Version de décembre 2022
Étape de configuration HITL
L'onglet "Configuration" sous "Human-In-The-Loop" est désormais formaté sous forme de paire ordonnée d'étapes pour une configuration plus simple et plus structurée.
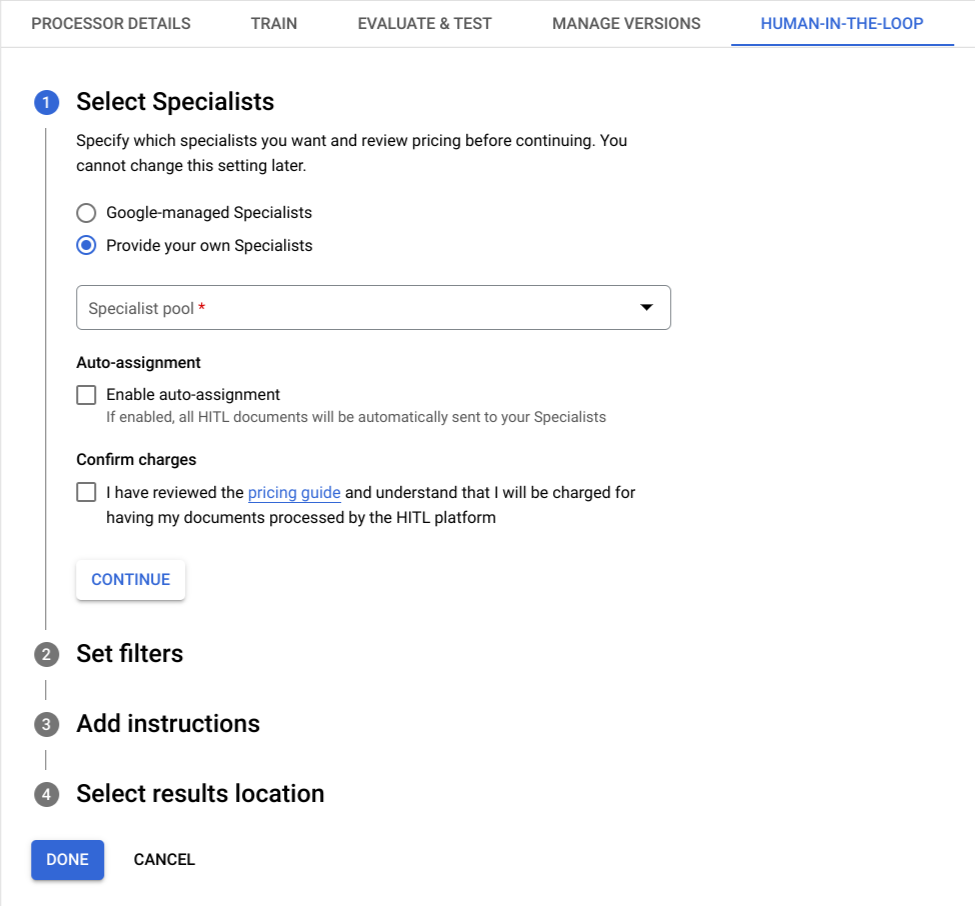 L'utilisateur peut désormais consulter des étapes distinctes pour configurer les paramètres liés au pool de spécialistes et les filtres pour déclencher le HITL, et sélectionner l'emplacement des instructions et des résultats pour les spécialistes.
L'utilisateur peut désormais consulter des étapes distinctes pour configurer les paramètres liés au pool de spécialistes et les filtres pour déclencher le HITL, et sélectionner l'emplacement des instructions et des résultats pour les spécialistes.
Version d'octobre 2022
Tableau de bord analytique des demandeurs HITL
L'onglet Analytics est désormais dédié à l'intervention humaine. Il fournit à l'utilisateur des métriques et des graphiques pour analyser l'état des tâches HITL par processeur et apporter les modifications nécessaires.
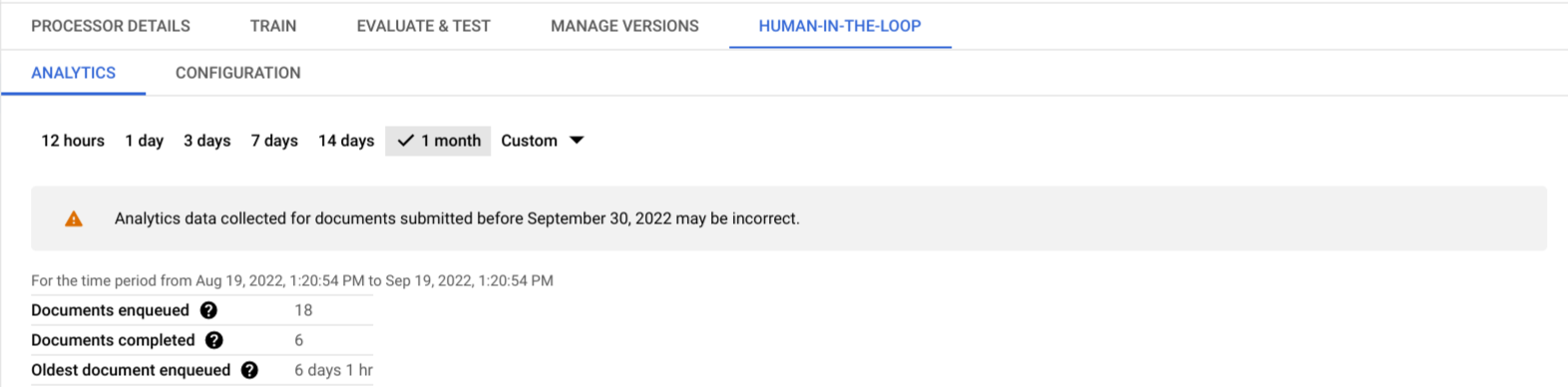
Actuellement, l'utilisateur peut consulter trois métriques différentes. Les données peuvent être agrégées par un sélecteur de période qui propose les options suivantes à l'utilisateur :

Pour chaque période sélectionnée, l'utilisateur peut consulter les informations suivantes :
- Statistiques agrégées : vue instantanée du nombre total de documents importés dans la file d'attente, du nombre total de documents traités (c'est-à-dire envoyés et refusés) par les spécialistes et du temps écoulé depuis l'ajout du document le plus ancien dans la file d'attente pour la période sélectionnée.
- Graphique d'activité human-in-the-loop : graphique montrant les données de série temporelle indiquant quand les documents ont été ajoutés à la file d'attente (
enqueuedDocumentCount) et quand les spécialistes les ont traités (completedDocumentCount).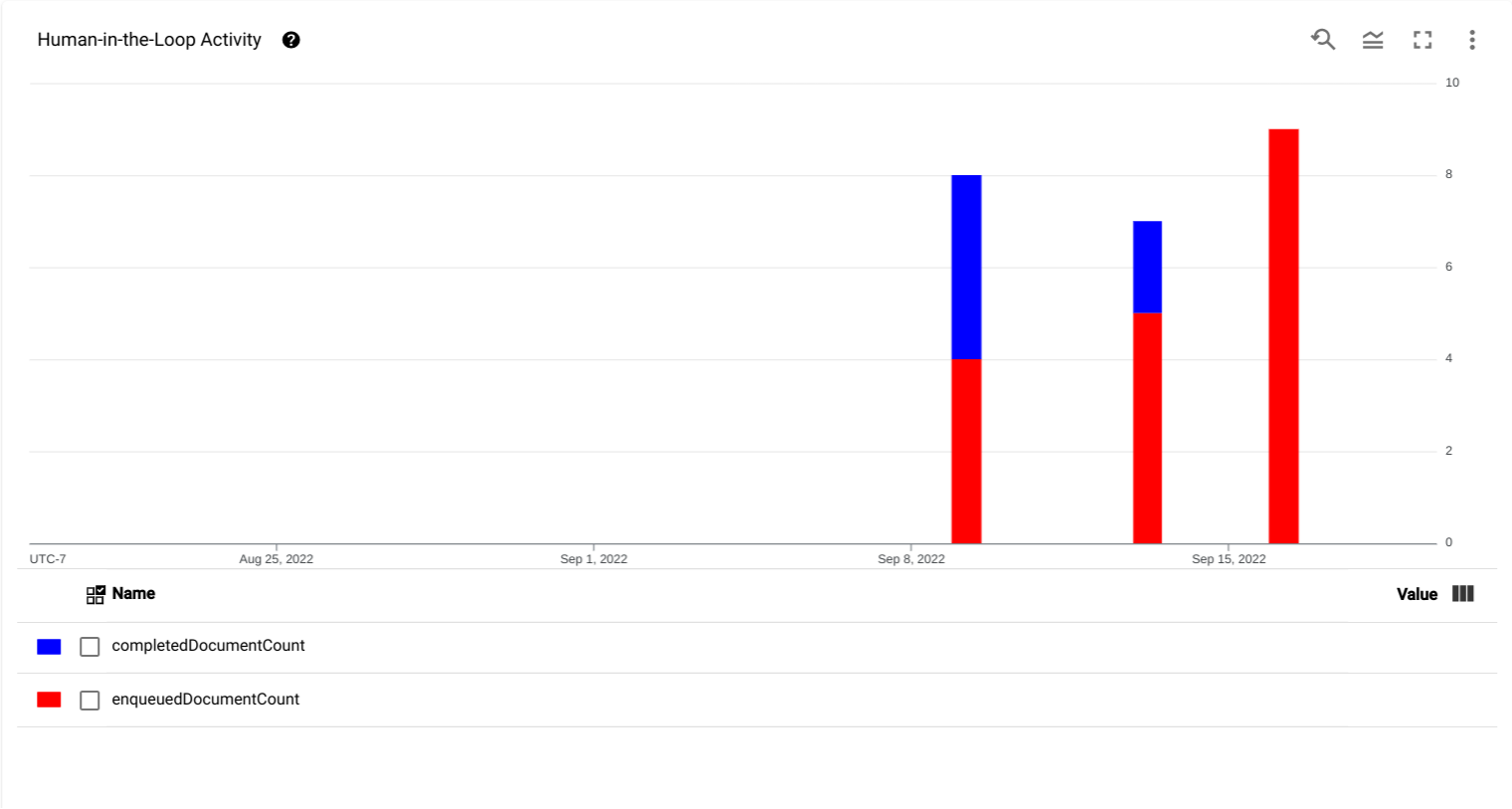
- Taux de déclenchement human-in-the-loop (avec intervention humaine) : graphique affichant les données de série temporelle pour le pourcentage de documents importés qui ont déclenché un examen human-in-the-loop au cours de la période sélectionnée.
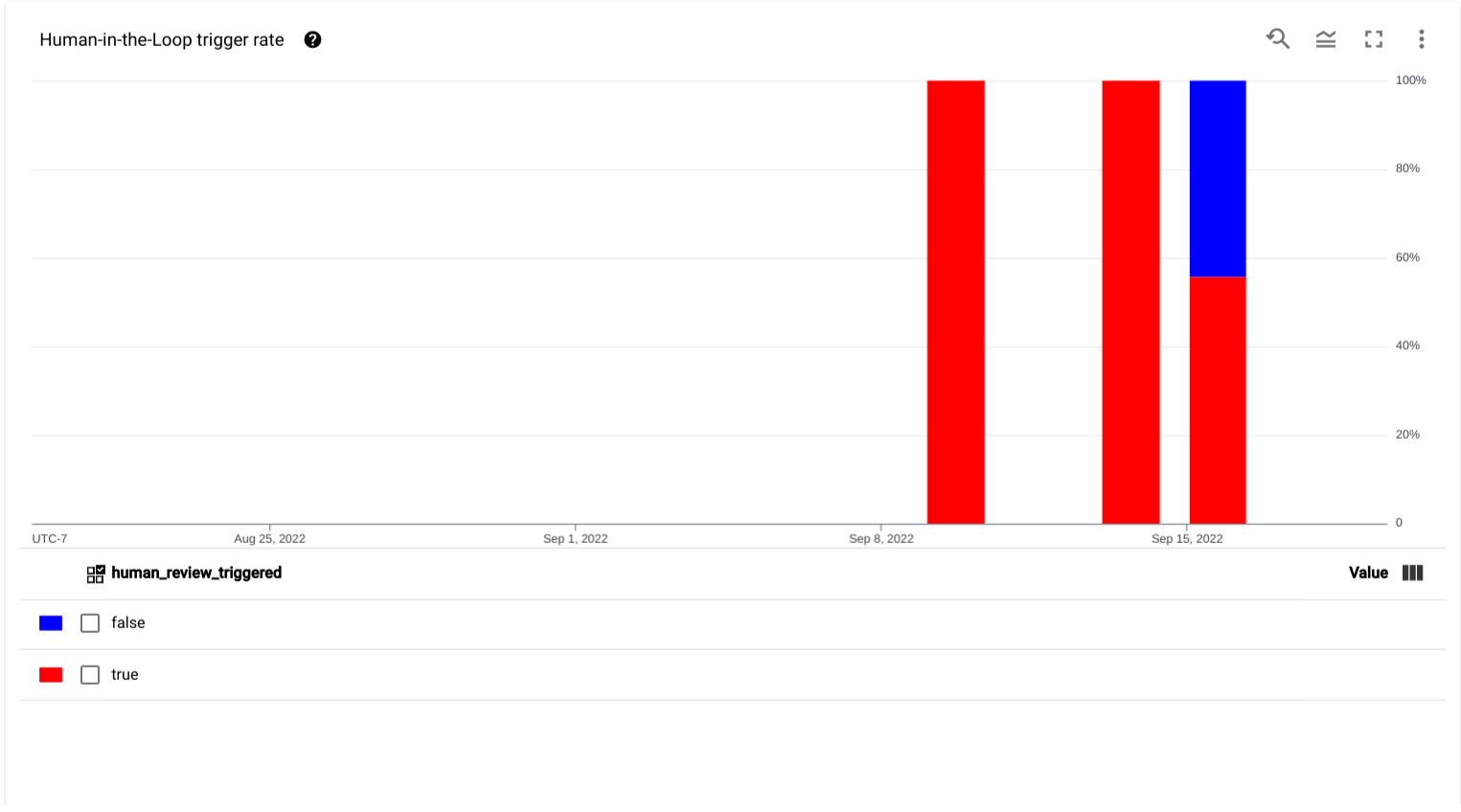
- Statistiques agrégées : vue instantanée du nombre total de documents importés dans la file d'attente, du nombre total de documents traités (c'est-à-dire envoyés et refusés) par les spécialistes et du temps écoulé depuis l'ajout du document le plus ancien dans la file d'attente pour la période sélectionnée.
Version de septembre 2022
Remarque : Les clients qui utilisent les processeurs Document AI Workbench, bon de commande, facture et note de frais ont accès à un nouveau schéma qui leur permet de libeller les cases à cocher (si elles sont définies dans le schéma) et de représenter précisément les entités imbriquées, c'est-à-dire la relation parent-enfant, dans l'interface utilisateur d'annotation et de révision HITL. À mesure que d'autres processeurs adopteront le nouveau schéma, ces notes de version seront mises à jour.
Entité imbriquée
- L'UI d'annotation permet désormais d'étiqueter les entités imbriquées. Le panneau de gauche est actualisé et présente une nouvelle apparence pour les lignes imbriquées, afin de représenter les entités imbriquées. La valeur "parent" est la concaténation de tous ses "enfants".
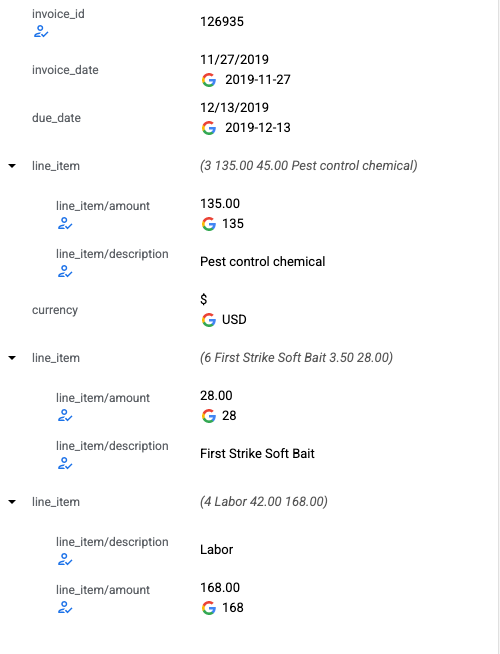
- La sélection d'entités dans le panneau de gauche affiche les libellés parent et enfant.

- Le menu des libellés d'entités dans le document est également actualisé pour prendre en charge l'étiquetage des entités imbriquées.
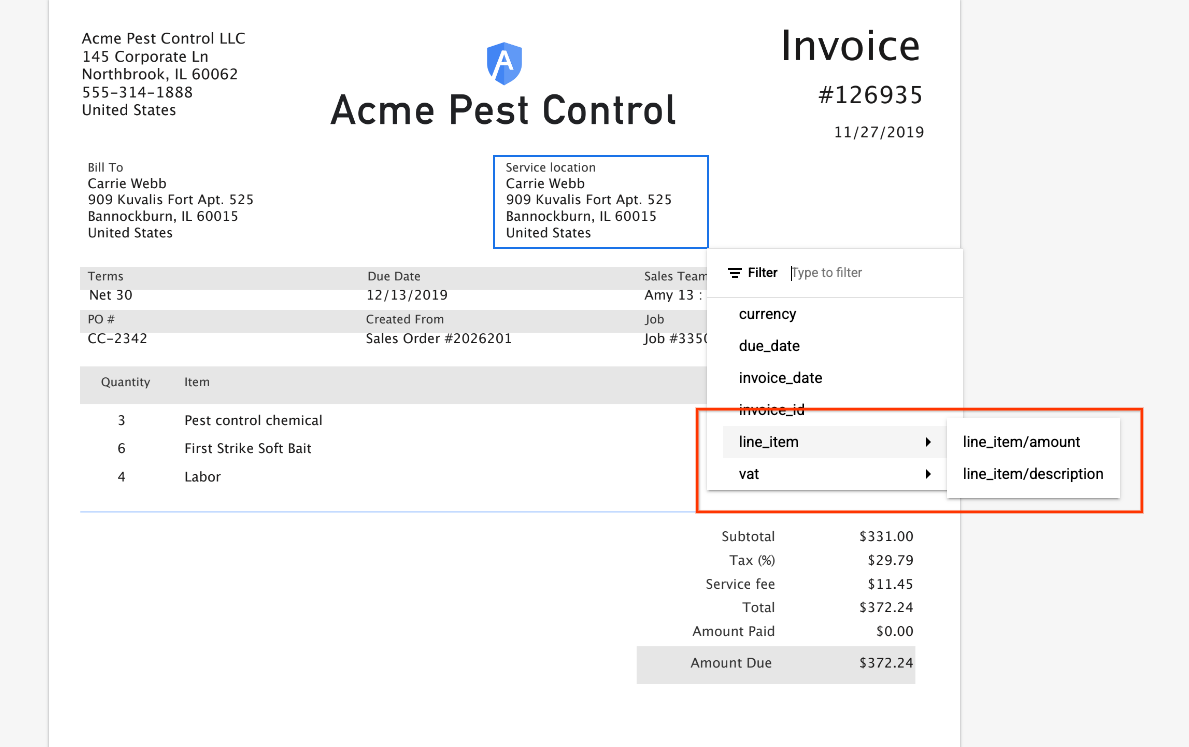
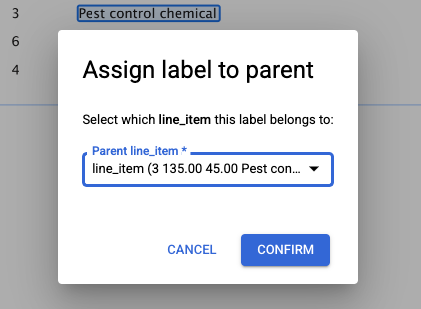
- Si vous cliquez sur un libellé imbriqué, une boîte de dialogue s'affiche pour vous permettre d'attribuer l'entité parente appropriée à l'entité enfant imbriquée.
Case à cocher
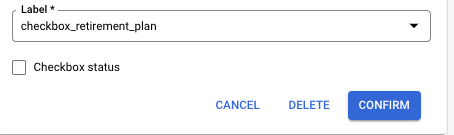
- L'UI d'annotation permet d'étiqueter des cases à cocher. Dans le panneau de gauche, la case à cocher peut être modifiée dans la ligne.

- La modification des cases à cocher est également disponible dans la boîte de dialogue de modification des entités.
Version d'août 2022
Sélectionner un libellé d'entité
- L'entrée de libellé d'entité est remplacée par une liste déroulante. Cette liste déroulante contient les options de libellé disponibles lorsque vous ajoutez une entité. Cette modification permet d'éviter que les annotateurs fassent des fautes de frappe et créent des libellés d'entités indésirables.
Format de date ISO
- Les dates normalisées sont affichées au format ISO 8601(aaaa-mm-jj).

Version de juillet 2022
Bouton de confirmation rapide
- Un bouton "Confirmer" est disponible dans les info-bulles des entités pour examiner et confirmer rapidement une valeur d'entité/de libellé. Le bouton "Modifier" a été supprimé, car les utilisateurs peuvent cliquer directement sur l'info-bulle de l'entité pour la modifier.
Version de janvier 2022
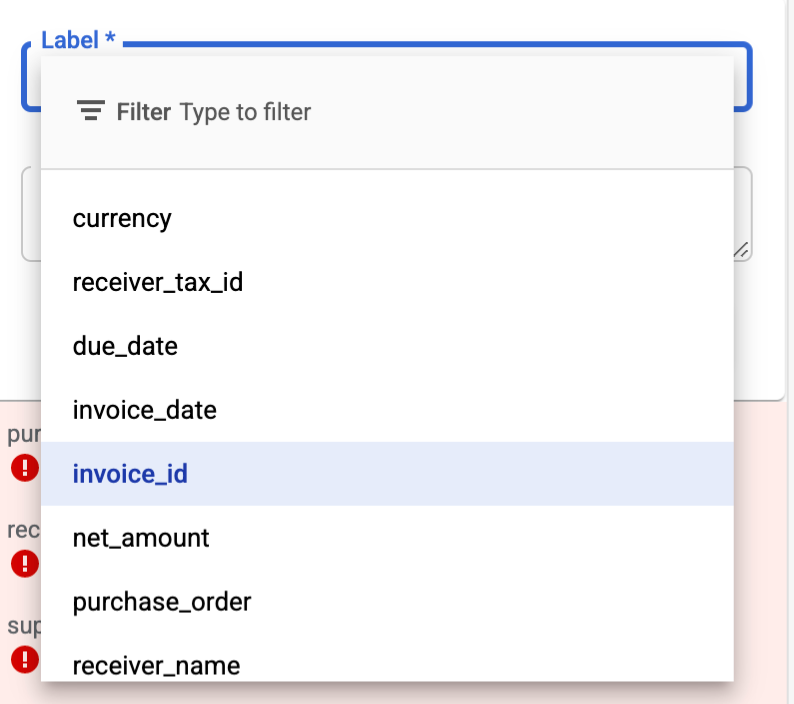
Options de libellé d'entité
- Les options de sélection des libellés d'entité sont désormais limitées à la liste des champs filtrés(définis dans la configuration du filtre HITL).
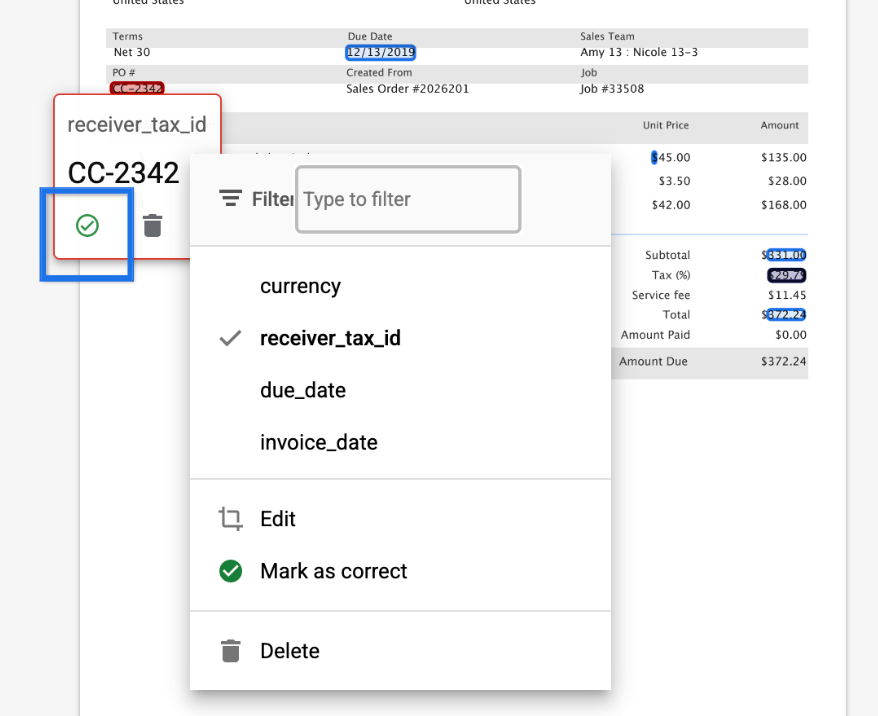
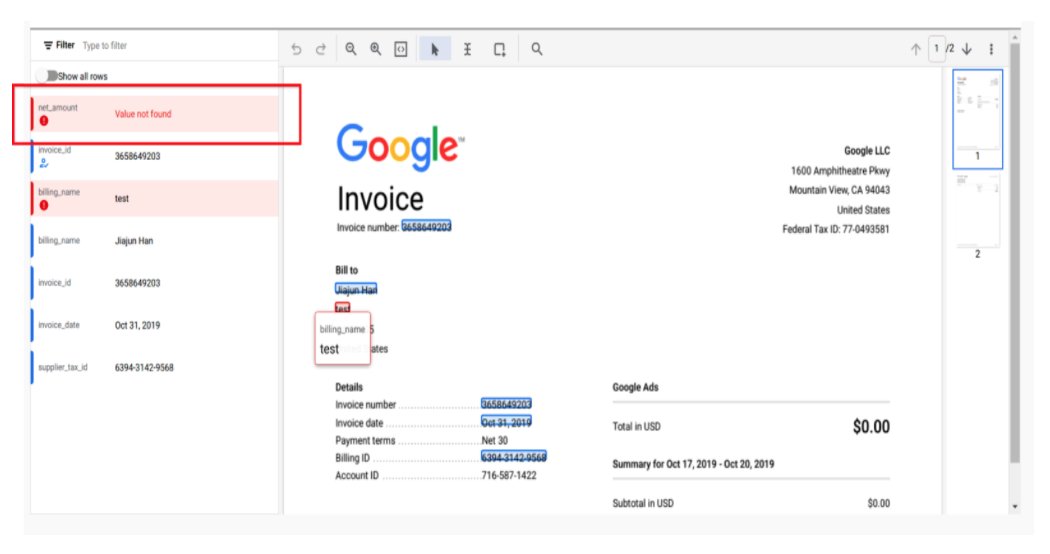
Champs manquants
- Nous affichons désormais les champs manquants (c'est-à-dire les champs marqués comme "Obligatoires" dans la configuration du filtre HITL, mais pour lesquels le processeur n'a pas prédit de valeurs) en rouge, ce qui permet au réviseur de mettre facilement à jour la valeur du champ.
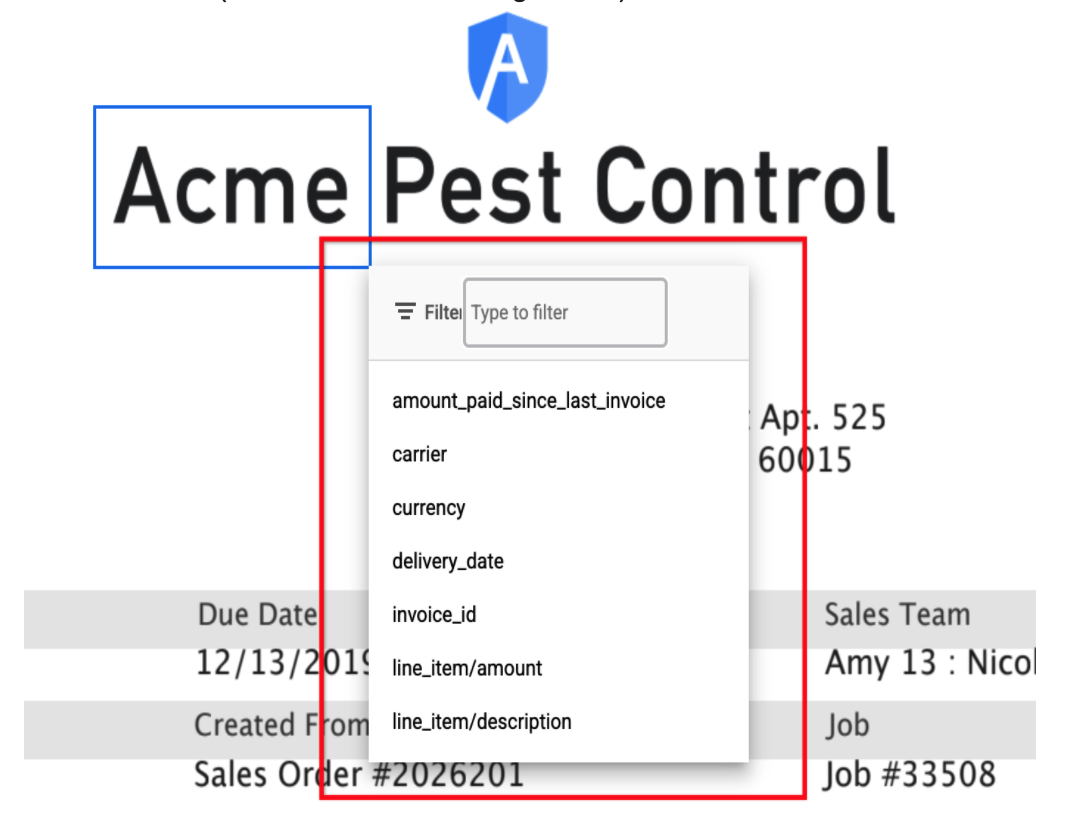
Échantillons complets aléatoires
- Nous acceptons désormais l'examen complet (c'est-à-dire de toutes les entités du document, et pas seulement des champs filtrés) d'un échantillon aléatoire de documents (par exemple, 2 % du volume quotidien). Cela permet de surveiller la dérive du modèle et d'obtenir des données analytiques sur la précision du processeur dans chaque champ. Nous collectons ces données analytiques, qui nous permettent de savoir quand un réentraînement est nécessaire. Il sert également d'ensemble de données avec une vérité terrain étiquetée pour les modèles d'entraînement.
- Les clients peuvent activer l'échantillon aléatoire et le définir sur une valeur comprise entre 1 % et 10 % en fonction de leur volume. Il serait utile de cibler entre 100 et 500 échantillons par semaine. Par exemple, si un client traite 10 000 documents par semaine, cette valeur peut être définie sur 500/10 000 = 5 %.
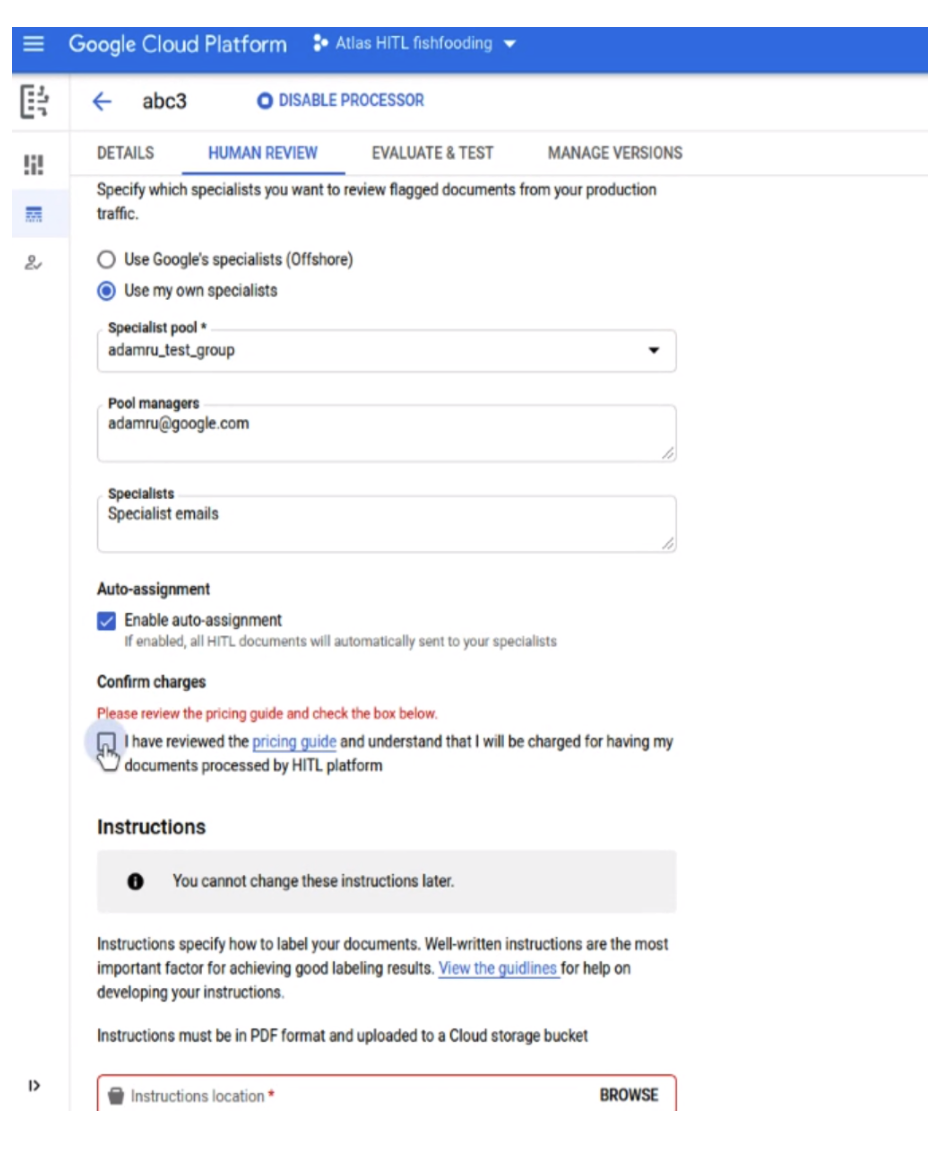
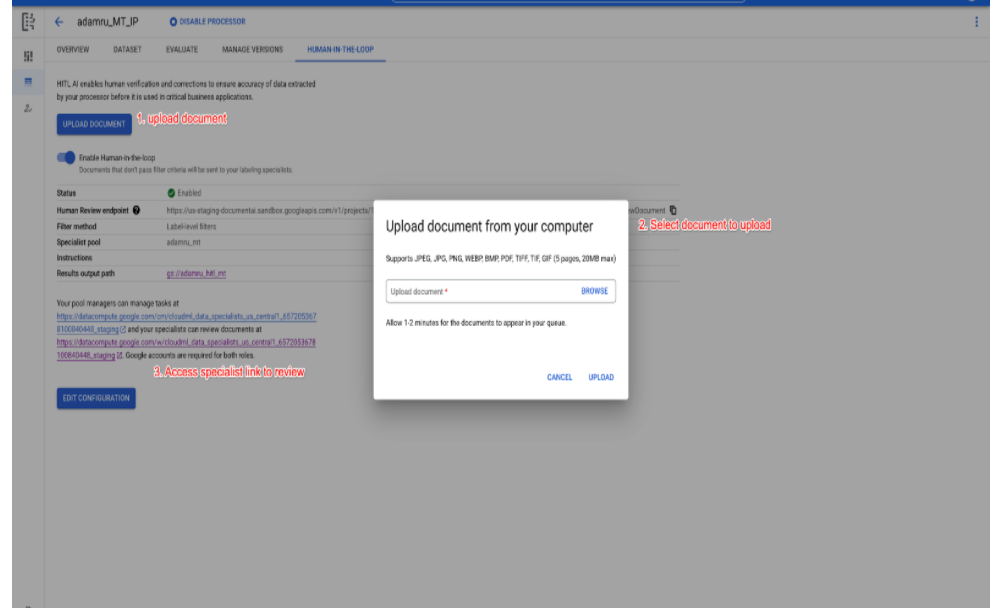
Configuration HITL simplifiée pour les nouveaux utilisateurs
- Nous avons simplifié la configuration BYOL HITL pour les nouveaux clients HITL. Ils peuvent ainsi configurer rapidement une tâche, attribuer des spécialistes et la lancer à partir d'un seul écran. Ils peuvent ainsi la tester rapidement avant d'augmenter le volume de production ou d'externaliser l'opération.
- Comme le montre la capture d'écran ci-dessous, l'utilisateur est défini comme gestionnaire par défaut du pool. Il peut ajouter d'autres spécialistes, qui sont tous automatiquement attribués à la tâche sur le même écran.
- Auparavant, le responsable désigné recevait un lien vers la console de gestionnaire, où il ajoutait des spécialistes et leur attribuait la tâche.
- Une fois la tâche envoyée, ils (et les autres spécialistes attribués) peuvent accéder à l'application HITL pour examiner les documents.
- L'utilisateur peut également importer un document de test (un à la fois) dans la file d'attente des tâches.
Supprimer le saut de ligne final
- Les retours à la ligne("\n") en fin de ligne sont supprimés dans entity.mentionText.
Version de décembre 2021
Trier les entités à faible score de confiance en haut de la liste
- Les entités dont le score de confiance est faible (c'est-à-dire celles qui sont inférieures au seuil de confiance) sont désormais triées en haut de la page, ce qui permet au spécialiste de se concentrer sur ces entités. Cela permet d'améliorer encore l'efficacité de l'étiquetage.

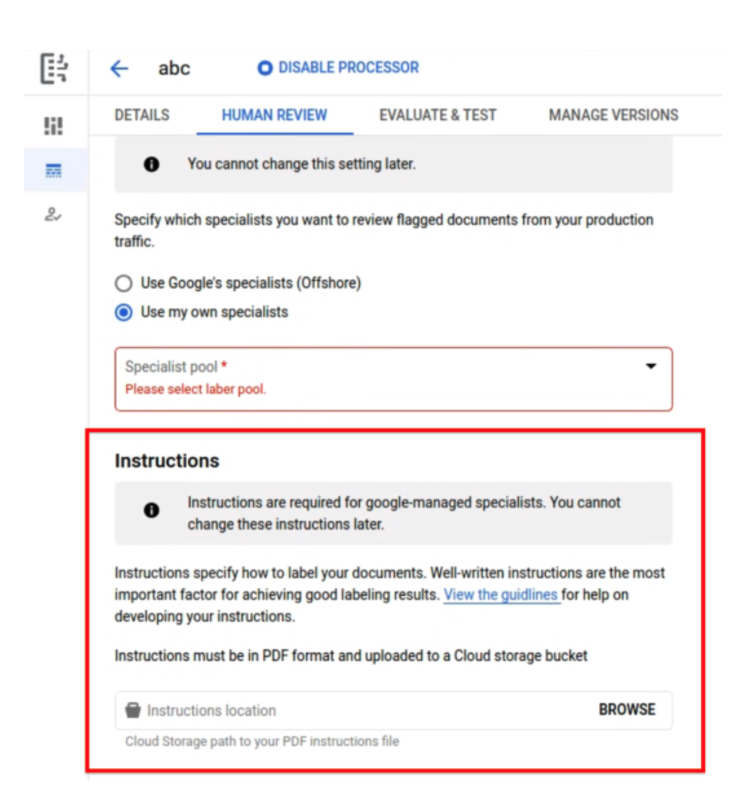
Instructions facultatives pour les tâches BYOL
- Le fichier PDF d'instructions à importer pour configurer une tâche HITL est désormais facultatif. Cela simplifie les tests et les lancements internes rapides pour lesquels les spécialistes n'ont pas besoin de guide d'instructions.
Option "Ajuster à la largeur" et "Ajuster à la hauteur de la page"
- Bouton permettant d'adapter la page à la largeur ou à la hauteur. Cela est utile lorsque les spécialistes doivent traiter des documents de taille variable (par exemple, des reçus) dans une tâche.

Nom de la tâche affiché dans l'UI du spécialiste
- Le nom de la tâche est désormais affiché dans l'UI des spécialistes pour leur fournir des informations supplémentaires sur la tâche et le type de document. Cela est très utile lorsque le spécialiste est affecté à plusieurs tâches.
- Notez que cela s'affiche dans les nouveaux processeurs lancés après cette version.

Champ de recherche pour les spécialistes
- Les spécialistes peuvent rechercher des entités/du texte dans les documents. Cela est particulièrement utile pour les grands documents de plusieurs pages et permet aux spécialistes d'être plus productifs.

Version de septembre 2021
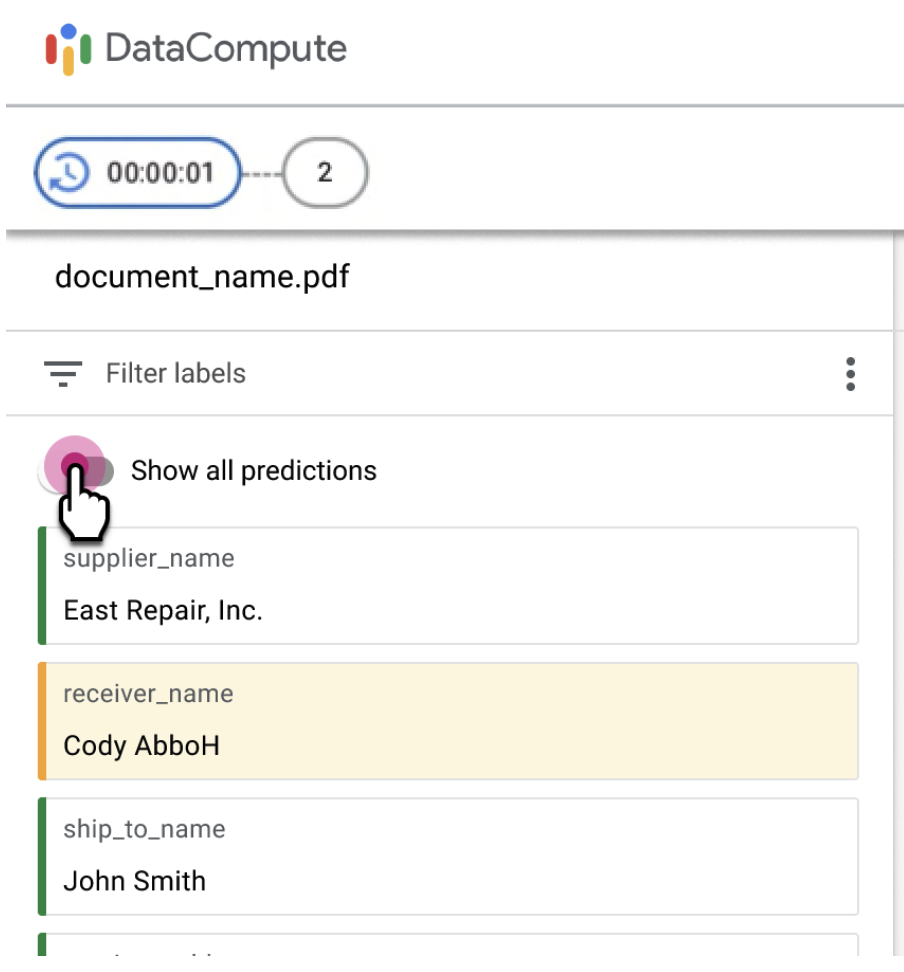
Activez l'option pour afficher tous les champs.
- Les annotateurs peuvent avoir besoin d'examiner et de mettre à jour les champs qui ne figurent pas dans l'ensemble filtré d'entités pour des documents spécifiques de la file d'attente.
Vous pouvez activer l'option Afficher toutes les prédictions pour permettre aux annotateurs d'examiner les champs non filtrés.
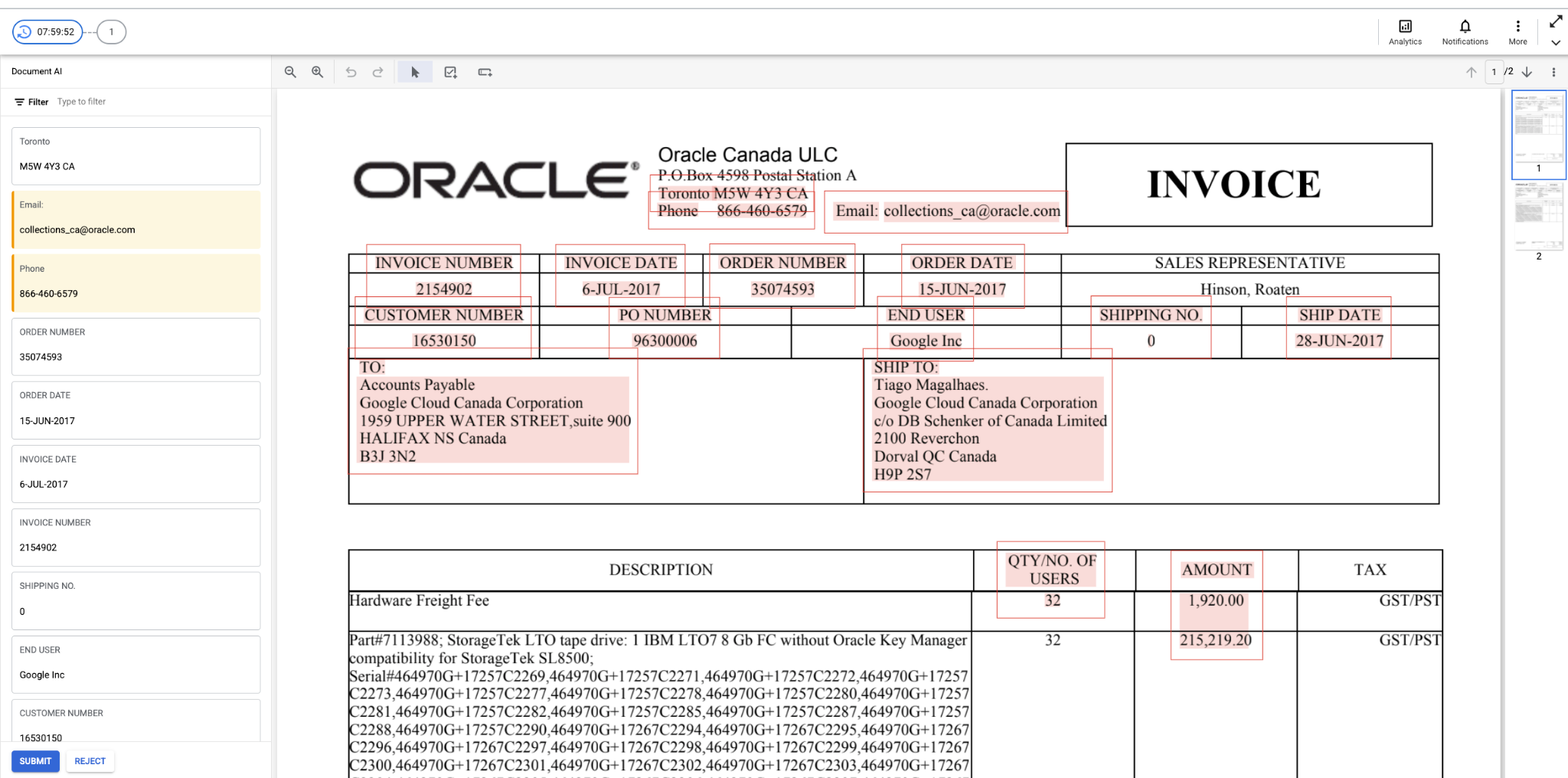
HITL pour l'analyseur de formulaires
- HITL est désormais compatible avec l'analyseur de formulaires. Les utilisateurs peuvent ainsi examiner et corriger les paires clé/valeur extraites par l'analyseur de formulaires. Le client peut activer HITL sur le processeur Form Parser de la plate-forme DocAI et configurer les noms de clés (comme indiqué dans la capture d'écran ci-dessous) qu'il souhaite filtrer pour l'examen HITL. Une fois l'examen HITL terminé, les résultats sont déposés sous forme de fichiers JSON dans le bucket Google Cloud Storage spécifié par le client.
- Ils peuvent spécifier des noms de clés alternatifs séparés par des virgules (par exemple, "client, nom du client, compte, n° de compte") afin que le filtre HITL détecte les documents avec toutes les variantes de noms de clés et les envoie pour examen HITL.



Version d'août 2021
Pipeline d'audit/de contrôle qualité
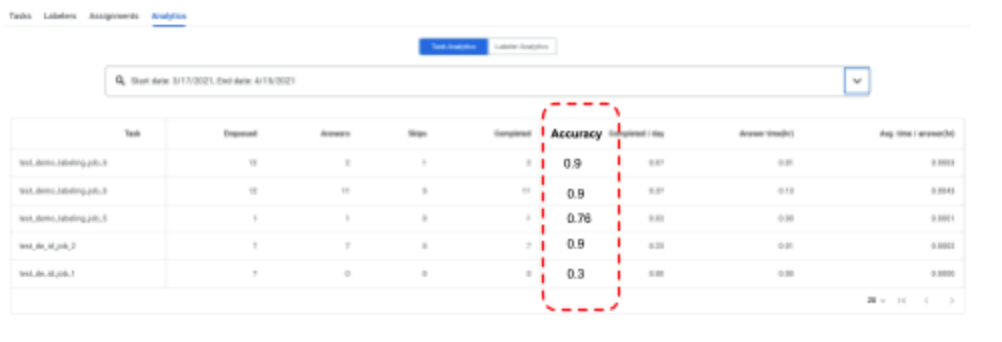
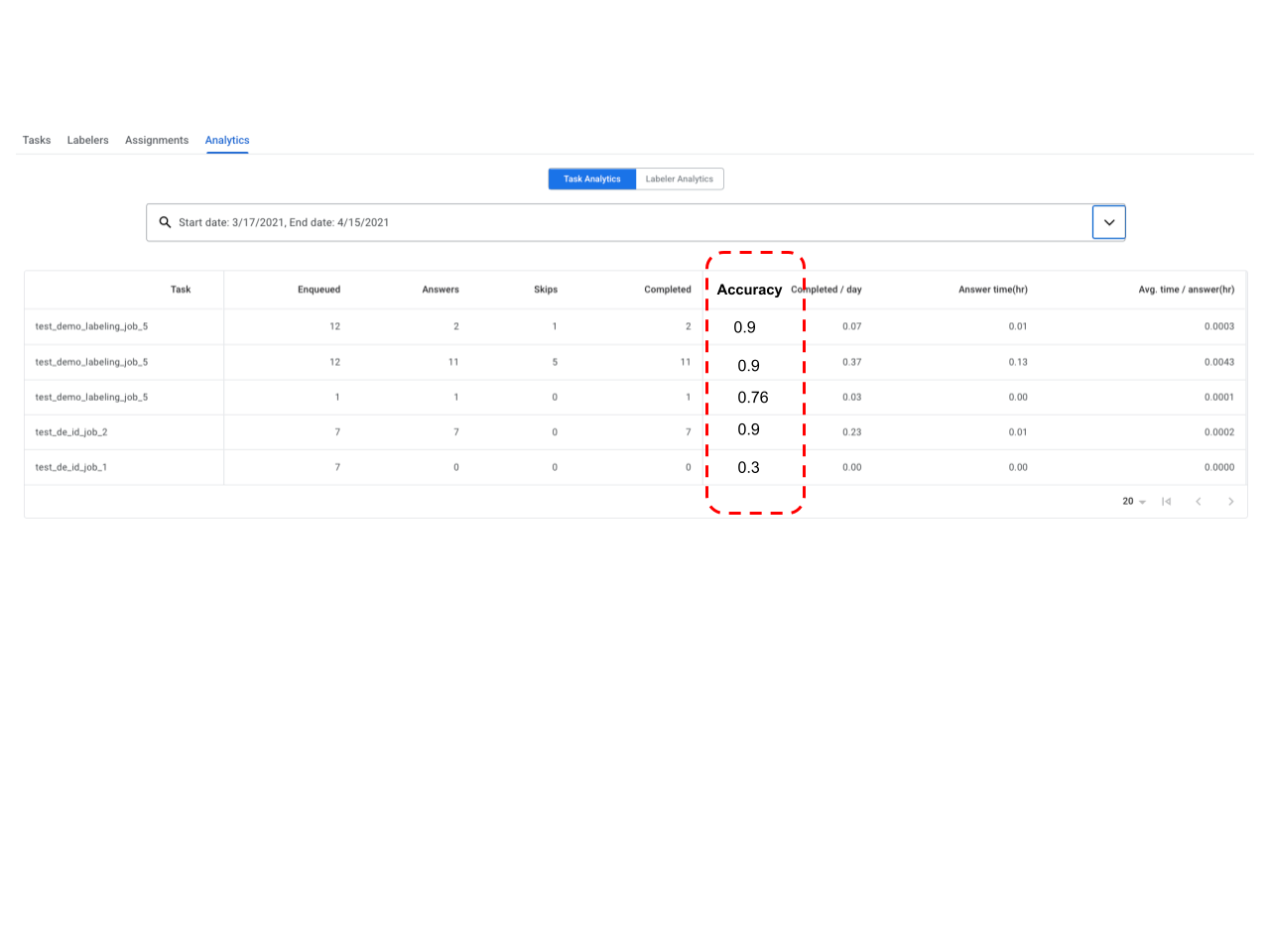
- L'HITL permet désormais une deuxième étape de contrôle qualité ou d'audit, et indique la précision des tâches d'examen (et des annotateurs). Une équipe QA ou un auditeur peuvent être désignés comme "annotateurs experts" pour une tâche. L'équipe QA/l'auditeur reçoit X % (par exemple, de 1 à 100 %, ce pourcentage est configurable par le client) des documents examinés. L'auditeur peut corriger le résultat de l'examinateur. Le système suit les corrections et attribue un score de précision (par exemple, 90 %) à chaque document audité. Le score de précision global d'une tâche ou d'un étiqueteur est indiqué dans les tableaux de bord "Analytics des tâches" et "Analytics des étiqueteurs", respectivement.
- Pour obtenir des instructions détaillées sur la configuration d'un pipeline d'audit, cliquez ici.
- Désigner un auditeur
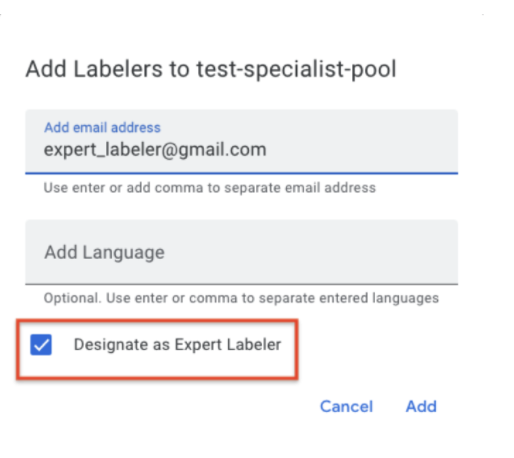
- Précision des rapports
Analyseurs Lending AI (15 août)
- L'HITL est désormais compatible avec certains analyseurs d'IA de prêt, y compris les formulaires 1040, 1040 Schedule E, 1040 Schedule C, 1099-DIV, 1099-G, 1099-INT, 1099-MISC, les bulletins de paie, les relevés bancaires, les formulaires W2, W9, 1120, 1120S, 1065, SSA-1099, 1099-NEC et 1099-R.
Version de juillet 2021
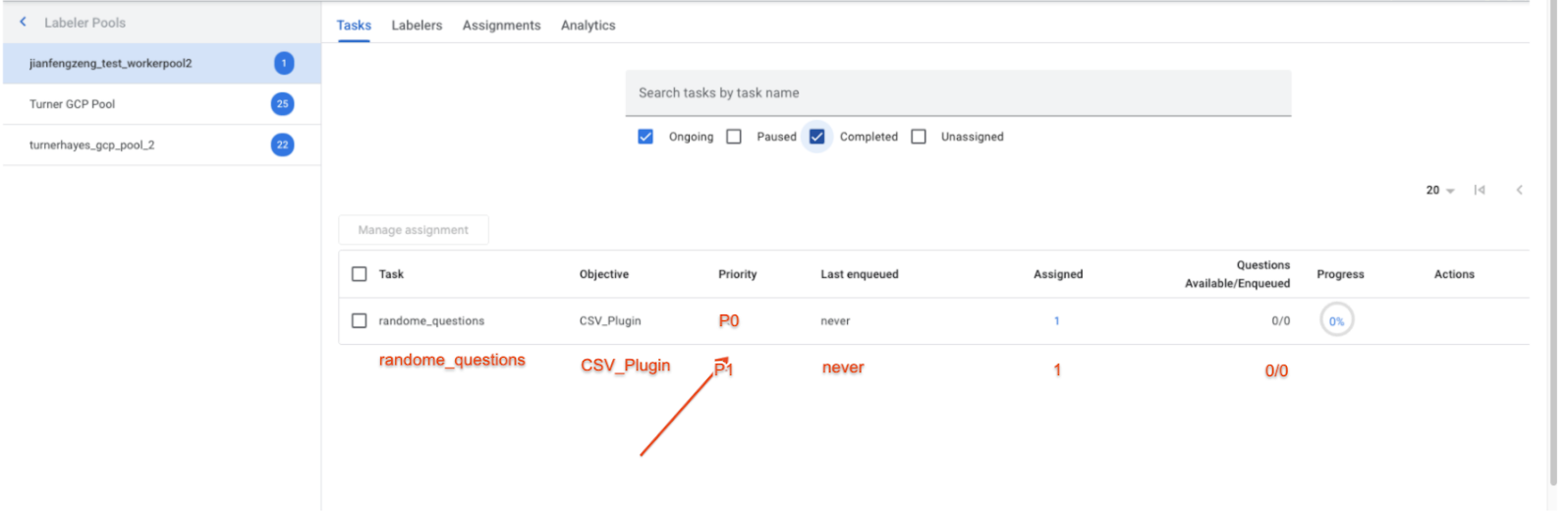
Files d'attente standard et urgente (2 juillet)
- Nous acceptons désormais deux files d'attente prioritaires (au lieu d'une) pour chaque processeur, en fonction de l'urgence de chaque document.
- Envoi : après la prédiction, l'urgence des documents extraits peut être évaluée. Ils peuvent ensuite être envoyés à deux files d'attente (standard ou urgente/accélérée) en fonction de leur urgence. Par exemple, les factures dont la date d'échéance est urgente peuvent être envoyées à la file d'attente Fast-track. La logique qui évalue l'urgence est actuellement en dehors de HITL et peut être une fonction personnalisée.
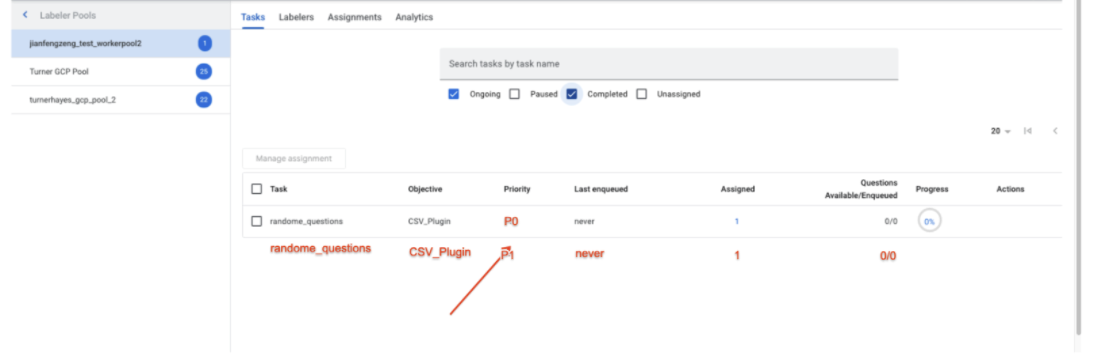
- Attribution des tâches : le responsable du libellé voit deux files d'attente différentes avec des priorités différentes, comme indiqué dans la capture d'écran ci-dessous, et peut attribuer le même groupe de libellés aux deux files d'attente.
- Priorisation des tâches : les annotateurs attribués aux deux tâches traiteront toujours les documents en attente dans la file d'attente rapide avant de traiter ceux de la file d'attente standard (c'est-à-dire que la priorisation des files d'attente est automatiquement gérée par le système).
- Appel d'API : définissez le champ priority dans ReviewDocument.
- Capture d'écran de l'UI (des tâches dans l'UI du gestionnaire de libellés) -
Version de juin 2021
Filtres de validation pour le point de terminaison HITL (24 juin)
- Les filtres de validation (configurés dans le processeur) qui filtrent les champs par score de confiance pour déterminer les documents à mettre en file d'attente pour examen manuel sont désormais également appliqués aux documents envoyés au point de terminaison HITL.
- Lorsque vous appelez l'API ReviewDocument, définissez le champ enable_schema_validation sur "true".
- Notez que si cette option est définie et que la validation détermine que le document n'a pas besoin de déclencher un examen manuel, une erreur "ANNULÉ" est renvoyée.
API Cancel
Le client peut annuler un document mis en file d'attente pour le traitement HITL en appelant l'API d'annulation pour un ID d'opération donné. Un ID d'opération est renvoyé pour chaque document envoyé à HITL.
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
Type de facture (examen de la classification)
- L'atelier d'étiquetage permet d'examiner la classification du type de facture.

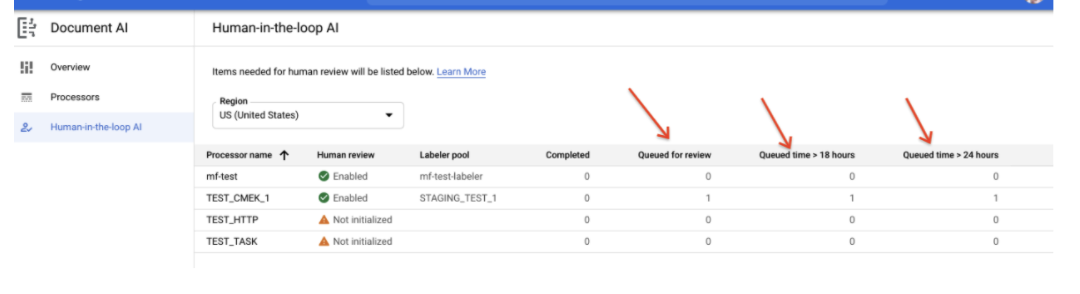
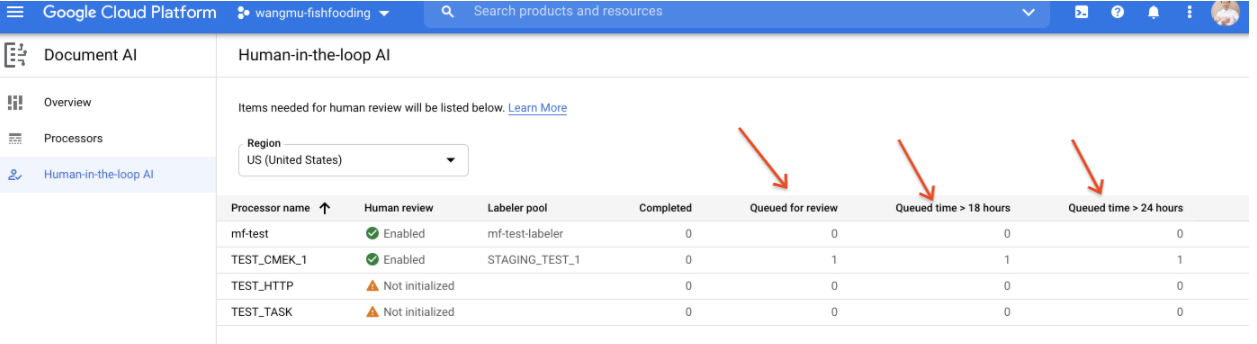
Rapport "Temps d'attente dans la file d'attente (SLO de latence HITL)"
- Un rapport indique le nombre de documents mis en file d'attente depuis plus de 18 heures et plus de 24 heures. Cela est utile pour les utilisateurs qui doivent gérer une attente de SLO concernant la latence HITL.
URL connue pour Labeler Workbench
- Les annotateurs attribués à un seul pool peuvent désormais accéder à l'atelier à une URL connue. Ils n'ont plus besoin de rechercher des URL cryptiques envoyées dans les notifications par e-mail (par le système ou par le responsable de l'annotation). Cette URL ne fonctionne pas pour les annotateurs attribués à plusieurs pools.
Paramètre de zoom persistant
- Le plug-in mémorise désormais le paramètre de zoom de l'utilisateur (pleine largeur ou pleine page) pour les prochains documents à examiner dans la file d'attente, afin qu'il n'ait pas à faire un zoom avant pour chaque document.
HITL pour l'analyseur de formulaires
- HITL est désormais compatible avec l'analyseur de formulaires. Les utilisateurs peuvent examiner et corriger les paires clé/valeur extraites par l'analyseur de formulaires, activer HITL sur le processeur de l'analyseur de formulaires dans la plate-forme DocAI et configurer les noms de clés (comme indiqué dans la capture d'écran ci-dessous) qu'ils souhaitent filtrer pour l'examen HITL. Une fois l'examen HITL terminé, les résultats sont enregistrés dans des fichiers JSON dans le bucket Google Cloud Storage spécifié par le client.
- Captures d'écran de l'UI pour configurer HITL sur les analyseurs de formulaires
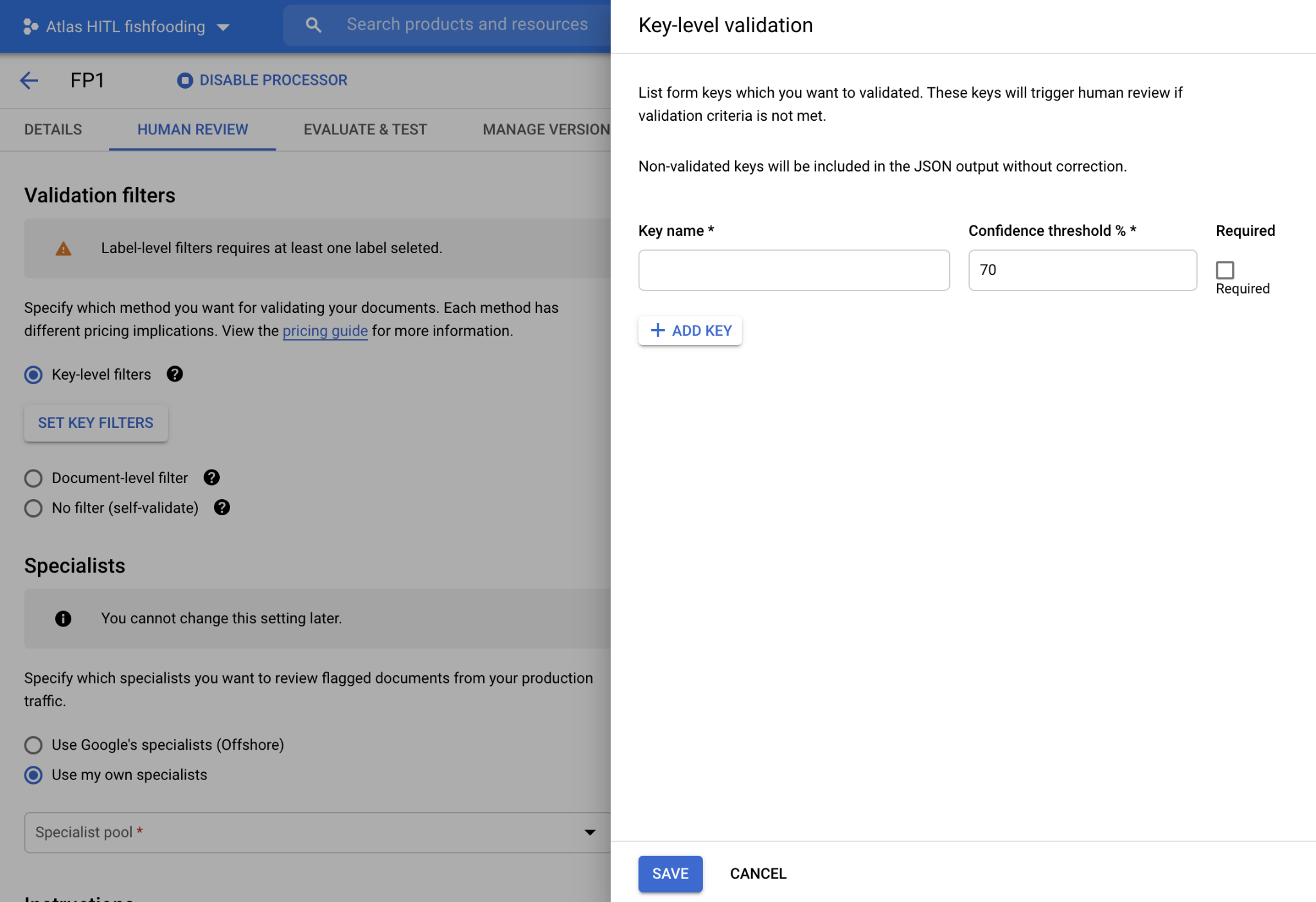
- Interface utilisateur pour configurer la validation au niveau des clés
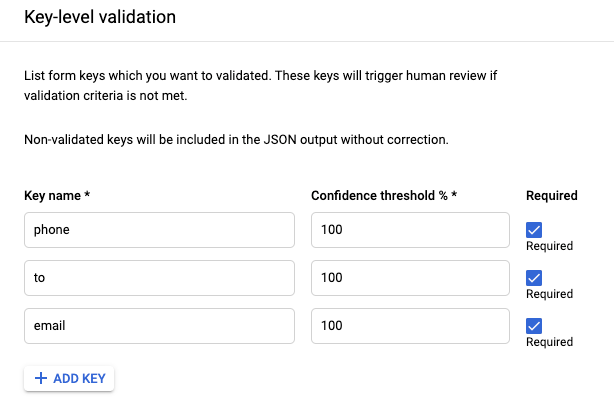
- Interface utilisateur de l'étiqueteur
Pipeline d'audit/de contrôle qualité
- L'HITL permet désormais une deuxième étape de contrôle qualité ou d'audit, et indique la précision des tâches d'examen (et des annotateurs). Une équipe QA ou un auditeur peuvent être désignés comme "annotateurs experts" pour une tâche. L'équipe QA/l'auditeur recevra X % (par exemple, de 1 % à 100 %, configurable par le client) des documents examinés. L'auditeur peut corriger le résultat de l'examinateur. Le système suit les corrections et attribue un score de précision (par exemple, 90 %) à chaque document audité. Le score de précision global d'une tâche ou d'un étiqueteur est indiqué dans les tableaux de bord "Analytics des tâches" et "Analytics des étiqueteurs", respectivement. Vous trouverez ci-dessous des instructions détaillées sur la configuration d'un pipeline d'audit.
Désigner un auditeur
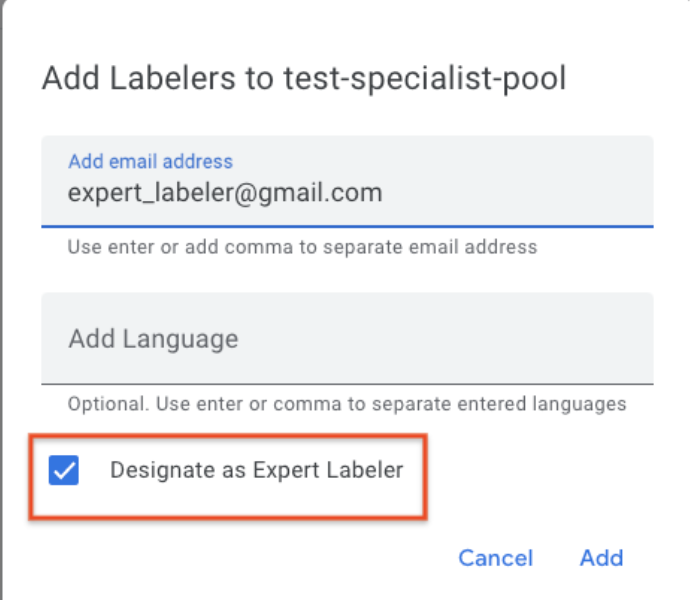
Précision des rapports
Analyseurs Lending AI (31 juillet)
- L'HITL est désormais compatible avec certains analyseurs d'IA de prêt, y compris les formulaires 1040, 1040 Schedule E, 1040 Schedule C, 1099-DIV, 1099-G, 1099-INT, 1099-MISC, les bulletins de paie, les relevés bancaires, les formulaires W-2, W-9, 1120, 1120-S, 1065, SSA-1099, 1099-NEC et 1099-R.
Files d'attente standards et accélérées (2 juillet)
- Nous acceptons désormais deux files d'attente prioritaires (au lieu d'une) pour chaque processeur, en fonction de l'urgence de chaque document.
- Envoi : après la prédiction, l'urgence des documents extraits peut être évaluée. Ils peuvent ensuite être envoyés à deux files d'attente (standard ou urgente/accélérée) en fonction de leur urgence. Par exemple, les factures dont la date d'échéance est urgente peuvent être envoyées à la file d'attente Fast-track. La logique qui évalue l'urgence peut être saisie à l'aide d'une fonction personnalisée.
- Attribution des tâches : le responsable du libellé voit deux files d'attente différentes avec des priorités différentes, comme indiqué dans la capture d'écran ci-dessous, et peut attribuer le même groupe de libellés aux deux files d'attente.
- Priorisation des tâches : les annotateurs attribués aux deux tâches traiteront toujours les documents en attente dans la file d'attente rapide avant de traiter ceux de la file d'attente standard (c'est-à-dire que la priorisation des files d'attente est automatiquement gérée par le système).
- Appel d'API : définissez le champ priority dans ReviewDocument.
- Capture d'écran de l'UI (des tâches dans l'UI du gestionnaire de libellés)
Filtres de validation pour le point de terminaison HITL (24 juin)
- Les filtres de validation (configurés dans le processeur) qui filtrent les champs par score de confiance pour déterminer les documents à mettre en file d'attente pour examen manuel sont désormais également appliqués aux documents envoyés au point de terminaison HITL.
- Lorsque vous appelez l'API
ReviewDocument, définissez le champ enable_schema_validation sur "true". Notez que si cette option est définie et que la validation détermine que le document n'a pas besoin de déclencher un examen manuel, une erreur CANCELLED sera renvoyée.
API Cancel
Vous pouvez annuler un document mis en file d'attente pour le traitement HITL en appelant l'API Cancel pour un ID d'opération donné. [Un ID d'opération est renvoyé pour chaque document envoyé à HITL]
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
Type de facture (examen de la classification)
- L'atelier d'étiquetage permet d'examiner la classification du type de facture.

Rapport "Temps d'attente dans la file d'attente (SLO de latence HITL)"
- Un rapport indique le nombre de documents mis en file d'attente depuis plus de 18 heures et plus de 24 heures. Cela est utile pour les utilisateurs qui doivent gérer une attente de SLO concernant la latence HITL.
URL connue pour Labeler Workbench
- Les annotateurs attribués à un seul pool peuvent désormais accéder à l'atelier à une URL connue : https://datacompute.corp.google.com/w/. Cela peut s'avérer utile si vous perdez l'e-mail contenant l'URL qui vous a été envoyé par le système ou le responsable de l'étiquetage. Cette URL ne fonctionne pas pour les annotateurs attribués à plusieurs pools.
Paramètre de zoom persistant
- Le plug-in mémorise désormais le paramètre de zoom (pleine largeur ou pleine page) d'un annotateur pour les prochains documents à examiner dans la file d'attente. Il n'est donc plus nécessaire de faire un zoom avant pour chaque document.