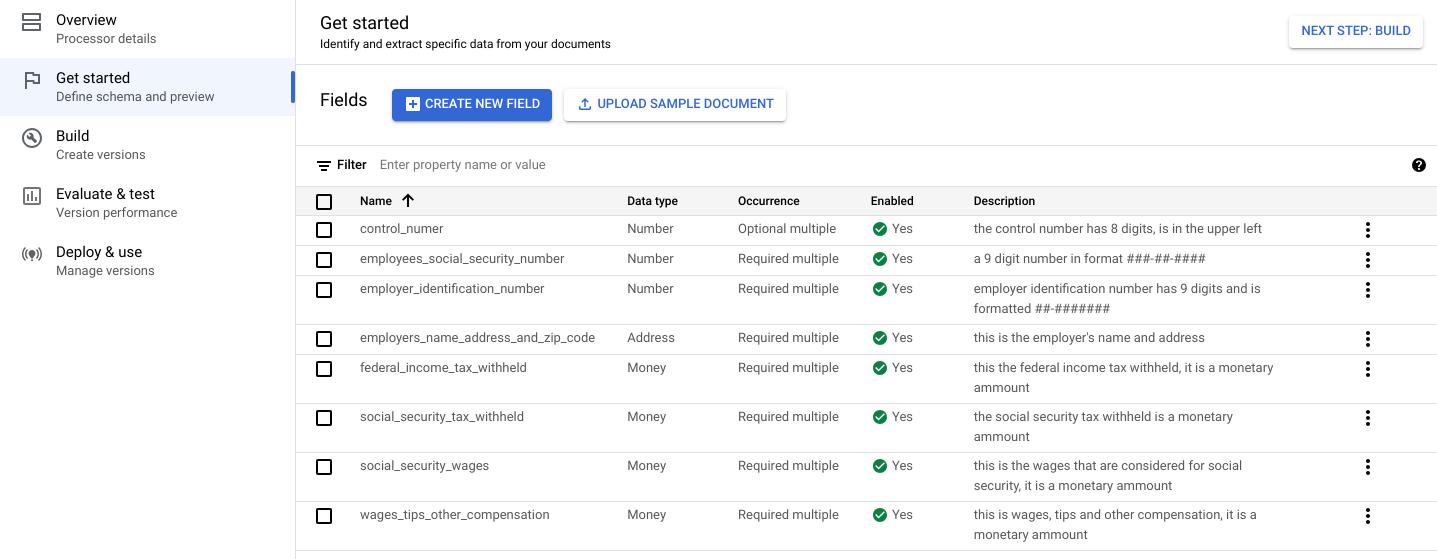
Inizia . Viene visualizzato il menu Campi.Seleziona Crea nuovo campo.
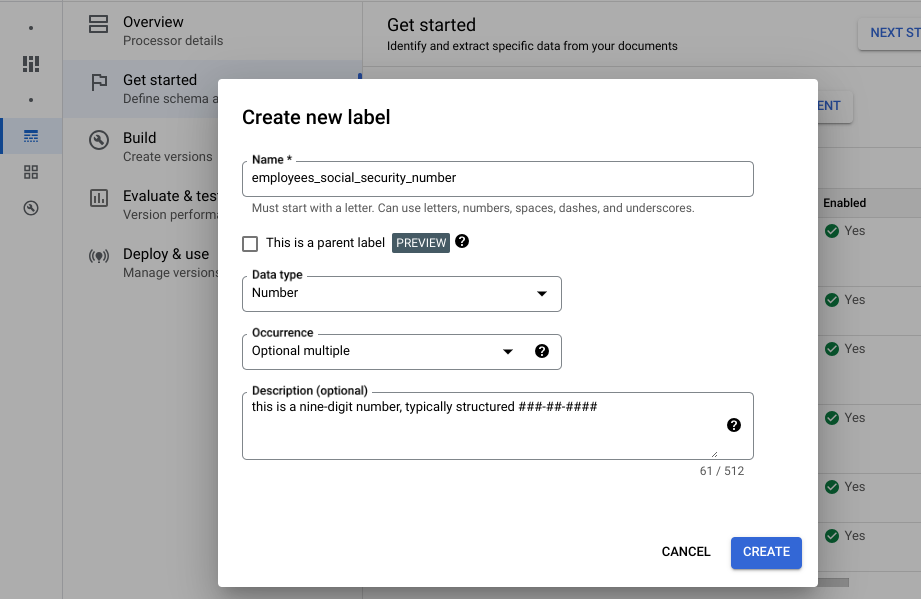
Inserisci il nome del campo. Seleziona il Tipo di dati e Occorrenza. Assegna all'etichetta una descrizione distinta e dettagliata. La descrizione della proprietà consente di fornire contesto aggiuntivo, approfondimenti e conoscenze precedenti per ogni entità al fine di migliorare l'accuratezza e il rendimento dell'estrazione.
- Seleziona Crea. Consulta Definisci lo schema del processore per istruzioni dettagliate su come creare e modificare uno schema.
Crea ognuna delle seguenti etichette per lo schema del processore.
Nome Tipo di dati Occorrenza control_numberNumero Multiplo facoltativo employees_social_security_numberNumero Multipla obbligatoria employer_identification_numberNumero Multipla obbligatoria employers_name_address_and_zip_codeIndirizzo Multipla obbligatoria federal_income_tax_withheldDenaro Multipla obbligatoria social_security_tax_withheldDenaro Multipla obbligatoria social_security_wagesDenaro Multipla obbligatoria wages_tips_other_compensationDenaro Multipla obbligatoria Puoi anche creare e utilizzare altri tipi di etichette nello schema del processore, ad esempio caselle di controllo ed entità tabulari. Ad esempio, i moduli W-2 contengono le caselle di controllo Dipendente statutario, Piano pensionistico e Indennità di malattia di terze parti che puoi aggiungere a lo schema.
Seleziona Carica documento di esempio.
Nella barra laterale, seleziona Importa documenti da Cloud Storage.
Per questo esempio, inserisci il nome di questo bucket in
Percorso di origine . Questo link rimanda direttamente a un documento.cloud-samples-data/documentai/Custom/W2/PDF/W2_XL_input_clean_2950.pdfSeleziona Importa.
Nella console di etichettatura, puoi notare che molte etichette sono già compilate. Questo perché il tipo di modello di estrattore personalizzato predefinito è un modello di base, in grado di eseguire previsioni zero-shot, ovvero senza addestramento.
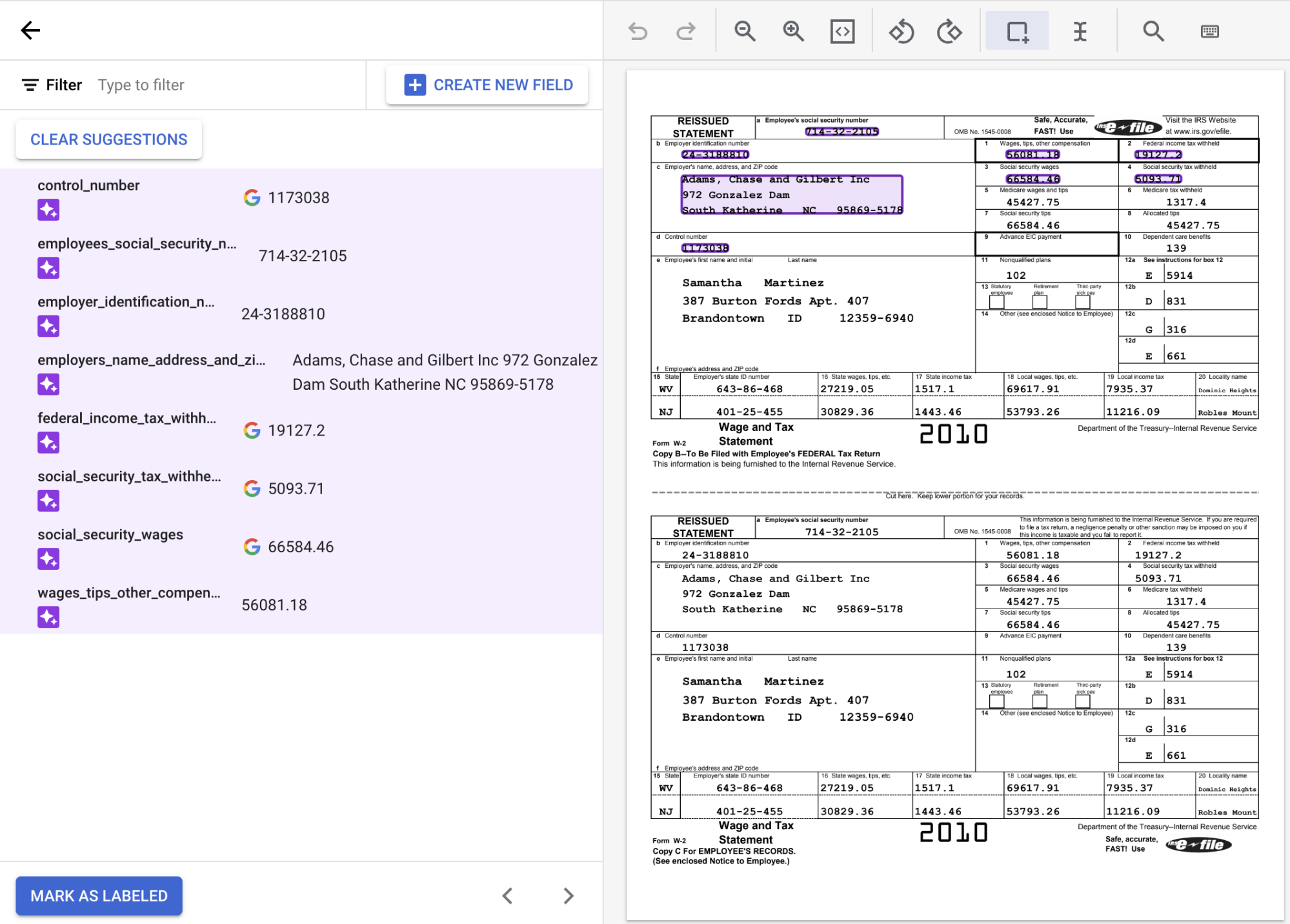
Per utilizzare le etichette suggerite, tieni il puntatore del mouse su ogni
etichetta nel riquadro laterale e seleziona il segno di spunta per confermare che l'etichetta sia corretta. Non modificare il testo, anche se il riconoscimento ottico dei caratteri lo legge in modo errato.In questo esempio, i valori in fondo al documento non sono stati identificati automaticamente, quindi occorre etichettarli manualmente.
Utilizza le icone nella barra degli strumenti sopra il documento da etichettare. Usa lo strumento predefinito
Riquadro di delimitazione , oppure lo strumentoSeleziona testo per i valori su più righe, per selezionare i contenuti e applicare l'etichetta.Una volta selezionato il testo, viene visualizzato un menu a discesa con tutti i campi definiti (entità) per selezionarne una. In questo esempio, è stato selezionato il valore
wages_tips_other_compensationcon lo strumento riquadro di delimitazione, quindi viene applicata questa etichetta.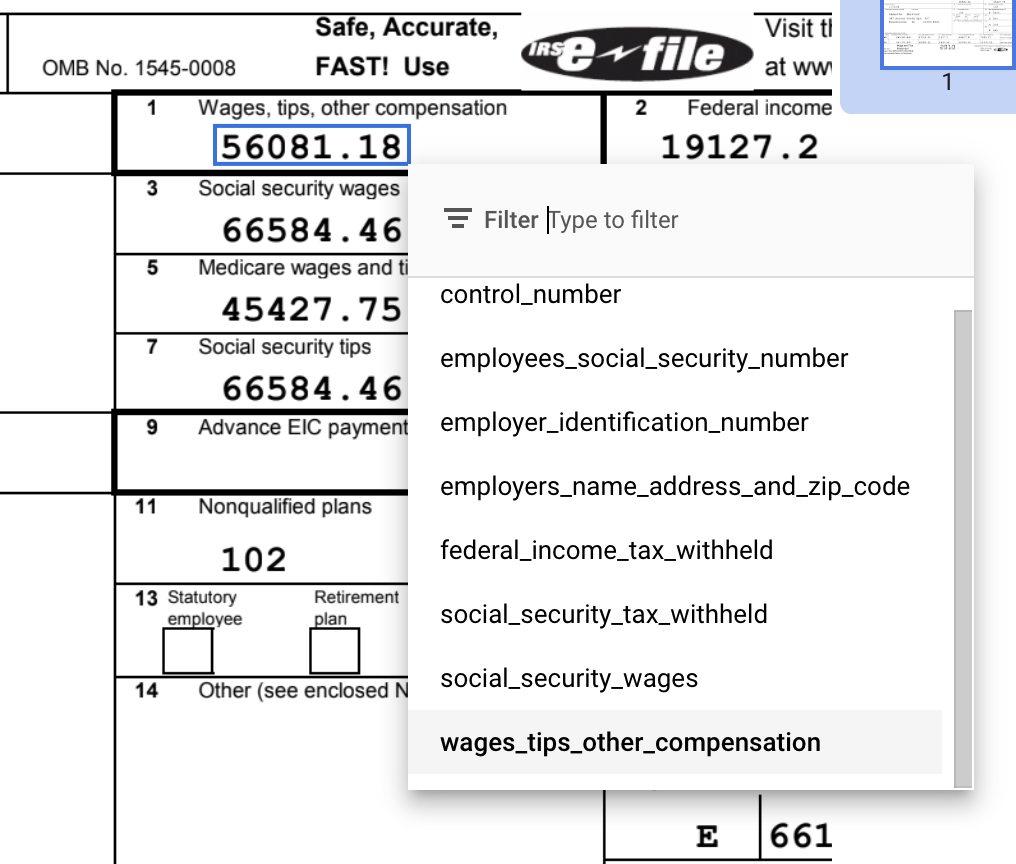
Rivedi i valori di testo rilevati per assicurarti che riflettano la posizione corretta del testo per ogni campo. Al termine, il documento W2 con etichetta avrà l'aspetto seguente:
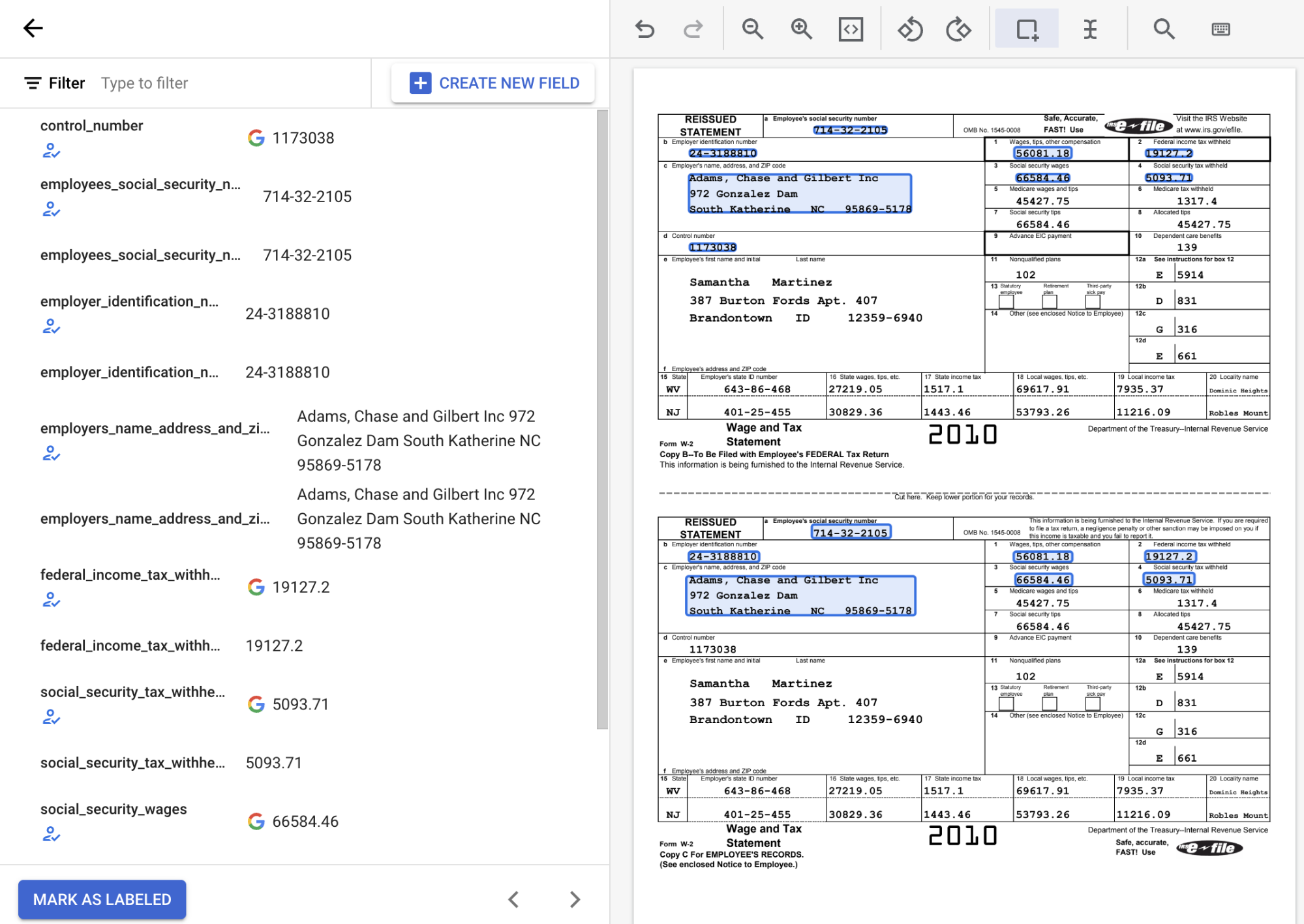
Se necessario, puoi selezionare
Crea nuovo campo per aggiungere un nuovo campo allo schema da questa pagina.Seleziona
Contrassegna come etichettato quando hai finito di annotare il documento. Viene visualizzata la scheda Per iniziare.Seleziona la scheda
Crea .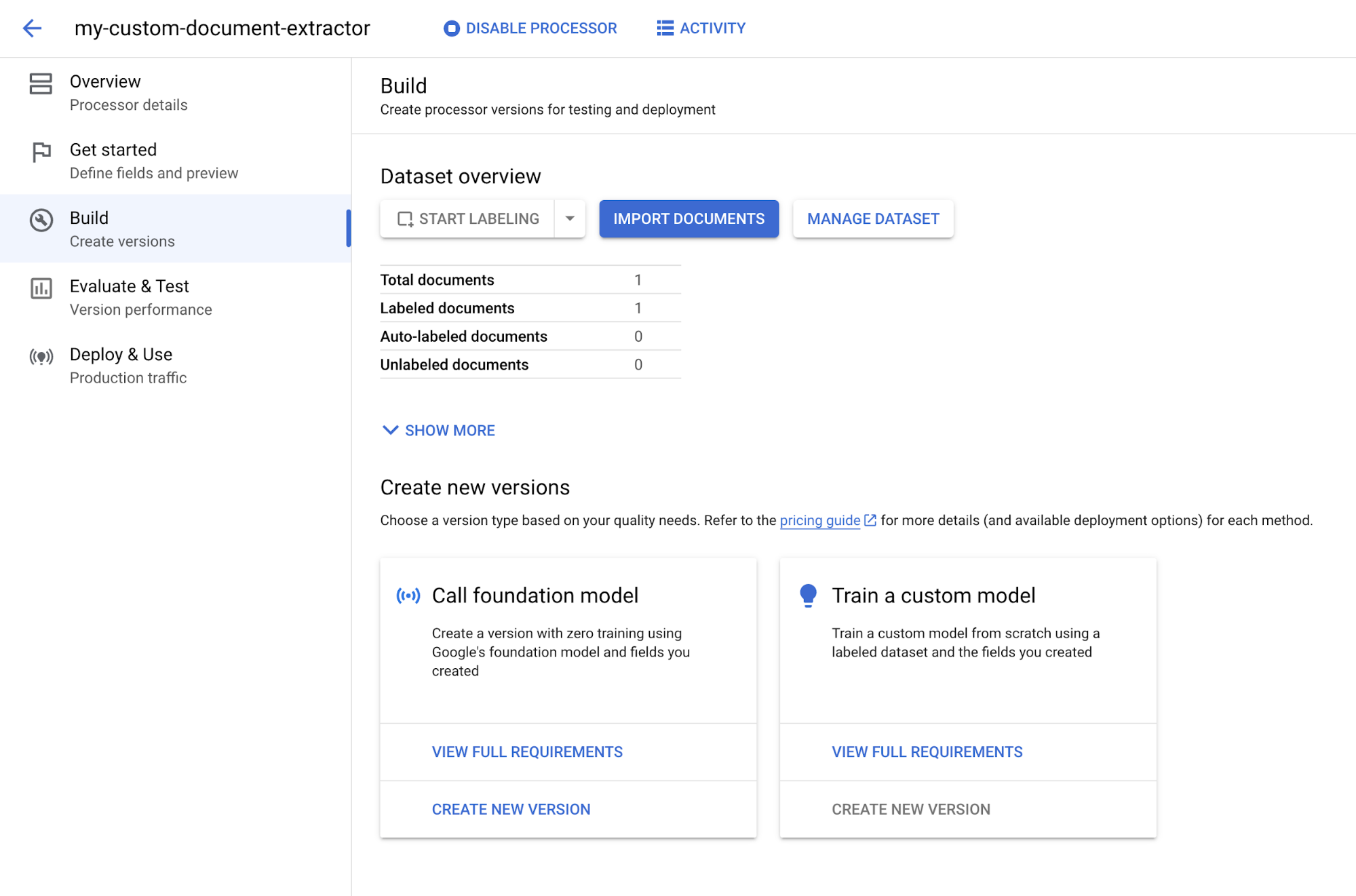
In Foundation model di chiamata, seleziona Crea nuova versione.
Inserisci un nome per la versione del processore, ad esempio
w2-foundation-model.Seleziona Crea versione. La creazione richiede qualche minuto.
(Facoltativo) Seleziona la scheda
Deployment e utilizzo . In questa pagina puoi visualizzare le versioni disponibili del processore e lo stato del deployment della nuova versione.Vai alla pagina
Crea .Seleziona
Importa documenti .Nella barra laterale, seleziona Importa documenti da Google Cloud Storage.
Inserisci il nome del bucket contenente i tuoi documenti.
Dall'elenco Suddivisione dati, seleziona Suddivisione automatica. In questo modo, i documenti vengono suddivisi automaticamente per includere l'80% nel set di addestramento e il 20% nel set di test.
Nella sezione Etichettatura automatica, seleziona la casella di controllo
Importa con etichettatura automatica .Seleziona la versione del processore del foundation model per etichettare i documenti.
Seleziona Importa e attendi l'importazione dei documenti. Puoi chiudere questa pagina e tornare più tardi.
Devi verificare i documenti etichettati automaticamente prima di poterli utilizzare per l'addestramento o i test. Seleziona
Inizia a creare etichette per visualizzare i documenti etichettati automaticamente.Per utilizzare le etichette suggerite, tieni il puntatore del mouse su ogni
annotazione e seleziona il segno di spunta per confermare che l'etichetta sia corretta. Ai fini dell'addestramento, non modificare i valori se non corrispondono al testo del documento. Modifica il riquadro di delimitazione solo se è stato selezionato il testo sbagliato.Seleziona
Contrassegna come etichettato quando hai finito di annotare il documento.Ripeti l'operazione per ogni documento etichettato automaticamente.
Vai alla pagina
Crea .Seleziona
Importa documenti .Nella barra laterale, seleziona Importa documenti da Cloud Storage.
Inserisci il tuo percorso nel Percorso di origine contenente i tuoi documenti. Questo bucket deve contenere documenti preetichettati nel formato Documento JSON.
Dall'elenco Suddivisione dati, seleziona Suddivisione automatica. In questo modo, i documenti vengono suddivisi automaticamente per includere l'80% nel set di addestramento e il 20% nel set di test. Lascia deselezionata l'opzione Importa con etichettatura automatica.
Seleziona Importa. L'importazione richiede diversi minuti.
- Dalla pagina Crea puoi accedere alla console
Gestisci set di dati per visualizzare e modificare tutti i documenti e le etichette nel set di dati. Per informazioni sui requisiti del set di dati, in Addestra un modello personalizzato, seleziona Crea nuova versione o Visualizza i requisiti completi. Questo non è un modello di AI generativa. Per un processore basato su modello personalizzato sono necessarie almeno 10 istanze di addestramento e 10 istanze di test per ciascun campo.
Nel campo Nome versione, inserisci un nome per la versione del processore, ad esempio
w2-custom-model.(Facoltativo) Seleziona Visualizza statistiche etichette per visualizzare le informazioni sulle etichette dei documenti. In questo modo puoi stabilire la copertura. Seleziona Chiudi per tornare alla configurazione dell'addestramento.
In Metodo di addestramento del modello, seleziona Basato su modello.
Seleziona Inizia addestramento. L'addestramento richiede alcune ore. Puoi abbandonare questa pagina e tornare più tardi.
(Facoltativo) Seleziona la scheda
Deployment e utilizzo . In questa pagina puoi visualizzare le versioni disponibili del processore e lo stato di addestramento della nuova versione.Al termine dell'addestramento, seleziona la scheda
Deployment e utilizzo .Seleziona la casella di controllo a sinistra della versione di cui vuoi eseguire il deployment e seleziona Esegui il deployment.
Seleziona Esegui il deployment nella finestra di dialogo. Il deployment richiede alcuni minuti.
Una volta completato il deployment della versione, puoi impostarla come
versione predefinita oppure fornire l'ID versione durante l'elaborazione dei documenti con l'API.Seleziona la scheda
Valuta per testare la versione del processore. In questa pagina, puoi visualizzare le metriche di valutazione, tra cui il punteggio F1, precisione e richiamo per l'intero documento e le singole etichette. Per ulteriori informazioni sulla valutazione e sulle statistiche, vedi Valuta il processore.Seleziona il selettore
Versione e seleziona la versione che utilizza il foundation model.Scarica un documento che non è stato incluso nei precedenti corsi o test in modo da poterlo utilizzare per valutare la versione del processore. Se utilizzi i tuoi dati, dovrai utilizzare un set di documenti separato.
Seleziona
Carica documento di test e seleziona il documento appena scaricato. Si apre la pagina Analisi dell'estrattore di documenti personalizzato. L'output sullo schermo mostra l'efficacia dell'estrazione del documento.Testa di nuovo il documento utilizzando la versione utilizzando un modello con addestramento personalizzato.
- Segui gli esempi di codice in Invia una richiesta di elaborazione per utilizzare l'elaborazione batch o online.
- Consulta Quote e limiti per conoscere il numero di pagine supportate per l'elaborazione batch e online.
- Segui l'esempio di codice di Estrattore di documenti personalizzato nella sezione su come gestire la risposta di elaborazione per ottenere le entità estratte dal processore.
Nel menu di navigazione della console Google Cloud , seleziona Document AI e I miei processori.
Seleziona
Altre azioni nella stessa riga del processore da eliminare.Seleziona Elimina processore, inserisci il nome del processore, quindi seleziona di nuovo Elimina per confermare.
Crea un processore
Definisci i campi del processore
Ora ti trovi nella pagina Panoramica del processore per il processore che hai appena creato.
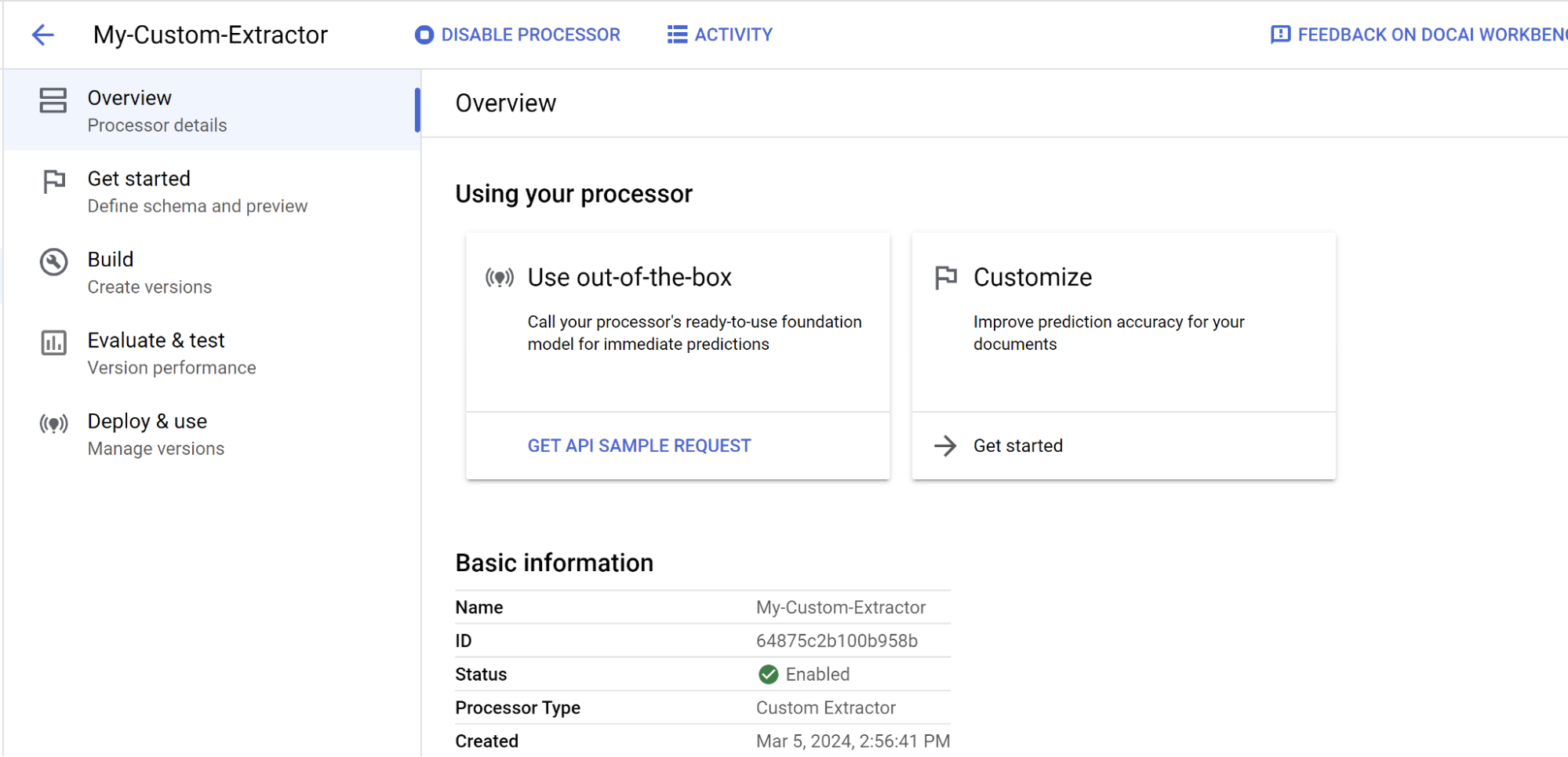
Puoi specificare i campi in cui il processore deve estrarre i documenti e iniziare a etichettarli.
Carica un documento di esempio
Esegui il test con un documento di esempio.
Viene visualizzata la console di etichettatura.
Etichetta un documento
Il processo di selezione del testo in un documento e applicazione di etichette è noto come annotazione o etichettatura.
Crea la versione del processore utilizzando il foundation model
Dopo aver etichettato un singolo documento, puoi creare una versione del processore utilizzando il foundation model preaddestrato per estrarre le entità.
Utilizza l'IA generativa per etichettare automaticamente i documenti
Il foundation model è in grado di estrarre con precisione i campi per vari tipi di documenti, ma puoi anche fornire dati di addestramento aggiuntivi per migliorare l'accuratezza del modello per strutture di documenti specifiche.
L'estrattore personalizzato utilizza i nomi delle etichette che definisci e le annotazioni precedenti per rendere più rapida e semplice l'etichettatura dei documenti su larga scala grazie all'etichettatura automatica.
Importa documenti di addestramento preetichettati
(Facoltativo) Visualizza e gestisci il set di dati
Addestra processore basato su modello personalizzato
L'addestramento potrebbe richiedere diverse ore, assicurati di aver configurato il processore con i dati e le etichette appropriati prima di iniziare l'addestramento.
Esegui il deployment della versione del processore
Valuta e testa il processore
Utilizza il processore
Hai creato e addestrato un processore di estrattore di documenti personalizzato.
Puoi gestire le versioni del processore con addestramento personalizzato come qualsiasi altra versione del processore. Per saperne di più, consulta Gestione delle versioni del processore.
Per utilizzare l'API Document AI:
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa pagina, segui questi passaggi.
Per evitare addebiti non necessari Google Cloud , utilizzaGoogle Cloud console per eliminare il processore e il progetto se non ti servono.
Se hai creato un nuovo progetto per prendere dimestichezza con Document AI, ma non ne hai più bisogno, elimina il progetto.
Se hai utilizzato un progetto Google Cloud esistente, elimina le risorse che hai creato per evitare addebiti sul tuo account.
Passaggi successivi
Per maggiori dettagli, vedi Guide.