BigQuery terintegrasi dengan Document AI untuk membantu membangun analisis dokumen dan kasus penggunaan AI generatif. Seiring percepatan transformasi digital, organisasi menghasilkan sejumlah besar data teks dan dokumen lainnya, yang semuanya memiliki potensi besar untuk menghasilkan insight dan mendukung kasus penggunaan AI generatif baru. Untuk membantu memanfaatkan data ini, kami dengan senang hati mengumumkan integrasi antara BigQuery dan Document AI, yang memungkinkan Anda mengekstrak insight dari data dokumen dan membuat aplikasi model bahasa besar (LLM) baru.
Ringkasan
Pelanggan BigQuery kini dapat membuat pengekstrak kustom Document AI, yang didukung oleh model dasar canggih Google, yang dapat mereka sesuaikan berdasarkan dokumen dan metadata mereka sendiri. Model yang disesuaikan ini kemudian dapat dipanggil dari BigQuery untuk mengekstrak data terstruktur dari dokumen secara aman dan teratur, menggunakan kesederhanaan dan kecanggihan SQL. Sebelum integrasi ini, beberapa pelanggan mencoba membuat pipeline Document AI independen, yang melibatkan kurasi logika dan skema ekstraksi secara manual. Kurangnya kemampuan integrasi bawaan membuat mereka harus mengembangkan infrastruktur khusus untuk menyinkronkan dan menjaga konsistensi data. Hal ini mengubah setiap project analisis dokumen menjadi tugas besar yang memerlukan investasi signifikan. Sekarang, dengan integrasi ini, pelanggan dapat membuat model jarak jauh di BigQuery untuk ekstraktor kustom mereka di Document AI, dan menggunakannya untuk melakukan analisis dokumen dan AI generatif dalam skala besar, sehingga membuka era baru insight dan inovasi berbasis data.
Pengalaman data ke AI yang terpadu dan dikelola
Anda dapat membuat ekstraktor kustom di Document AI dengan tiga langkah:
- Tentukan data yang perlu diekstrak dari dokumen Anda. Hal ini disebut
document schema, disimpan dengan setiap versi ekstraktor kustom, dapat diakses dari BigQuery. - Jika perlu, berikan dokumen tambahan dengan anotasi sebagai contoh ekstraksi.
- Latih model untuk pengekstraksi kustom, berdasarkan model dasar yang disediakan di Document AI.
Selain pengekstraksi kustom yang memerlukan pelatihan manual, Document AI juga menyediakan pengekstraksi siap pakai untuk pengeluaran, tanda terima, invoice, formulir pajak, tanda pengenal pemerintah, dan berbagai skenario lainnya, di galeri pemroses.
Kemudian, setelah pengekstraksi kustom siap, Anda dapat beralih ke BigQuery Studio untuk menganalisis dokumen menggunakan SQL dalam empat langkah berikut:
- Daftarkan model jarak jauh BigQuery untuk ekstraktor menggunakan SQL. Model dapat memahami skema dokumen (yang dibuat di atas), memanggil ekstraktor kustom, dan mengurai hasilnya.
- Buat tabel objek menggunakan SQL untuk dokumen yang disimpan di Cloud Storage. Anda dapat mengatur data tidak terstruktur dalam tabel dengan menetapkan kebijakan akses tingkat baris, yang membatasi akses pengguna ke dokumen tertentu dan dengan demikian membatasi kemampuan AI untuk privasi dan keamanan.
- Gunakan fungsi
ML.PROCESS_DOCUMENTpada tabel objek untuk mengekstrak kolom yang relevan dengan melakukan panggilan inferensi ke endpoint API. Anda juga dapat memfilter dokumen untuk ekstraksi dengan klausaWHEREdi luar fungsi. Fungsi ini menampilkan tabel terstruktur, dengan setiap kolom adalah kolom yang diekstrak. - Gabungkan data yang diekstrak dengan tabel BigQuery lain untuk menggabungkan data terstruktur dan tidak terstruktur, sehingga menghasilkan nilai bisnis.
Contoh berikut mengilustrasikan pengalaman pengguna:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
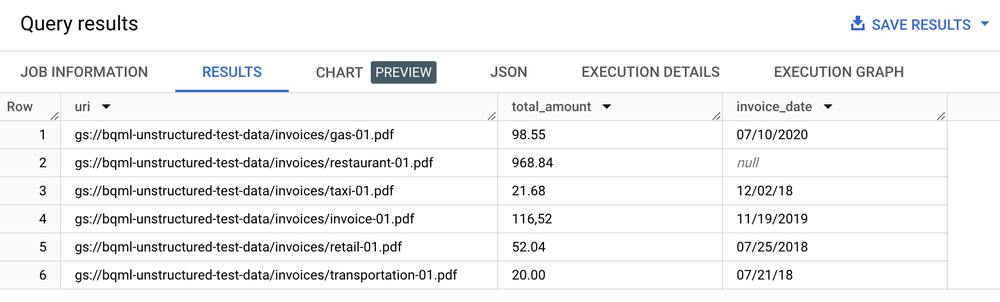
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
Tabel hasil
Analisis teks, pembuatan ringkasan, dan kasus penggunaan analisis dokumen lainnya
Setelah mengekstrak teks dari dokumen, Anda dapat melakukan analisis dokumen dengan beberapa cara:
- Menggunakan BigQuery ML untuk melakukan analisis teks: BigQuery ML mendukung pelatihan dan deployment model sematan dengan berbagai cara. Misalnya, Anda dapat menggunakan BigQuery ML untuk mengidentifikasi sentimen pelanggan dalam panggilan dukungan, atau untuk mengklasifikasikan masukan produk ke dalam berbagai kategori. Jika Anda adalah pengguna Python, Anda juga dapat menggunakan BigQuery DataFrames untuk pandas, dan API seperti scikit-learn untuk analisis teks pada data Anda.
- Gunakan LLM
text-embedding-004untuk membuat embedding dari dokumen yang dipecah: BigQuery memiliki fungsiML.GENERATE_EMBEDDINGyang memanggil modeltext-embedding-004untuk membuat embedding. Misalnya, Anda dapat menggunakan Document AI untuk mengekstrak masukan pelanggan dan meringkas masukan tersebut menggunakan PaLM 2, semuanya dengan BigQuery SQL. - Gabungkan metadata dokumen dengan data terstruktur lainnya yang disimpan dalam tabel BigQuery:
Misalnya, Anda dapat membuat embedding menggunakan dokumen yang di-chunk dan menggunakannya untuk penelusuran vektor.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
Menerapkan kasus penggunaan penelusuran dan AI generatif
Setelah mengekstrak teks terstruktur dari dokumen, Anda dapat membuat indeks yang dioptimalkan untuk kueri mencari jarum dalam tumpukan jerami, yang dimungkinkan oleh kemampuan penelusuran dan pengindeksan BigQuery, sehingga membuka kemampuan penelusuran yang canggih. Integrasi ini juga membantu membuka aplikasi LLM generatif baru seperti menjalankan pemrosesan file teks untuk pemfilteran privasi, pemeriksaan keamanan konten, dan pengelompokan token menggunakan SQL dan model Document AI kustom. Teks yang diekstrak, yang digabungkan dengan metadata lain, menyederhanakan kurasi korpus pelatihan yang diperlukan untuk menyesuaikan model bahasa besar. Selain itu, Anda membangun kasus penggunaan LLM pada data perusahaan yang diatur dan telah dirujuk melalui kemampuan pembuatan embedding dan pengelolaan indeks vektor BigQuery. Dengan menyinkronkan indeks ini dengan Vertex AI, Anda dapat menerapkan kasus penggunaan retrieval-augmented generation, untuk pengalaman AI yang lebih teratur dan efisien.
Contoh aplikasi
Untuk contoh aplikasi end-to-end yang menggunakan Konektor Document AI:
- Lihat demo laporan pengeluaran ini di GitHub.
- Baca postingan blog pendamping.
- Tonton video pembahasan mendalam dari Google Cloud Next 2021.