BigQuery se integra con Document AI para ayudar a crear análisis de documentos y casos de uso de IA generativa. A medida que se acelera la transformación digital, las organizaciones generan grandes cantidades de texto y otros datos de documentos, todos los cuales tienen un inmenso potencial para obtener estadísticas y potenciar casos de uso novedosos de IA generativa. Para aprovechar estos datos, nos complace anunciar una integración entre BigQuery y Document AI, que te permite extraer estadísticas a partir de los datos de documentos y compilar nuevas aplicaciones de modelos de lenguaje grande (LLM).
Descripción general
Los clientes de BigQuery ahora pueden crear extractores personalizados de Document AI, potenciados por los modelos de base de vanguardia de Google, que pueden personalizar en función de sus propios documentos y metadatos. Luego, estos modelos personalizados se pueden invocar desde BigQuery para extraer datos estructurados de documentos de manera segura y controlada, con la simplicidad y la potencia de SQL. Antes de esta integración, algunos clientes intentaron crear canalizaciones independientes de Document AI, lo que implicaba seleccionar manualmente la lógica y el esquema de extracción. La falta de capacidades de integración integradas los obligó a desarrollar una infraestructura personalizada para sincronizar y mantener la coherencia de los datos. Esto convirtió cada proyecto de análisis de documentos en una tarea sustancial que requirió una inversión significativa. Ahora, con esta integración, los clientes pueden crear modelos remotos en BigQuery para sus extractores personalizados en Document AI y usarlos para realizar análisis de documentos y aprovechar la IA generativa a gran escala, lo que marca el comienzo de una nueva era de estadísticas basadas en datos y de innovación.
Una experiencia unificada y administrada de datos a IA
Puedes crear un extractor personalizado en Document AI en tres pasos:
- Define los datos que necesitas extraer de tus documentos. Se llama
document schemay se almacena con cada versión del extractor personalizado, al que se puede acceder desde BigQuery. - De manera opcional, proporciona documentos adicionales con anotaciones como muestras de la extracción.
- Entrena el modelo para el extractor personalizado, según los modelos de base proporcionados en Document AI.
Además de los extractores personalizados que requieren entrenamiento manual, Document AI también proporciona extractores listos para usar para gastos, recibos, facturas, formularios fiscales, documentos de identidad gubernamentales y una multitud de otros casos de uso en la galería de procesadores.
Luego, una vez que tengas listo el extractor personalizado, puedes pasar a BigQuery Studio para analizar los documentos con SQL en los siguientes cuatro pasos:
- Registra un modelo remoto de BigQuery para el extractor con SQL. El modelo puede comprender el esquema del documento (creado anteriormente), invocar el extractor personalizado y analizar los resultados.
- Crea tablas de objetos con SQL para los documentos almacenados en Cloud Storage. Puedes controlar los datos no estructurados en las tablas configurando políticas de acceso a nivel de la fila, lo que limita el acceso de los usuarios a ciertos documentos y, por lo tanto, restringe la potencia de la IA para la privacidad y la seguridad.
- Usa la función
ML.PROCESS_DOCUMENTen la tabla de objetos para extraer los campos relevantes realizando llamadas de inferencia al extremo de API. También puedes filtrar los documentos para las extracciones con una cláusulaWHEREfuera de la función. La función devuelve una tabla estructurada, en la que cada columna es un campo extraído. - Une los datos extraídos con otras tablas de BigQuery para combinar datos estructurados y no estructurados, lo que generará valores comerciales.
En el siguiente ejemplo, se ilustra la experiencia del usuario:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
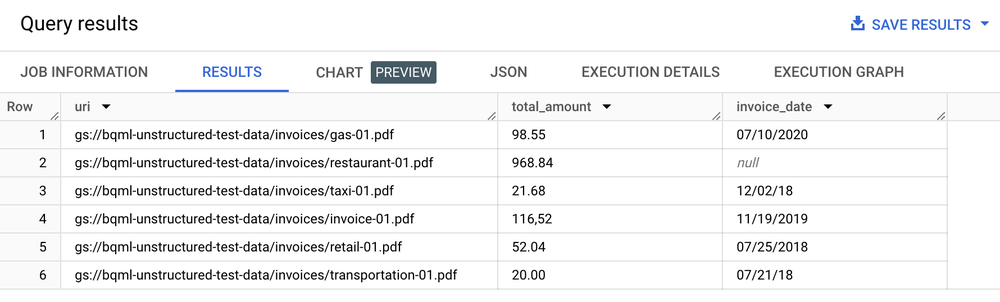
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
Tabla de resultados
Casos de uso de análisis de texto, resumen y otros análisis de documentos
Una vez que hayas extraído el texto de tus documentos, podrás realizar análisis de documentos de las siguientes maneras:
- Usa BigQuery ML para realizar análisis de texto: BigQuery ML admite el entrenamiento y la implementación de modelos de incorporación de varias maneras. Por ejemplo, puedes usar BigQuery ML para identificar la opinión de los clientes en las llamadas de asistencia o para clasificar los comentarios sobre los productos en diferentes categorías. Si eres usuario de Python, también puedes usar BigQuery DataFrames para Pandas y APIs similares a scikit-learn para el análisis de texto en tus datos.
- Usa el LLM
text-embedding-004para generar embeddings a partir de los documentos divididos en fragmentos: BigQuery tiene una funciónML.GENERATE_EMBEDDINGque llama al modelotext-embedding-004para generar embeddings. Por ejemplo, puedes usar Document AI para extraer comentarios de los clientes y resumirlos con PaLM 2, todo con SQL de BigQuery. - Une los metadatos del documento con otros datos estructurados almacenados en tablas de BigQuery:
Por ejemplo, puedes generar embeddings con los documentos fragmentados y usarlos para la búsqueda de vectores.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
Implementa casos de uso de la búsqueda y la IA generativa
Una vez que hayas extraído el texto estructurado de tus documentos, puedes crear índices optimizados para las búsquedas de aguja en un pajar, lo que es posible gracias a las capacidades de búsqueda y de indexación de BigQuery, que desbloquean una potente capacidad de búsqueda. Esta integración también ayuda a desbloquear nuevas aplicaciones de LLM generativos, como la ejecución del procesamiento de archivos de texto para el filtrado de privacidad, las verificaciones de seguridad del contenido y la división en fragmentos de tokens con SQL y modelos personalizados de Document AI. El texto extraído, combinado con otros metadatos, simplifica la selección del corpus de entrenamiento necesario para ajustar los modelos de lenguaje grandes. Además, compilas casos de uso de LLM sobre datos empresariales gobernados que se fundamentan a través de las capacidades de generación de embeddings y administración de índices vectoriales de BigQuery. Si sincronizas este índice con Vertex AI, puedes implementar casos de uso de generación mejorada por recuperación para obtener una experiencia de IA más controlada y optimizada.
Aplicación de ejemplo
Para obtener un ejemplo de una aplicación de extremo a extremo con el conector de Document AI:
- Consulta esta demostración del informe de gastos en GitHub.
- Lee la entrada de blog complementaria.
- Mira un video detallado de Google Cloud Next 2021.