Restez organisé à l'aide des collections
Enregistrez et classez les contenus selon vos préférences.
Vous pouvez entraîner un modèle très performant avec seulement trois documents d'entraînement et trois documents de test pour les cas d'utilisation à mise en page fixe. Accélérez le développement et réduisez le temps de production pour les types de documents modèles tels que les formulaires W9, 1040, ACORD, les enquêtes et les questionnaires.
Configuration d'ensemble de données
Un ensemble de données de documents est requis pour entraîner, surentraîner ou évaluer une version du processeur.
Les processeurs Document AI apprennent à partir d'exemples, tout comme les humains. L'ensemble de données alimente la stabilité du processeur en termes de performances.
Ensemble de données d'entraînement
Pour améliorer le modèle et sa précision, entraînez un ensemble de données sur vos documents. Le modèle est constitué de documents avec vérité terrain. Vous devez disposer d'au moins trois documents pour entraîner un nouveau modèle.
Ensemble de données de test
L'ensemble de données de test est ce que le modèle utilise pour générer un score F1 (précision). Il est composé de documents avec une vérité terrain. Pour savoir à quelle fréquence le modèle a raison, la vérité terrain est utilisée pour comparer les prédictions du modèle (champs extraits du modèle) aux bonnes réponses. L'ensemble de données de test doit comporter au moins trois documents.
Bonnes pratiques concernant l'étiquetage en mode modèle
Un étiquetage approprié est l'une des étapes les plus importantes pour obtenir une grande précision.
Le mode Modèle utilise une méthodologie d'étiquetage unique qui diffère des autres modes d'entraînement :
Dessinez des cadres de délimitation autour de toute la zone où vous vous attendez à ce que les données se trouvent (par libellé) dans un document, même si le libellé est vide dans le document d'entraînement que vous libellez.
Vous pouvez libeller des champs vides pour l'entraînement basé sur un modèle. Ne libellez pas les champs vides pour l'entraînement basé sur un modèle.
Créer et évaluer un extracteur personnalisé avec le mode modèle
Définissez l'emplacement de l'ensemble de données. Sélectionnez le dossier d'option par défaut (géré par Google). Cela peut se faire automatiquement peu de temps après la création du processeur.
Accédez à l'onglet Compiler, puis sélectionnez Importer des documents avec l'étiquetage automatique activé. Ajouter plus de documents que le minimum de trois requis n'améliore généralement pas la qualité de l'entraînement basé sur des modèles. Au lieu d'en ajouter d'autres, concentrez-vous sur l'étiquetage d'un petit ensemble de données avec une grande précision.
Étendez les cadres de délimitation. Ces zones pour le mode modèle doivent ressembler aux exemples précédents. Élargissez les cadres de sélection en suivant les bonnes pratiques pour obtenir un résultat optimal.
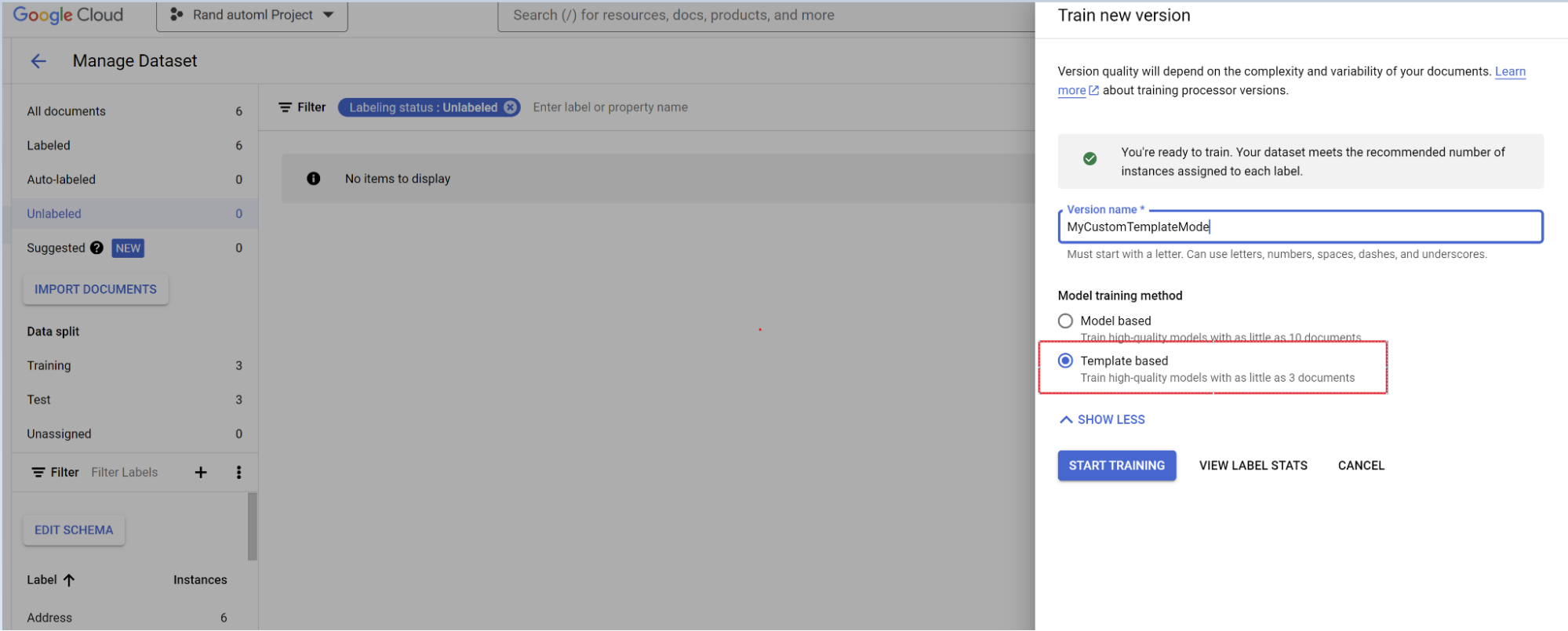
Entraîner le modèle
Sélectionnez Entraîner une nouvelle version.
Nommez la version du processeur.
Accédez à Afficher les options avancées, puis sélectionnez l'approche basée sur les modèles.
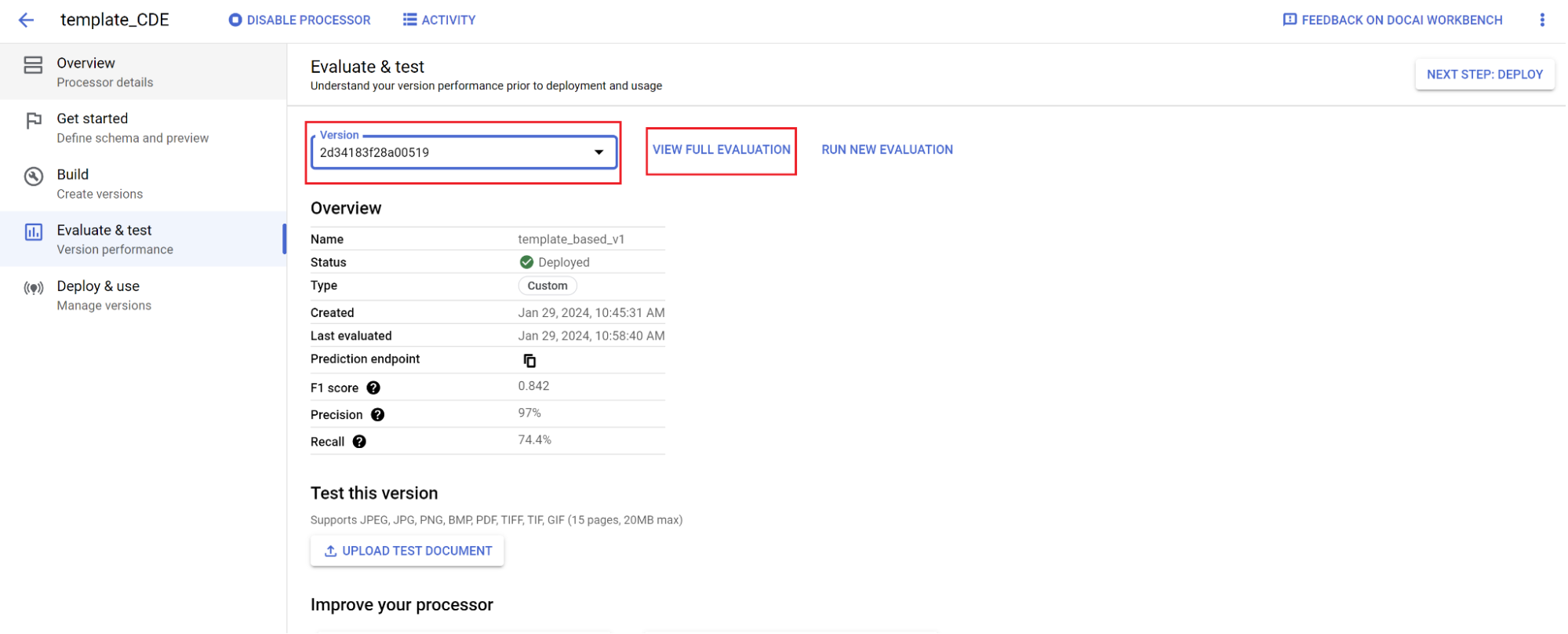
Évaluation.
Accédez à Évaluer et tester.
Sélectionnez la version que vous venez d'entraîner, puis Afficher l'évaluation complète.
Vous pouvez désormais consulter des métriques telles que le score F1, la précision et le rappel pour l'ensemble du document et pour chaque champ.
1. Déterminez si les performances répondent à vos objectifs de production. Si ce n'est pas le cas, réévaluez les ensembles d'entraînement et de test.
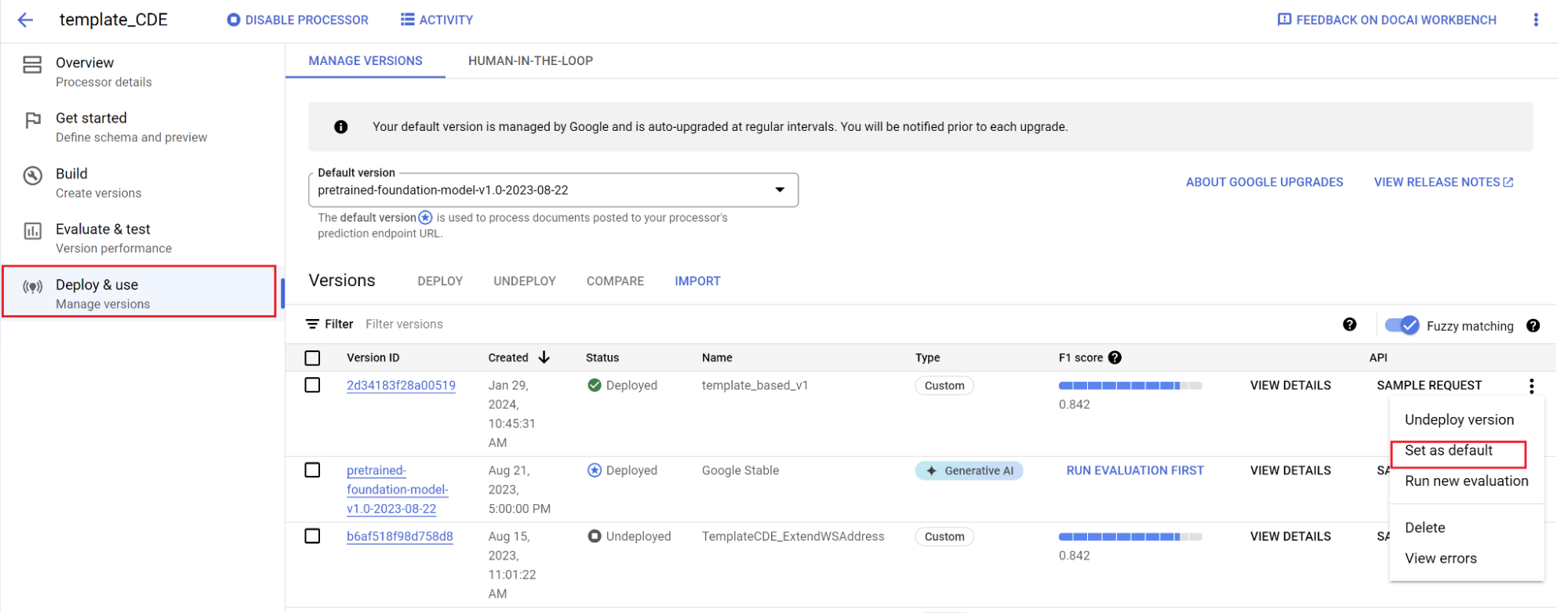
Définissez une nouvelle version par défaut.
Accédez à Gérer les versions.
Sélectionnez pour afficher le menu des paramètres, puis cochez Définir comme paramètre par défaut.
Votre modèle est désormais déployé et les documents envoyés à ce processeur utilisent votre version personnalisée. Vous souhaitez évaluer les performances du modèle (en savoir plus) pour vérifier s'il nécessite un entraînement supplémentaire.
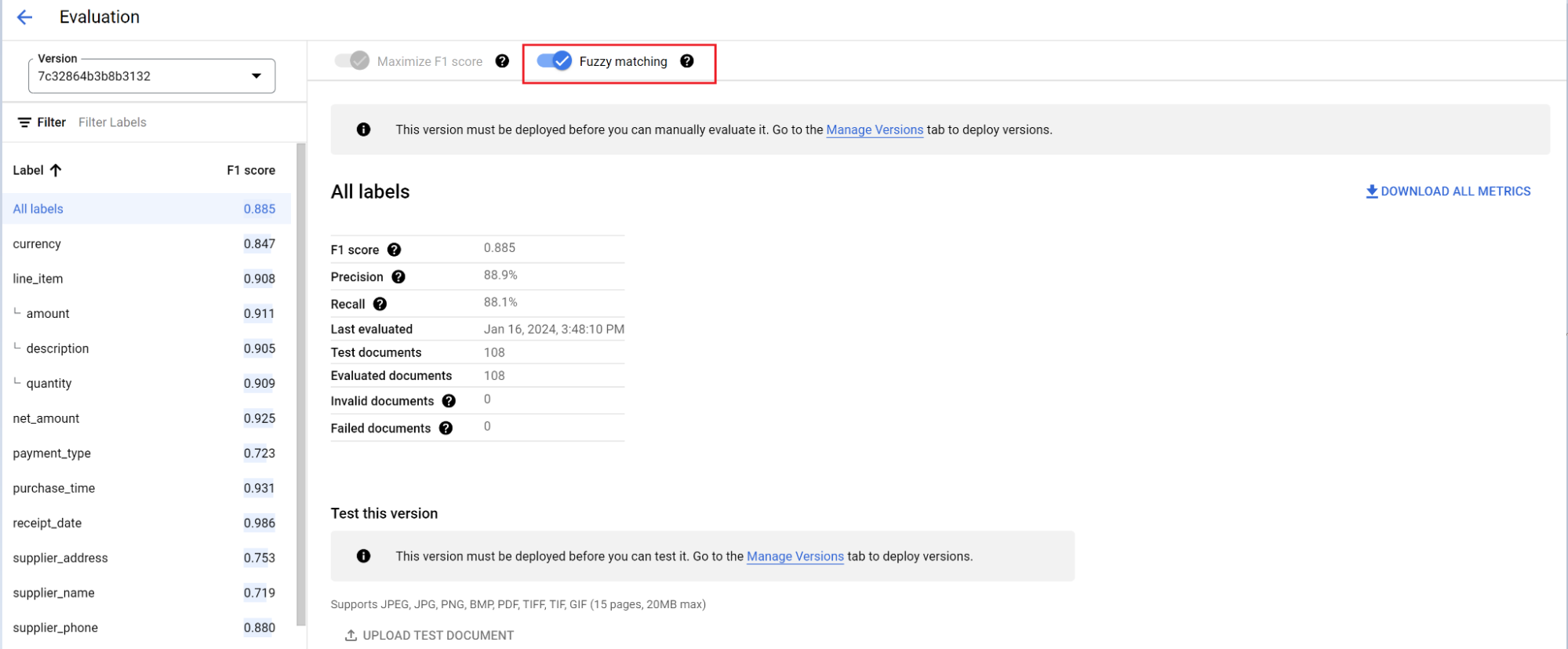
Référence d'évaluation
Le moteur d'évaluation peut effectuer une correspondance exacte ou approximative.
Pour une correspondance exacte, la valeur extraite doit correspondre exactement à la vérité terrain. Dans le cas contraire, elle est considérée comme une erreur.
Les extractions par correspondance approximative qui présentent de légères différences, comme des différences de casse, sont toujours considérées comme des correspondances. Vous pouvez le modifier sur l'écran Évaluation.
Étiquetage automatique avec le modèle de fondation
Le modèle de fondation peut extraire avec précision des champs à partir de types de documents divers, mais vous pouvez également fournir des données d'entraînement supplémentaires afin d'améliorer sa précision pour des structures de documents spécifiques.
Document AI utilise les noms d'étiquettes que vous avez définis et les annotations précédentes pour faciliter et accélérer l'étiquetage des documents à grande échelle grâce à l'étiquetage automatique.
Après avoir créé un processeur personnalisé, accédez à l'onglet Commencer.
Sélectionnez Créer un champ.
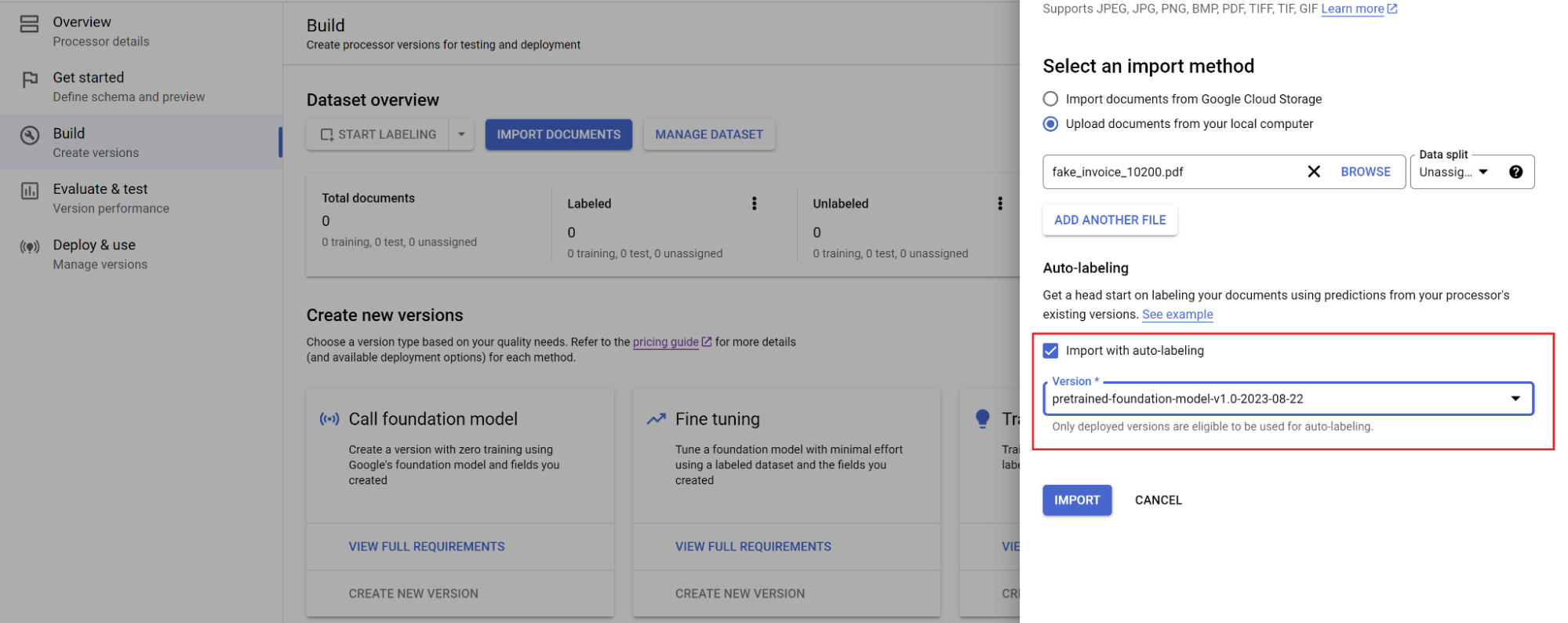
Accédez à l'onglet Compiler, puis sélectionnez Importer des documents.
Sélectionnez le chemin d'accès aux documents et l'ensemble dans lequel ils doivent être importés. Cochez la case "Étiquetage automatique" et sélectionnez le modèle de fondation.
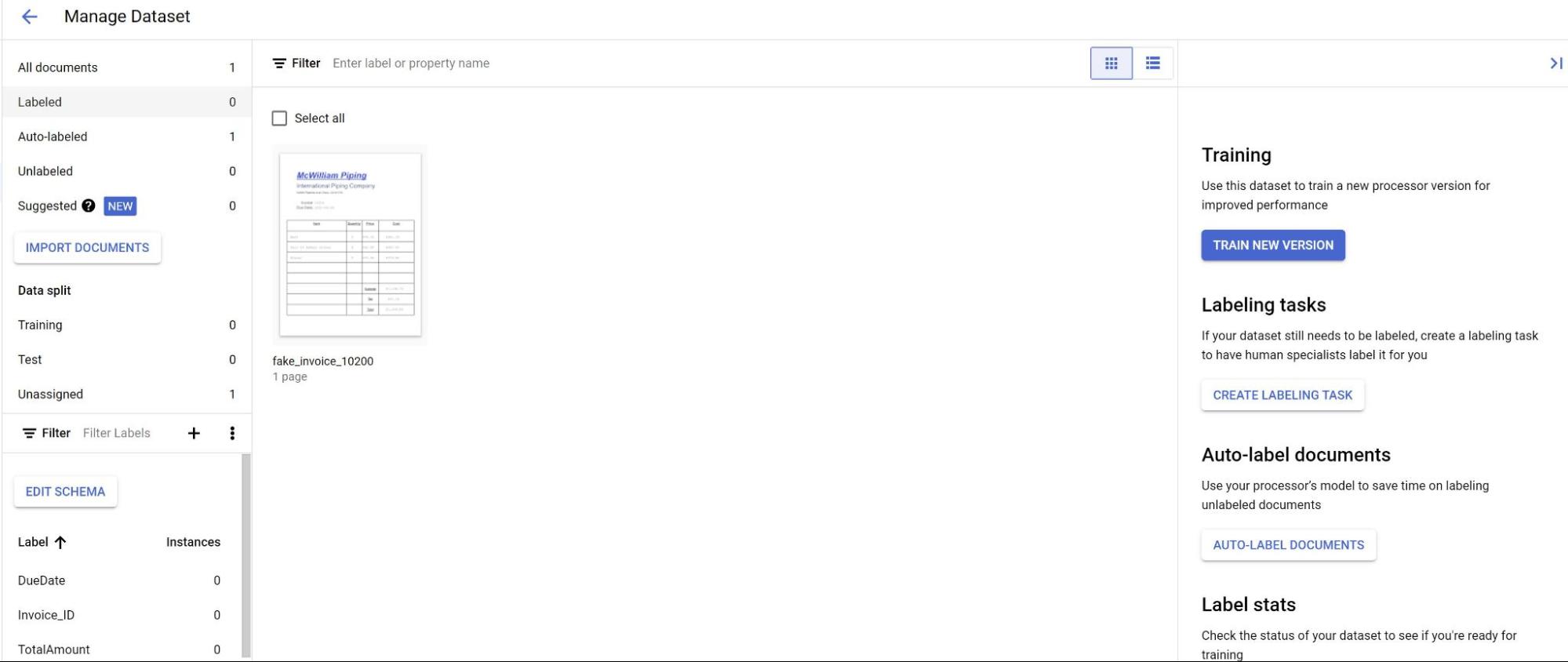
Dans l'onglet Compiler, sélectionnez Gérer l'ensemble de données. Vos documents importés devraient s'afficher. Sélectionnez l'un de vos documents.
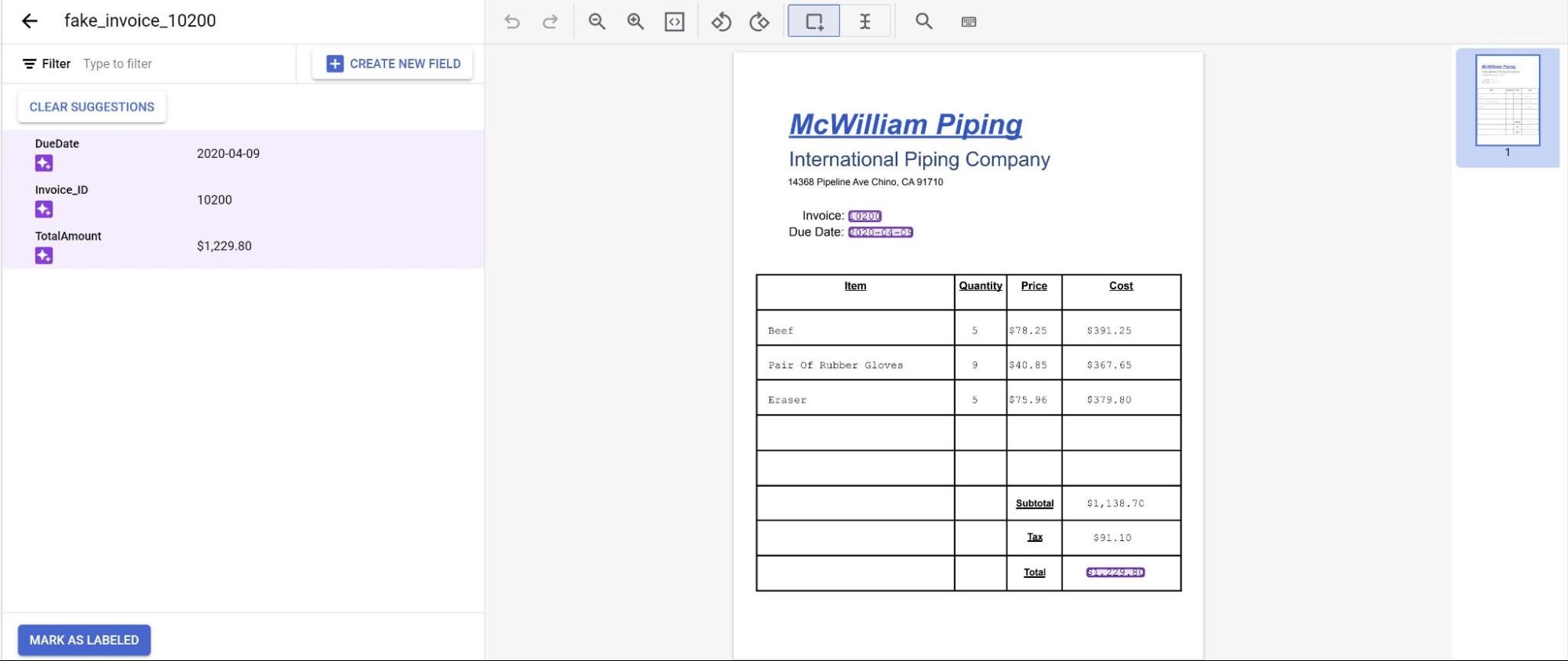
Les prédictions du modèle sont mises en évidence en violet. Vous devez examiner chaque étiquette prédite par le modèle et vous assurer qu'elle est correcte. Si des champs sont manquants, vous devez également les ajouter.
.
Une fois le document examiné, sélectionnez Marquer comme étiqueté.
Le document est maintenant prêt à être utilisé par le modèle. Assurez-vous que le document se trouve dans l'ensemble de test ou d'entraînement.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/04 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/04 (UTC)."],[[["\u003cp\u003eTemplate-based extraction allows for training a high-performing model with a minimum of three training and three test documents, ideal for fixed-layout documents like W9s and questionnaires.\u003c/p\u003e\n"],["\u003cp\u003eA document dataset, comprising documents with ground-truth data, is essential for training, up-training, and evaluating a processor version, as the processor learns from these examples.\u003c/p\u003e\n"],["\u003cp\u003eFor template mode labeling, it is recommended to draw bounding boxes around the entire expected data area within a document, even if the field is empty in the training document, unlike model-based training.\u003c/p\u003e\n"],["\u003cp\u003eWhen building a custom extractor, auto-labeling can be enabled during document import, and it is advised to focus on accurately labeling a small set of documents rather than adding more documents during template-based training.\u003c/p\u003e\n"],["\u003cp\u003eThe foundation model allows for auto-labeling, which can be improved in accuracy and performance with the addition of training data with descriptive label names, while ensuring that all fields are accurate.\u003c/p\u003e\n"]]],[],null,["# Template-based extraction\n=========================\n\nYou can train a high-performing model with as little as three training and three test\ndocuments for fixed-layout use cases. Accelerate development and reduce time to\nproduction for templated document types like W9, 1040, ACORD, surveys, and questionnaires.\n\n\nDataset configuration\n---------------------\n\nA document dataset is required to train, up-train, or evaluate a processor version. Document AI processors learn from examples, just like humans. Dataset fuels processor stability in terms of performance. \n\n### Train dataset\n\nTo improve the model and its accuracy, train a dataset on your documents. The model is made up of documents with ground-truth. You need a minimum of three documents to train a new model. Ground-truth is the correctly labeled data, as determined by humans.\n\n### Test dataset\n\nThe test dataset is what the model uses to generate an F1 score (accuracy). It is made up of documents with ground-truth. To see how often the model is right, the ground truth is used to compare the model's predictions (extracted fields from the model) with the correct answers. The test dataset should have at least three documents.\n\n\u003cbr /\u003e\n\nBefore you begin\n----------------\n\nIf not already done, enable:\n\n- [Billing](/document-ai/docs/setup#billing)\n- [Document AI API](/document-ai/docs/setup)\n\nTemplate-mode labeling best practices\n-------------------------------------\n\nProper labeling is one of the most important steps to achieving high accuracy.\nTemplate mode has some unique labeling methodology that differs from other training modes:\n\n- Draw bounding boxes around the entire area you expect data to be in (per label) within a document, even if the label is empty in the training document you're labeling.\n- You may label empty fields for template-based training. Don't label empty fields for model-based training.\n\n| **Recommended.** Labeling example for template-based training to extract the top section of a 1040.\n| **Not recommended.** Labeling example for template-based training to extract the top section of a 1040. This is the labeling technique you should use for model-based training for documents with layout variation across documents.\n\nBuild and evaluate a custom extractor with template mode\n--------------------------------------------------------\n\n1. Create a custom extractor. [Create a processor](/document-ai/docs/workbench/build-custom-processor#create_a_processor)\n and [define fields](/document-ai/docs/workbench/build-custom-processor#define_processor_fields)\n you want to extract following [best practices](/document-ai/docs/workbench/label-documents#name-fields),\n which is important because it impacts extraction quality.\n\n2. Set dataset location. Select the default option folder (Google-managed). This\n might be done automatically shortly after creating the processor.\n\n3. Navigate to the **Build** tab and select **Import documents** with auto-labeling\n enabled. Adding more documents than the minimum of three needed typically doesn't improve quality for\n template-based training. Instead of adding more, focus on labeling a small set very accurately.\n\n | **Note:** You can experiment by increasing the training set size if you observe template variations in your dataset. Try to include at least three training documents per variation. At least three training documents, three test documents, and three schema labels are required per set.\n4. Extend bounding boxes. These boxes for template mode should look like the preceding\n examples. Extend the bounding boxes, following the best practices for the optimal result.\n\n5. Train model.\n\n 1. Select **Train new version**.\n 2. Name the processor version.\n 3. Go to **Show advanced options** and select the template-based model approach.\n\n | **Note:** It takes some time for the training to complete.\n6. Evaluation.\n\n 1. Go to **Evaluate \\& test**.\n 2. Select the version you just trained, then select **View Full Evaluation**.\n\n You now see metrics such as F1, precision, and recall for the entire document and each field.\n 1. Decide if performance meets your production goals, and if not, reevaluate training and testing sets.\n7. Set a new version as the default.\n\n 1. Navigate to **Manage versions**.\n 2. Select to see the settings menu, then mark **Set as default**.\n\n Your model is now deployed and documents sent to this processor use your custom\n version. You want to evaluate the model's performance ([more details](/document-ai/docs/workbench/evaluate)\n on how to do that) to check if it requires further training.\n\nEvaluation reference\n--------------------\n\nThe evaluation engine can do both exact match or [fuzzy matching](/document-ai/docs/workbench/evaluate#fuzzy_matching).\nFor an exact match, the extracted value must exactly match the ground truth or is counted as a miss.\n\nFuzzy matching extractions that had slight differences such as capitalization\ndifferences still count as a match. This can be changed at the **Evaluation** screen.\n\nAuto-labeling with the foundation model\n---------------------------------------\n\nThe foundation model can accurately extract fields for a variety of document types,\nbut you can also provide additional training data to improve the accuracy of the\nmodel for specific document structures.\n\nDocument AI uses the label names you define and previous annotations to make\nit quicker and easier to label documents at scale with auto-labeling.\n\n1. After creating a custom processor, go to the **Get started** tab.\n2. Select **Create New Field**.\n\n | **Note:** The label name with the foundation model can greatly affect model accuracy and performance. Be sure to give a descriptive name.\n\n3. Navigate to the **Build** tab and then select **Import documents**.\n\n4. Select the path of the documents and which set the documents should be imported\n into. Check the auto-labeling checkbox and select the foundation model.\n\n5. In the **Build** tab, select **Manage dataset**. You should see your imported\n documents. Select one of your documents.\n\n6. You see the predictions from the model highlighted in purple, you need to review\n each label predicted by the model and ensure it's correct. If there are missing\n fields, you need to add those as well.\n\n | **Note:** It's important that all fields are as accurate as possible or model performance is going to be affected. For more [details on labeling](/document-ai/docs/workbench/label-documents).\n\n7. Once the document has been reviewed, select **Mark as labeled**.\n\n8. The document is now ready to be used by the model. Make sure the document is\n in either the testing or training set."]]