固定レイアウトのユースケースでは、3 つのトレーニング ドキュメントと 3 つのテスト ドキュメントだけで、パフォーマンスの高いモデルをトレーニングできます。W9、1040、ACORD、アンケート、質問票などのテンプレート化されたドキュメント タイプの開発を加速し、本番環境までの時間を短縮します。
データセットの構成
プロセッサ バージョンのトレーニング、アップトレーニング、評価を行うには、ドキュメント データセットが必要です。Document AI プロセッサは、人間と同じように例から学習します。データセットは、パフォーマンスの面でプロセッサの安定性を高めます。トレーニング データセット
モデルとその精度を向上させるには、ドキュメントでデータセットをトレーニングします。モデルは、正解を含むドキュメントで構成されています。新しいモデルをトレーニングするには、少なくとも 3 つのドキュメントが必要です。テスト データセット
テスト データセットは、モデルが F1 スコア(精度)を生成するために使用するものです。グラウンド トゥルースを含むドキュメントで構成されています。モデルの正答率を確認するには、グラウンド トゥルースを使用して、モデルの予測(モデルから抽出されたフィールド)と正解を比較します。テスト データセットには、少なくとも 3 つのドキュメントが必要です。始める前に
まだ有効になっていない場合は、次の設定を有効にします。
テンプレート モードのラベル付けのベスト プラクティス
適切なラベル付けは、高い精度を実現するための最も重要なステップの一つです。テンプレート モードには、他のトレーニング モードとは異なる独自のラベリング方法があります。
- ラベル付けするトレーニング ドキュメントでラベルが空の場合でも、ドキュメント内のデータが存在すると予想される領域全体(ラベルごと)の周囲に境界ボックスを描画します。
- テンプレート ベースのトレーニングでは、空のフィールドにラベルを付けることができます。モデルベースのトレーニングでは、空のフィールドにラベルを付けないでください。
テンプレート モードでカスタム エクストラクタを構築して評価する
カスタム エクストラクタを作成します。プロセッサを作成し、ベスト プラクティスに沿って抽出するフィールドを定義します。これは抽出の品質に影響するため、重要です。
データセットのロケーションを設定します。デフォルトのオプション フォルダ(Google 管理)を選択します。これは、プロセッサの作成直後に自動的に行われることがあります。
[ビルド] タブに移動し、自動ラベル付けが有効になっている [ドキュメントのインポート] を選択します。通常、テンプレート ベースのトレーニングでは、必要な最小数の 3 つを超えるドキュメントを追加しても品質は向上しません。数を増やすのではなく、少数のセットに正確なラベルを付けることに注力します。
境界ボックスを拡張します。テンプレート モードのこれらのボックスは、上記の例のようになります。最適な結果を得るためのベスト プラクティスに沿って、バウンディング ボックスを拡張します。
モデルをトレーニングする。
- [新しいバージョンをトレーニング] を選択します。
- プロセッサ バージョンに名前を付けます。
- [詳細オプションを表示する] に移動し、テンプレート ベースのモデル アプローチを選択します。
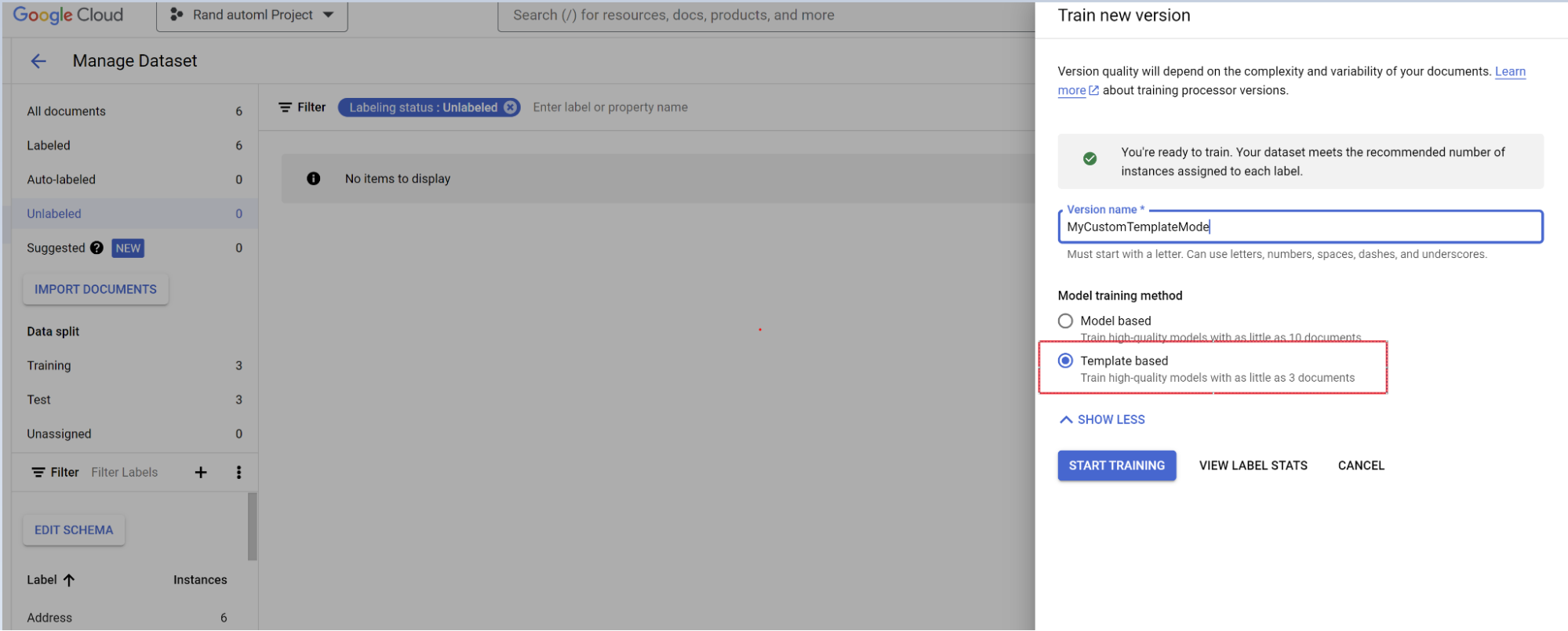
評価。
- [評価とテスト] に移動します。
- トレーニングしたバージョンを選択し、[完全な評価を表示] を選択します。
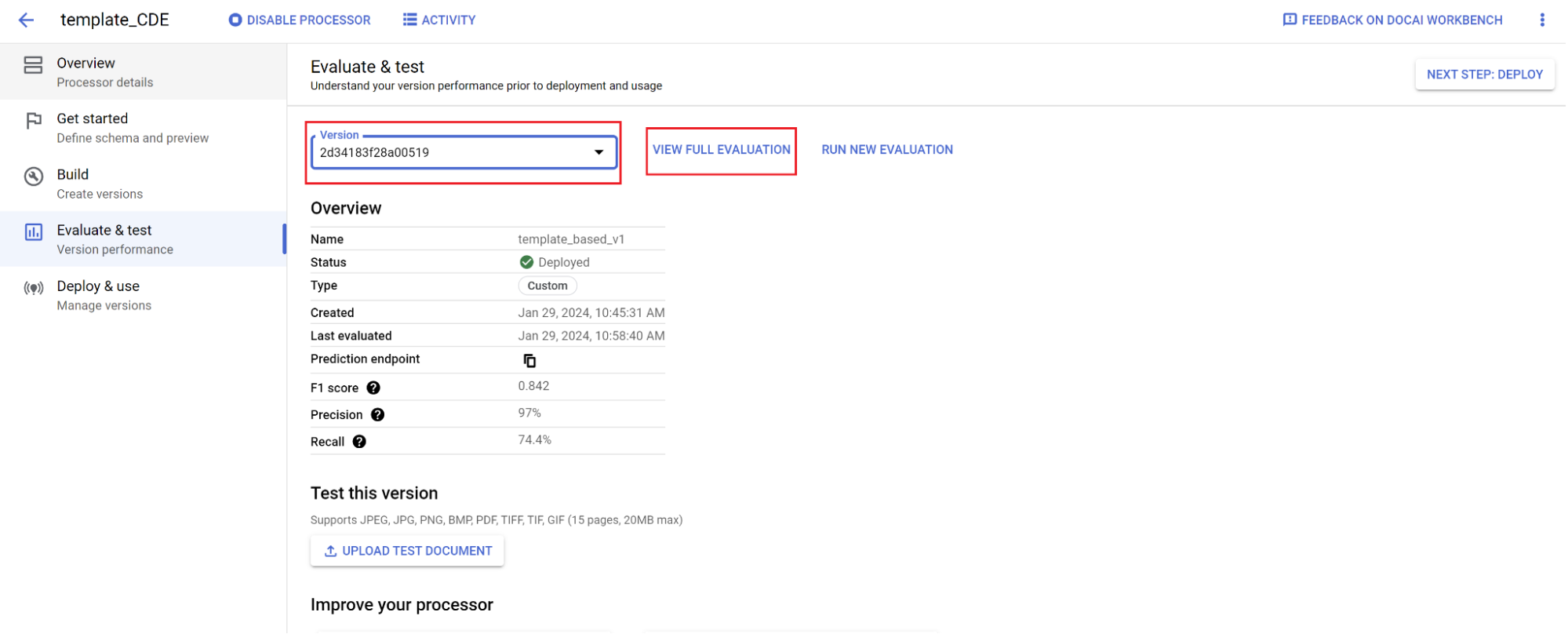
ドキュメント全体と各フィールドの F1 スコア、適合率、再現率などの指標が表示されます。1. パフォーマンスが本番環境の目標を満たしているかどうかを判断します。満たしていない場合は、トレーニング セットとテストセットを再評価します。
新しいバージョンをデフォルトとして設定します。
- [版を管理] に移動します。
- 選択して設定メニューを表示し、[デフォルトに設定] をオンにします。
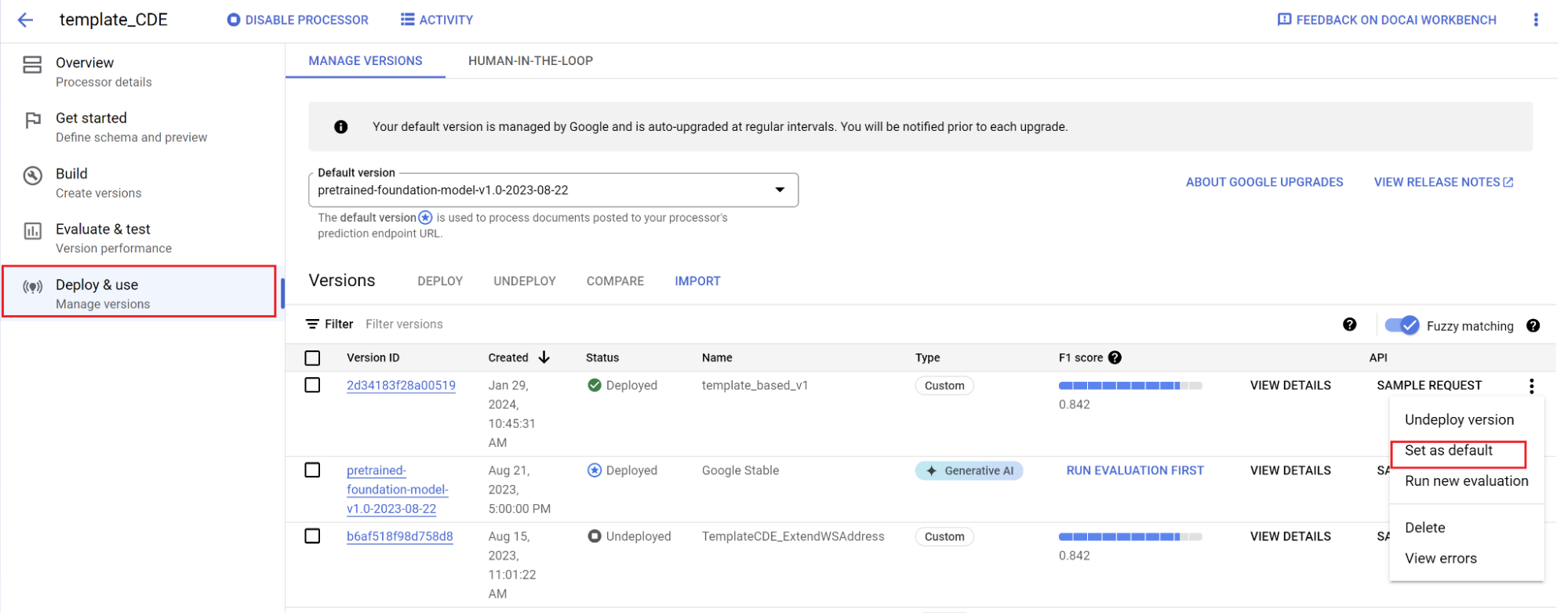
モデルがデプロイされ、このプロセッサに送信されたドキュメントはカスタム バージョンを使用します。モデルのパフォーマンスを評価し(評価方法の詳細)、追加のトレーニングが必要かどうかを確認する。
評価参照
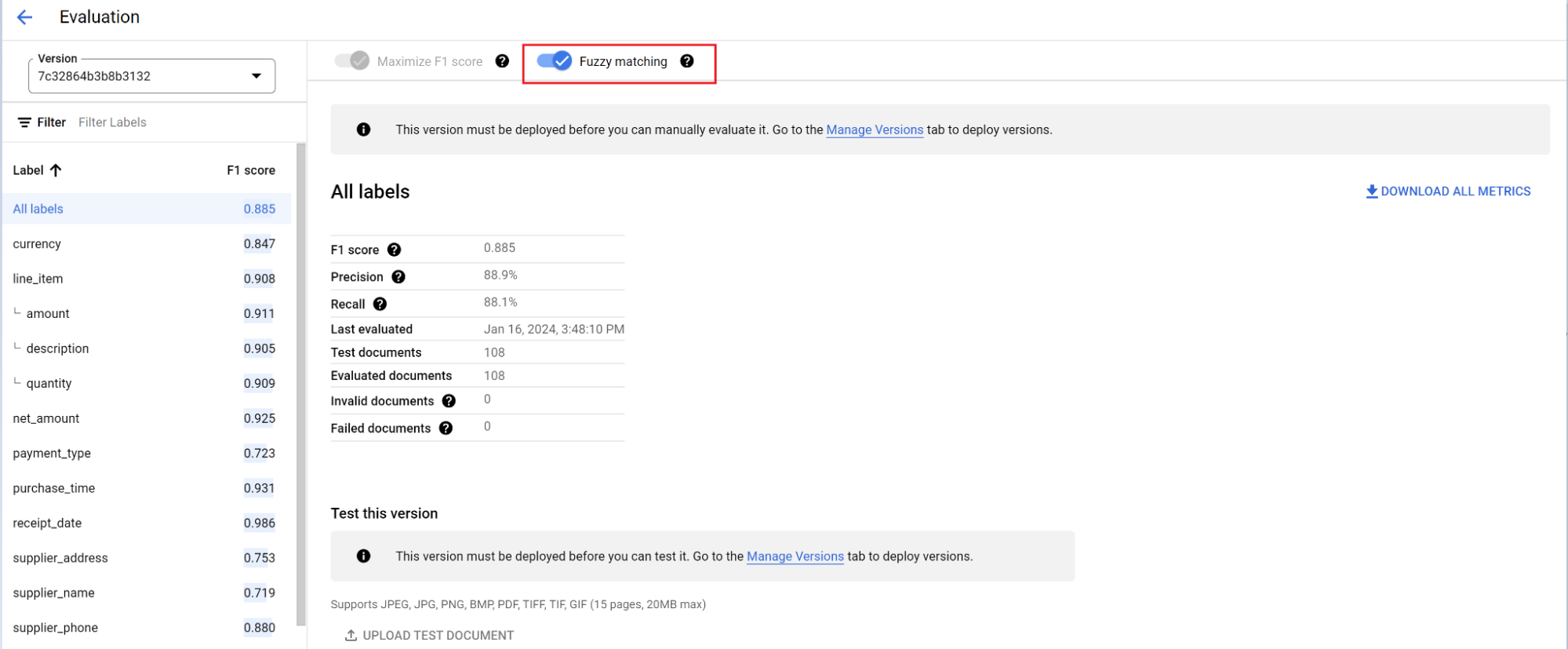
評価エンジンは、完全一致とファジー マッチングの両方を行うことができます。完全一致の場合、抽出された値が正解ラベルと完全に一致している必要があります。一致していない場合は、不一致としてカウントされます。
大文字と小文字の違いなど、わずかな違いがあるファジー マッチング抽出は、一致としてカウントされます。この設定は [評価] 画面で変更できます。
基盤モデルを使用した自動ラベル付け
基盤モデルは、さまざまなドキュメント タイプのフィールドを正確に抽出できますが、追加のトレーニング データを提供して、特定のドキュメント構造に対するモデルの精度を向上させることもできます。
Document AI は、定義したラベル名と以前のアノテーションを使用して、自動ラベル付けで素早く簡単にドキュメントを大規模にラベル付けすることができます。
- カスタム プロセッサを作成したら、[スタートガイド] タブに移動します。
[新しいフィールドを作成] を選択します。
[ビルド] タブに移動し、[ドキュメントのインポート] を選択します。
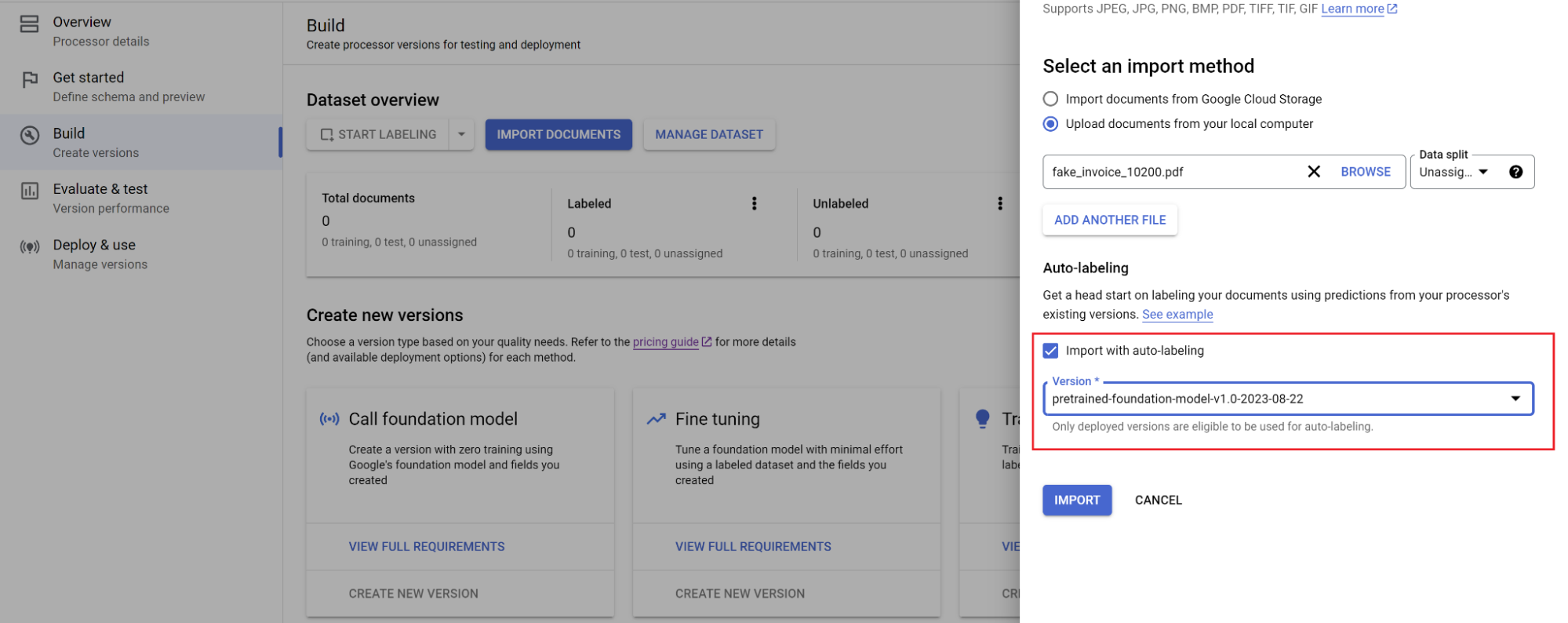
ドキュメントのパスと、ドキュメントのインポート先のセットを選択します。自動ラベル付けのチェックボックスをオンにして、基盤モデルを選択します。
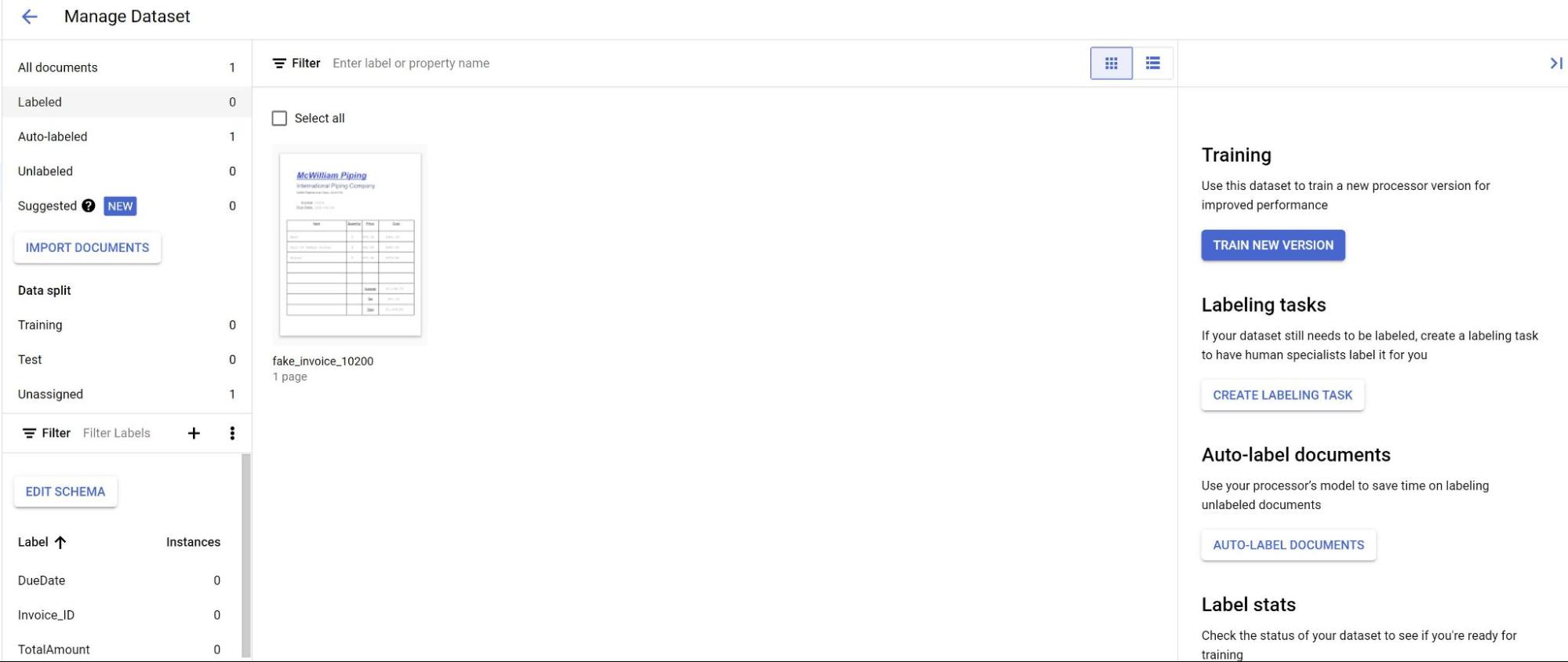
[ビルド] タブで、[データセットを管理] を選択します。インポートしたドキュメントが表示されます。ドキュメントを 1 つ選択します。
モデルの予測が紫でハイライト表示されます。モデルによって予測された各ラベルを確認し、正しいことを確認する必要があります。欠落しているフィールドがある場合は、それらも追加する必要があります。
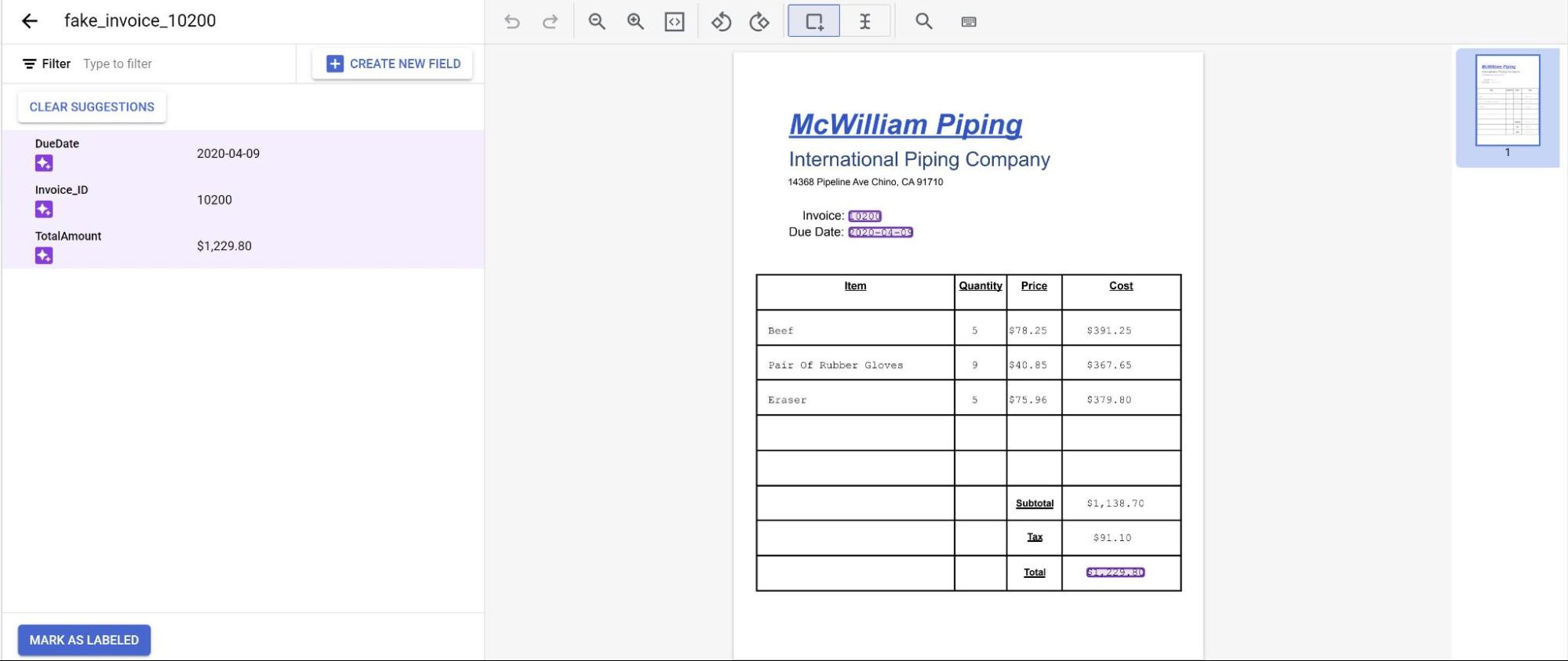
ドキュメントの審査が完了したら、[ラベル付きとしてマーク] を選択します。
これで、ドキュメントをモデルで使用できるようになりました。ドキュメントがテストセットまたはトレーニング セットのいずれかに含まれていることを確認します。