Document AI は、Enterprise Knowledge Graph を使用して、エンティティ抽出結果(サポートされているフィールドの場合)を正規化および拡充します。たとえば、123 Main St Apt 1 と 123 Main street # 1 のアドレスは、同じ標準化されたアドレスに正規化できます。
サポートされている各フィールドについて、Document AI は抽出された未加工のフィールドに加えて normalizedValue も返し、リテラル テキストを正規化します。これには、後処理を減らすために標準化された形式のデータが含まれています。
ほとんどのデータは次のいずれかのカテゴリに属します。
- 金額
- 日付
- タイムスタンプ
- 住所
- ブール値
- 整数
- 浮動小数点数
レスポンスの例
次の切り捨てられたサンプルに示すように、拡充された値は entities.normalizedValue フィールドにあります。
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "employer_name",
"mentionText": "Google Singapore",
"confidence": 0.69933707,
"pageAnchor": {
"pageRefs": [
{
"boundingPoly": {
"normalizedVertices": [ ... ]
}
}
]
},
"id": "9",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
}
]
}
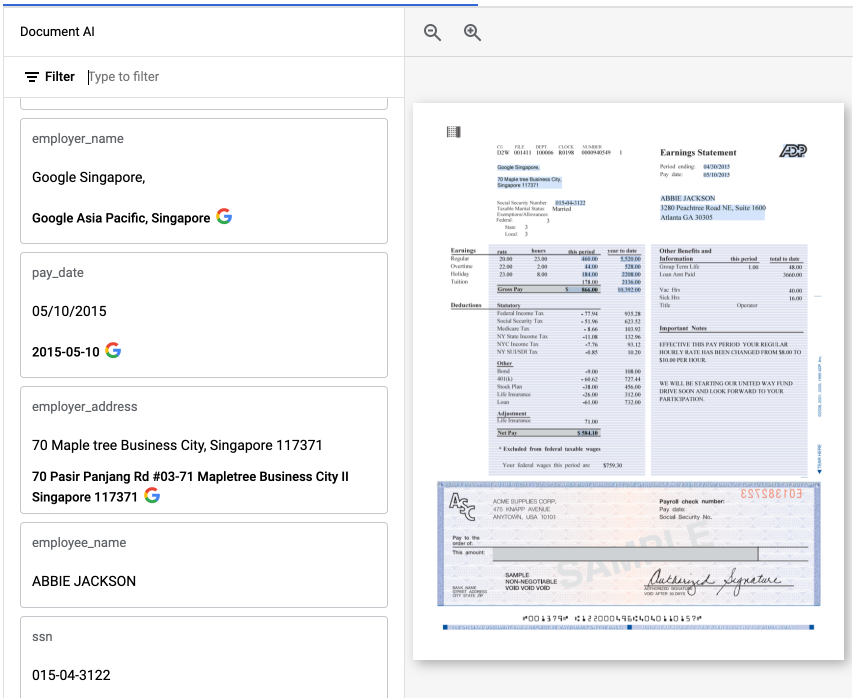
この例では、元の employer_name「Google Singapore」が「Google Asia Pacific, Singapore」に正規化されています。
Google Cloud コンソールでは、拡充および正規化されたフィールドに G というアノテーションが付けられます。次に例を示します。
サポートされるプロセッサ
エンティティの拡充をサポートするプロセッサとフィールドは次のとおりです。
| プロセッサ | 拡充されたフィールド | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
銀行明細書パーサー
|
|
||||||||||||
W2 パーサー
|
|
||||||||||||
支払い明細パーサー
|
|
||||||||||||
経費パーサー
|
|
||||||||||||
Invoice パーサー
|
|